Opening up Research and Data Day1 - FORCE11 Scholarly Communication Institute (FSCI)
FORCE11 Scholarly Communications Institute at the University of California, San Diego is a week long summer training course on improving research and communication
California, San Diego Slides Link: http://tiny.cc/fsci-mt6-1 Gaurav Godhwani | Handle: @gggodhwani Technical Lead - Open Budgets India - CBGA | Chapter Lead - DataKind Bangalore
1: Planning Open Data Pipelines - Session 2: Developing Key Components of Open Data Pipelines - Session 3: Scaling Up - Session 4: Learning, Sharing and Iterating
can be shared by large groups of people without making anybody poorer.” ― Aaron Swartz, The Boy Who Could Change the World: The Writings of Aaron Swartz Image Source: Aaron Swartz 3 at Boston Wikipedia Meetup | CC-BY-SA 3.0 Sage Ross https://commons.wikimedia.org/wiki/File:Aaron_Swartz_3_at_Boston_Wikipedia_Meetup, _2009-08-18.jpg
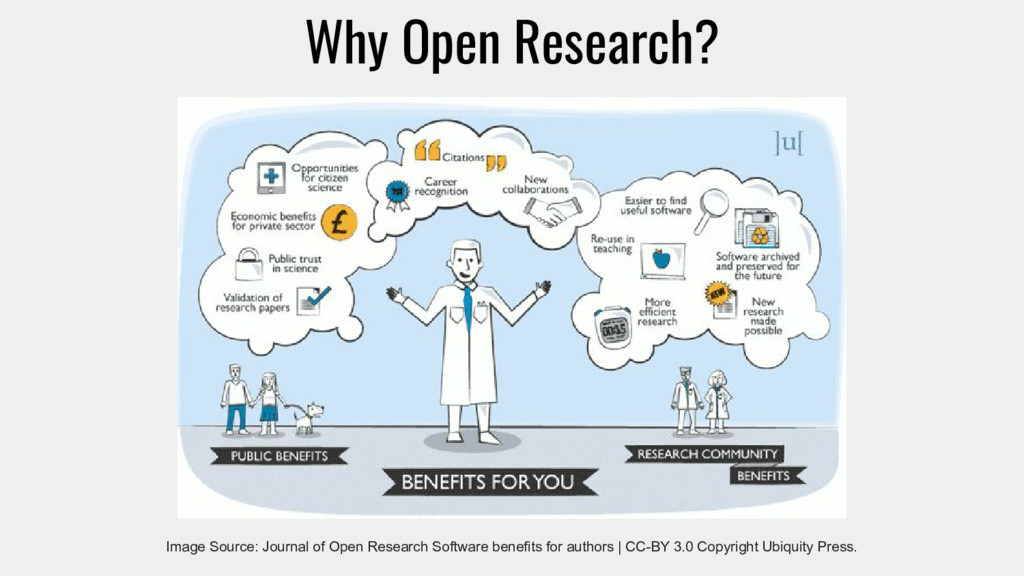
scientific research more transparent, more collaborative and more efficient. A central aspect to it is to provide open access to scientific information, especially to the research published in scholarly journals and to the underlying data, much of which traditional science tends to hide away. Other aspects are more open forms of collaboration and engagement with a wider audience, including citizen scientists and the public at large.” - Wikipedia, https://en.wikipedia.org/wiki/Open_research
GDP by around 1.1% points (almost 55%) of the G20’s 2% growth target over five years. Source: The G20 and Open Data: Open for Business https://www.omidyar.com/sites/default/files/file.../ON%20Report_061114_FNL.pdf Why Open Data?
trillion cumulatively over the next five years. Source: The G20 and Open Data: Open for Business https://www.omidyar.com/sites/default/files/file.../ON%20Report_061114_FNL.pdf Why Open Data?
