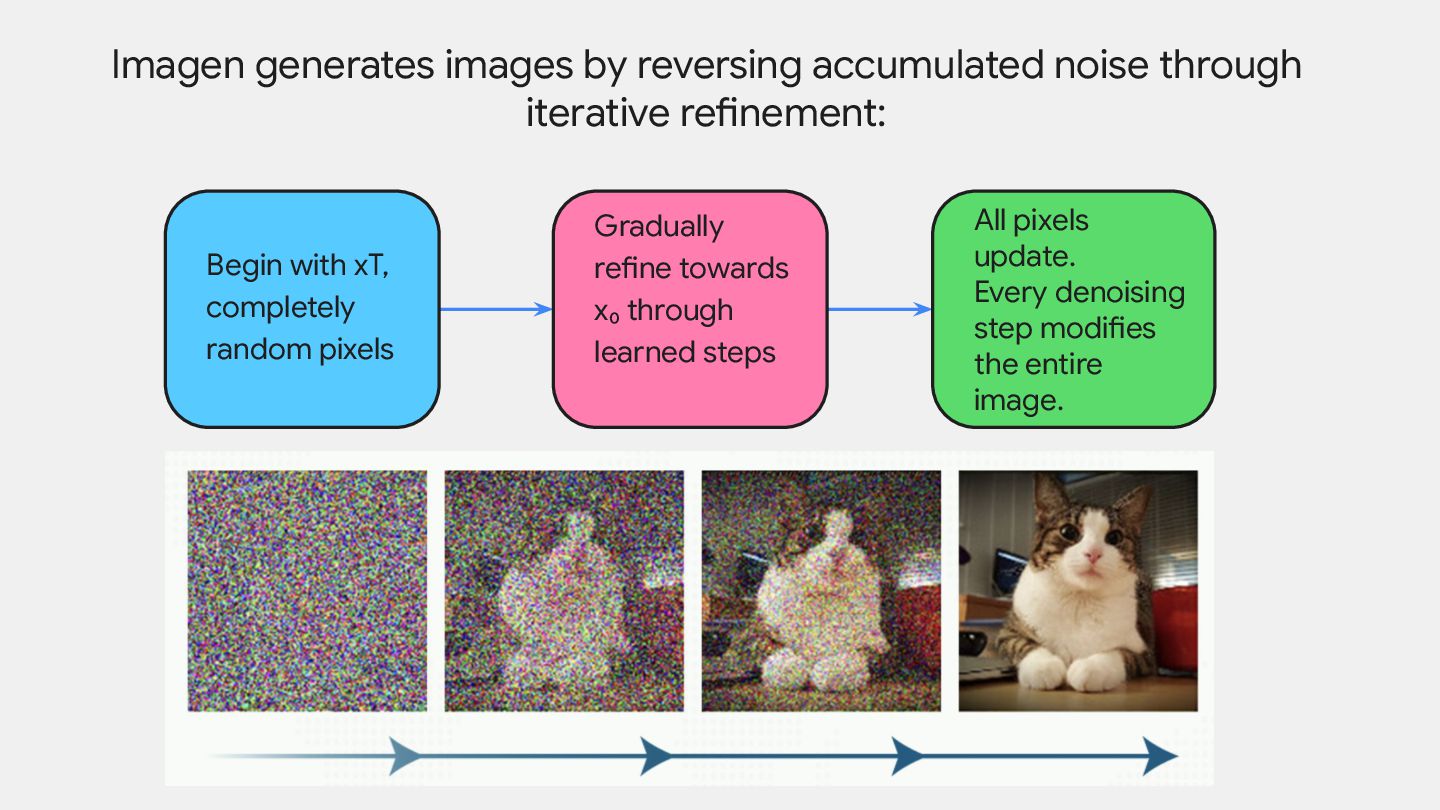
through learned steps All pixels update. Every denoising step modifies the entire image. Imagen generates images by reversing accumulated noise through iterative refinement:
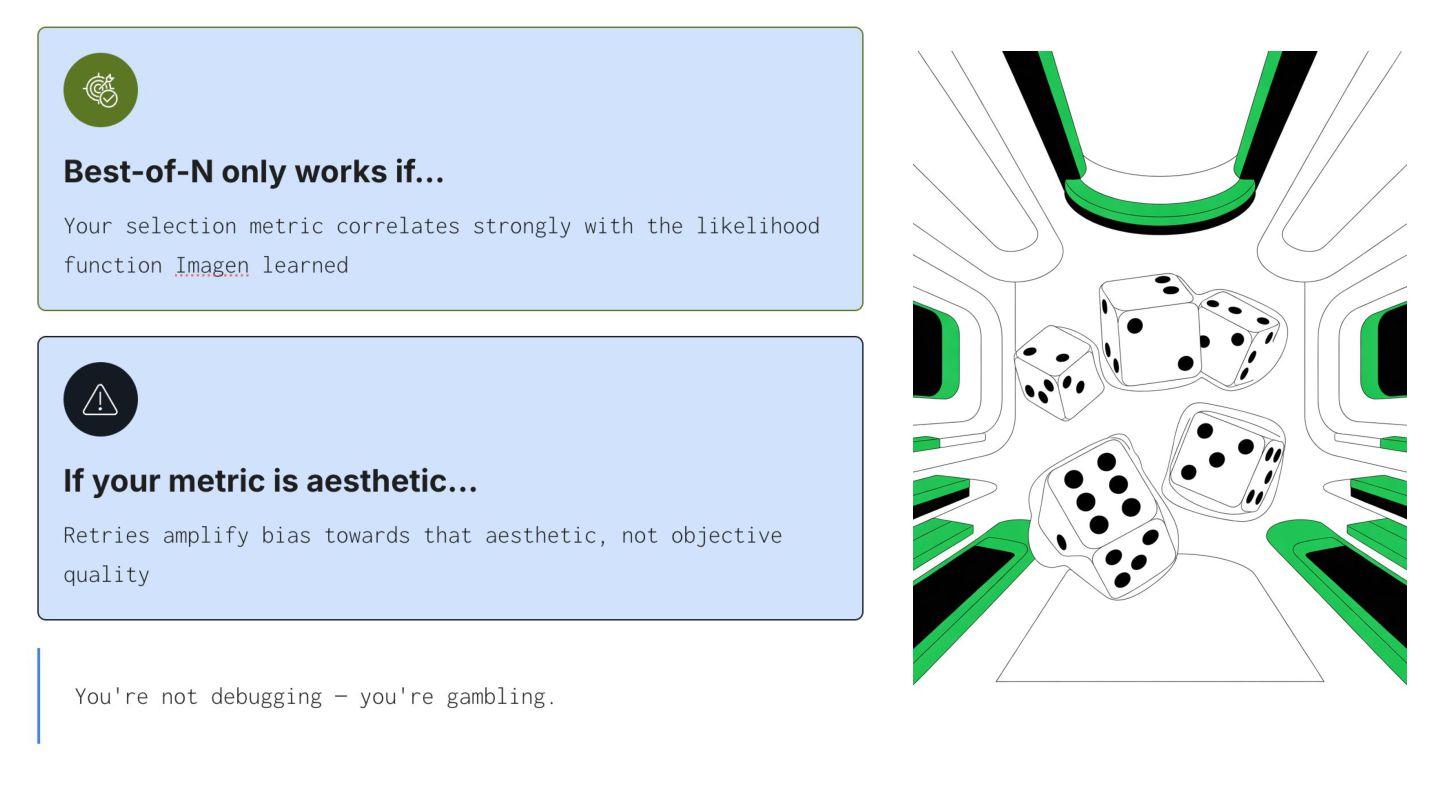
or "in the centre" provides diminishing control • Detail shifts style, not