Education: ◦ Lahore University of Management Sciences (LUMS), BSc. CS ◦ University of Illinois at Urbana Champaign (UIUC), Masters in CS ◦ University of Chicago, Masters in Applied Data Science • Work: ◦ Google ▪ Real-Time Data Flow • Kafka + Pub/Sub ▪ Data Processing Pipelines • Apache Beam ◦ Argonne National Laboratory ▪ Reinforcement Learning
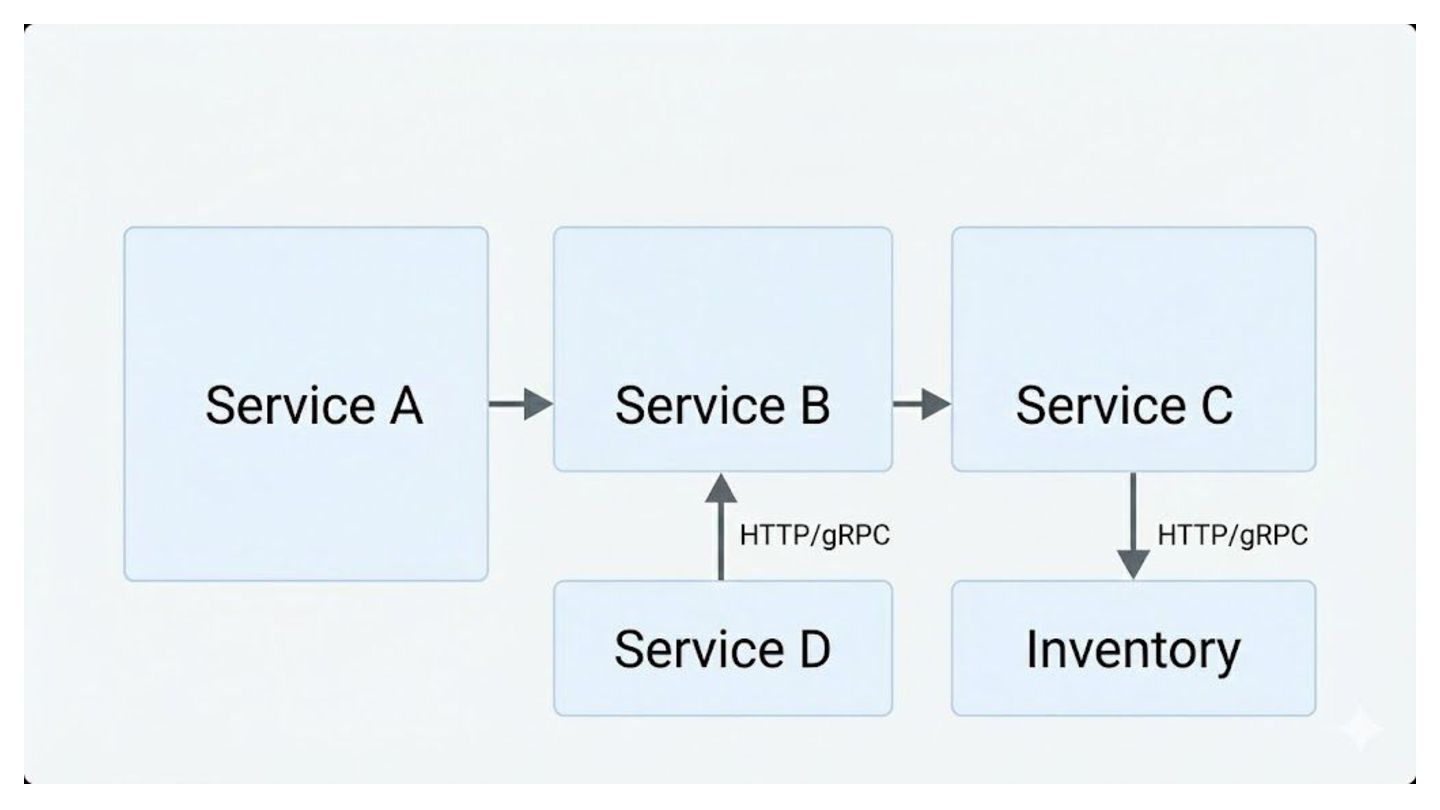
