Dealing with real-time, in-memory, streaming data is a unique challenge and with the advent of the smartphone and IoT (trillions of internet connected devices), we are witnessing an exponential growth in data at scale.
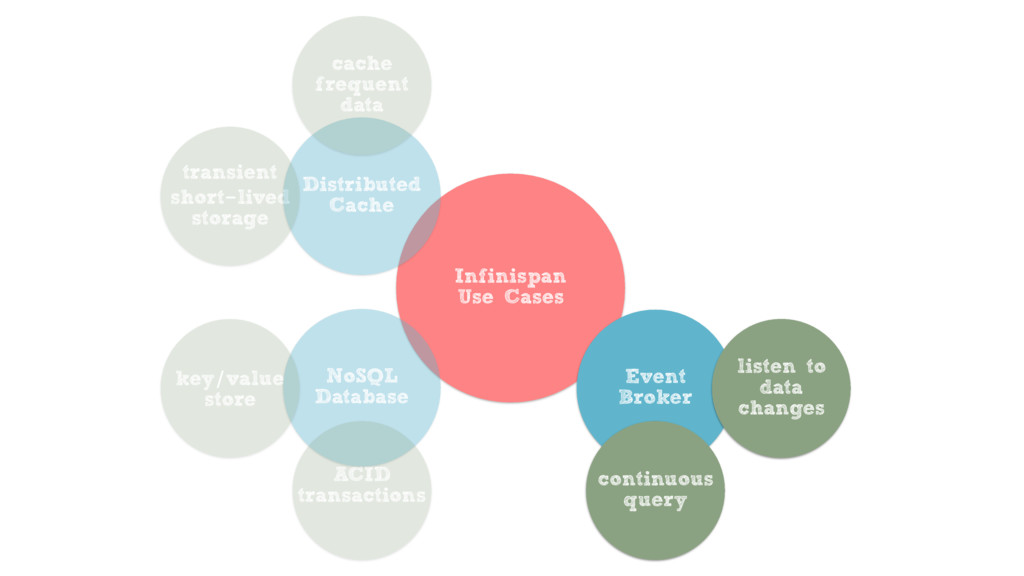
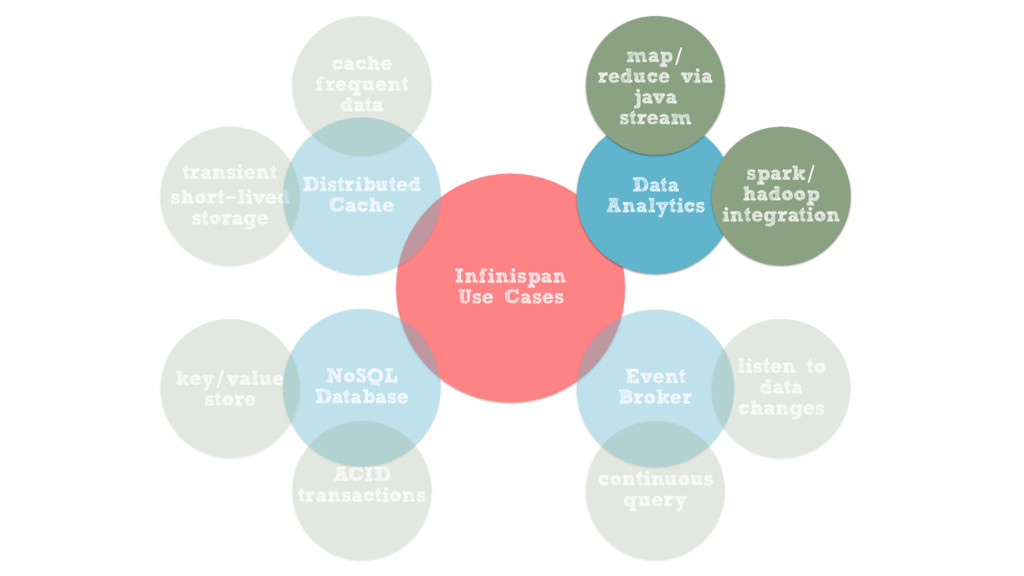
