Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Solr für Volltext-Suche oder gleich als Datenba...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Frank Neff
October 30, 2014
Programming
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Solr für Volltext-Suche oder gleich als Datenbank Engine
Slides zum Talk an der Symfony Live Konferenz in Berlin 2014
Frank Neff
October 30, 2014
More Decks by Frank Neff
See All by Frank Neff
Principles of Object Orientation
frne
0
360
Symfony High Availability in the Cloud
frne
0
630
Symfony 3 [german]
frne
0
430
Exception Handling in PHP
frne
2
140
Plaing with Neo4j -[:USING]-> PHP
frne
0
470
PHP under the hood
frne
3
220
Other Decks in Programming
See All in Programming
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
190
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
100
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
8.9k
Claude Team Plan導入・ガイド
tk3fftk
0
180
初めてのKubernetes 本番運用でハマった話
oku053
0
120
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
480
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
3.5k
symfony/aiとlaravel/boost
77web
0
120
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.8k
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
390
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
170
Signal Forms: Details & Live Coding @enterJS 2026 in Mannheim
manfredsteyer
PRO
0
230
Featured
See All Featured
How to Ace a Technical Interview
jacobian
281
24k
WENDY [Excerpt]
tessaabrams
11
38k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Being A Developer After 40
akosma
91
590k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
280
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Transcript
Solr für Volltext-Suche oder gleich als Datenbank Engine Frank Neff
Symfony Live Berlin 2014 #sfLiveSolr
Über mich Frank Neff ▪ Software Engineer @ YMC AG
▪ Lebt in Zurich, Schweiz ▪ Codet PHP und Java ▪ Student ▪ Open Source Enthusiast ▪ Multicopter Drohne Pilot ▪ Hobby-Fotograf ▪ frankneff.ch ▪ ymc.ch
None
Open Source Switzerland Agile Since 2001 Conferences International Software solutions
Best of swiss web Über YMC
Mehr Daten...
...langsame Suche
“If all you have is a hammer, everything looks like
a nail” - Abraham Maslow
None
• Such-Server (Reverse Index) • Basiert auf Apache Lucene •
Standalone oder Cluster • Skalierbar • Unterstützt diverse Formate • Stemmer, Stopwords, Facettierung • Gewichtung von Feldern
“Solr wird mit mehr Daten nicht markant langsamer...”
Funktionsweise Solr Index
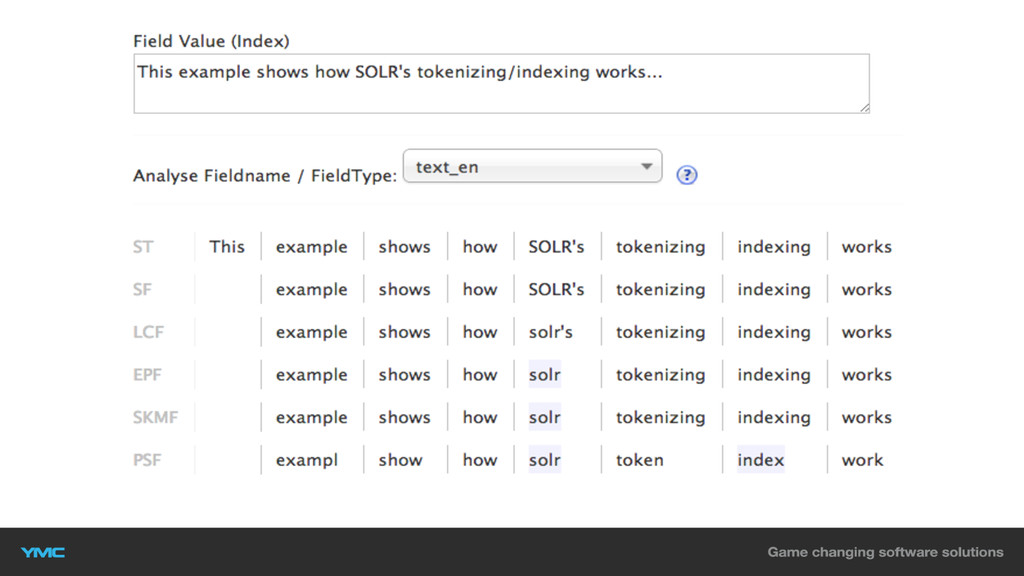
Textfeld: “This example shows how SOLR's tokenizing/indexing works…” Such-String: “How-To