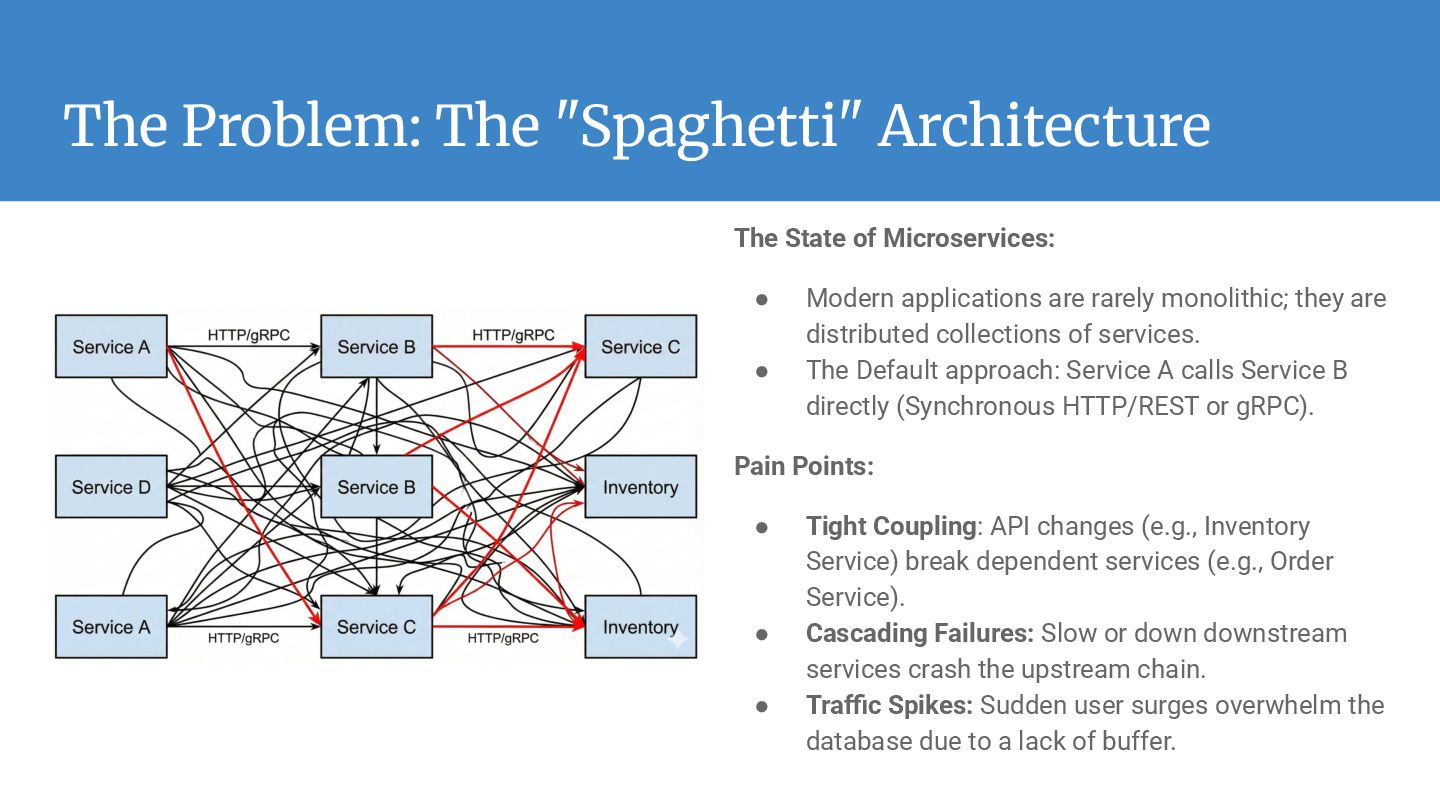
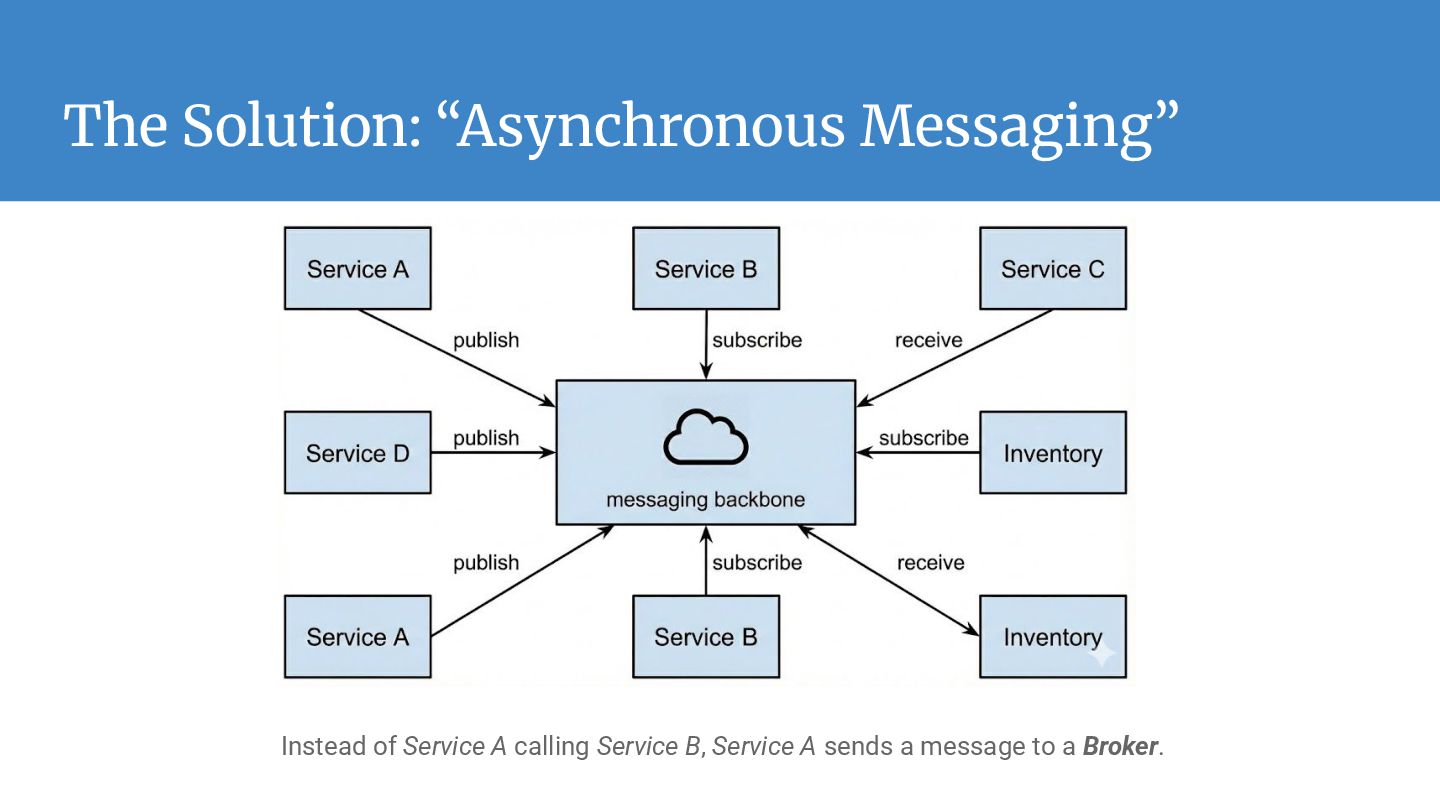
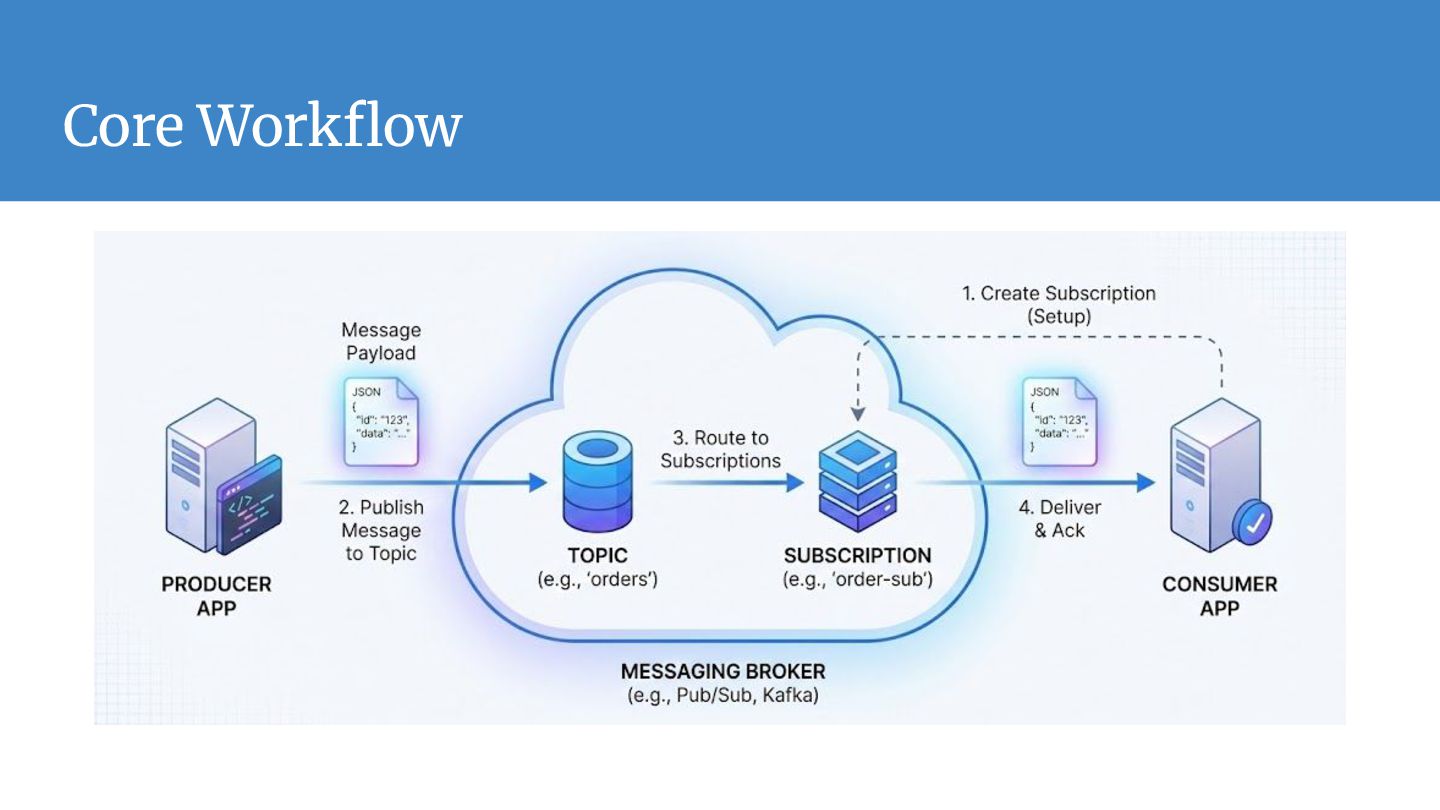
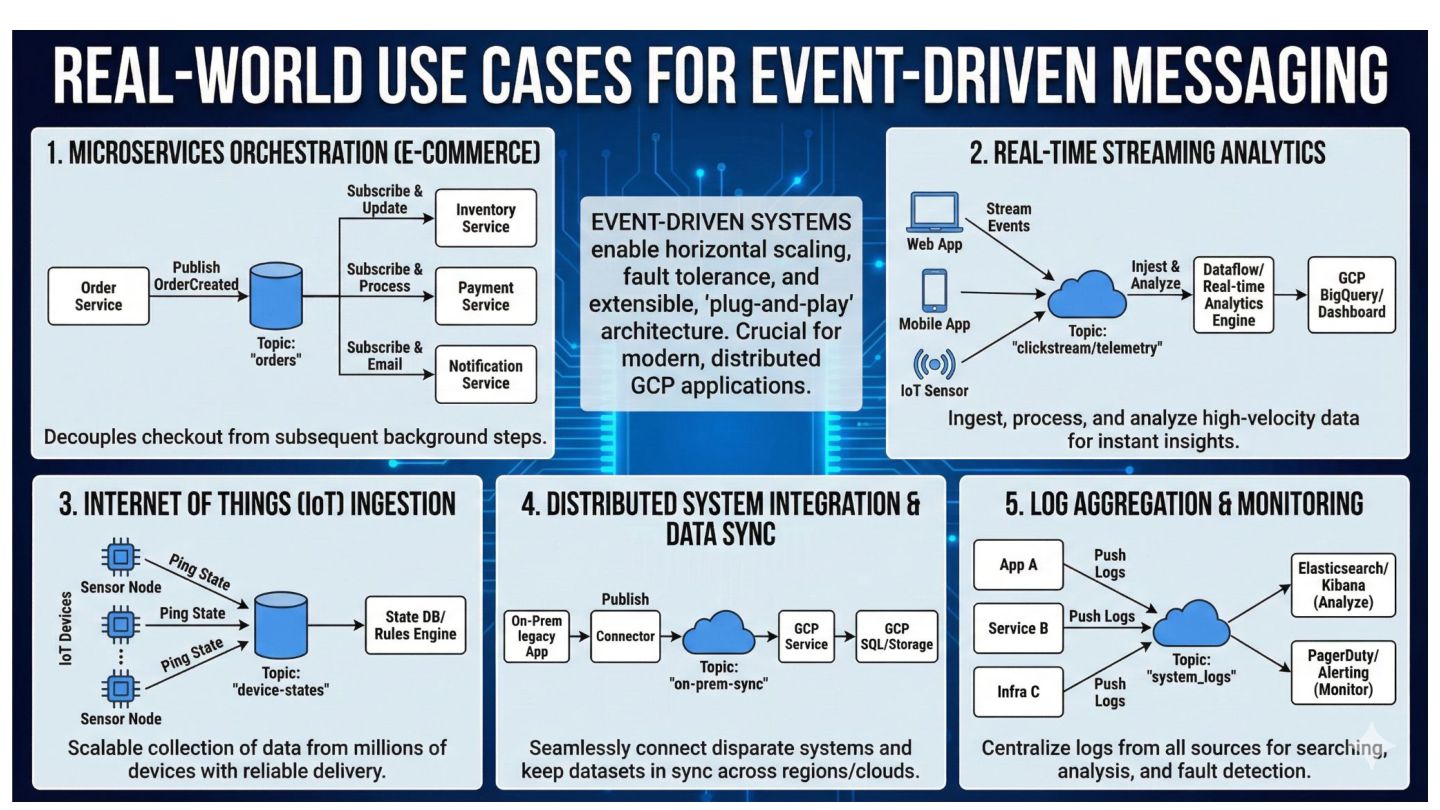
Modern applications are rarely monolithic; they are distributed collections of services. • The Default approach: Service A calls Service B directly (Synchronous HTTP/REST or gRPC). Pain Points: • Tight Coupling: API changes (e.g., Inventory Service) break dependent