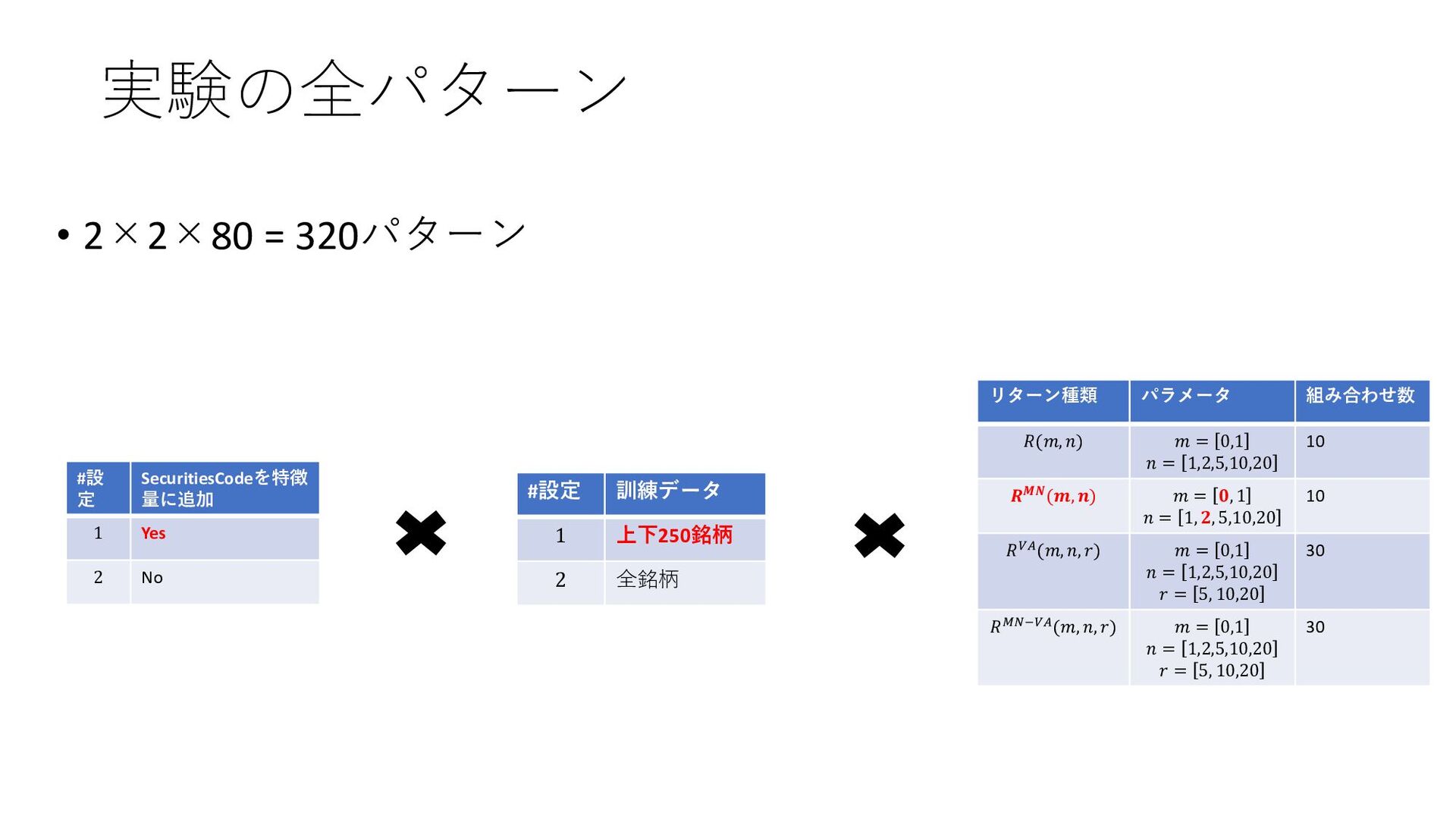