Solr tokenization” Beispiel Indexierung
None
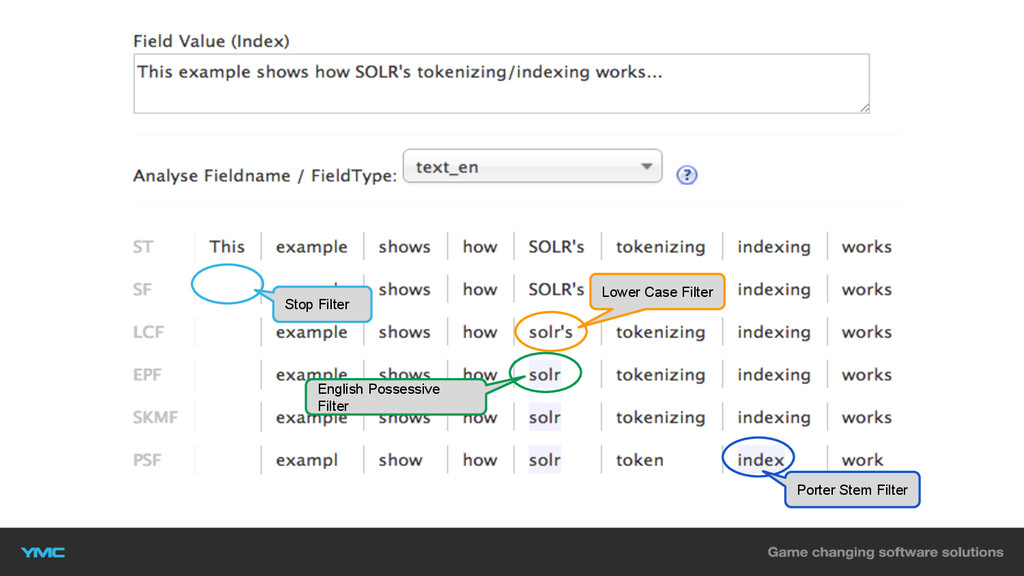
Stop Filter Lower Case Filter English Possessive Filter Porter Stem
Filter
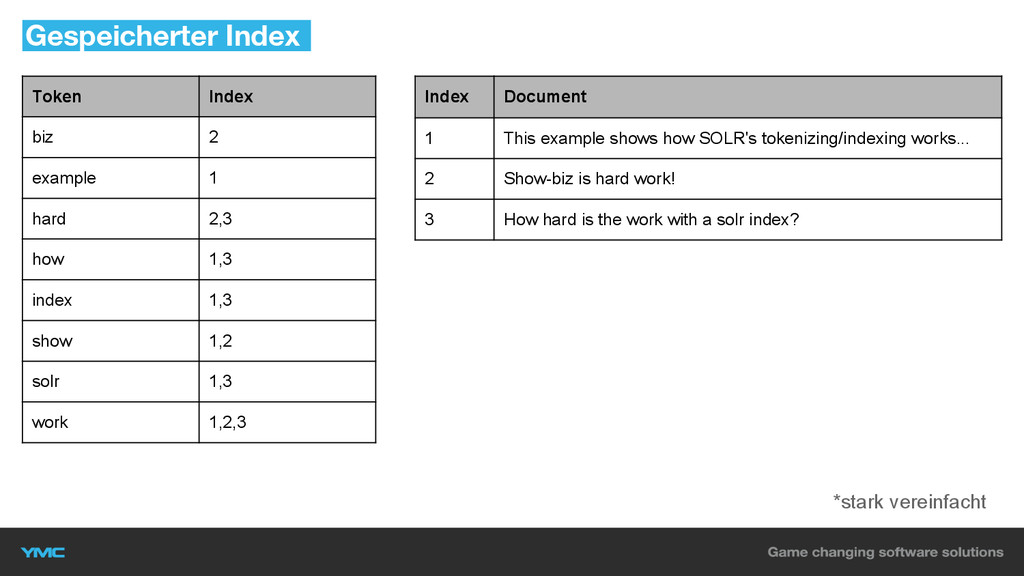
Gespeicherter Index Token Index biz 2 example 1 hard 2,3
how 1,3 index 1,3 show 1,2 solr 1,3 work 1,2,3 Index Document 1 This example shows how SOLR's tokenizing/indexing works... 2 Show-biz is hard work! 3 How hard is the work with a solr index? *stark vereinfacht
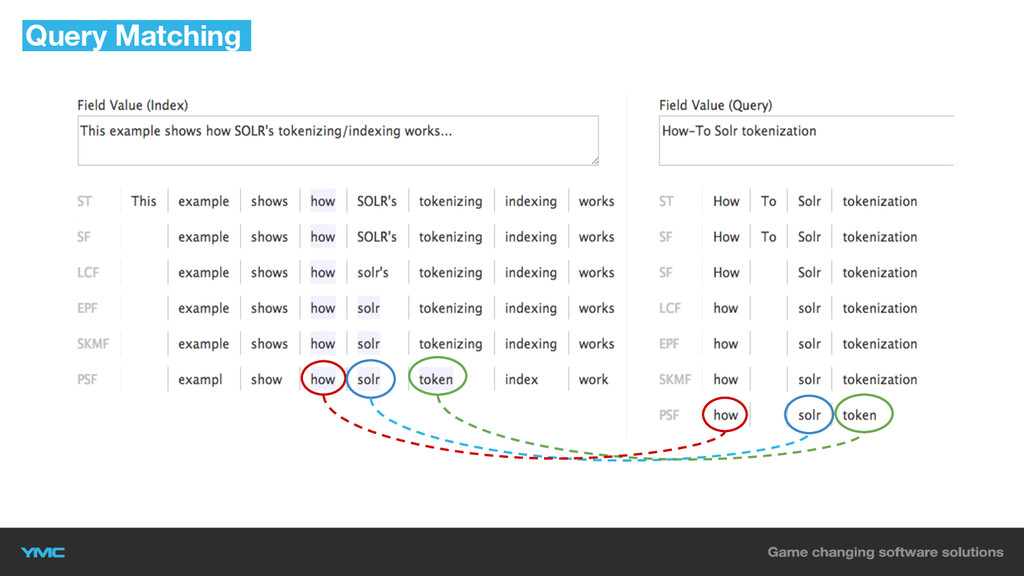
Query Matching
▪ ~500’000 Wörter (Duden) ▪ = max. Index-Tokens ▪ Wachstum
des Indexes verringert sich / bleibt konstant ▪ Suche wird nicht langsamer Anzahl Artikel Index Grösse Index Grösse
in PHP Integration
▪ Grundlegende C-Extension für Indexierung und Abfrage ▪ http://pecl.php.net/package/solr ▪
http://php.net/manual/de/book.solr.php pecl/php_solr
▪ Feature-Complete Solr Library ◦ Geschrieben in PHP ◦ Facet
support ◦ Query building API ◦ Plugin system ◦ DisMax support ▪ http://www.solarium-project.org/ Solarium
Solarium Beispiel
Symfony 2 Konzepte in
▪ Volltextsuche ▪ MySQL entlasten ▪ Document Store ▪ Polyglot-Persistence?
Einsatzmöglichkeiten in Symfony 2
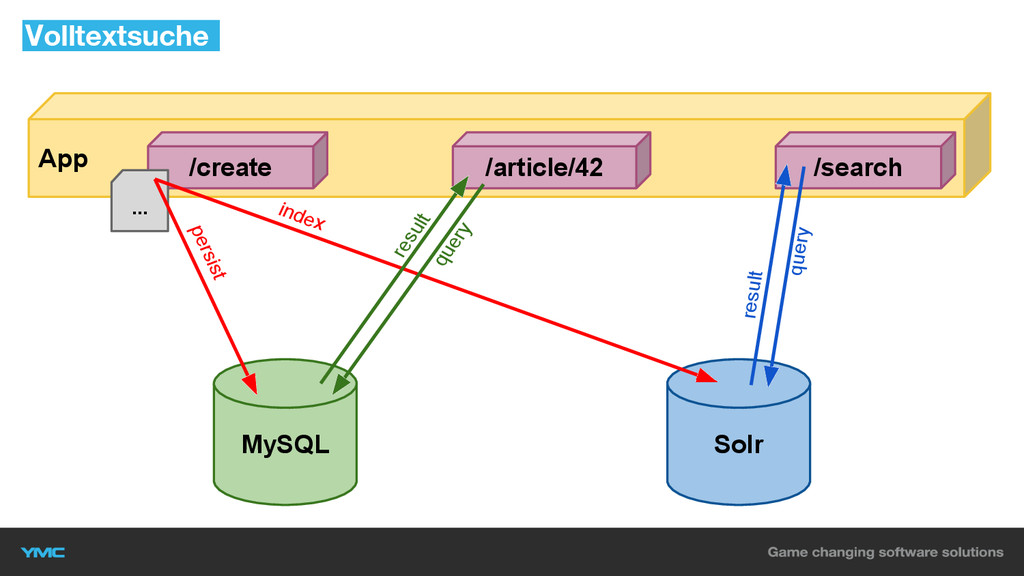
Volltextsuche
Volltextsuche MySQL Solr App index persist /search query /create ...