that it is freely available on the public Internet permitting any user to download, copy, analyse, re-process, pass them to software or use them for any other purpose without financial, legal, or technical barriers other than those inseparable from gaining access to the internet itself.” - https://pantonprinciples.org/
Data Types in Research - Open Data life cycle and its Key Elements - Data Search Techniques - Open Data Management Plans and Policies - Exploring similar projects in your field [Brief Discussion]
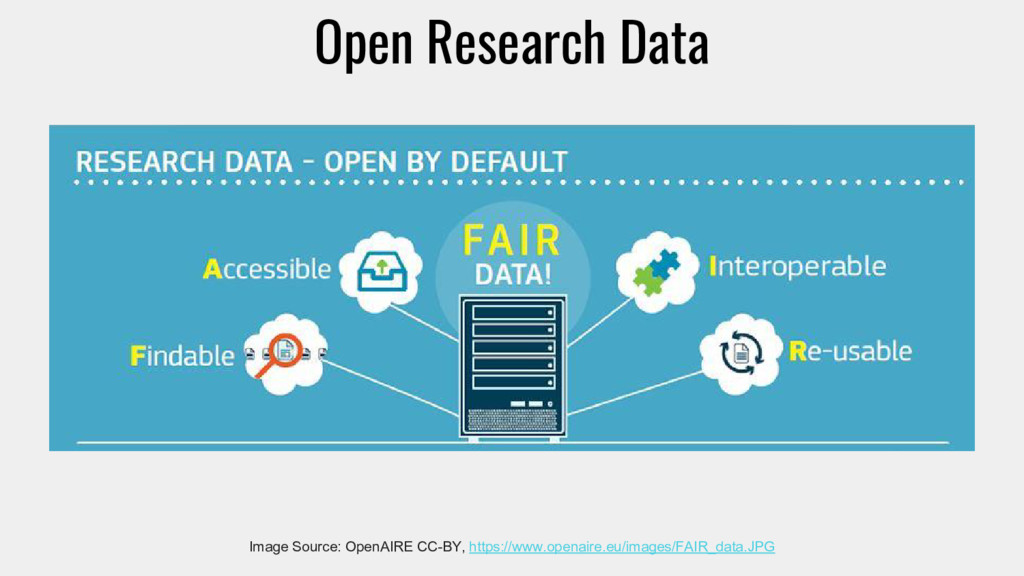
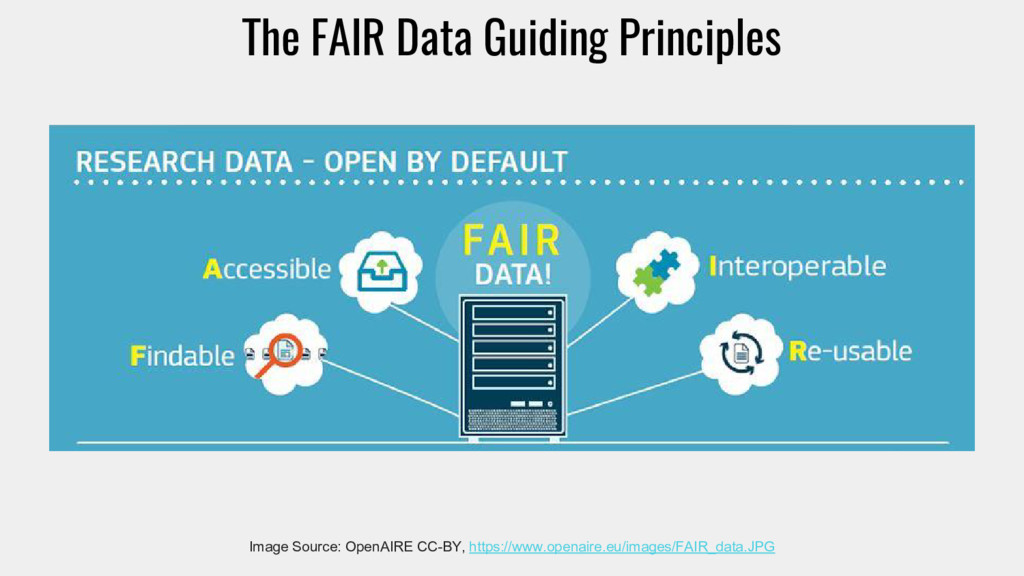
are assigned a globally Unique and Persistent Identifier F2. data are described with rich metadata (defined by R1 below) F3. metadata clearly and explicitly include the identifier of the data it describes F4. (meta)data are registered or indexed in a searchable resource Source: The FAIR Guiding Principles for scientific data management and stewardship CC-BY 4.0 https://www.nature.com/articles/sdata201618
are retrievable by their identifier using a standardized communications protocol A1.1 the protocol is open, free, and universally implementable A1.2 the protocol allows for an authentication and authorization procedure, where necessary A2. metadata are accessible, even when the data are no longer available Source: The FAIR Guiding Principles for scientific data management and stewardship CC-BY 4.0 https://www.nature.com/articles/sdata201618
use a formal, accessible, shared, and broadly applicable language for knowledge representation. I2. (meta)data use vocabularies that follow FAIR principles I3. (meta)data include qualified references to other (meta)data Source: The FAIR Guiding Principles for scientific data management and stewardship CC-BY 4.0 https://www.nature.com/articles/sdata201618
are richly described with a plurality of accurate and relevant attributes R1.1. (meta)data are released with a clear and accessible data usage license R1.2. (meta)data are associated with detailed provenance R1.3. (meta)data meet domain-relevant community standards Source: The FAIR Guiding Principles for scientific data management and stewardship CC-BY 4.0 https://www.nature.com/articles/sdata201618
Simulation - Derived or compiled - Reference or canonical Source: University of Virginia, Research Data Services + Sciences - Data Types & File Formats http://data.library.virginia.edu/data-management/plan/format-types/
or recaptured. Sometimes called 'unique data' - Example include sensor data, human observation, and survey results Source: University of Virginia, Research Data Services + Sciences - Data Types & File Formats http://data.library.virginia.edu/data-management/plan/format-types/ Key Data Types in Research
conditions - Usually reproducible, but expensive to do so - Examples include gene sequences, chromatograms, spectroscopy Source: University of Virginia, Research Data Services + Sciences - Data Types & File Formats http://data.library.virginia.edu/data-management/plan/format-types/ Key Data Types in Research
or theoretical systems - Models and metadata where the input may be of greater importance than the output - Examples include climate models, economic models, systems engineering. Source: University of Virginia, Research Data Services + Sciences - Data Types & File Formats http://data.library.virginia.edu/data-management/plan/format-types/ Key Data Types in Research
