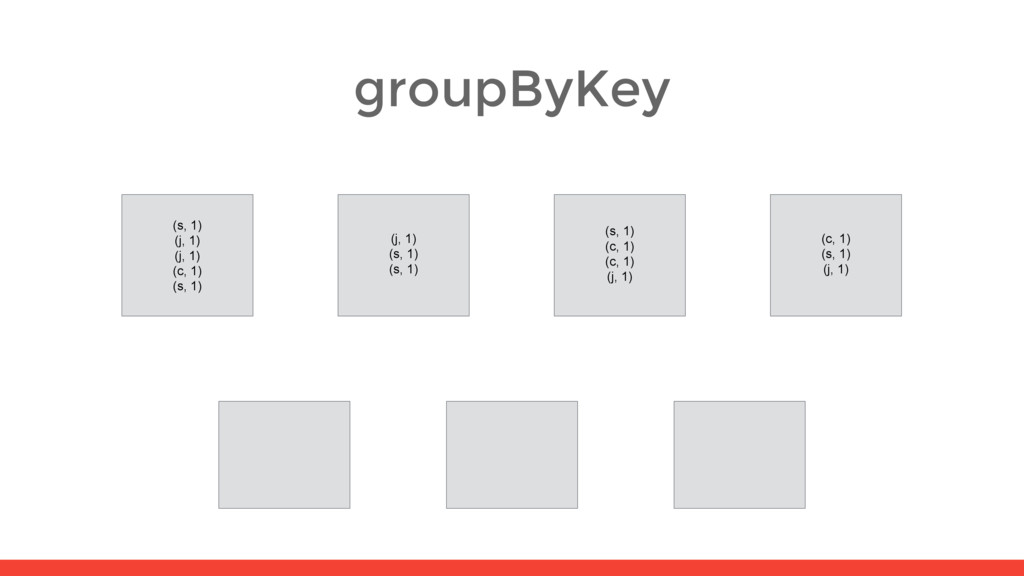
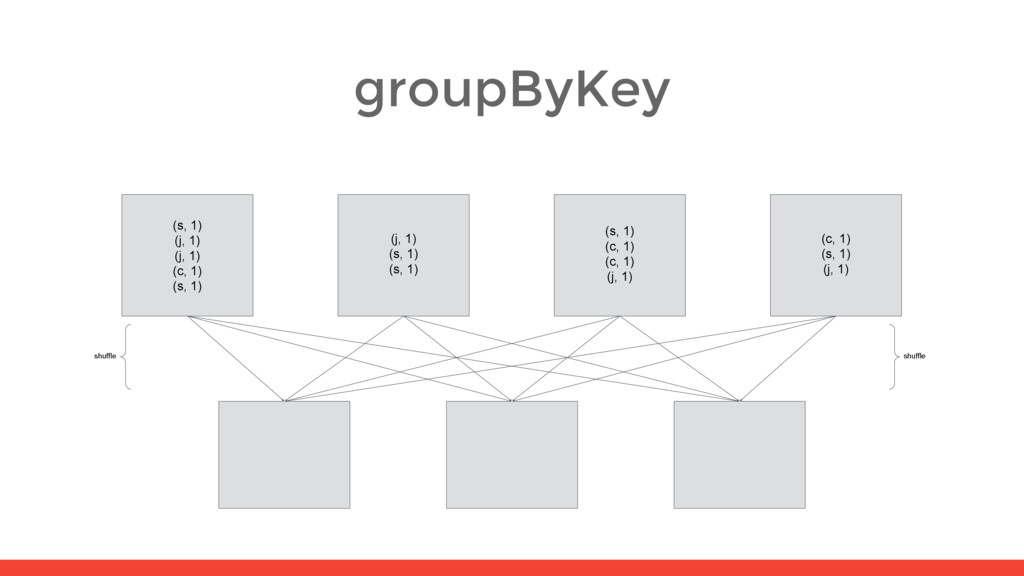
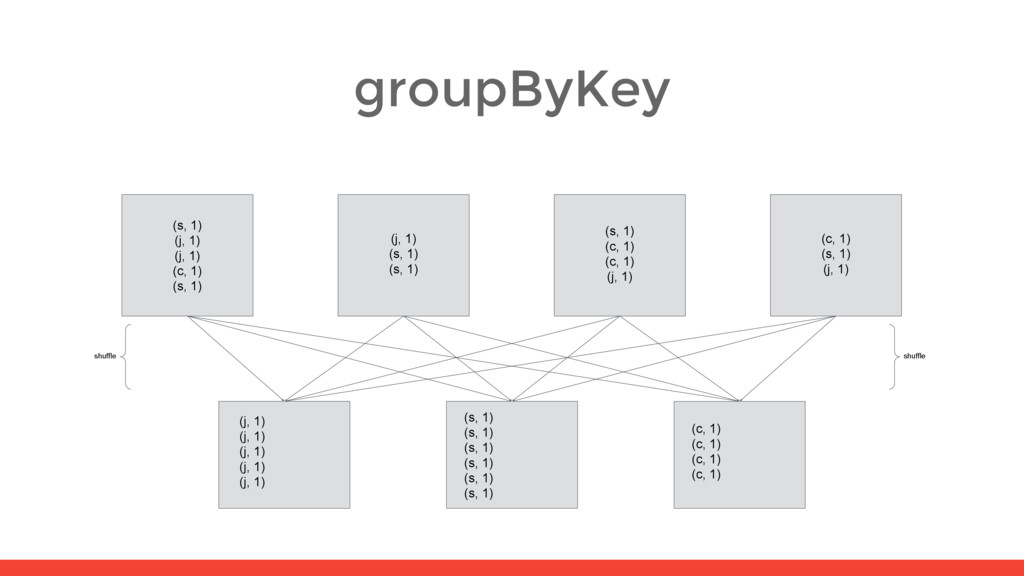
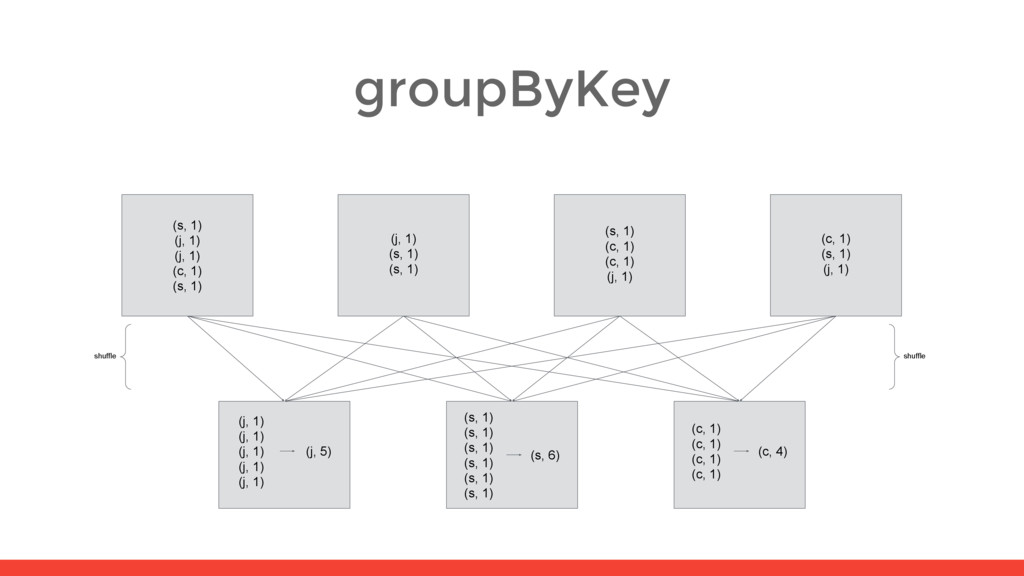
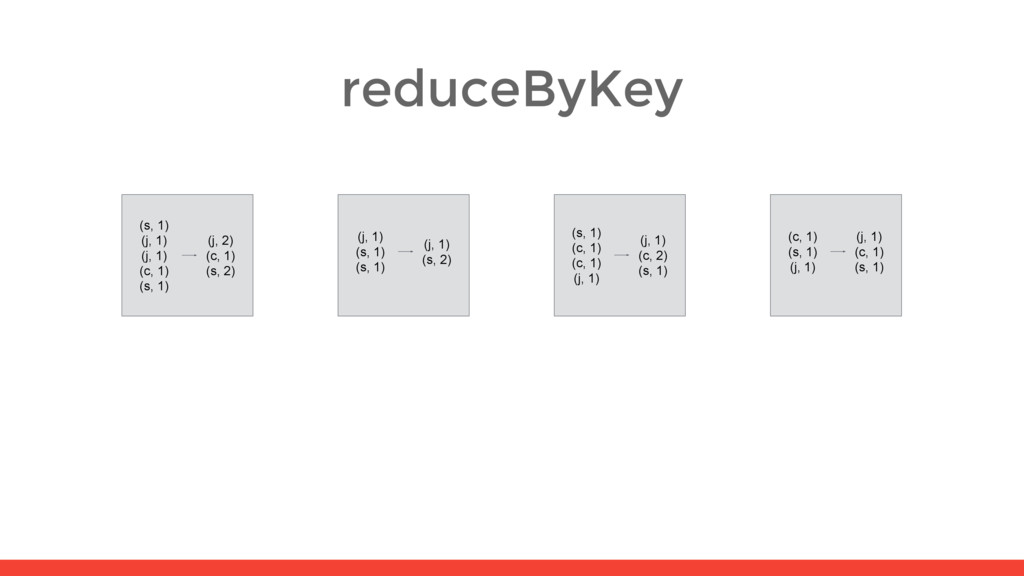