/article/42 result query result
▪ Solr NRT-Search verwenden ▪ Indexierung “onPostPersist” ▪ Komplexe Queries
▪ Keine Datenbank-Last Volltextsuche
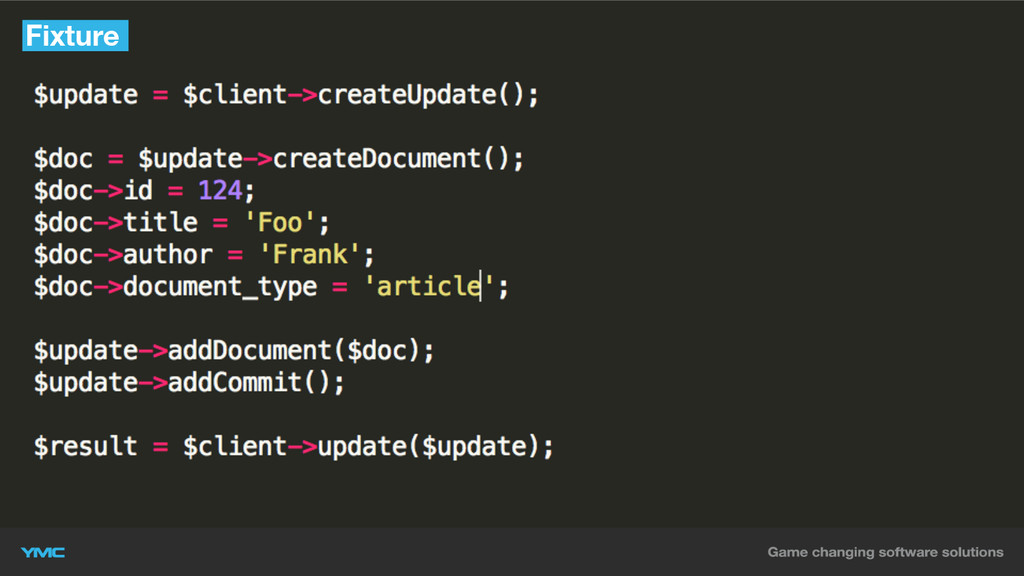
Fixture
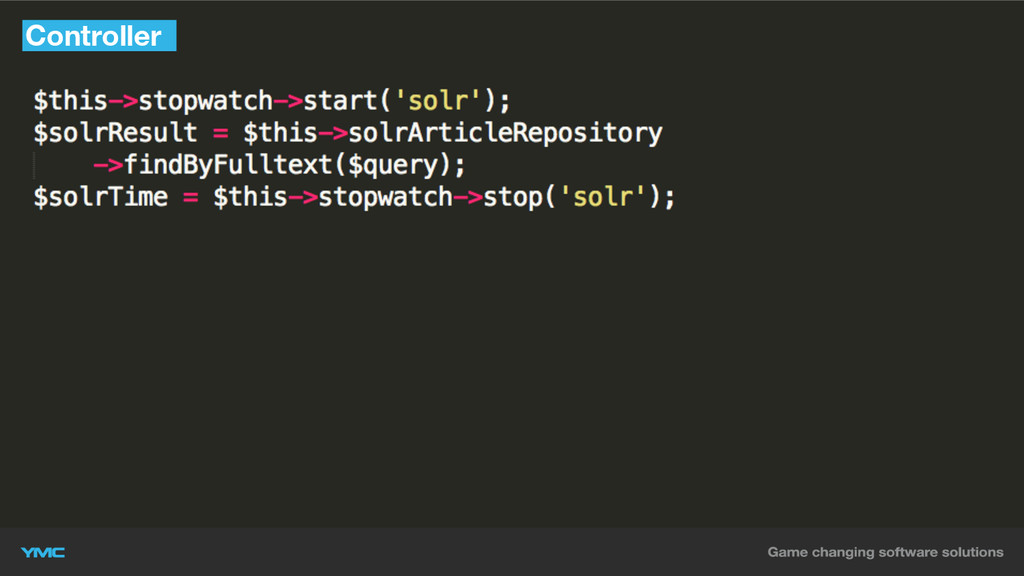
Controller
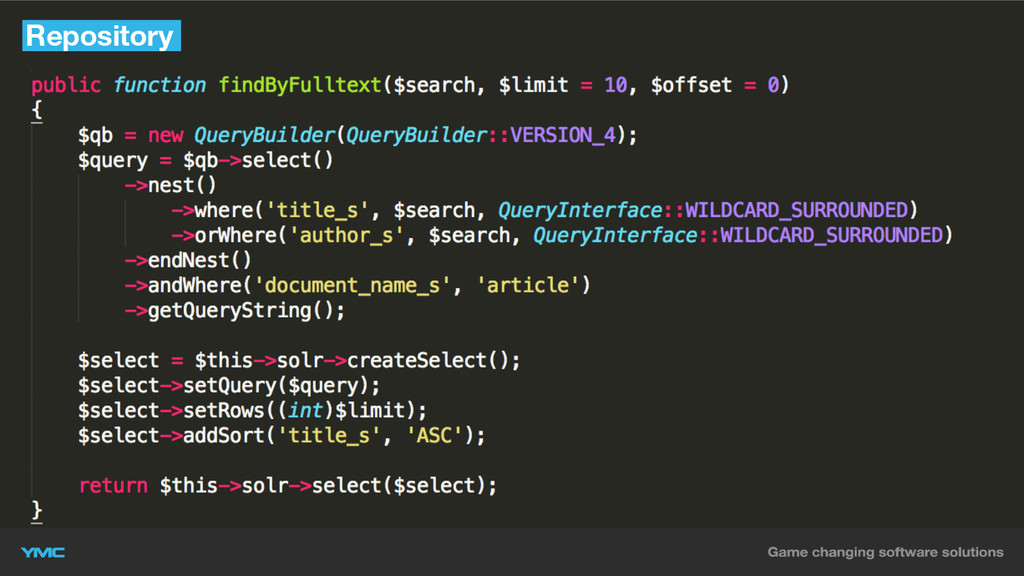
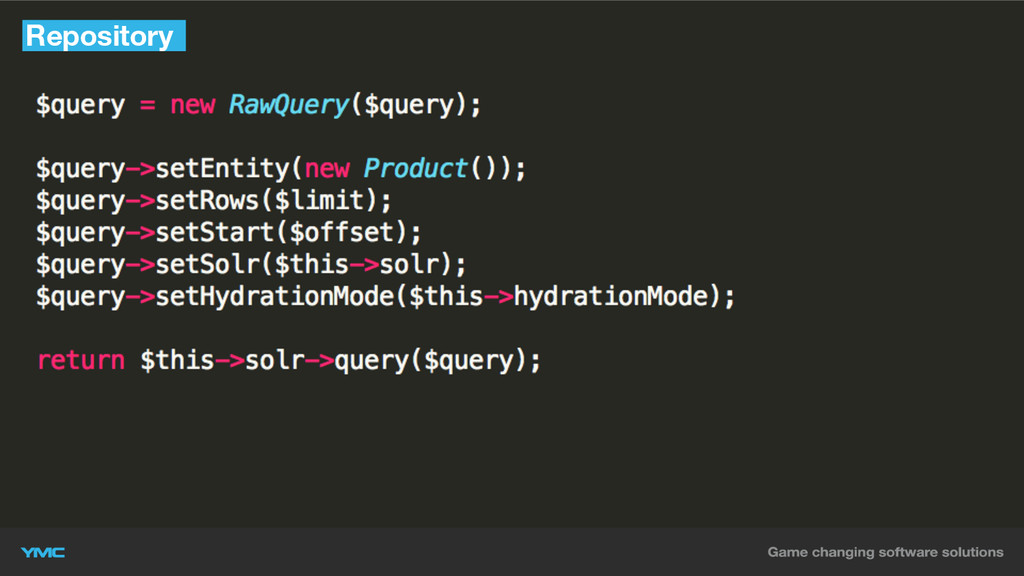
Repository
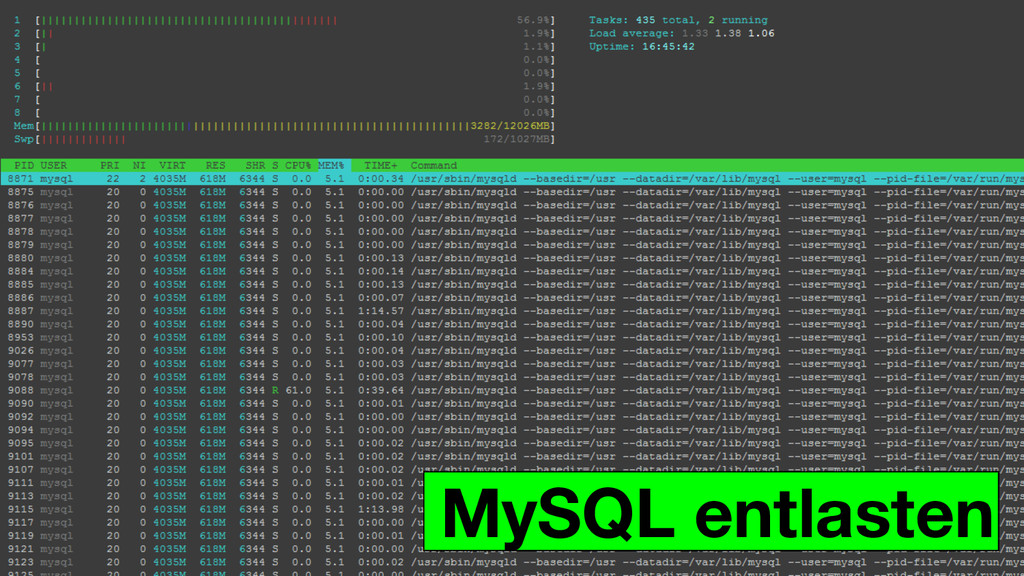
