Dann sind wir fertig! Was ist Unsinn? • “Machen Sie es so schnell wie möglich!” – Darf es denn soviel wie möglich kosten? • “Die Maschine kann doch mehr!” – Stimmt, das kann sie immer, aber um welchen Preis? Man braucht also klare Ziele zum Benchmarken!
5 – Spalte idle ist 0 (letzte Spalte rechts)=> 100% Auslastung – mehr geht nicht! – Bei zuviel System Time (Spalte sys): – -> 5. Applikation erzeugt zuviel System Last
prstat -L Thread behindert Prozess • CPU des Threads ist bei ( 100 / Anzahl_CPUs ) % – Klarheit schaffen mit pbind • Thread an CPU binden: – pbind -b cpu cpu/thread
– mpstat 5 Eine CPU ist bei 100% (0% wt + idl) – prstat Prozess nutzt eine CPU: Spalte CPU • Anmerkungen: – Eine CPU entspricht im ps/prstat ( 100 / Anzahl_CPUs ) % – Die Spalten wt im mpstat sagen nichts aus – prstat zeigt die Anzahl der Threads als NLWP – CMT: corestat für Analyse core notwendig
user + system = 100%: – Mehr CPUs einbauen • Schnellere CPUs einbauen (so verfügbar) – Allgemein: kein CPU-Rennen mehr... • Applikation anders Programmieren oder Benutzen – mehr Threads – Applikation mehrfach starten • Daten aufteilen in Teilmengen
Prozesse – psrset (schon seit Solaris 2.6, saubere Separation) • gut ad-hoc nutzbar – Resource Pools mit Prozessorsets (ab Solaris 9) • aufwendiger als psrset, gut für dauerhafte Nutzung – Fixed Priority Scheduler (ab Solaris 9) • ~ Real-Time Scheduler Features ohne die Gefahren! – pbind (aber kein Ausschluß → nicht benutzen) – Modifizieren der Scheduling Tabellen (gefährlich)
zeigt: die Spalten free und sr(meist verrutscht) • swap: freier virtueller Speicher in KByte • free: freier realer Speicher in Kbyte (~1/32 muss immer frei sein (minfree)) • sr: scan rate (dauernd > 0 bei Speichernotstand) in 8k-Seiten/Sekunde Suche nach Seiten zum Freigeben Nur noch bei Programmstarts > 0 z.B. DB Start (Ab S8) Sonst: Maschine hat zuwenig Real-Speicher!
I/O zu Dateien – Wenn das Programm mmap benutzt: eigenes Segment – Alles andere: mapping via Segment segmap im OS – Default für segmap ist 12 % • z.B. Bei 64 GB Hauptspeicher fast 8 GB! – Einstellung in /etc/system (Wert in Prozent) – Segmap größer • bei File-Server • Programme mit vielen Dateien • Nur bei UFS, PCFS, HSFS, nicht bei ZFS
ARC – Einen anderen als UFS! – ARC – Adaptive Replacement Cache • Passt sich automatisch an die Nutzung der Daten an • Unterscheidet Daten: einmal gelesen, häufig gelesen • Einmal gelesene Daten stören nicht das Caching der häufig gelesenen Daten • ARC Cache Default ist 75% des Hauptspeichers – Automatische Anpassung an verfügbaren Speicher – “Kampf” zwischen ARC und Applikationen – Reduktion z.B.: set zfs_arc_max=0x78000000 (Bytes)
5' zeigt nach Plattennamen sortiert: • read und write pro Sekunde (zusammen: I/O / Sek) • read KB und write KB: Datenrate • asvc_t: average Service time in Millisekunden – <= 20 ist optimal, 2-5 ist super, 0-1 ist SSD – länger ist ok, wenn User zufrieden
wieviel Prozent der Zeit die Platte beschäftigt war (mindestens 1 I/O aktiv). Das sagt gar nichts aus! Multiple I/Os pro Platte sind möglich (tags)! (ausser bei IDE Platten) – wait: IO kann nicht an Platte übertragen werden • Limit der Platte erreicht • max_throttle (/etc/system) erreicht