services (e.g., Order Service). • Cascading Failures: Slow or down downstream services crash the upstream chain. • Traffic Spikes: Sudden user surges overwhelm the database due to a lack of buffer.
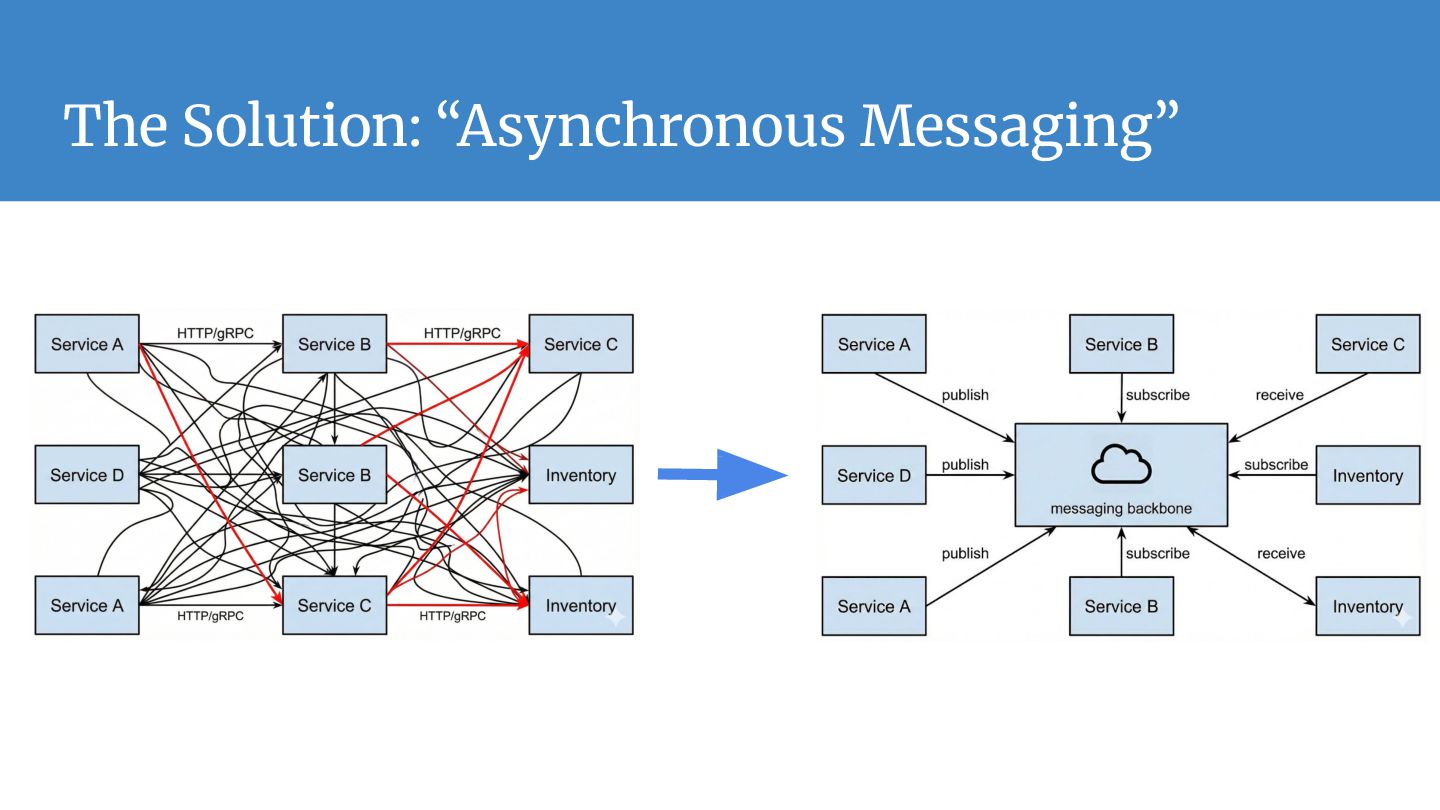
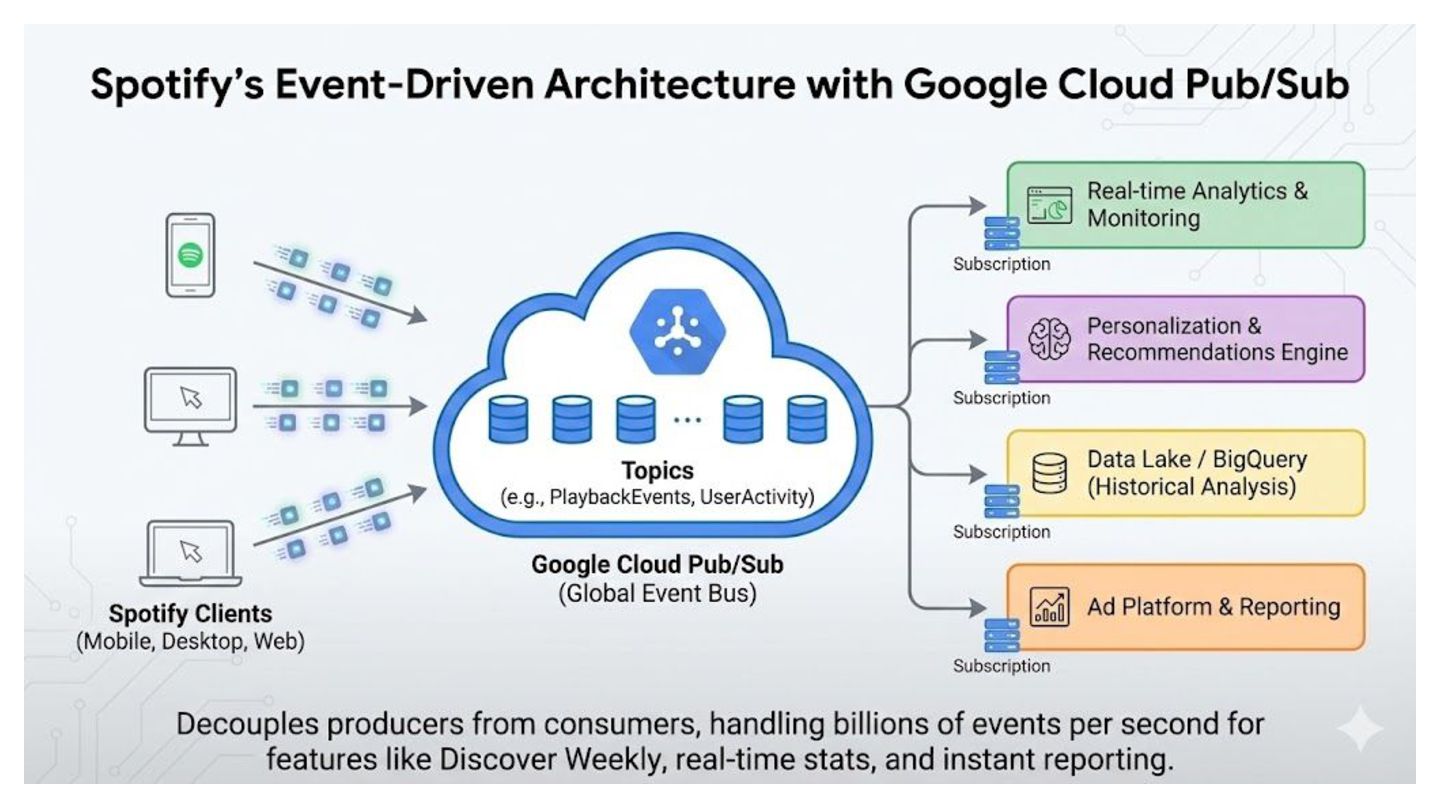
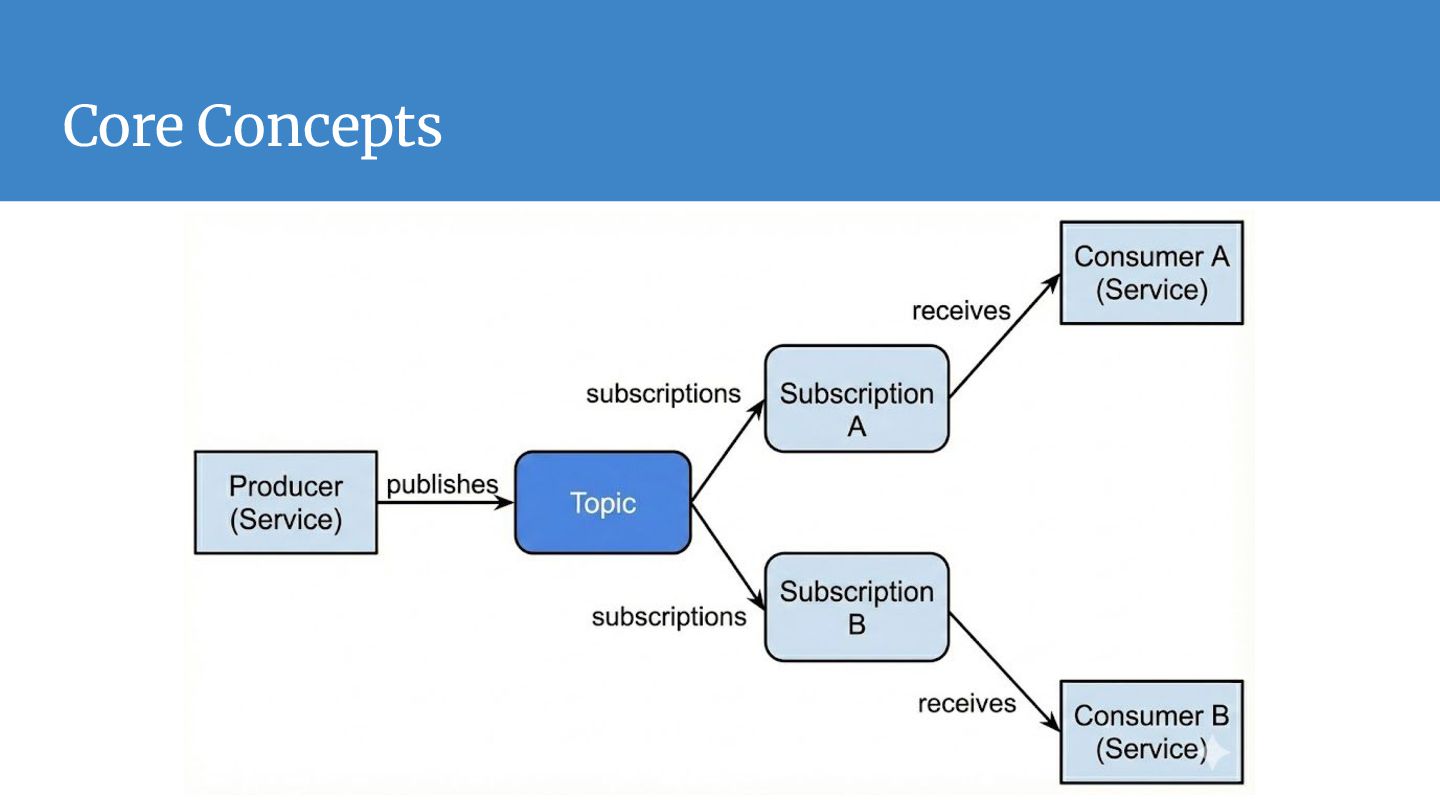
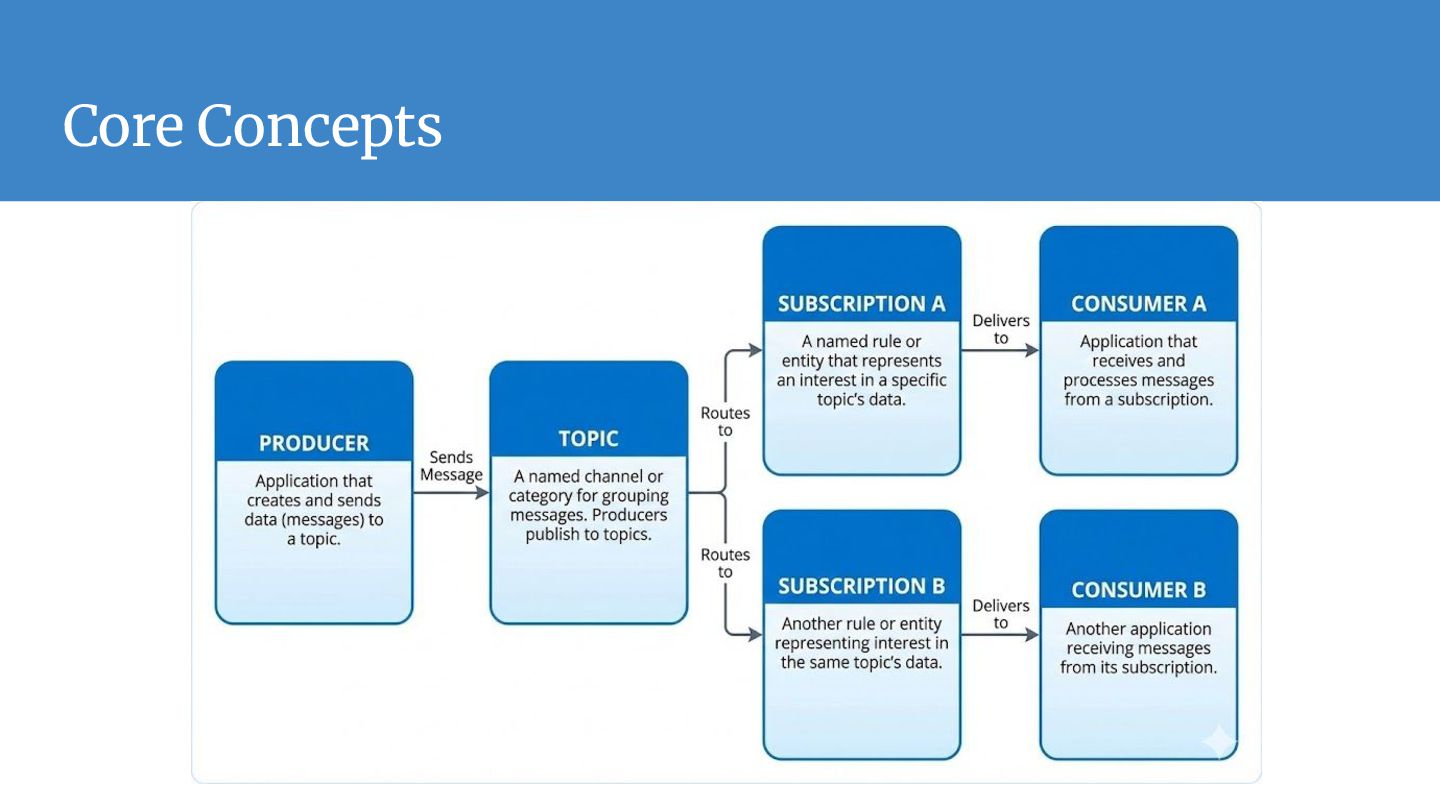
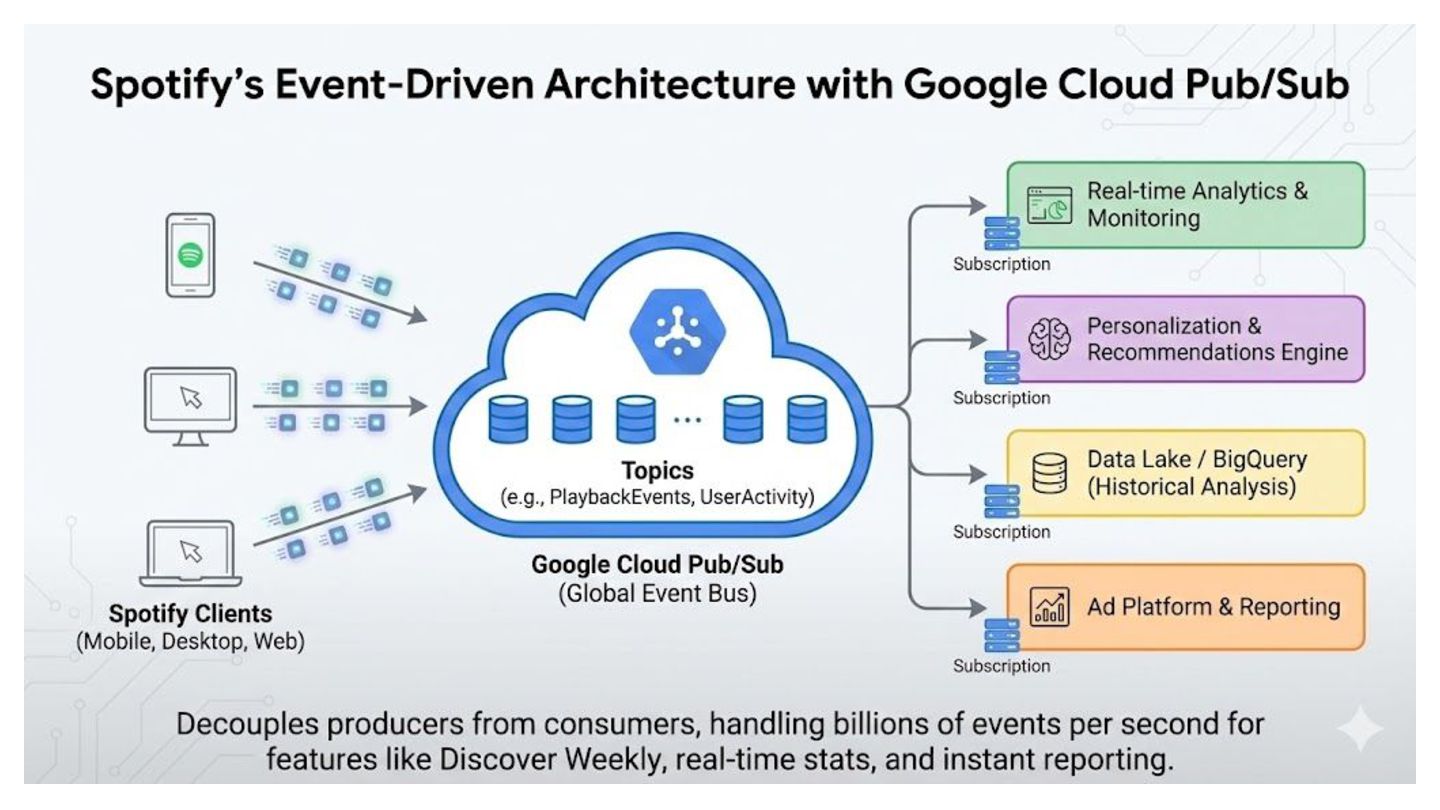
operate independently. They interact only with the interface (Topic), removing direct dependencies and "spaghetti code." • Load Leveling (Buffering): Acts as a shock absorber. If traffic spikes 10x, the broker buffers the data, protecting downstream databases from being overwhelmed. • Elastic Scalability: innovative parallel processing. You can handle massive throughput by horizontally scaling your consumer services; the broker balances the work automatically. • Reliability & Persistence: "Fire and forget." The system guarantees delivery and creates a durable record of events, ensuring data isn't lost even if the receiver is offline. • Extensibility: The "Fan-Out" pattern allows you to add new downstream services (like analytics or logging) to existing data streams without refactoring upstream applications.
