Webscraping techniques are a bit like porn. A lot of us are using them, but no one's really talking about it. Maybe that's why scraping applications often end up as a bunch of scripts hacked together by some guy who left the company ages ago.
How sad! Let me show you that reverse engineering a frontend in order to extract data is actually quite a fun challenge and that there are lots of amazing tools out there that do most of the hard work for you.
{kind=link}
{kind=link}
{kind=link}
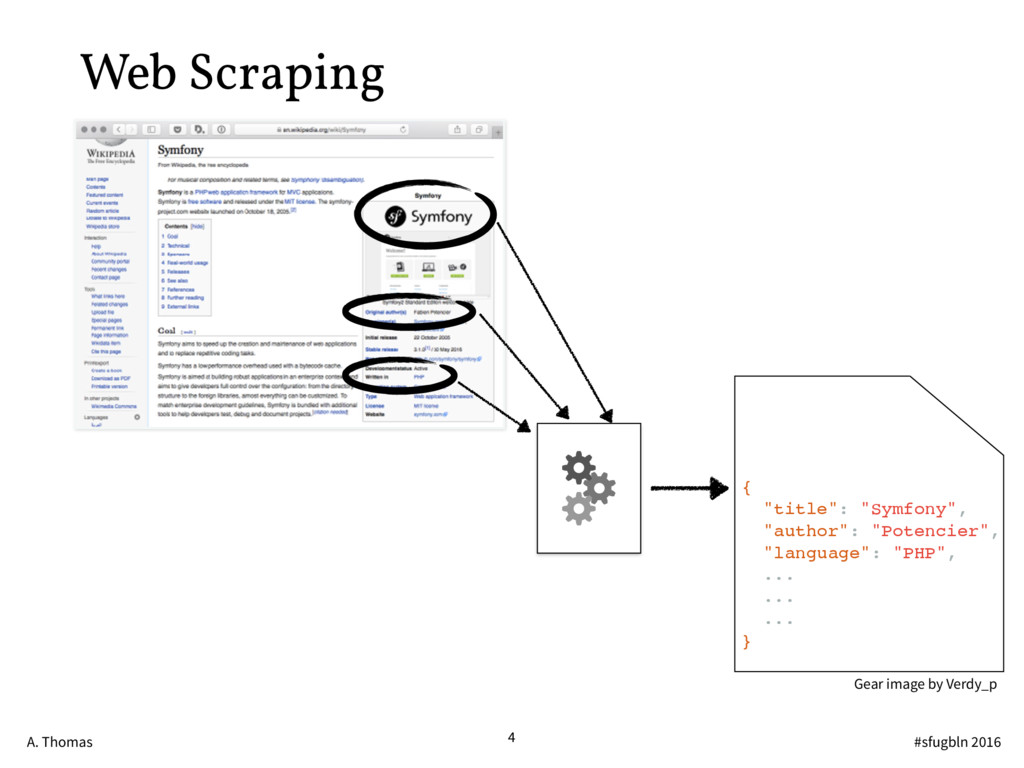{kind=link}
{kind=link}
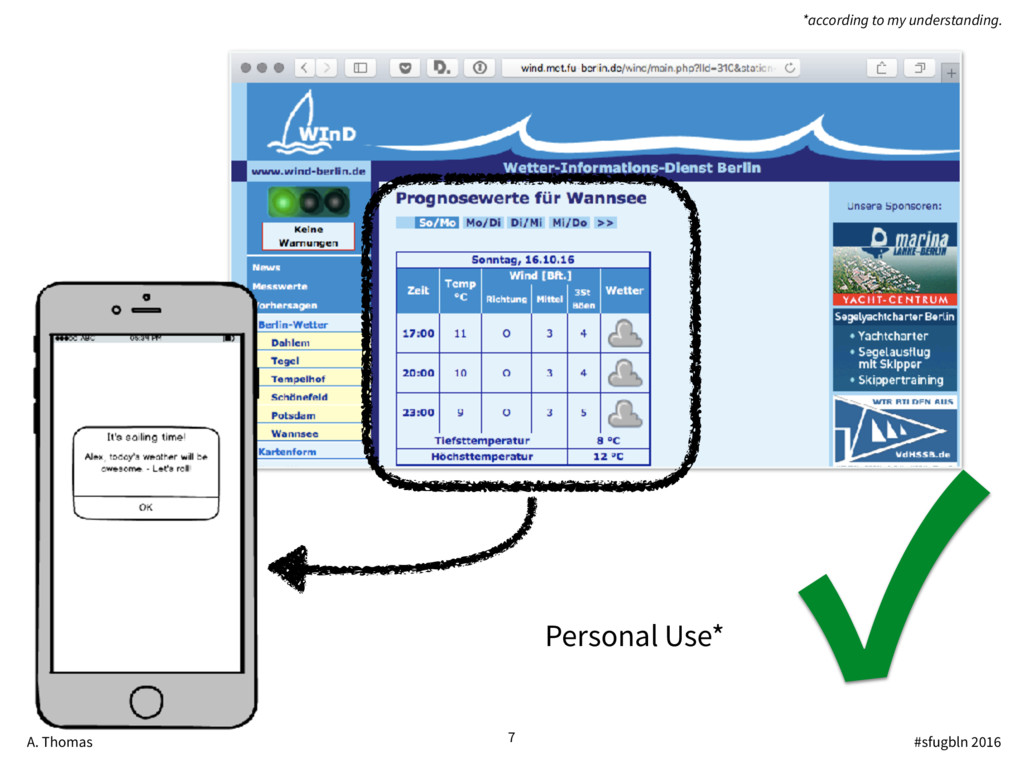{kind=link}
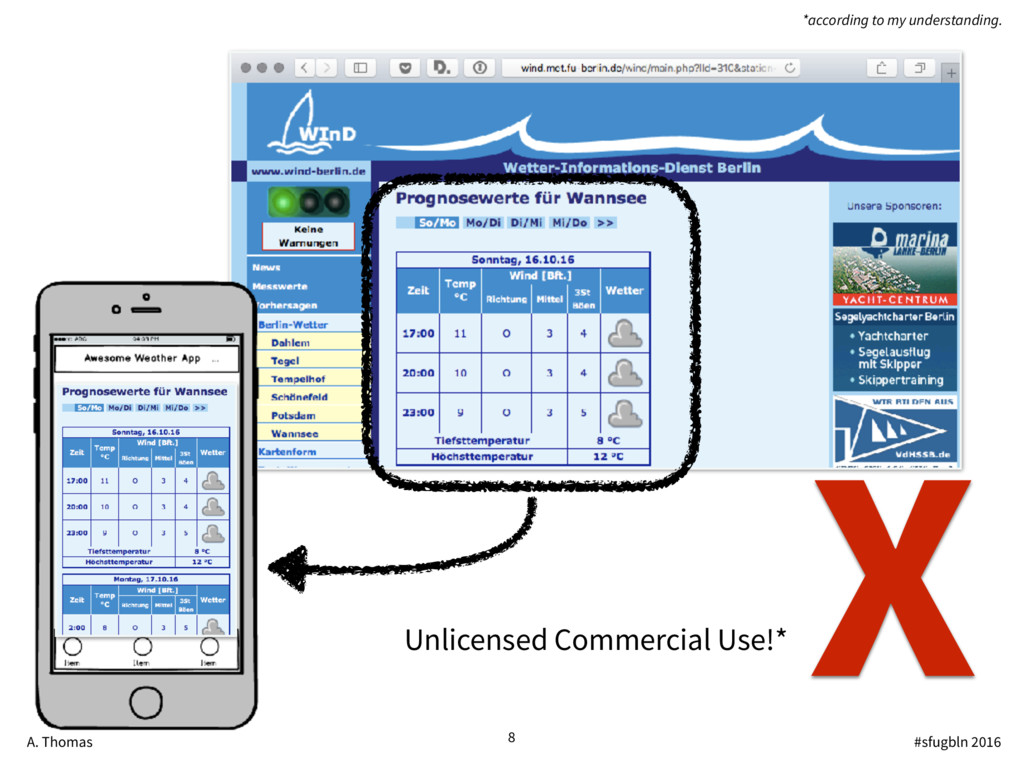{kind=link}
{kind=link}