structure ◦ More descriptive prompts change texture and mood, not fundamental composition • Improvements hit limits fast ◦ Prompt engineering reaches a ceiling far earlier than with LLMs
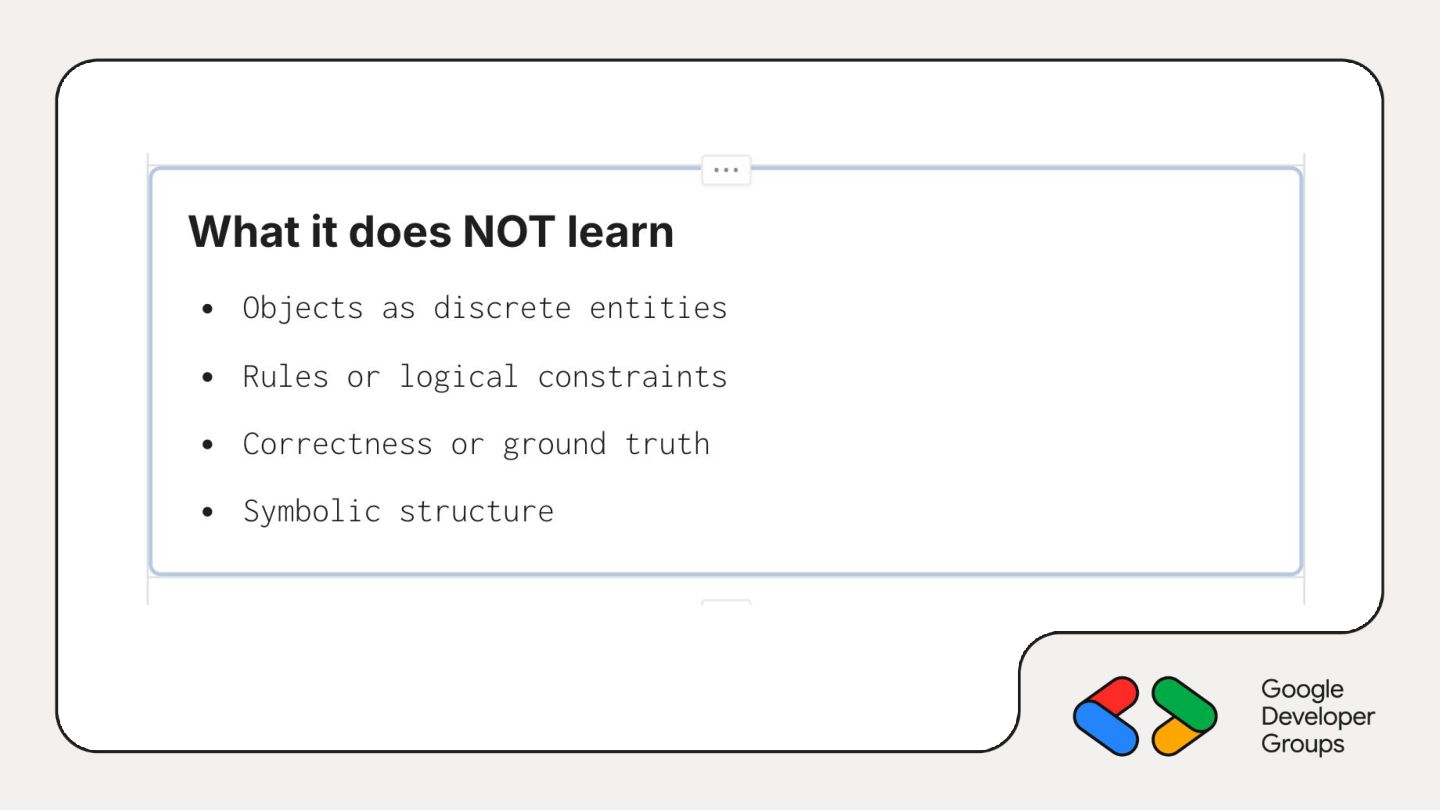
identity across space ◦ bidirectional consistency ◦ symbols as symbols • It models local pixel correlations • Realism collapses under global constraints.
lighting, style • makes unlikely images less likely • produces convincing surface coherence • “Does this look like something I’ve seen before?” Understanding • no enforced rules or invariants • no object identity across space • no constraint satisfaction • “Is this necessarily correct?”