or aggregated from multiple sources - Reproducible, but very expensive - Examples include text and data mining, compiled databases, 3D models. Source: University of Virginia, Research Data Services + Sciences - Data Types & File Formats http://data.library.virginia.edu/data-management/plan/format-types/ Key Data Types in Research
usually peer-reviewed, and often published and curated. - Examples include gene sequence databanks, census data, chemical structures. Source: University of Virginia, Research Data Services + Sciences - Data Types & File Formats http://data.library.virginia.edu/data-management/plan/format-types/ Key Data Types in Research
or What? ◦ Social Unit: This is the population that you want to study 2) When? ◦ Time: This is the period of time you want to study 3) Where? ◦ Space: Geography or place Source: Michigan State University, How to find Data & Statistics http://libguides.lib.msu.edu/c.php?g=96631&p=626754
Repositories (Open Access Directory) ◦ Open data repositories from multiple academic disciplines. ◦ URL: http://oad.simmons.edu/oadwiki/Data_repositories • re3data.org: Registry of Research Data Repositories ◦ re3data.org is a global registry of research data repositories that covers research data repositories from different academic disciplines. Data Search Techniques Source: Michigan State University, How to find Data & Statistics http://libguides.lib.msu.edu/c.php?g=96631&p=626754
◦ figshare.com is a repository where users can make all of their research outputs available in a citable, shareable and discoverable manner • Open Science Framework ◦ A scholarly commons to connect and publish the entire research cycle ◦ URL: https://osf.io/ Data Search Techniques Source: CC-BY 3.0 How to be a Modern Scientist http://leanpub.com/modernscientist
Dataverse ◦ Find and cite data across all research fields ◦ URL: https://dataverse.harvard.edu/ • Find data from variety of field specific data repositories Data Search Techniques Source: CC-BY 3.0 How to be a Modern Scientist http://leanpub.com/modernscientist
working with new data repository ensure: ◦ been around for a while ◦ have a track record of managing data ◦ make their pricing structure clear if they charge Data Search Techniques Source: CC-BY 3.0 How to be a Modern Scientist http://leanpub.com/modernscientist
and publish this type of data? ◦ Government Agencies ◦ Non-Government Organizations ◦ Academic Institutions ◦ Private Sector Data Search Techniques Source: Michigan State University, How to find Data & Statistics http://libguides.lib.msu.edu/c.php?g=96631&p=626754
Bibliographies • Library Indexes • Library Catalog Data Search Techniques Source: Michigan State University, How to find Data & Statistics http://libguides.lib.msu.edu/c.php?g=96631&p=626754
Description 1 Data description A description of the information to be gathered; the nature and scale of the data that will be generated or collected. 2 Existing data A survey of existing data relevant to the project and a discussion of whether and how these data will be integrated. 3 Format Formats in which the data will be generated, maintained, and made available, including a justification for the procedural and archival appropriateness of those formats. 4 Metadata A description of the metadata to be provided along with the generated data, and a discussion of the metadata standards used. Source: Inter-university Consortium for Political and Social Research (ICPSR), Institute for Social Research University of Michigan http://www.icpsr.umich.edu/icpsrweb/content/datamanagement/dmp/elements.html
