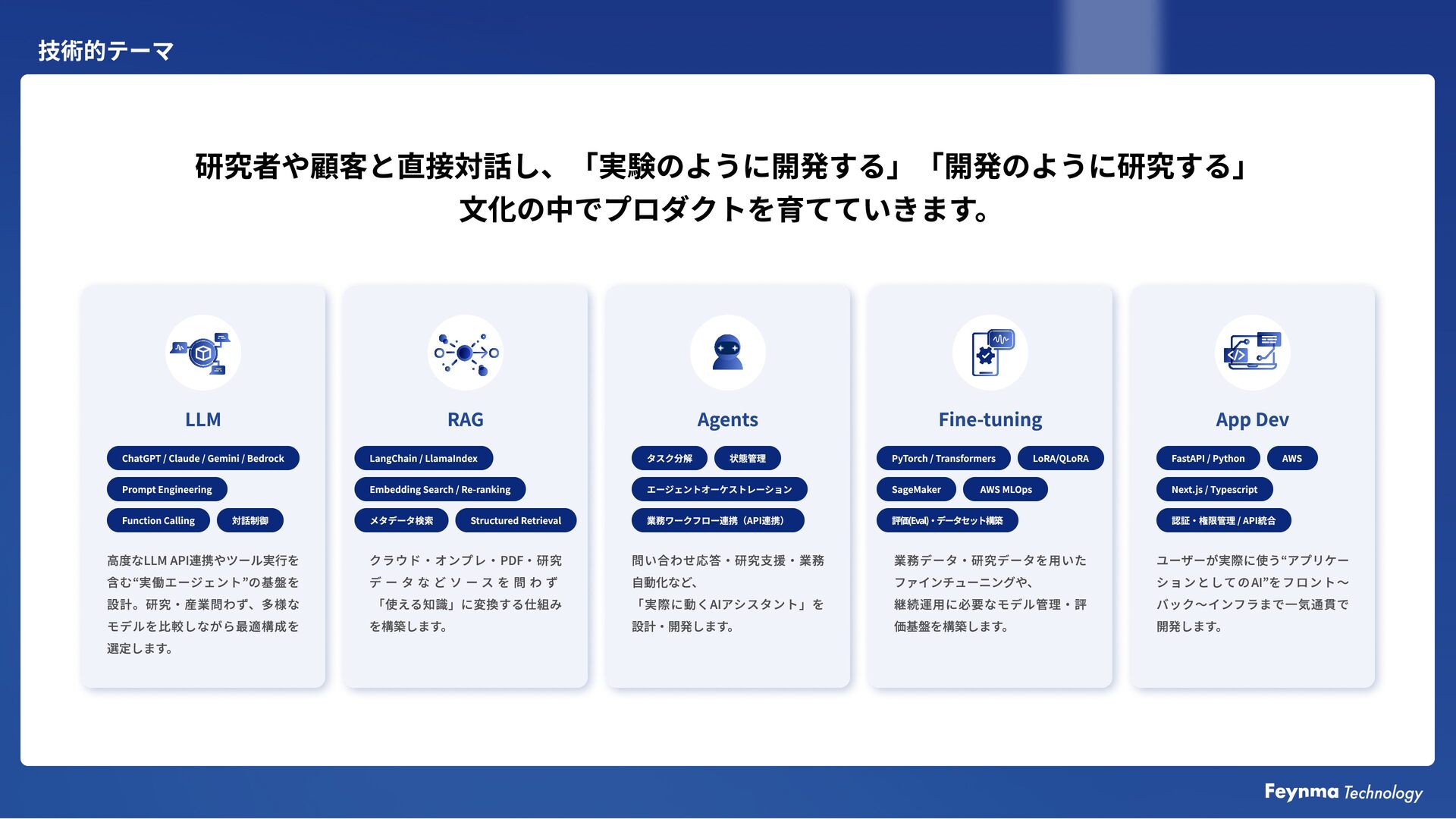
PDF解析 文書構造化 テキスト抽出 図表抽出 PDFをドラッグ&ドロップするだけで、 1分で翻訳結果をWordに出力 Deep Lの翻訳 エンジ ンを ベースに 1paper 独自 の検出 技術で 読みやす い論文を出力 論文に 特化した翻訳 サービス 翻訳 エンジ ン 図 式、テー ブル、段組の 崩れなし 改ペー ジによる文 章の 崩れを 軽減 原文 注釈付きの Word出 力 Inre ce nt year s,se nt ime nta nal ysisha sbe co me a nincrea singl yimporta ntta skinnat ural la ngua ge pro ce ssing(N LP),wit ha ppl icat io nsin f ield ssucha smar ket ing,custo mer ser vice ,a nd pol it icala nal ysis.Ho we ver ,a ccuratel ydete ct ing t he se nt ime ntofa give ntext ca nbe challe nging d uetot he co mplexit ya nd nua nceofla ngua ge. In t hispa per ,we pro po sea no vela pproa chto se nt ime nta nal ysisusingf ine -t unedtra nsfor mer model s,spe cif icall yBERTa ndRoBERTa.We e val uate o ur a pproa ch 近年、 マーケ ティング、カ スタ マーサービ ス、政治 分析な どの 分野で、 感情 分析は 自然言語処理(N LP)において ますます重要なタ スクとなっています。しかし、与 えら れ た テキストの 感情を正確に検出することは、言語の複 雑さやニ ュアン スのた めに 課題となる 場合があります。 本論文では、BERT やRoBERTaなどの ファイン チューニ ング されたト ラン スフォー マーモデルを使用した 感情 分 析の 新しい アプロー チを 提案します。 我々は複 数の ベ ン チマークデータセ ットで 我々の 手法を 評価し、 既存の 最先端の 方法より も優れた 精度を 達成し、 最大で 5% の 精度向上を 示しました。 さらに、トレーニングデータ のサ イズ や前処理 技術などの異なる要 因が、 我々のモ デルの 性能に与 える 影響を 詳細に 分析します。 Word 3.1BERTの事前トレーニング ピーターズらとは異なり。 (2018a)およびRadford etal。 (2018)、 BERTの事前トレーニングに従来の左から右または右から左の言語モデ ルを使用していません。代わりに、このセクションで説明する2つの教 師なしタ スクを使用してBERTを事前トレーニングします。この ステッ プは、 図1の左 側に 示されています。 