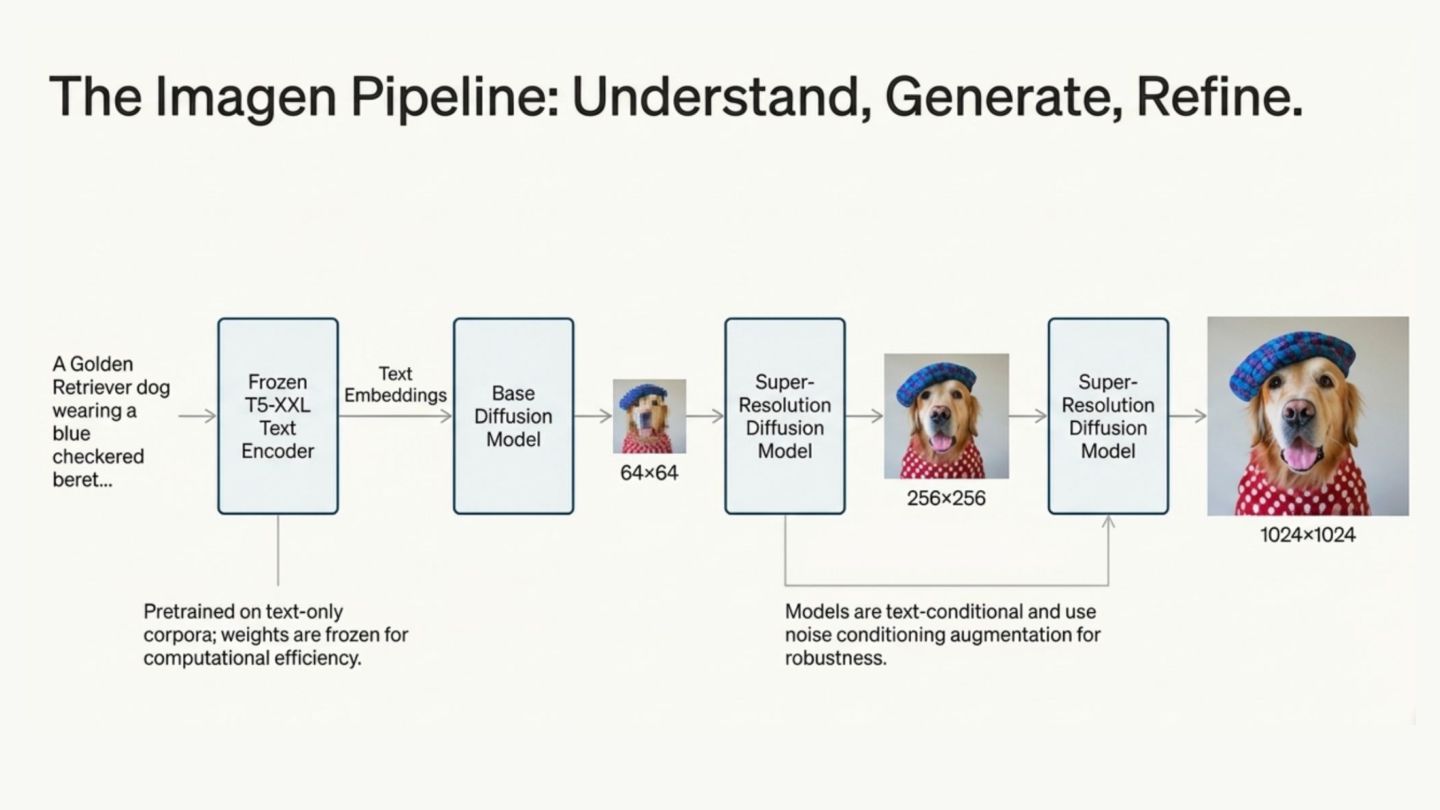
to generate virtual characters from text • users describe characters • Imagen creates visually plausible characters for video • motion, timing, and storytelling are handled by the product
for text-to-character visual generation • creators describe characters in natural language • Imagen generates character visuals directly in the