Description 5 Storage and backup Storage methods and backup procedures for the data, including the physical and cyber resources and facilities that will be used for the effective preservation and storage of the research data. 6 Security A description of technical and procedural protections for information, including confidential information, and how permissions, restrictions, and embargoes will be enforced. 7 Responsibility Names of the individuals responsible for data management in the research project. 8 License Select appropriate Open Data License(s) for various data elements of the project Source: Inter-university Consortium for Political and Social Research (ICPSR), Institute for Social Research University of Michigan http://www.icpsr.umich.edu/icpsrweb/content/datamanagement/dmp/elements.html
Description 9 Access and sharing A description of how data will be shared, including access procedures, embargo periods, technical mechanisms for dissemination and whether access will be open or granted only to specific user groups. A timeframe for data sharing and publishing should also be provided. 10 Audience The potential secondary users of the data. 11 Selection and retention periods A description of how data will be selected for archiving, how long the data will be held, and plans for eventual transition or termination of the data collection in the future. 12 Archiving and preservation The procedures in place or envisioned for long-term archiving and preservation of the data, including succession plans for the data should the expected archiving entity go out of existence. Source: Inter-university Consortium for Political and Social Research (ICPSR), Institute for Social Research University of Michigan http://www.icpsr.umich.edu/icpsrweb/content/datamanagement/dmp/elements.html
Description 13 Ethics and privacy A discussion of how informed consent will be handled and how privacy will be protected, including any exceptional arrangements that might be needed to protect participant confidentiality, and other ethical issues that may arise. 14 Budget The costs of preparing data and documentation for archiving and how these costs will be paid. Requests for funding may be included. 15 Data organization How the data will be managed during the project, with information about version control, naming conventions, etc. 16 Quality Assurance Procedures for ensuring data quality during the project. 17 Legal requirements A listing of all relevant federal or funder requirements for data management and data sharing. Source: Inter-university Consortium for Political and Social Research (ICPSR), Institute for Social Research University of Michigan http://www.icpsr.umich.edu/icpsrweb/content/datamanagement/dmp/elements.html
http://leanpub.com/modernscientist To maximize both the value of your data and your impact • Post both raw and tidy versions of your data • Post relevant metadata about experiments you performed in a README • README should ideally be a TXT or a Markup file • Post related code that can be used to analyze the data as you did in your paper.