Strecken – Erhöht die Antwortzeit, z.T. extrem • Summation des Datenverkehrs für Controller – iostat -Cxn 5 • Analyse IO pro Disk Slice – iostat -xznp 5
Zuordnung zur Applikation • Statistik über die Größe von read/write • welche Applikation verursacht I/O auf – einer Platte – allen Platten mit Statistik • Summarische Daten bereits ab Solaris 8 mit kstat – Zahlen werden pro Platte / Partition aufsummiert – iostat nutzt dieses Interface – was gibts?: kstat -c disk • Umsetzung sd Nummern in Plattennamen: /etc/path_to_inst
zu sehen – netstat -I ge0 5 • zeigt die Zahl der Pakete auf Interface ge0 – kstat -p -c net 5 • plus Auswertescript zeigt alles • z.B.: ifstat (Basis ist kstat)
Crossbow Flows (S11...) – mehr Netzwerk Interfaces – Behebung von ungünstiger Programmierung in der Applikation – Trunking hilft nur bei 1:n – 10 GBit Ethernet (demnächst 40Gbit) – Infiniband
Das OS synchronisiert mit locks viele Dinge. – spinning mutex: Warten auf das lock • da es sich nicht lohnt den Prozess zu suspendieren • man sowieso gleich drankommt (hoffentlich) – zu häufig: spinning mutex Werte sind hoch
'mpstat 5' in der Spalte smtx – US-III bis 8000-12000 smtx pro CPU – US-IV bis 20000 pro CPU – SPARC-64: 50000 - 60000 – dann Systemcalls und Applikation langsamer – Applikation synchronisiert zuviel • Handshake mit zu kleinen Daten-Elementen(Byte für Byte...) • zu kleine Netzwerk-Pakete • ggf. in Konfig-Datei einstellbar – dtrace (ab Solaris 10)
im mpstat Spalte syscl • Anzahl der Systemcalls pro Sekunde (diese CPU) • Zuordnung zur Applikation • dtrace (ab Solaris 10) • truss – Prozess muß bekannt sein – kann Performance beeinträchtigen – besser: truss -c -p <pid> • Behebung nur durch Änderung der Applikation
einem anderen Prozessor noch bearbeitet werden – schlechte Applikation – Backup von Dataspace einer Datenbank • Summarisch: mpstat Spalte xcal • Zuordnung zur Applikation: dtrace • Behebung: • Überarbeitung Betriebskonzept
'truss -p <pid>' • untersucht die Systemaufrufe von Applikationen. – Kenntnisse der Unix Systemcalls sind erforderlich – Fehlverhalten von Programmen entdeckbar (keine Garantie!) – optimalere Einstellung der Volumes oder des OS möglich
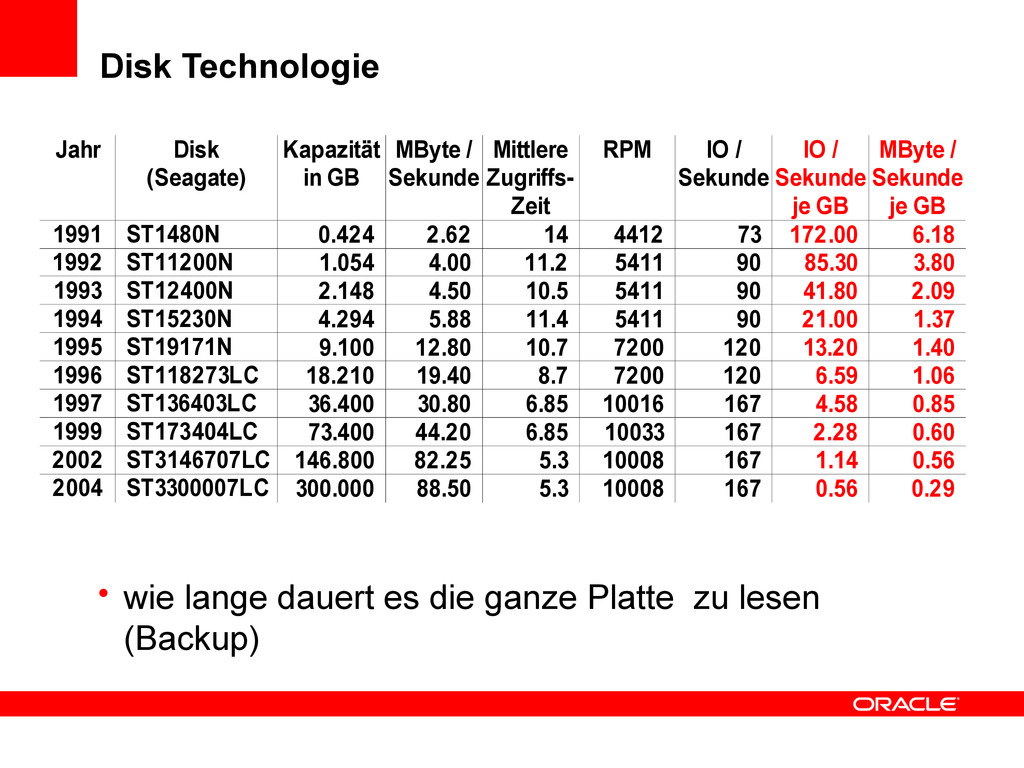
2 TB: – 7200 RPM=> 120 Umdrehungen pro Sekunde=> 120 Positionierungen (ohne I/O)< 120 IOs – In der Regel: 60-80 realistische IOs – Beispiel • NFS Service mit 150000 random reads pro Minute – 2500 IOs pro Sekunde – => 2500 / 60 ~ 42 Platten mindestens!Eher mehr um bessere Latency zu bekommen ( x 2 ! ) • Der Cache hilft, nur – Er muss gross genug sein – Er muss gefüllt sein (kann dauern)
– Wie Cache bei HDS/EMC • Mit logbias=throughput besser bei ganz vielen Platten • ZFS sammelt random writes – Schreibt mit wenigen sequential writes – In Beispielkonfigurationen: 4-fache IO (random write)
anpassen – Mit Datenbanken: besser Cache der Datenbank erhöhen • Sequential read, wenn sequentiell gelesen: ok • Random writes => Logzilla hilft mit ZFS • Sonderfall: random schreiben, sequentiell lesen – Prefetch im ZFS hilft (genug IOs notwendig) – Bei Datenbanken: Anpassung der Queries – Danke!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}