Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第2回ディープラーニング勉強会~画像処理編~
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
iwanaga
November 27, 2021
Science
0
300
第2回ディープラーニング勉強会~画像処理編~
iwanaga
November 27, 2021
Tweet
Share
More Decks by iwanaga
See All by iwanaga
第1回ディープラーニング勉強会~画像処理編~
ganchan11
0
270
第0回ディープラーニング勉強会(演習問題、訂正)
ganchan11
0
440
第0回ディープラーニング勉強会~画像処理編~資料
ganchan11
1
780
第3回python勉強会(解答)
ganchan11
0
340
第3回python勉強会~基礎編~
ganchan11
0
480
第2回python勉強会(解答編)
ganchan11
0
430
第2回python勉強会~基礎編~
ganchan11
0
610
第1回python勉強会~インストール編~
ganchan11
0
660
Other Decks in Science
See All in Science
DMMにおけるABテスト検証設計の工夫
xc6da
1
1.6k
2025-06-11-ai_belgium
sofievl
1
240
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
960
HDC tutorial
michielstock
1
540
(2025) Balade en cyclotomie
mansuy
0
480
Distributional Regression
tackyas
0
370
動的トリートメント・レジームを推定するDynTxRegimeパッケージ
saltcooky12
0
260
Rashomon at the Sound: Reconstructing all possible paleoearthquake histories in the Puget Lowland through topological search
cossatot
0
670
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.1k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
0
230
HajimetenoLT vol.17
hashimoto_kei
1
190
[Paper Introduction] From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
haruumiomoto
0
220
Featured
See All Featured
We Have a Design System, Now What?
morganepeng
55
8k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
110k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
1.8k
So, you think you're a good person
axbom
PRO
2
2k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
150
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
140
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.1k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