MySQL entlasten
MySQL entlasten Copying to tmp table… ☠ ☠ ☠
MySQL entlasten MySQL Solr App index persist related articles query
/create ... /article/42 result article content query result
▪ Komplexe Queries ▪ Operationen die “Full-Table-Scans” auslösen ▪ Between
Abfragen ▪ Geo-Koordinaten ▪ Sortierte Listen ▪ Keine Datenbank-Last MySQL entlasten
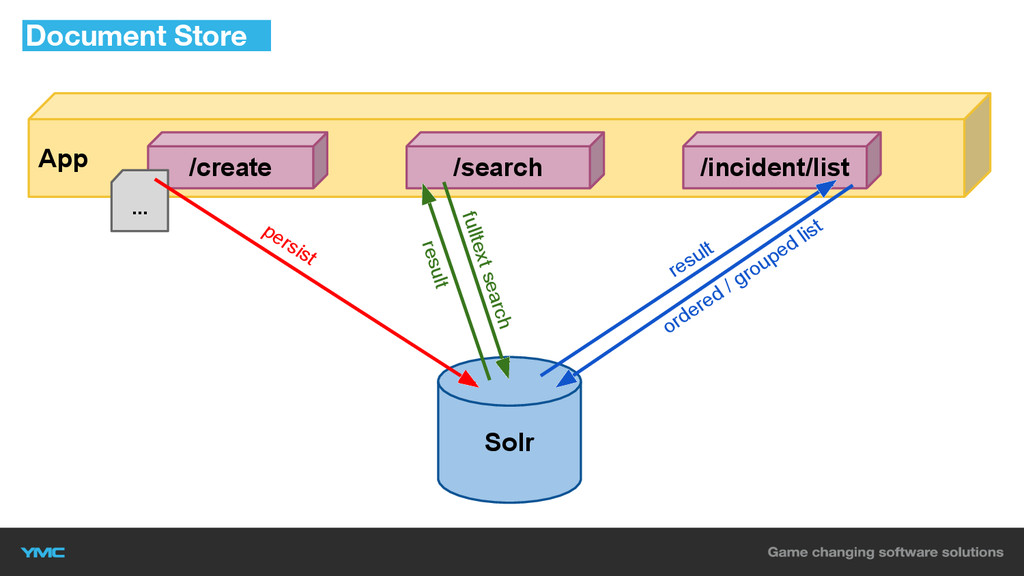
Document Store
Document Store Solr App persist ordered / grouped list /create
... /incident/list result /search fulltext search result
▪ nelmio/solarium-bundle ▪ Schnelle Abfragen ▪ Sortierte Listen ▪ Volltextsuche
“out of the box” ▪ Geeignet für grosse Dokumentarchive ▪ Keine Relationen Document Store
Keine Relationen?