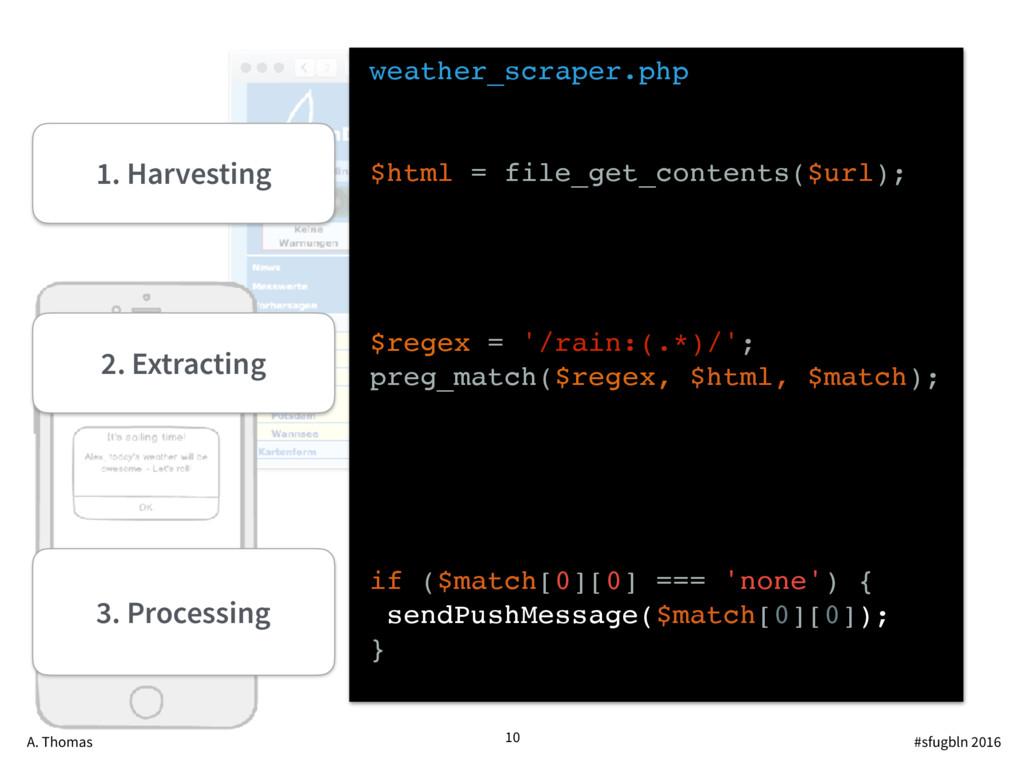{kind=link}
{kind=link}
{kind=link}
{kind=link}
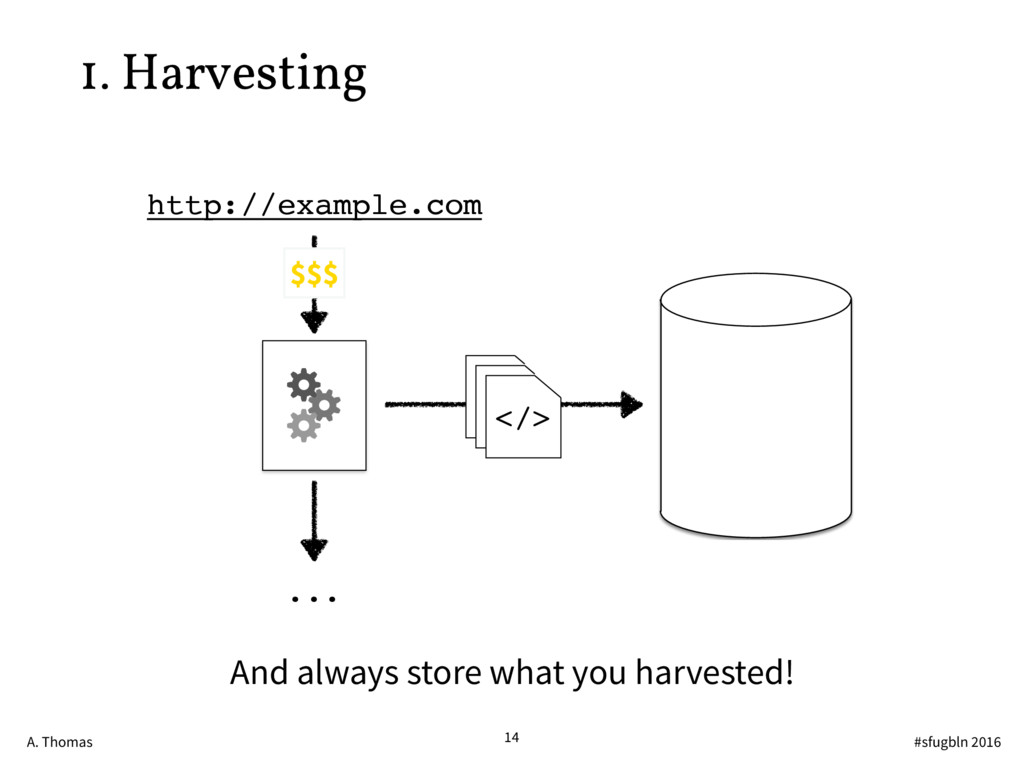{kind=link}
{kind=link}