Modern Scientist http://leanpub.com/modernscientist To maximize both the value of your data and your impact 1. The raw data 2. A tidy dataset 3. A code book describing each variable and its values in the tidy data set. 4. An explicit and exact recipe you used to go from 1 -> 2,3
Scientist http://leanpub.com/modernscientist Image Source: CC 3.0 BY-SA https://en.wikipedia.org/wiki/Binary_file#/media/File:Wikipedia_favicon_hexdump.svg Examples of Raw Data • The strange binary file your measurement machine spits out
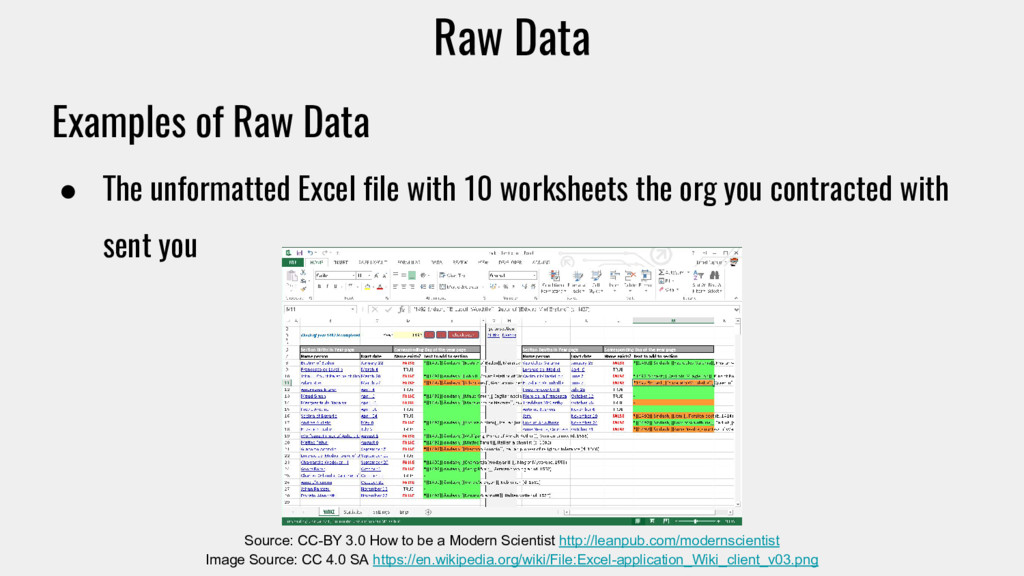
Scientist http://leanpub.com/modernscientist Image Source: CC 4.0 SA https://en.wikipedia.org/wiki/File:Excel-application_Wiki_client_v03.png Examples of Raw Data • The unformatted Excel file with 10 worksheets the org you contracted with sent you
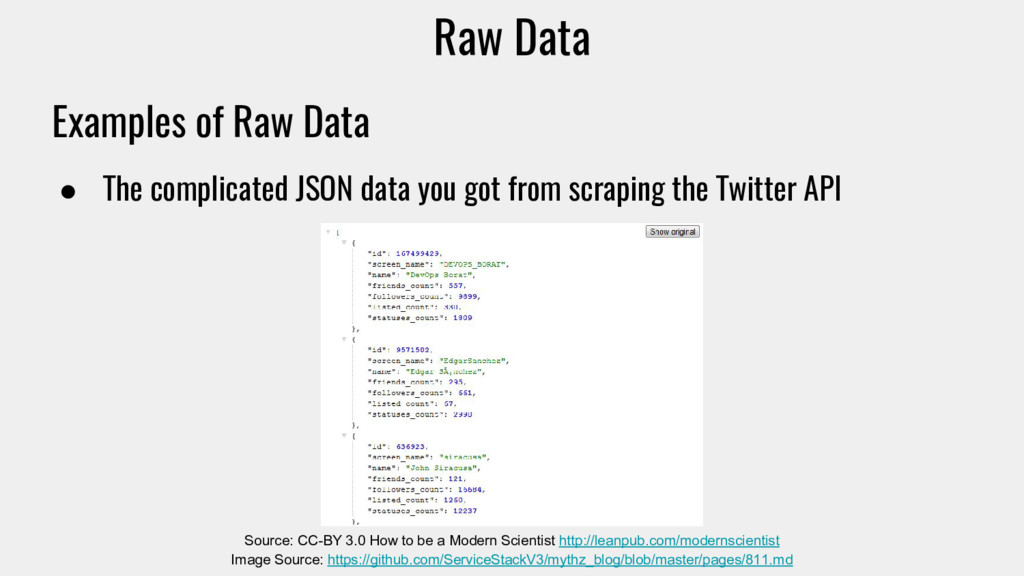
Scientist http://leanpub.com/modernscientist Image Source: https://github.com/ServiceStackV3/mythz_blog/blob/master/pages/811.md Examples of Raw Data • The complicated JSON data you got from scraping the Twitter API
Scientist http://leanpub.com/modernscientist Image Source: https://www.flickr.com/photos/nasacommons/9467782468 Examples of Raw Data • The hand-entered numbers you collected looking through a microscope
Scientist http://leanpub.com/modernscientist You know the raw data is in the right format if you: 1. Ran no software on the data 2. Did not manipulate any of the numbers in the data 3. You did not remove any data from the data set 4. You did not summarize the data in any way
Scientist http://leanpub.com/modernscientist Principles of Tidy Data: 1. Each variable you measure should be in one column 2. Each different observation of that variable should be in a different row 3. There should be one table for each “kind” of variable 4. If you have multiple tables, they should include a column in the table that allows them to be linked 5. Share the data in a CSV or TAB-delimited text file
Scientist http://leanpub.com/modernscientist A code book describes: 1. Study Design - Thorough description of how you collected the data 2. Information about the variables (including units!) in the data set not contained in the tidy data 3. Information about the summary choices you made 4. Information about the experimental study design you used 5. Should ideally be a TXT or a Markup file
else) that takes the raw data as input and produces the tidy data you are sharing as output. • Installation Notes (a TXT or a Markup file) • Contribution Guidelines (a TXT or a Markup file) • Pseudo Code explaining your process to non-programmers (a TXT or a Markup file) Instruction list/Script Source: CC-BY 3.0 How to be a Modern Scientist http://leanpub.com/modernscientist
Scientist http://leanpub.com/modernscientist Example: • Step 1 - take the raw file, run version 3.1.2 of summarize software with parameters a=1, b=2,c=3 • Step 2 - run the software separately for each sample • Step 3 - take column three of outputfile.out for each sample and that is the corresponding row in the output data set
Methodologies - Metadata standards - Open Data Ontology - Open Data Storage Structures & Schemas - Data Analysis and Outcomes - Open Source Codebase - Open Data Visualization
privacy and security - Open Data Quality Checks - Publishing Platforms - Open Data Licences - Open Issues and Bug Tracking - Indexing, Searching and Reusing Open Data - Changelog and Version Controlling
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}