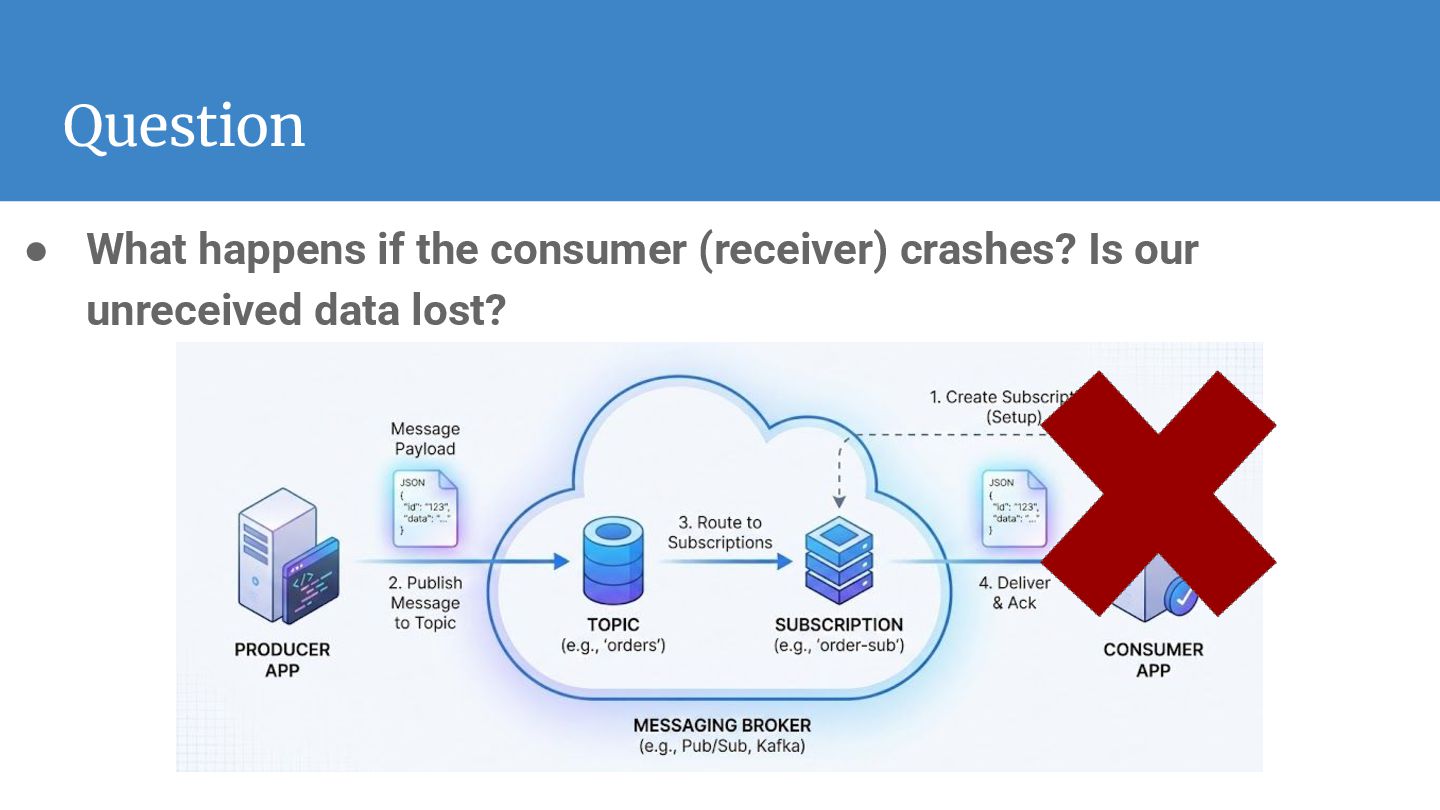
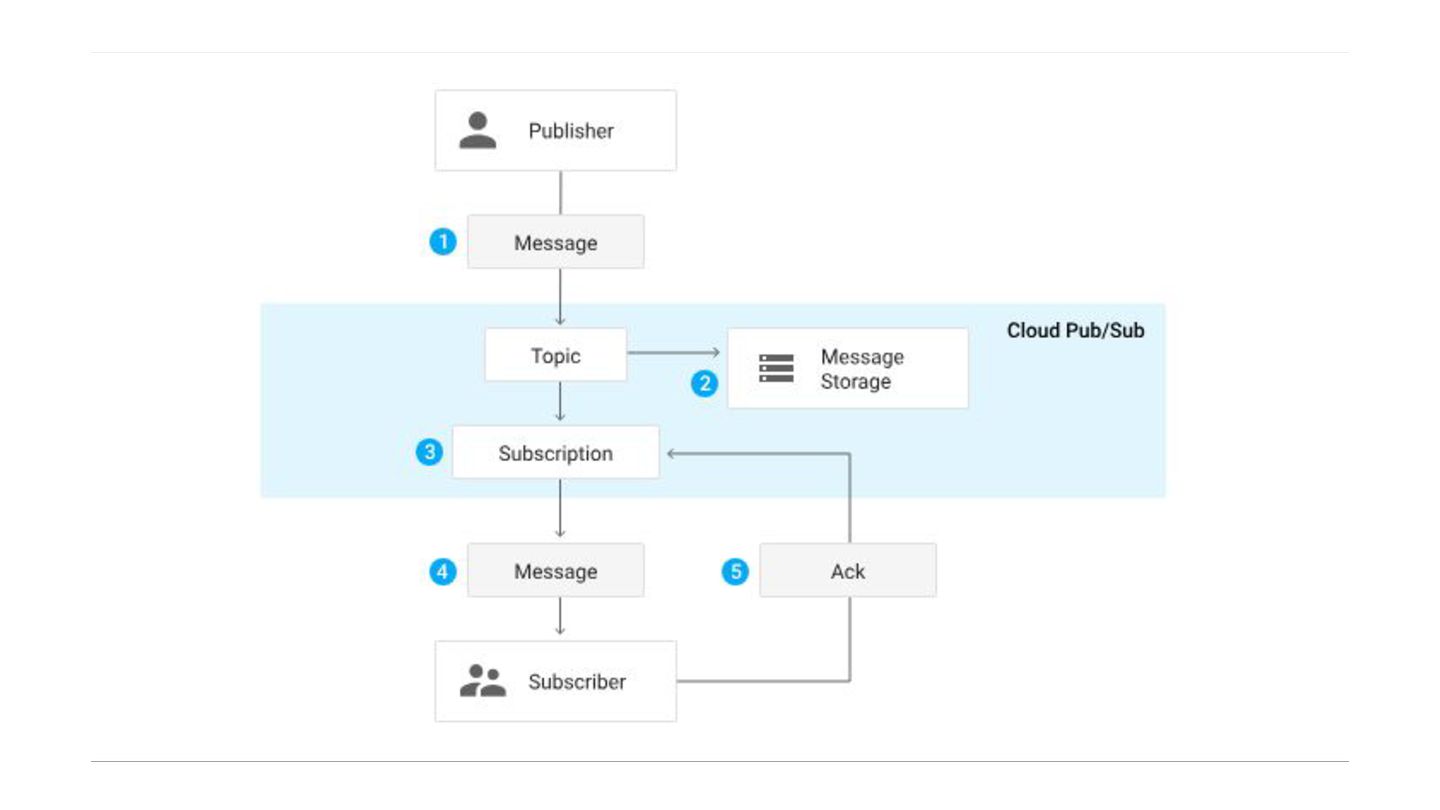
our unreceived data lost? ◦ No, data is not lost. ◦ The broker persists the message (stores it safely) until the receiver comes back online and acknowledges that it has processed it. ◦ Your data "waits" in the queue rather than disappearing.