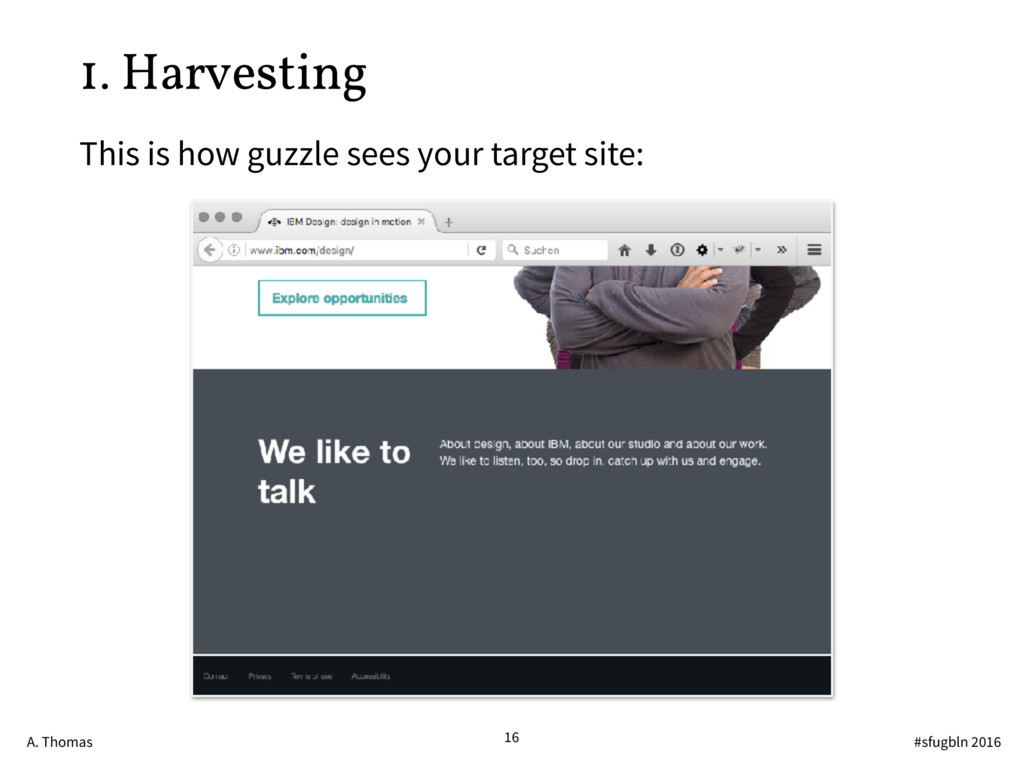{kind=link}
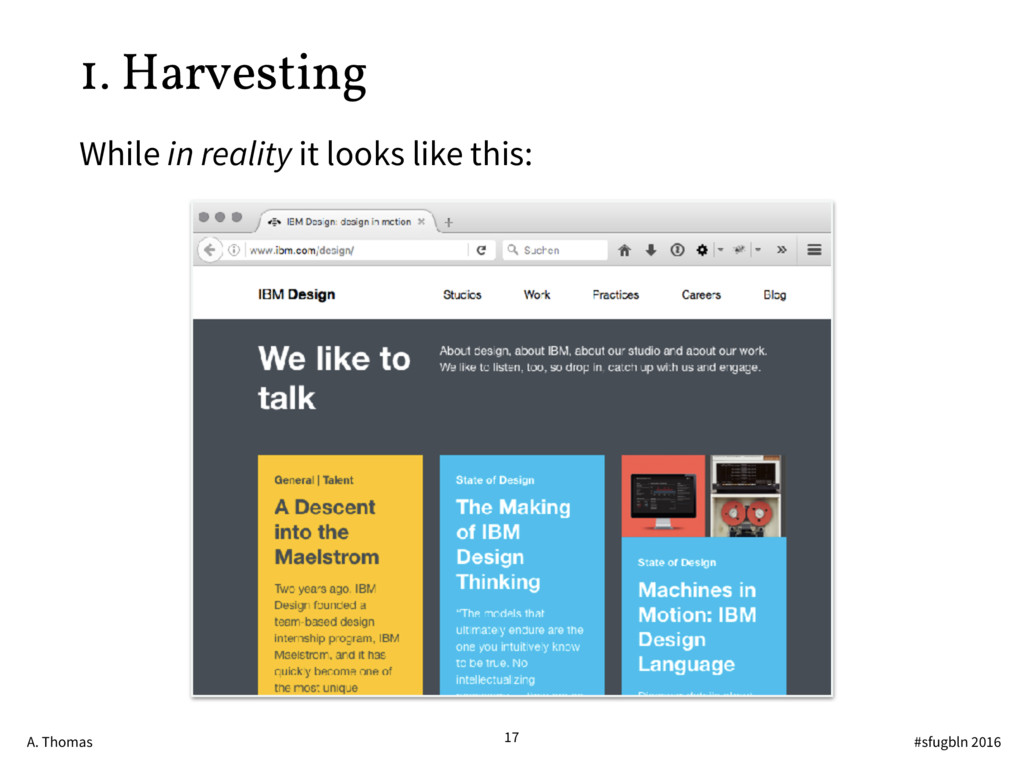{kind=link}
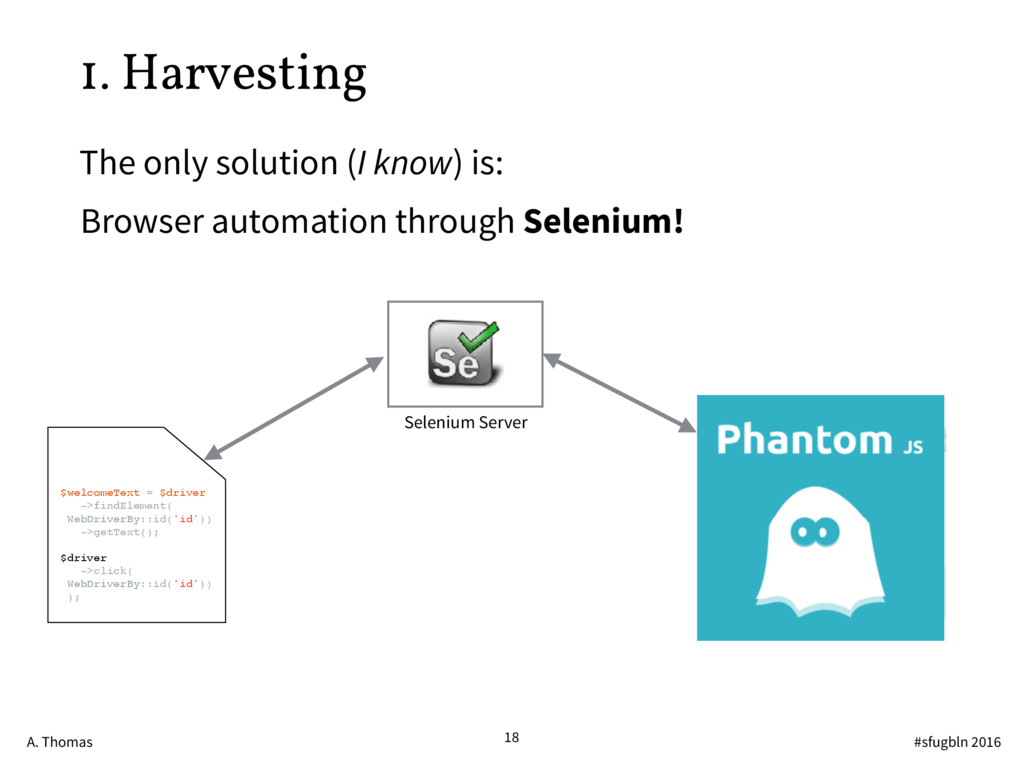{kind=link}
{kind=link}