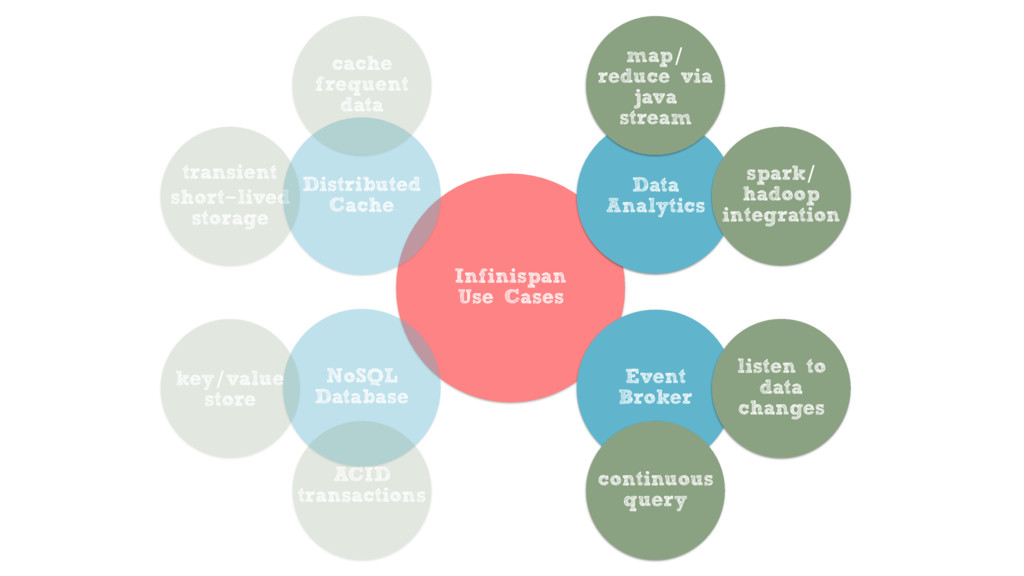
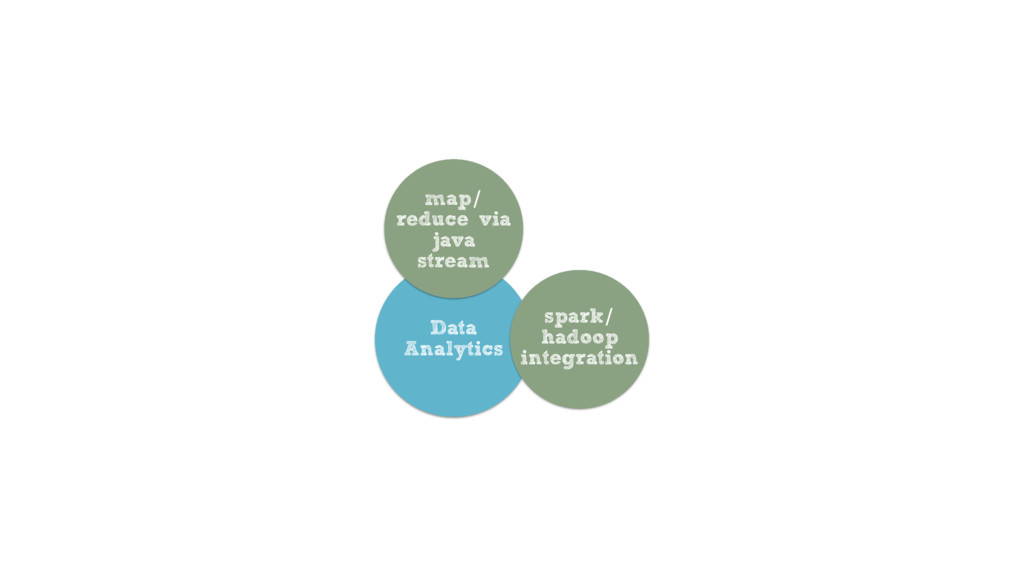
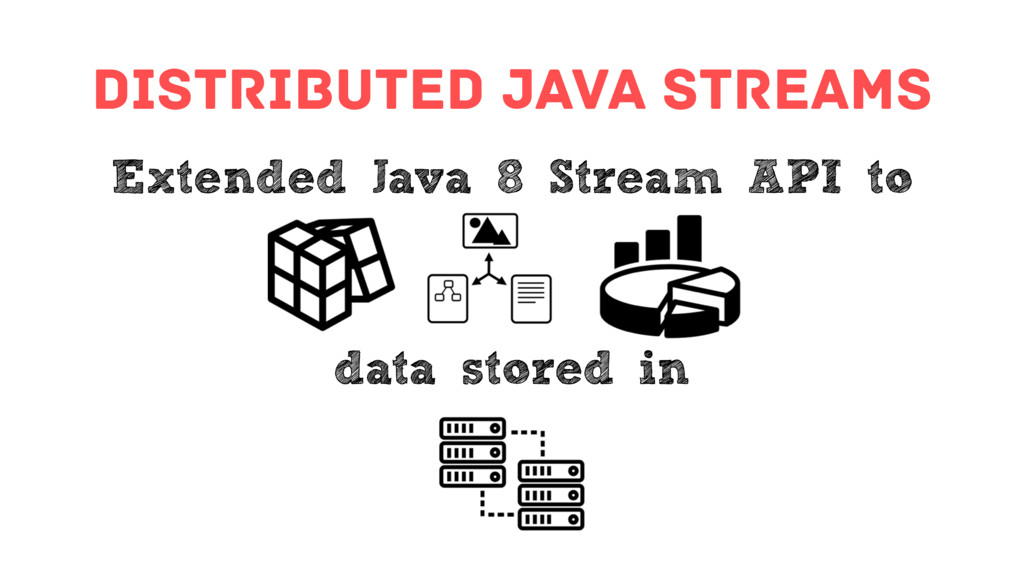
Building data layers that can satisfy these requirements can be challenging, but with the help of Infinispan, an in-memory data grid from Red Hat, you can take advantage of state of the art