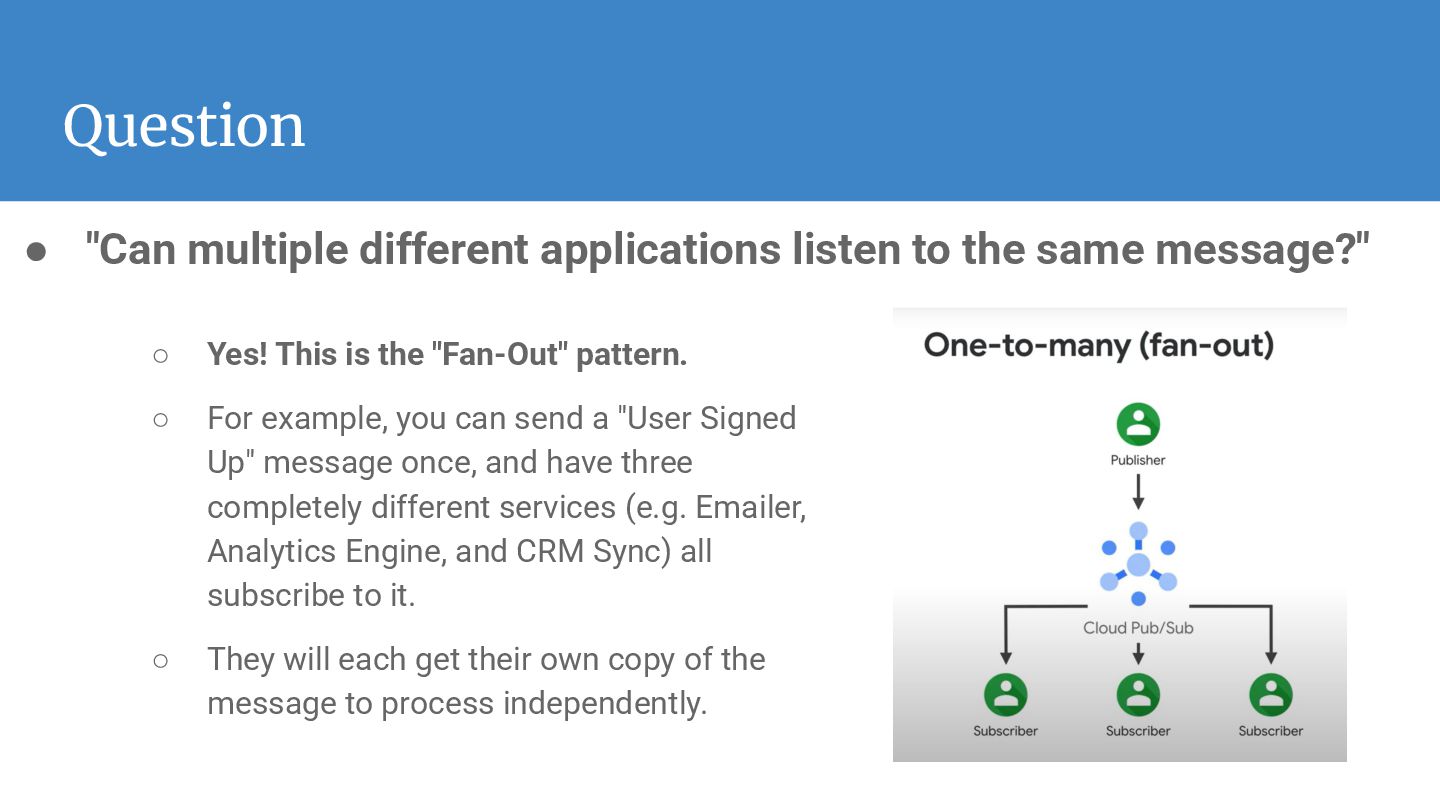
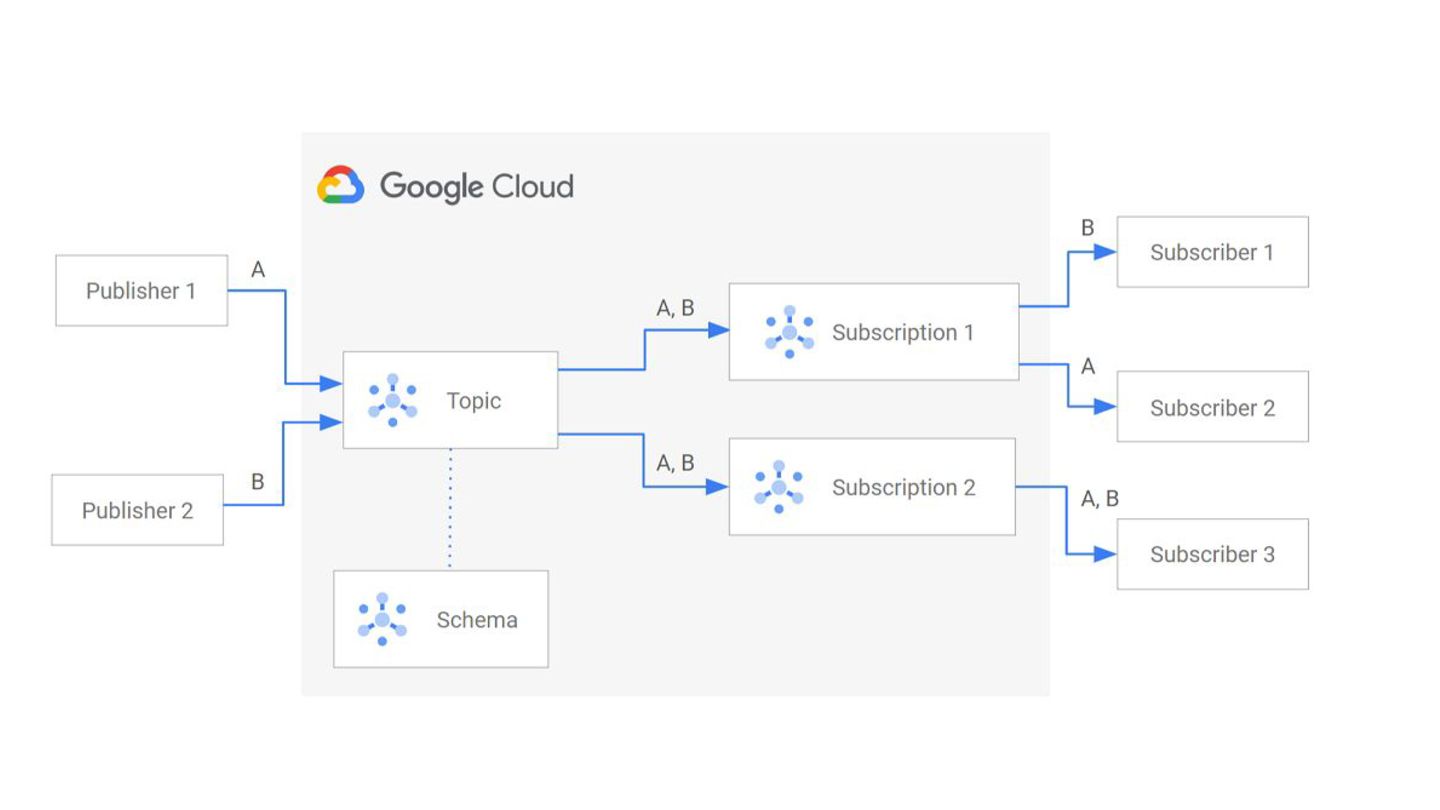
message?" ◦ Yes! This is the "Fan-Out" pattern. ◦ For example, you can send a "User Signed Up" message once, and have three completely different services (e.g. Emailer, Analytics Engine, and CRM Sync) all subscribe to it. ◦ They will each get their own copy of the message to process independently.
service. • "Serverless" Philosophy: No provisioning of instances or clusters. You just create a topic and go. Key Features: • Global Availability: A single topic can be accessed from anywhere in the world without complex region replication configuration. • Auto-scaling: Automatically handles traffic from zero to millions of messages per second. • Delivery Modes: ◦ Pull: Consumer requests messages. ◦ Push: Pub/Sub initiates requests to your endpoint (e.g., a Cloud Function or Cloud Run container). • Message State: Tracks individual message acknowledgments (per-message state).