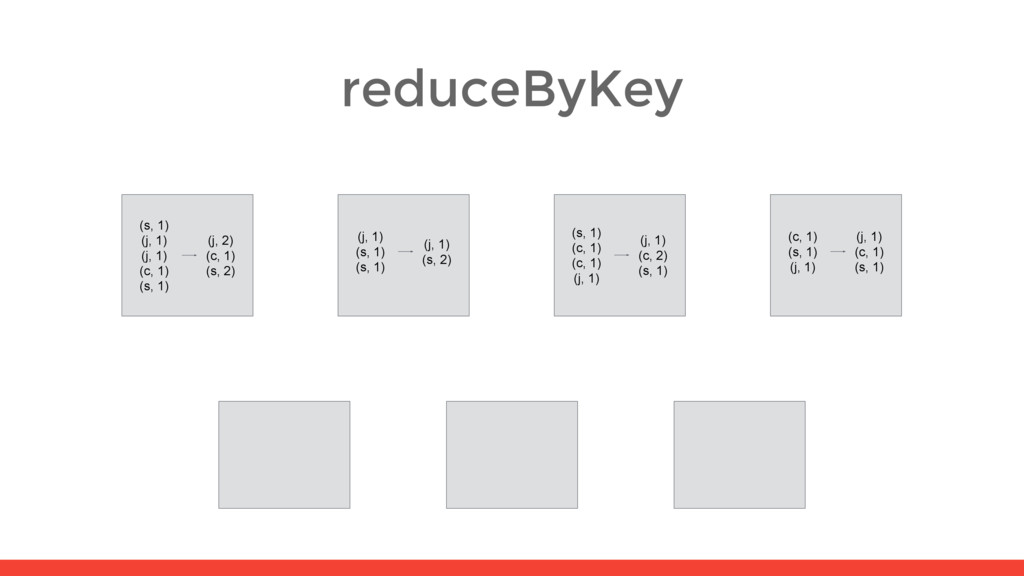
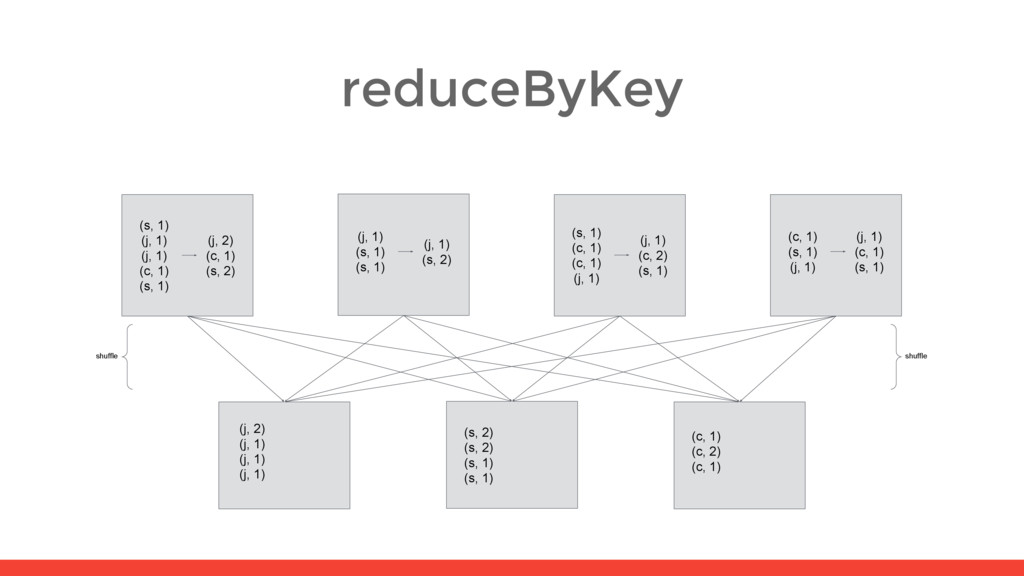
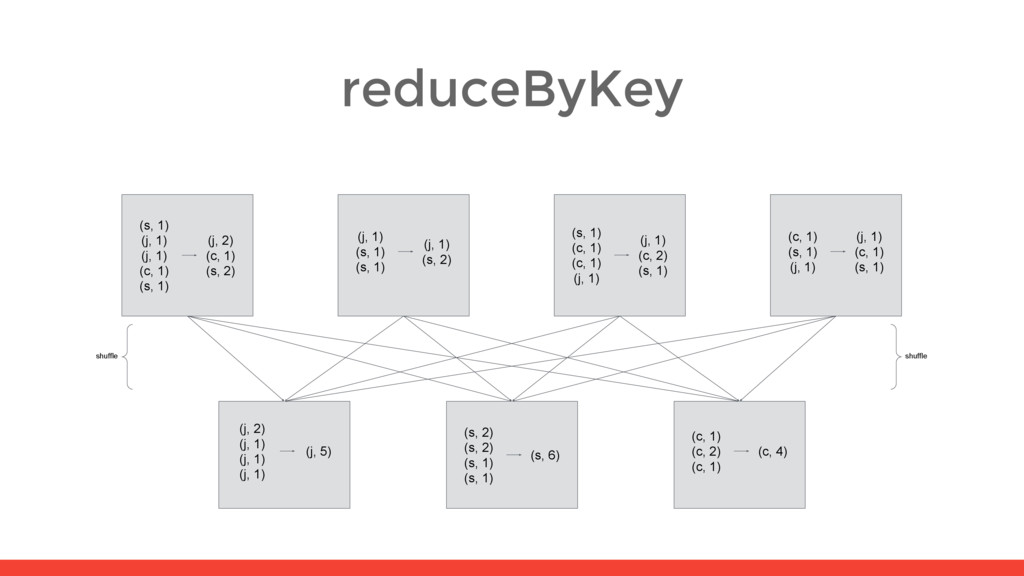
5) (s, 2) (s, 2) (s, 1) (s, 1) (s, 6) (c, 1) (c, 2) (c, 1) (c, 4) (s, 1) (j, 1) (j, 1) (c, 1) (s, 1) (j, 2) (c, 1) (s, 2) (j, 1) (s, 1) (s, 1) (j, 1) (s, 2) (s, 1) (c, 1) (c, 1) (j, 1) (j, 1) (c, 2) (s, 1) (c, 1) (s, 1) (j, 1) (j, 1) (c, 1) (s, 1) shuffle shuffle
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS Fede Fernández @fede_fdz [email protected] Fran Pérez @FPerezP [email protected] Thanks!](https://files.speakerdeck.com/presentations/8fed9e997723418ab5039e7269efbea5/slide_36.jpg){kind=link}