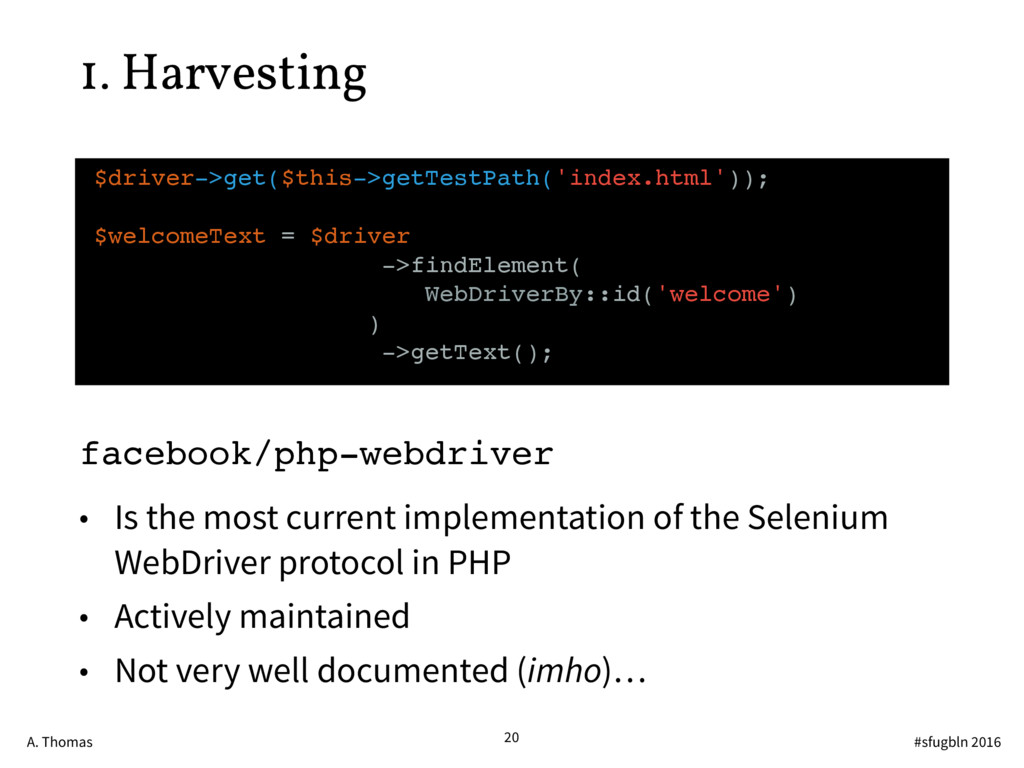{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
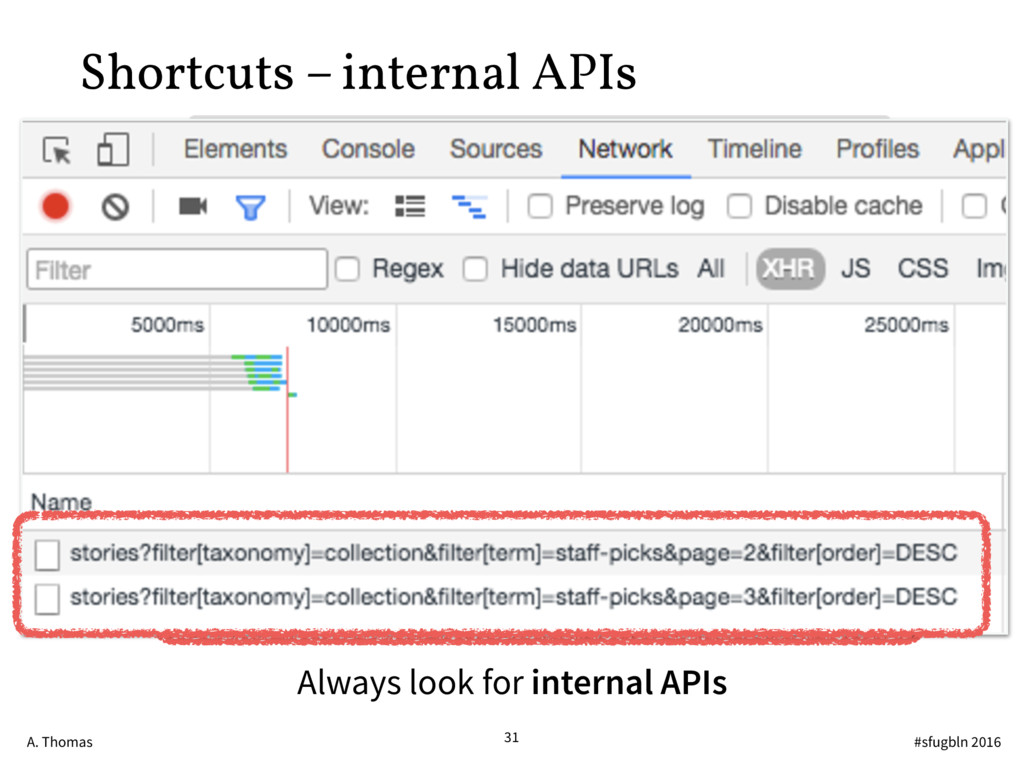
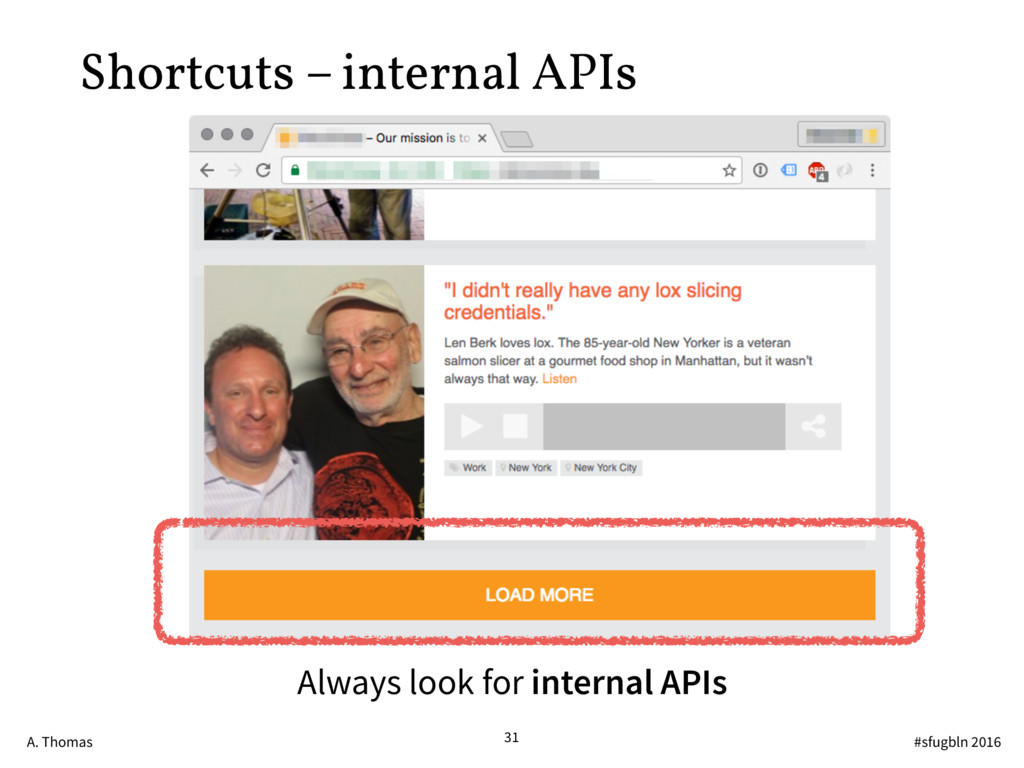{kind=link}