55k
From π to Pie charts
rasagy
0
150
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
100
How to Talk to Developers About Accessibility
jct
2
150
Transcript
第2回ディープラーニング 勉強会 ~画像処理編~
⽬次 ▪ ⾃⼰紹介 ▪ 本の紹介 ▪ ResNetとは ▪ VGGとは ▪
画像分類のディープラーニングにおい て ▪ Loss関数とOptimizer ▪ VGGの実装 ▪ 汎化性能 ▪ 学習⽤データと評価⽤データ ▪ オンライン学習 ▪ 混同⾏列 ▪ バッチ学習の利⽤ ▪ 過学習 ▪ 最後にやってみて
⾃⼰紹介 ▪ 岩永拓也 ▪ 九州⼯業⼤学 情報⼯学部 4年 ▪ 藤原研究室 アルゴリズム
▪ 趣味︓ゲーム、読書、ボードゲーム ▪ エディタ︓Atom
本の紹介 ▪ 即戦⼒になるための ディープラーニング開発実践ハンズオン ▪ [著]井上⼤樹、佐藤峻 ▪ 価格︓3280円(税抜) ▪ リンク︓
https://gihyo.jp/book/2021/978-4-297-11942-3
ResNetとは ▪ 2015年のLISVRC(ImageNet Large Scale Visual Recognition Challenge)で1位に なったモデル。以前の優勝したモデルの層の数が約20なのに対し、ResNetは 152層
▪ ⼀般的に層が多くなるほど複雑になっていき、勾配消失問題などが出てくるた め学習が進まない。 →その解決法として残差ブロックを置くこと
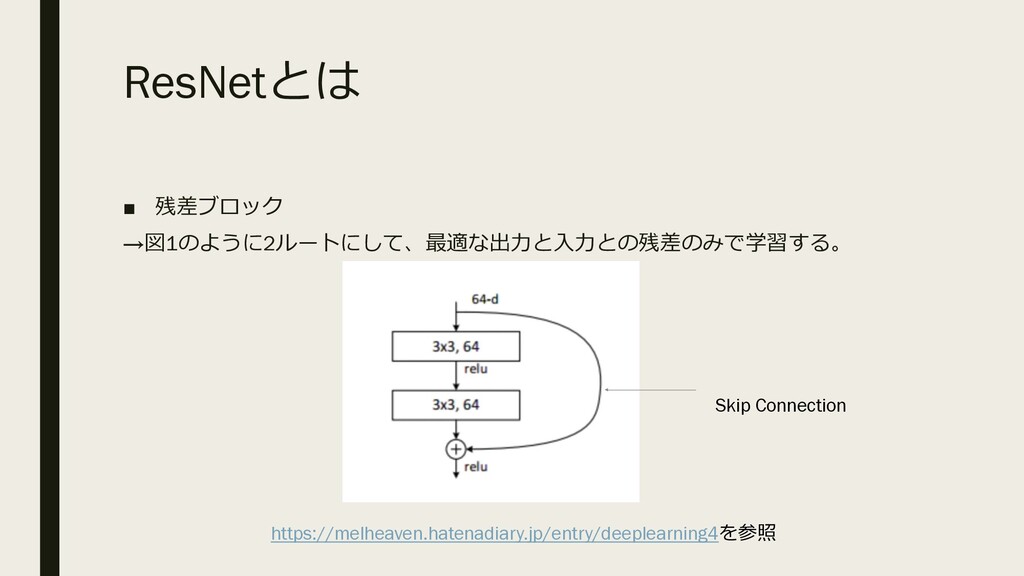
ResNetとは ▪ 残差ブロック →図1のように2ルートにして、最適な出⼒と⼊⼒との残差のみで学習する。 https://melheaven.hatenadiary.jp/entry/deeplearning4を参照 Skip Connection