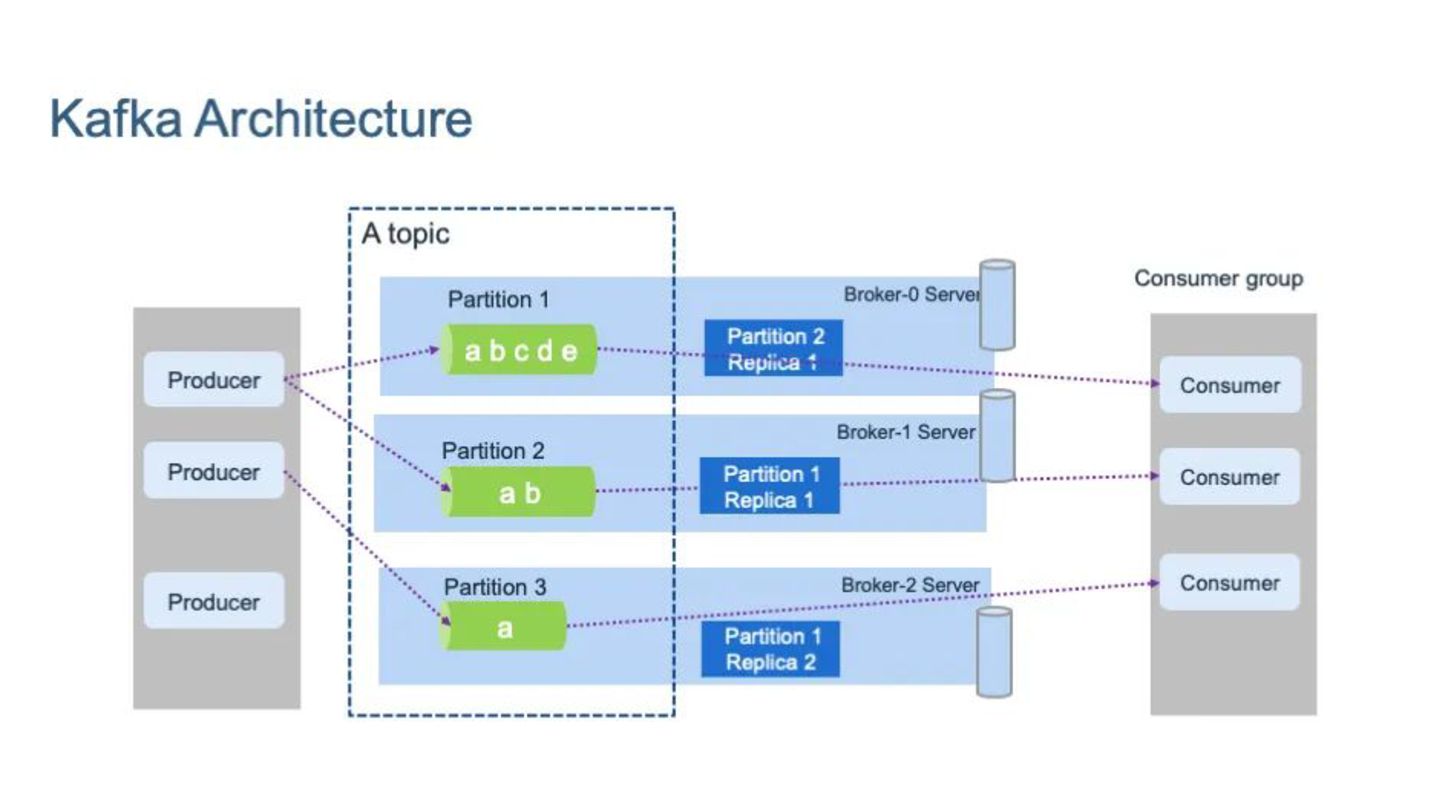
streaming. • Designed originally by LinkedIn for massive throughput. Google Cloud offers its own Managed Kafka Service Architecture (The Log): • Distributed Commit Log: Messages are appended to the end of a log file. • Partitions: Topics are split into partitions to allow parallel processing. • Ordering: Strict ordering is guaranteed within a partition. Key Mechanics: • Retention: Messages are kept for a set time (e.g., 7 days) regardless of whether they have been read. • Offsets: Consumers track their own position (offset) in the log. This allows them to "rewind" and "replay" data.
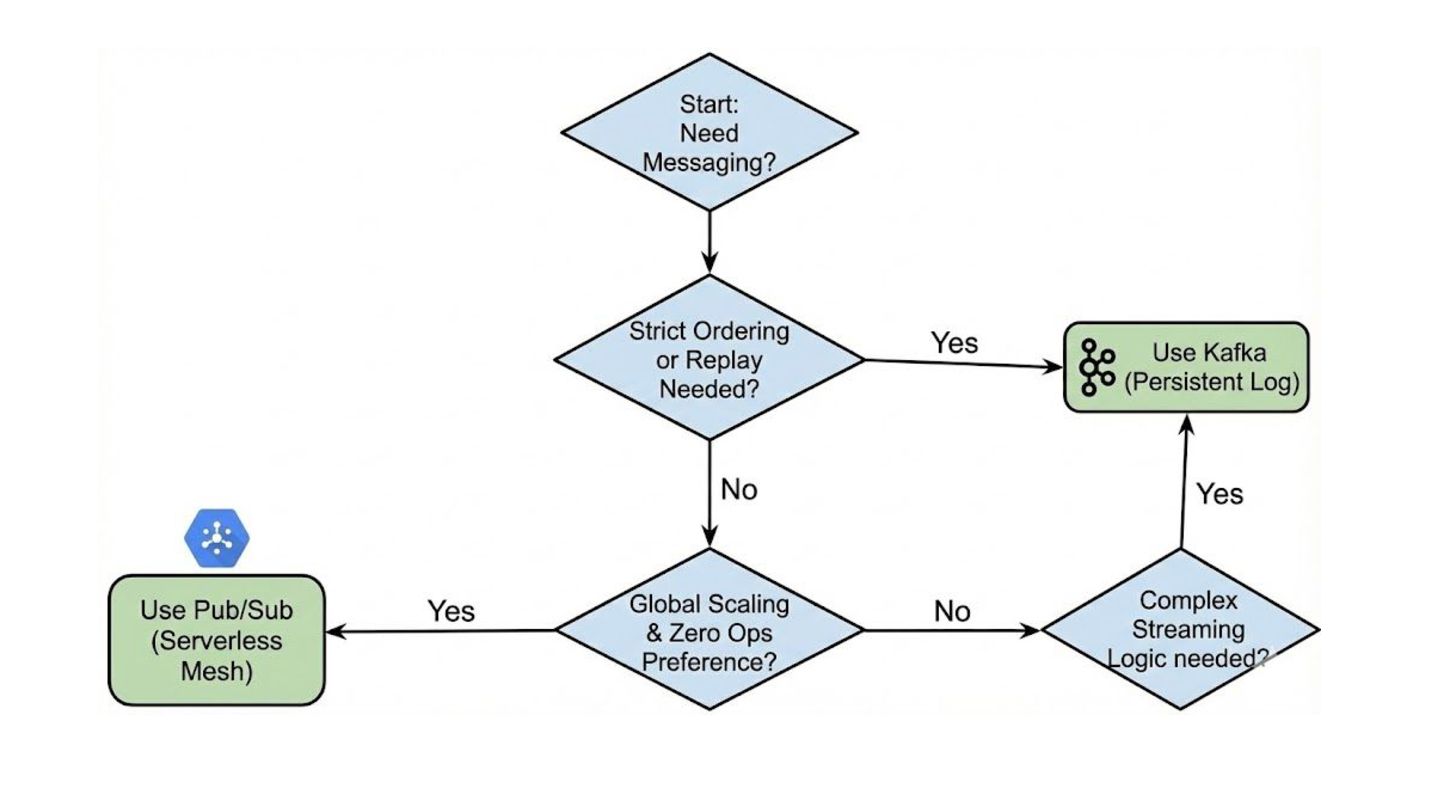
"Zero-Ops": You don't want to manage clusters, partitions, or sizing. Variable Traffic: Your workload is unpredictable or "spiky" (Pub/Sub scales from 0 to millions instantly). Global Ingestion: You need to aggregate data from multiple regions effortlessly. Per-Message Processing: You need to track every single message independently (with built-in Dead Letter Queues). Choose Kafka if: Lift & Shift: You have existing Kafka applications and want to move to the cloud without rewriting code. Strict Ordering & Replay: You need strict ordering at high throughput or indefinite data retention (Event Sourcing). Low Latency: You require end-to-end latency in the ~10ms range (vs. ~100ms for Pub/Sub). Multi-Cloud: You need to run the exact same messaging stack on AWS, Azure, and On-Prem.
I sent them?" ◦ Answer: It depends on the tool. ◦ Kafka: Yes, it guarantees order (within a partition). This is essential for things like banking ledgers. ◦ Pub/Sub: Generally No. To achieve infinite scaling, it might deliver Message B before Message A. If strict order matters for you, you must use specific "ordering keys" (which comes with some limitations).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}