product • characters are then animated and exported fully rigged • Imagen supports creative ideation, not animation logic
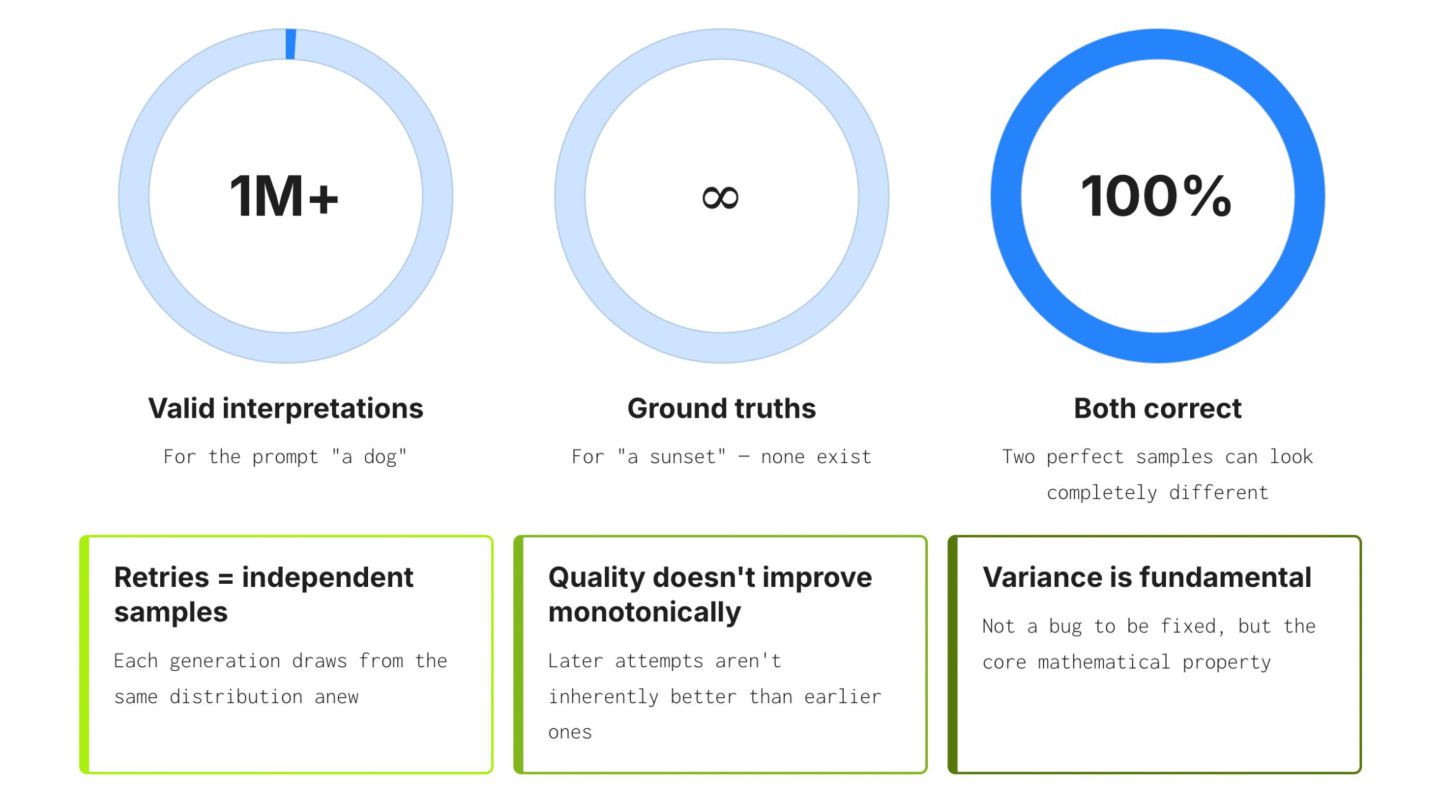
like software. But Imagen shows us: • outputs are sampled, not computed • realism can emerge without understanding • improvement does not imply new capabilities
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}