distributed data processing capabilities to tackle these challenges. From classic or full-text queries, to Spark/Hadoop integrations via distributed Java Streams, these wide ranging data processing capabilities make Infinispan the perfect choice for the Big Data era.
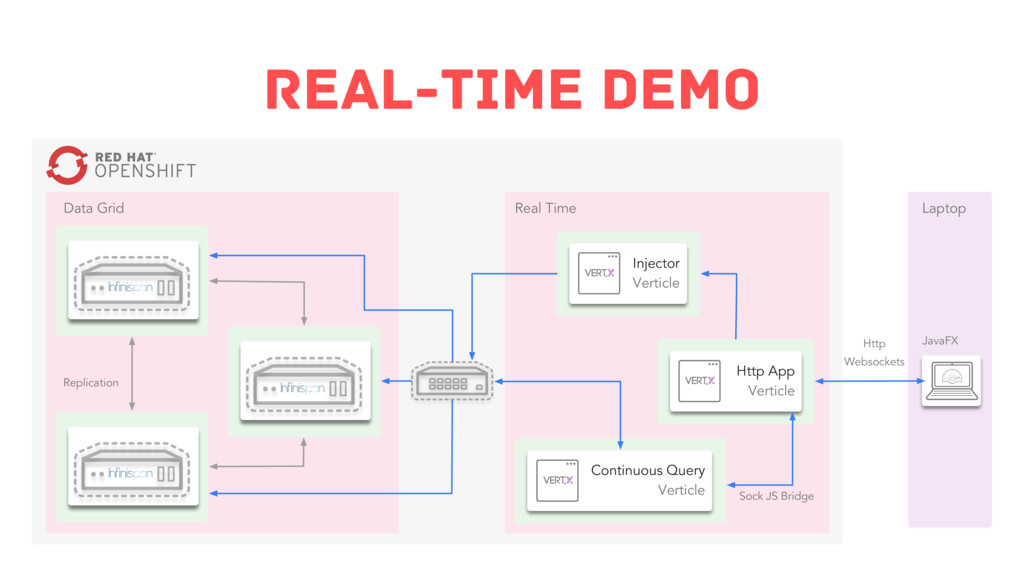