{kind=link}
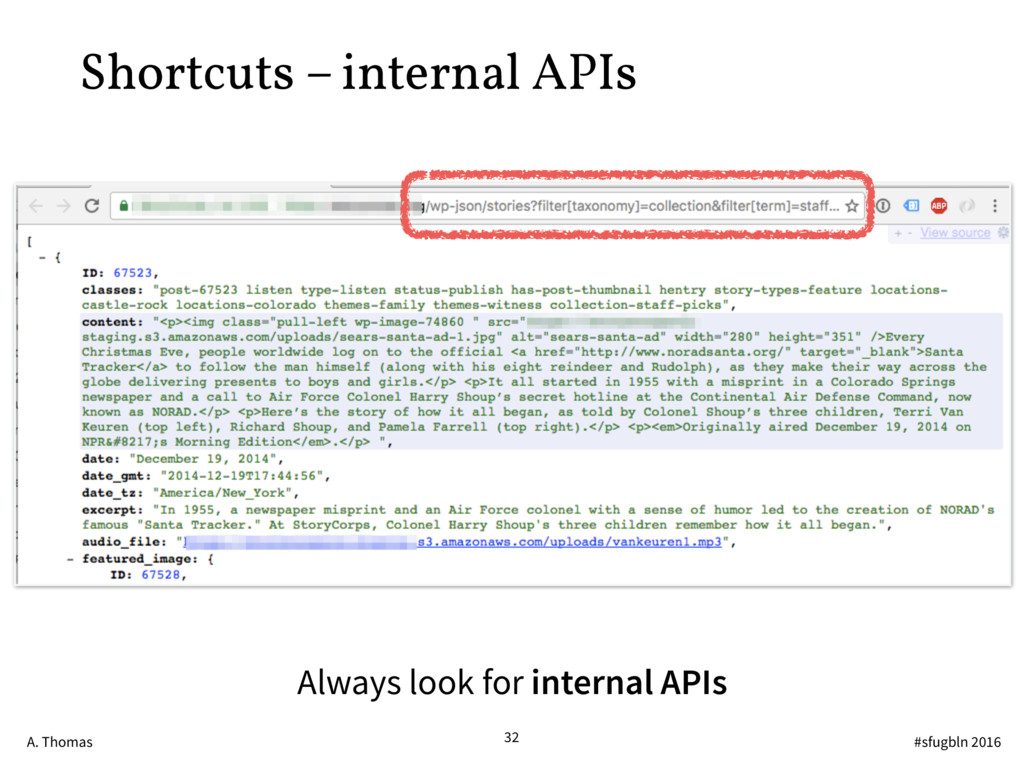{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
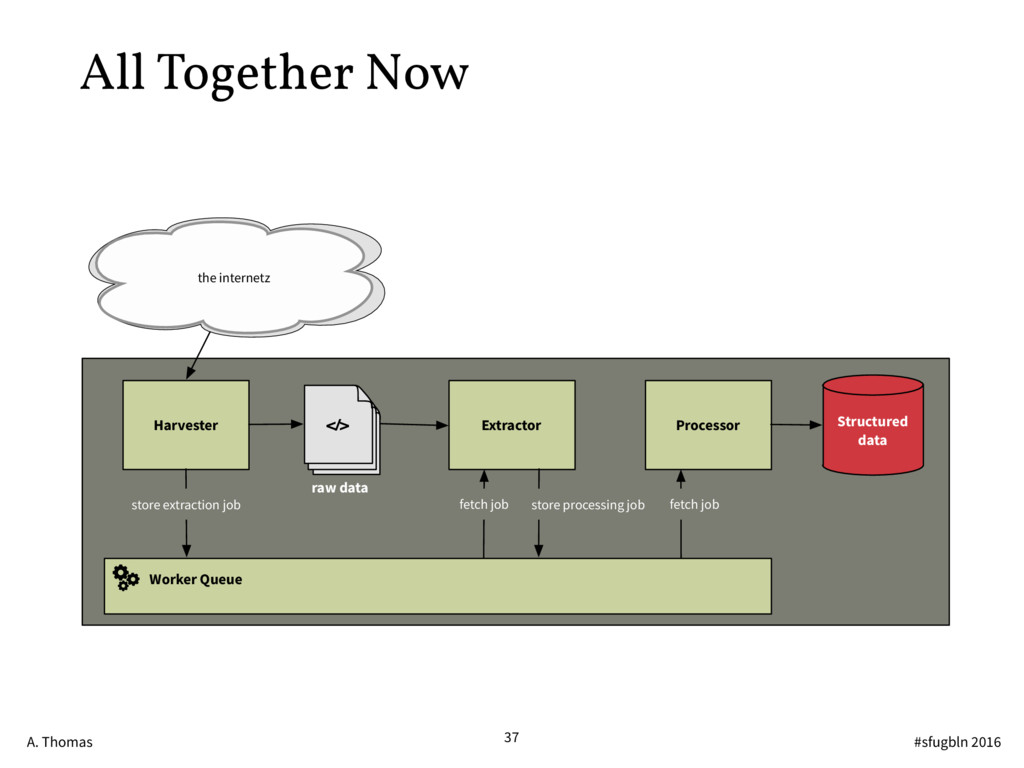{kind=link}
{kind=link}