タ スク #1 :マスク された LM直感的に、 深い 双方向モデルは、左から右 のモデル、または左から右と右から左のモデルの 浅い 連結より も厳密に 強力で あると 考えるの が妥当です。 残念な がら、 標準の 条件付き言語モ デルは、左から右または右から左にしかトレーニングで きません。こ れは、 双方向の 条件付けにより、 各単語 が間接的に 「自分自身を 見る 」こと が で き、モデル が多層でター ゲット 単語を 簡単に 予測で きるた めです。 環境。 の みの バー ジョンは テキスト 生成に使用で きるた め「トランスフォーマーデコーダー」と 呼ばれます 。 1 pa per al. (2018 ), we do not use trad it io nal left -to -r ight or r ight -to -left la ngua ge model s to pre -tra in BERT. Instead , we pre -tra in BERT using t wo unsuper vised ta sks, de scr ibed in t his se ct io n. T his ste p is pre se nted in t he left part of Figure 1. 1 pa per rea so na ble to bel ie ve t hat a dee p bid ire ct io nal model is str ictl y more po werf ul t ha n e it her a left -to -r ight model or t he shallo w co ncate nat io n of a left -tor ight a nd a r ight -to -left model. Unfort unatel y, sta ndard co nd it io nal la ngua ge model s ca n o nl y be tra ined left -to -r ight or r ight -to -left , since bid ire ct io nal co nd it io ning wo uld allo w ea ch word to ind ire ctl y “see it self ”, and the 1 pa per “Tra nsfor mer e ncoder” while t he left -co ntext -o nl y ver sio n is referred to a s a “Tra nsfor mer de coder” since it ca n be used 【p. 4】 Unl ike Peter s et al. (2018a ) a nd Radford et 【p. 4】 Ta sk #1 : Ma sked LM Int uit ivel y, it is 前 者は「トランスフォーマーエンコーダー」と呼ばれることが多く、左側のコンテキスト 【p. 4】 for mer is ofte n referred to a s a 導入企業様
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}