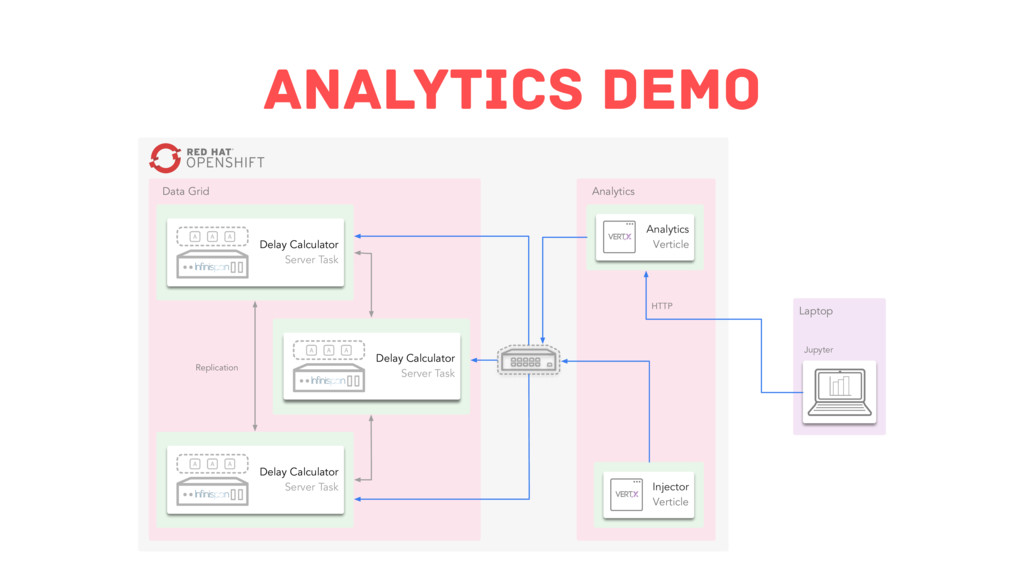
In this session, we will identify critical patterns and principles that will help you achieve greater scale and response speed. On top of that, you will witness how Infinispan follows these patterns and principles to tackle a big data situation via a live coding