▪ Solr ist kein RDBMS! ▪ Hält viele Daten, unterstützt
aber keine Strukturen ▪ Optionen ◦ Denormalisierung ◦ Object-Hydration (bspw. über Doctrine ORM) ◦ Polyglot-Persistence Relationen
Object-Hydration MySQL Solr App persist /create /article/42 article User Artikel
user by article index [hydrator] query result article + user
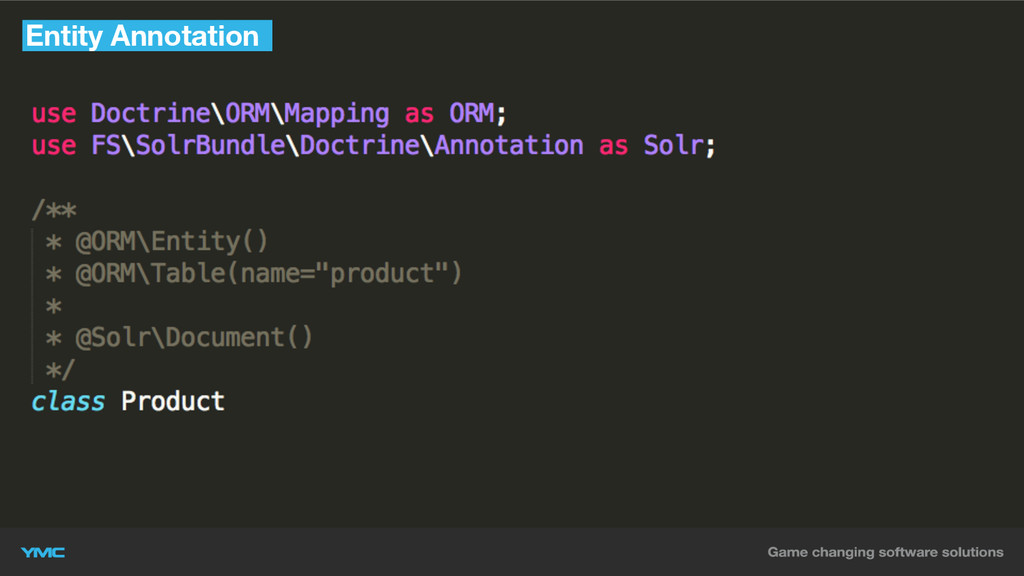
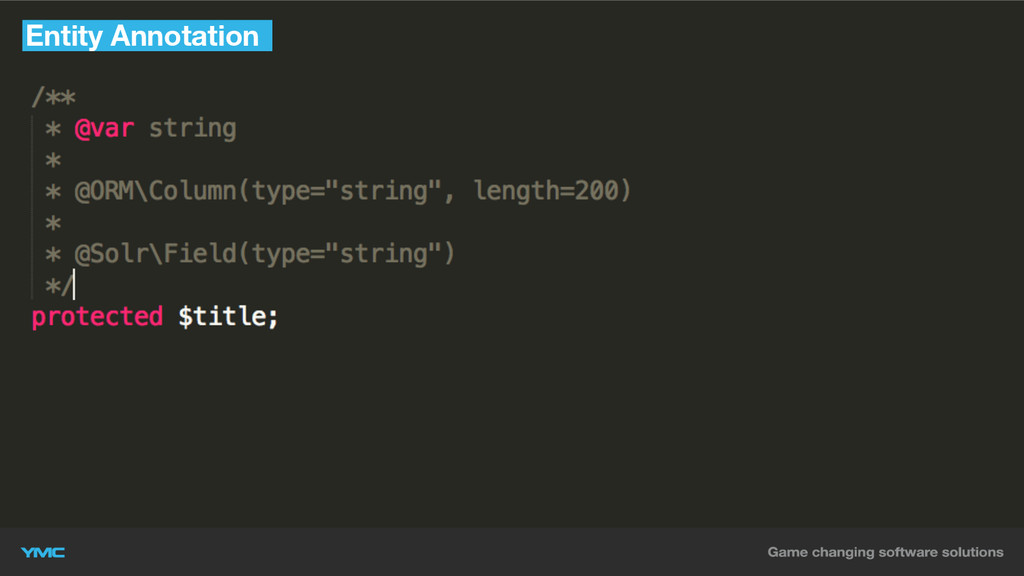
▪ floriansemm/solr-bundle ▪ Hydration über Solr-Index oder RDBMS ▪ Entity
Annotation Support ▪ Indexierung anhand von Doctrine-Events ▪ Unterstützt Doctrine ORM/ODM Object-Hydration
Entity Annotation
Entity Annotation
Entity Annotation
Repository
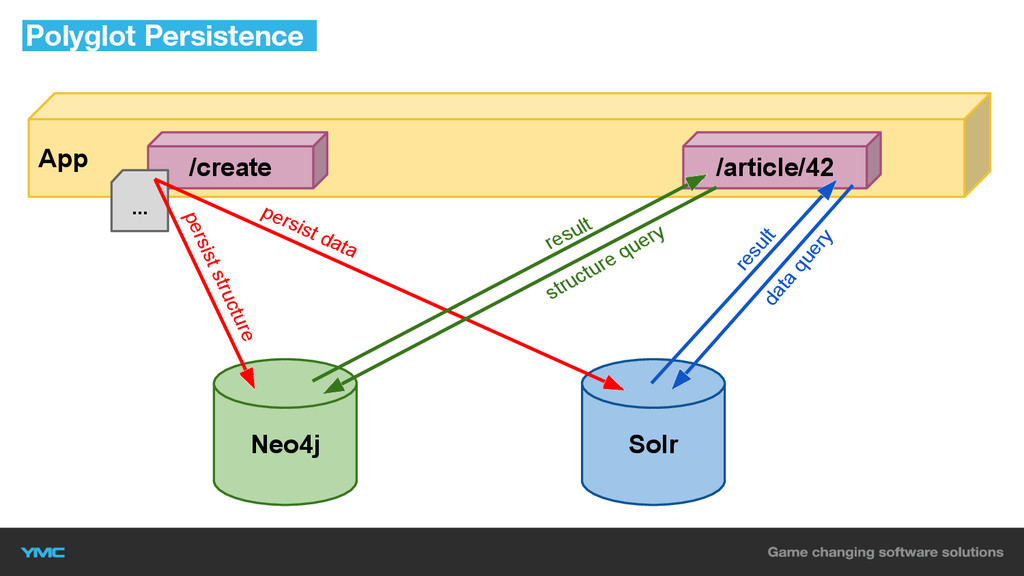
Polyglot Persistence
Polyglot Persistence Neo4j Solr App persist data persist structure data
query /create ... /article/42 result structure query result
▪ Trennung von Daten und Struktur ▪ Synchronisierung auf Business-Logik
Level ▪ Noch kein OSS-Bundle Polyglot Persistence
Query Language The Lucene
"A search string" Simple Query Query all Fields
title:"The Right Way" AND text:go Fields Field Name
title:"te?t" AND text:*test* Wildcard search Single Character Wildcard String
text:roam~0.8 Fuzzy search Levenshtein Distance
text:"solr apache"~10 Proximity search Word Distance
mod_date:[20020101 TO 20030101] Numeric Range
title:{Aida TO Carmen} String Range
text:"solr^4 apache" Term boosting Boost Factor