VGGとは ▪ 2014年のILSVRCでローカリゼーション(画像の中の物体の検出)の分野にて1位、 画像分類の分野で2位になったアルゴリズム。 ▪ 前年のILSVRCの画像分野で1位だったZFNetが8層に対し、VGGは最⼤で19層。
画像分類のディープラーニングにお いて ▪ メリット →⼯場での製品の検査などにおいて従来は前からのものに限定していたのに対し、 ディープラーニングを取り⼊れることで横からや斜めに撮影した映像や写真といっ た場合でも特徴を抽出し、検出が可能 ▪ デメリット →実装には莫⼤なコストがかかる。
例︓データの質と量の確保、学習にかかる時間
画像分類のディープラーニングにお いて ▪ アルゴリズムの選定⽅法 →ディープラーニングのアルゴリズムは毎年数多く発表されている。⾼い制度を持 つからといって、実際の事業などで有⽤とは限らない。 ⾼い処理速度を要するものにとっては、コンピュータのメモリが⼗分に搭載されて いなかったり、ハードウェアを容易に拡張できない場合があるため慎重に選ぶ必要 がある。
Loss関数とOptimizer 今まで受け取った画像を処理する⼿順のみ定義してた →学習を進めるためLoss関数(損失関数)とOptimizer(最適化関数)が必要になる ▪ Loss関数 →理想とする結果から現在の処理結果がどれだけの誤差があるか表現した関数 主に平均⼆乗誤差かクロスエントロピーに使⽤。
Loss関数とOptimizer ▪ 平均⼆乗誤差 →それぞれの出⼒の差を⼆乗し、平均を取ったもの。誤差を⼆乗して正にすること で相殺を防ぎ、学習を進められる https://atmarkit.itmedia.co.jp/ait/articles/2105/24/news019.htmlを参照