demonstration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
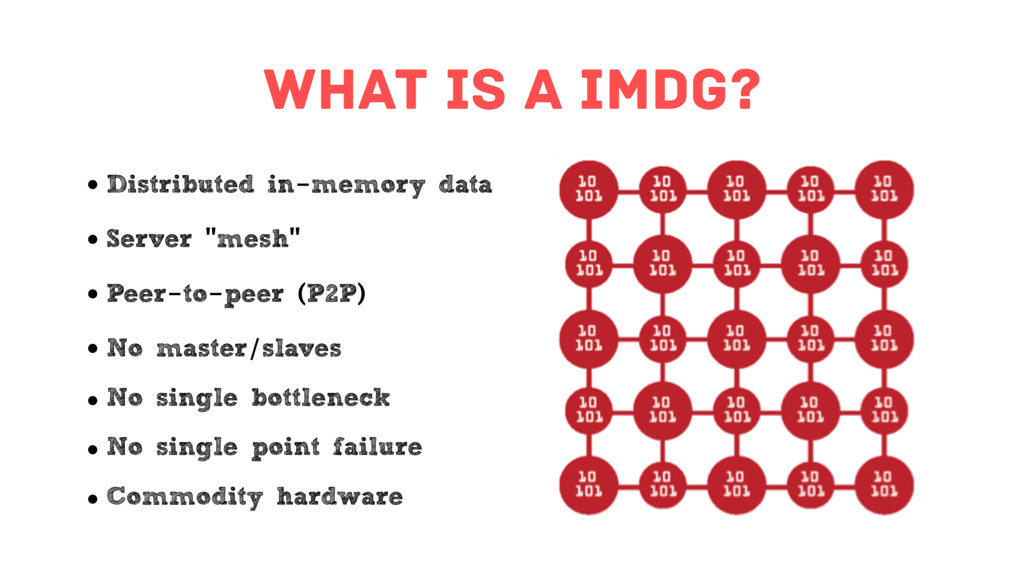{kind=link}
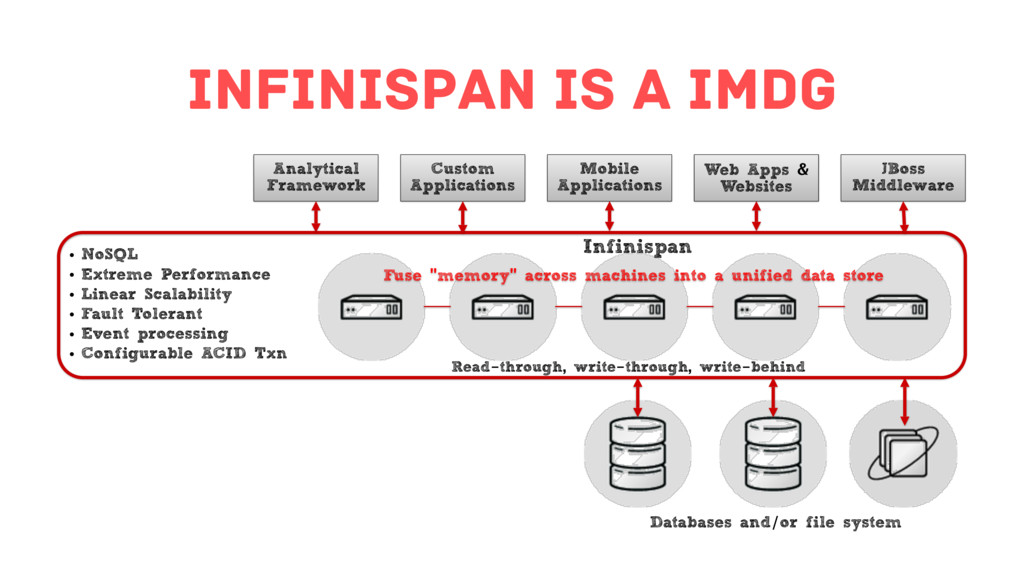{kind=link}
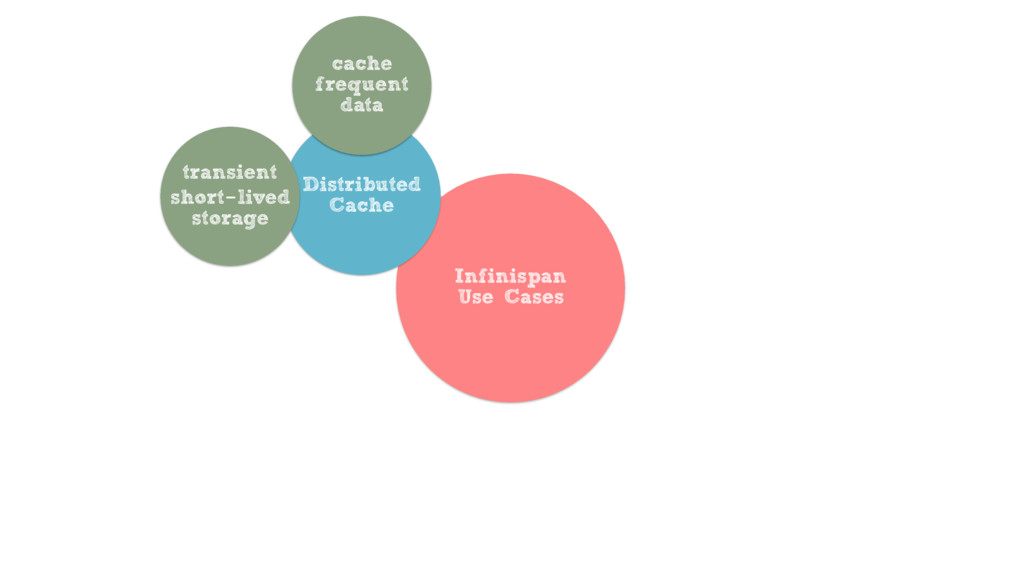{kind=link}
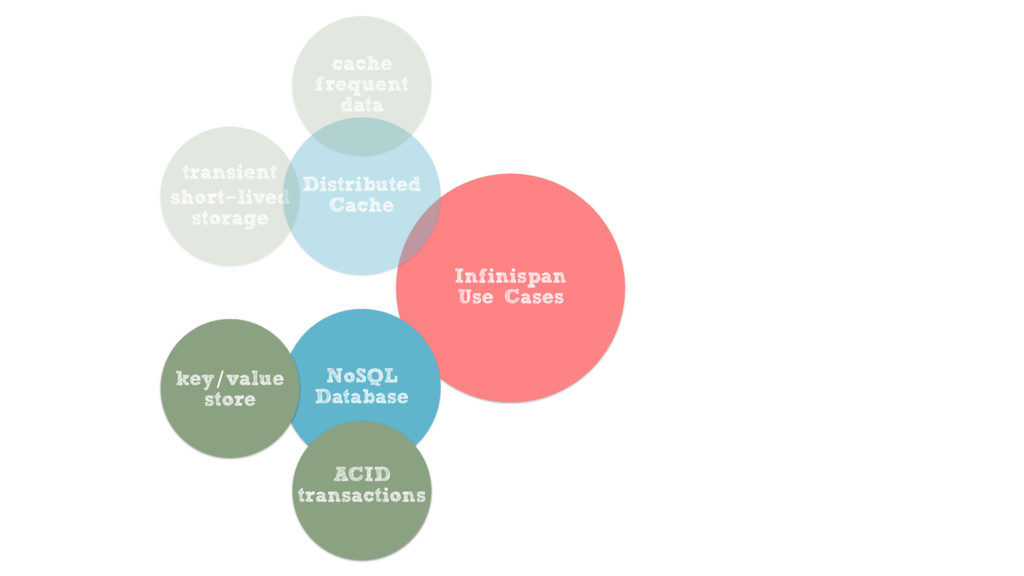{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}