"Apache Solr" NOT "Webserver" Exclusion Exclude Result
(nginx OR apache) AND webserver Grouping
coole Features Noch mehr
▪ Cluster-Betrieb ▪ High Availability ▪ Fault Tolerance ▪ Konfigurationsmanagement
mit Zookeeper ▪ Benötigt Solr 4 ▪ cwiki.apache.org/confluence/x/ioDxAQ Solr Cloud
▪ Eingrenzung von Resultaten anhand verschiedener Filter ▪ A.k.a Explorative
Suche ▪ Benutzer kann Filter selbst wählen und verknüpfen ▪ wiki.apache.org/solr/SolrFacetingOverview Faceting
▪ nelmio/NelmioSolariumBundle ▪ floriansemm/SolrBundle ▪ swiss-php-friends/solr-query-builder ▪ frne/symfony-solr-playground Try it
out!
Web Solutions Big Data Analytics Mobile Fragen ? Input ?
Web Solutions Big Data Analytics Mobile Danke ;) @frank_neff www.frankneff.ch
www.ymc.ch github.com/frne speakerdeck. com/frne Bilder 1. http://bigdata.globant.com/?p=629 2. http://www.ecloudtimes.com/reduce-blog-loading-time/ 3. http://grabcad.com/ 4. http://www.colbenson.com/-/apache-solr-course-in-bilbao- tomorrow 5. http://www.solarium-project.org/ 6. http://office-lernen.com/ 7. https://forums.zarafa.com/ 8. https://plus.google.com/+RecordxpressCa/posts 9. https://www.simple-talk.com/sql 10. http://cloudconceptgroup.com/ 11. http://www.digitec.ch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![mod_date:[20020101 TO 20030101] Numeric Range](https://files.speakerdeck.com/presentations/049fb6b042830132aca356294df362d1/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}