Loss関数とOptimizer ▪ クロスエントロピー →分類タスクで⽤いられ、分類時の確率が100%になるような出⼒になり、正解ク ラスの確率が1に近いほど良いことからLogを⽤いてその誤差を表現する。 ※今回はクロスエントロピーを⽤いる →「categorical_crossentropy」を使⽤
Loss関数とOptimizer ▪ Optimizer →Loss関数によって求めた誤差をどのような⽅針で修正するか表現する関数。 ディープラーニングでは⼤量の変数を取り扱うので、ただ求めた結果の通り修正し ているだけでは誤差が⼩さくなりません。 →⽅法としてLearningRate(学習率)で修正する量を⼩さくする。
Loss関数とOptimizer ▪ SGD(Stochastic Gradient Descent : 確率的勾配降下法) →Loss関数で求めた修正量に学習率をかけて修正するOptimizer。 学習率は1e-3~1e-5あたりの数が⽤いられる。 ▪
他にもMomentumSGD、AdamGrad、RMSprop、Adam、Eveなど数多くのOptimizerが 存在する。 ※参考リンク︓https://qiita.com/omiita/items/1735c1d048fe5f611f80 今回はMomentumSGDを使⽤。学習率は1e-2に学習率減衰は5e-4にモーメンタムは0.9
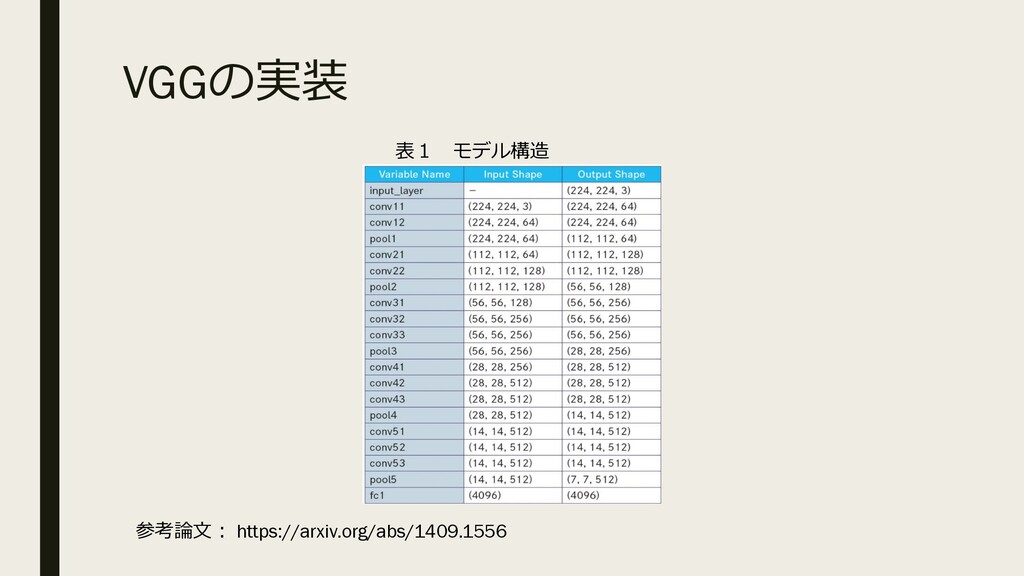
VGGの実装 参考論⽂︓ https://arxiv.org/abs/1409.1556 表1 モデル構造
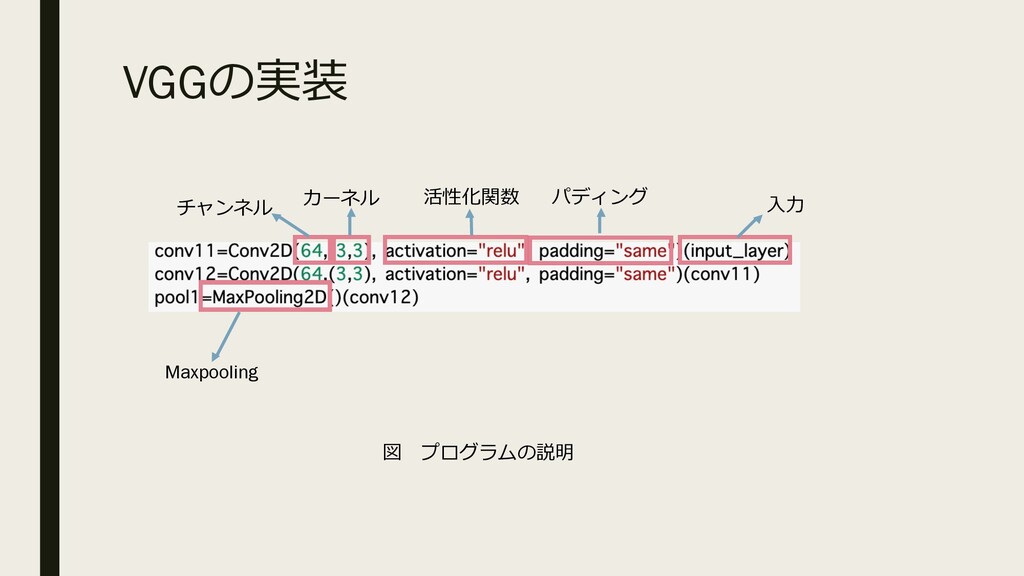
VGGの実装 チャンネル カーネル 活性化関数 パディング ⼊⼒ Maxpooling 図 プログラムの説明
VGGの実装 出⼒ ドロップアウト率
汎化性能 ▪ 汎化性能 →1つのモデルがどれだけ幅広いデータに適応できるかを⽰すもの。⾼いほど学習 してないデータに対して適応できる可能性が⾼い。精度とはトレードオフの関係に あることが多く、どちらかを⾼くするかはプロジェクトの要件によって異なる。
学習⽤データと評価⽤データ ▪ ディープラーニングは⽤意したデータ全てをモデルに学習させるわけではなく、 その⼀部を使って学習したモデルの性能を学習の際に与えなかった残りのデー タで評価する。これにより、実際にそのモデルを使⽤する状況に近い状態で精 度評価を⾏える。この時学習⽤データと評価⽤データは7:3の⽐率でランダムに 分割することが多い。
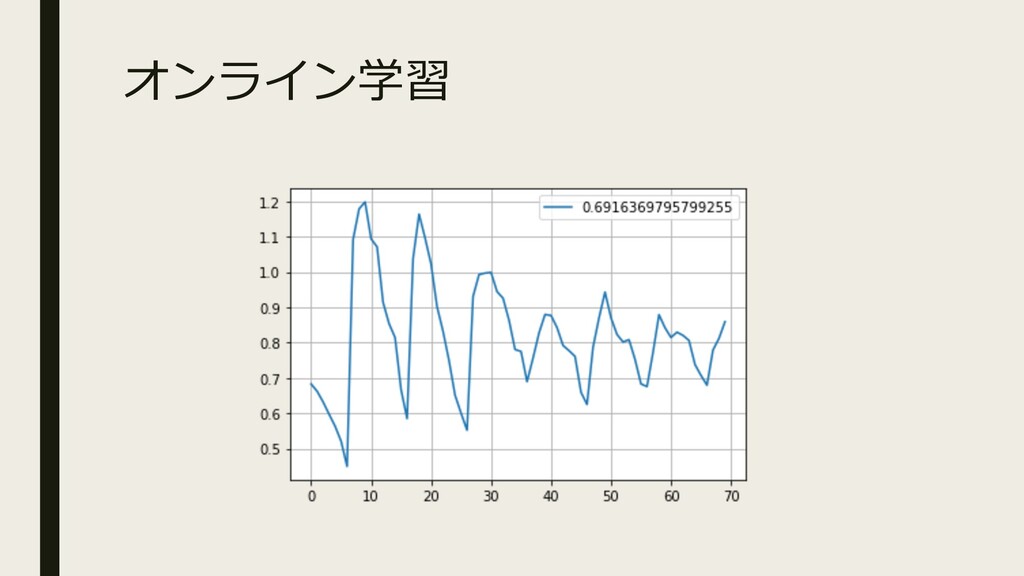
オンライン学習 ▪ 本に載ってる検証環境 スペックが⾼すぎるので⽤意できません︕ ※Google Colaboratoryでできるようにプログラムを変更しました。
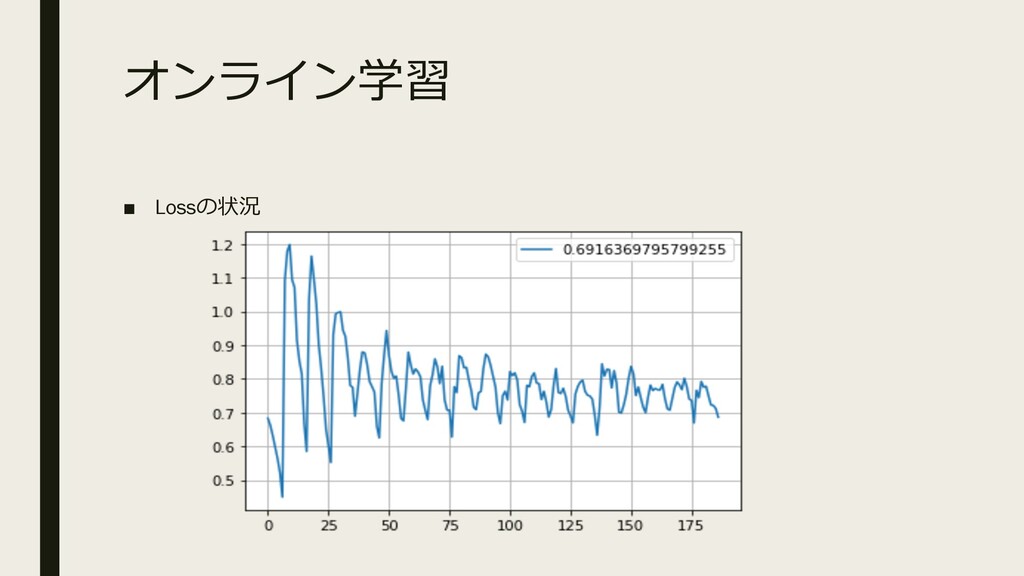
オンライン学習 ▪ Lossの状況
オンライン学習
混同⾏列 ▪ 評価を⾏う際表2が使⽤されます。これを混同⾏列(混合⾏列)という。 ▪ 混合⾏列はデータを分類したときに、その正解・不正解の数を整理しておくた めの表です。 Positive Negative Positive 89(True
Positive) 16(False Negative) Negative 4(False Positive) 91(True Negative) ⼊⼒ 出⼒ 表2 混同⾏列
混同⾏列 ▪ True Positive(真陽性,TP) →Positiveと予想し、実際Positive ⭕ ▪ False Positive(偽陽性,FP) →Positiveと予想し、実際Negative
❌ ▪ False Negative (偽陰性,FN) →Negativeと予想し、実際Positive ❌ ▪ True Negative(真陰性,TN) → Negativeと予想し、実際Negative ⭕ https://vector-ium.com/ds-confusion/を参照
混同⾏列 ▪ 正解率(Accuracy) →出⼒全体に対し、正しく判断できたものの割合 式︓ !"#!$ !"#!$#%"#%$ ▪ 再現率(Recall) →Positiveな⼊⼒に対し、出⼒もPositiveな割合
式︓ !" !"#%$
混同⾏列 ▪ 適合率(Precision) →Positiveな出⼒に対して⼊⼒もPositiveな割合 式︓ !" !"#%" ▪ F値 →再現率と適合率の調和平均
式︓ &×()*+,,×"-)*./.01 ()*+,,#"-)*./.01
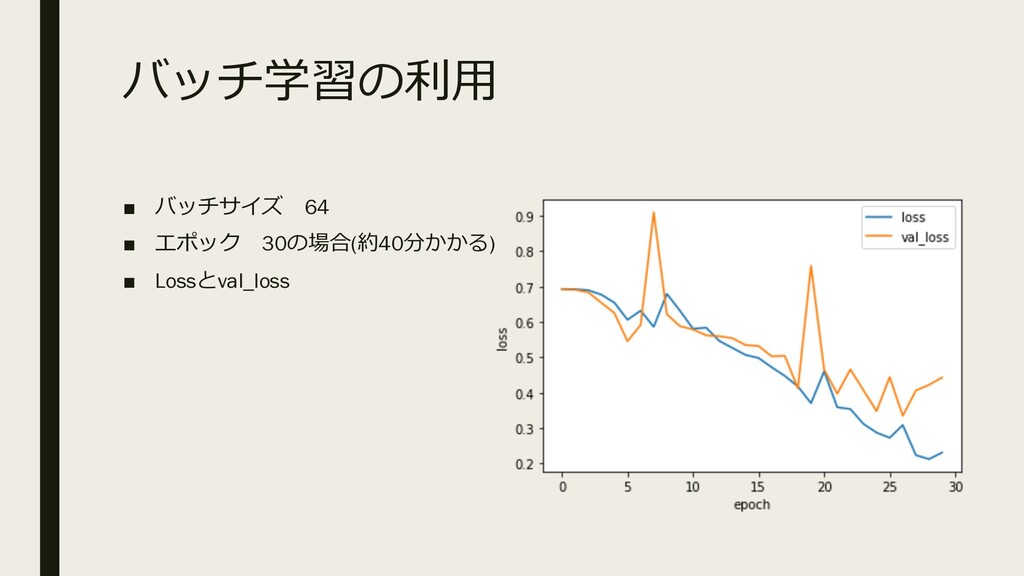
バッチ学習の利⽤ ▪ バッチサイズ 64 ▪ エポック 30の場合(約40分かかる) ▪ Lossとval_loss
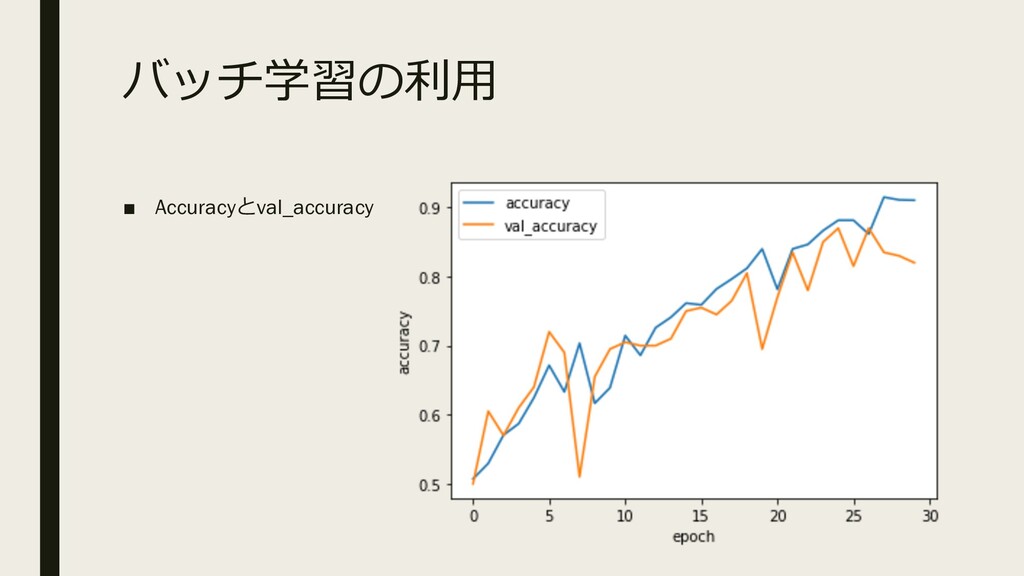
バッチ学習の利⽤ ▪ Accuracyとval_accuracy
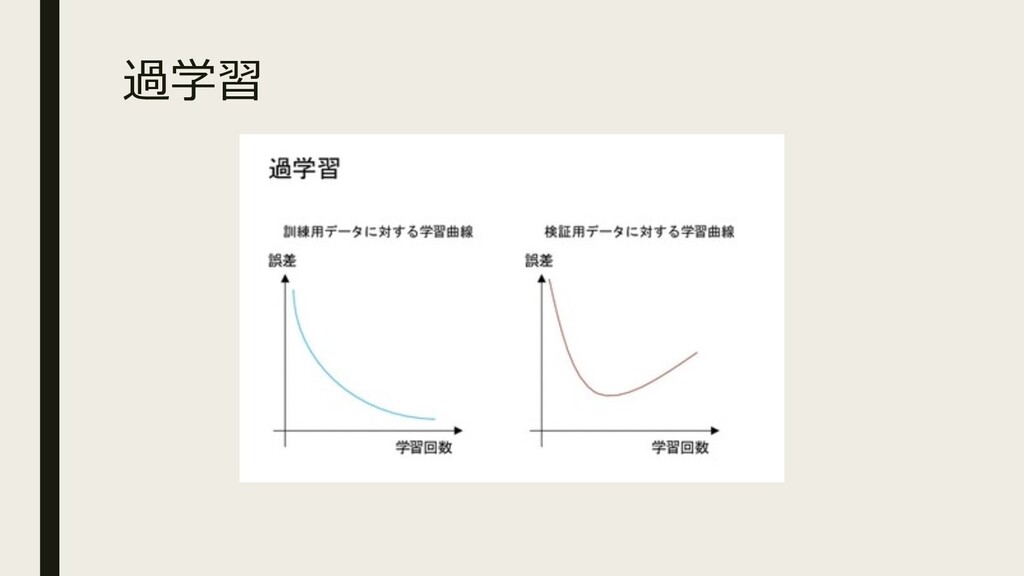
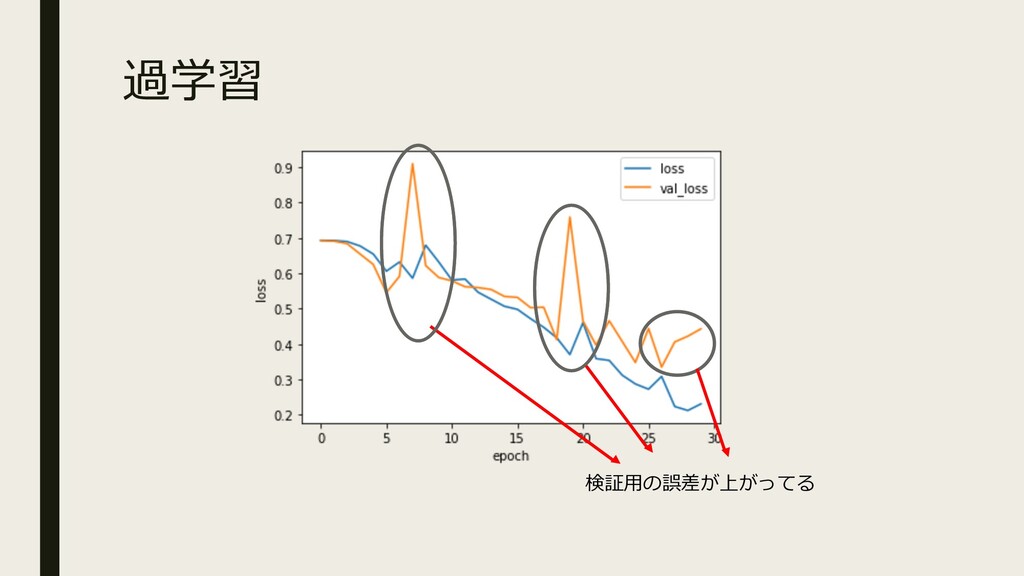
過学習
過学習 検証⽤の誤差が上がってる
改善点 ▪ しっかりしたデータを使⽤ ▪ バッチサイズ、エポックの変更 ▪ SDGの変更 ▪ 画像処理の追加や削減 など…
最後にやってみて ▪ 今回は猫と⼈の識別を⾏いましたが、他にも⽝のデータが存在しますのでそれ も⽤いての識別 ▪ 先程のプログラムを改良して精度を上げる⼯夫 ▪ VGG以外のモデルの調査
{kind=link}
{kind=link}
{kind=link}
![本の紹介 ▪ 即戦⼒になるための ディープラーニング開発実践ハンズオン ▪ [著]井上⼤樹、佐藤峻 ▪ 価格︓3280円(税抜) ▪ リンク︓](https://files.speakerdeck.com/presentations/0293446496a040d39d430ab47d7db2f3/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}