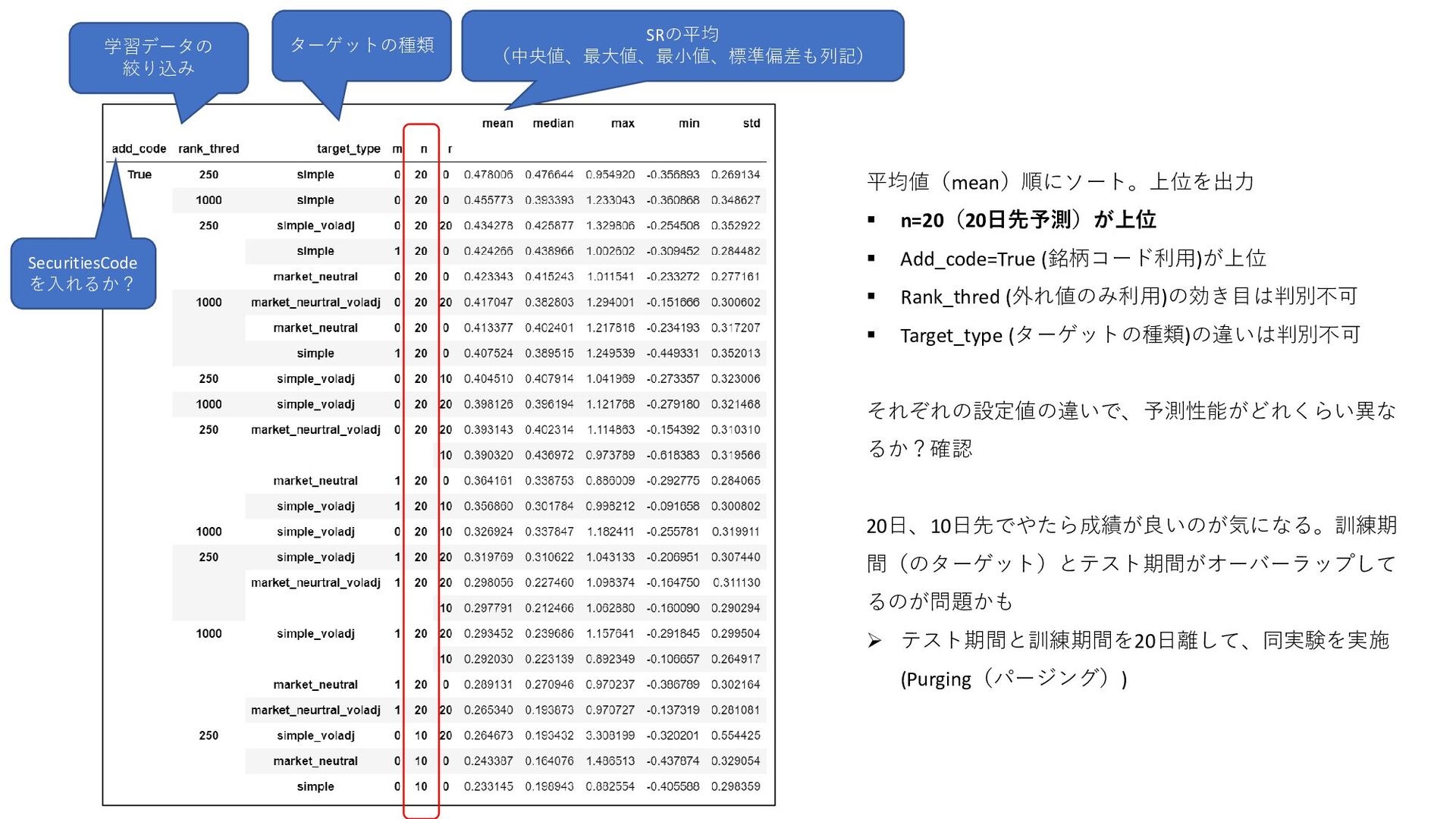
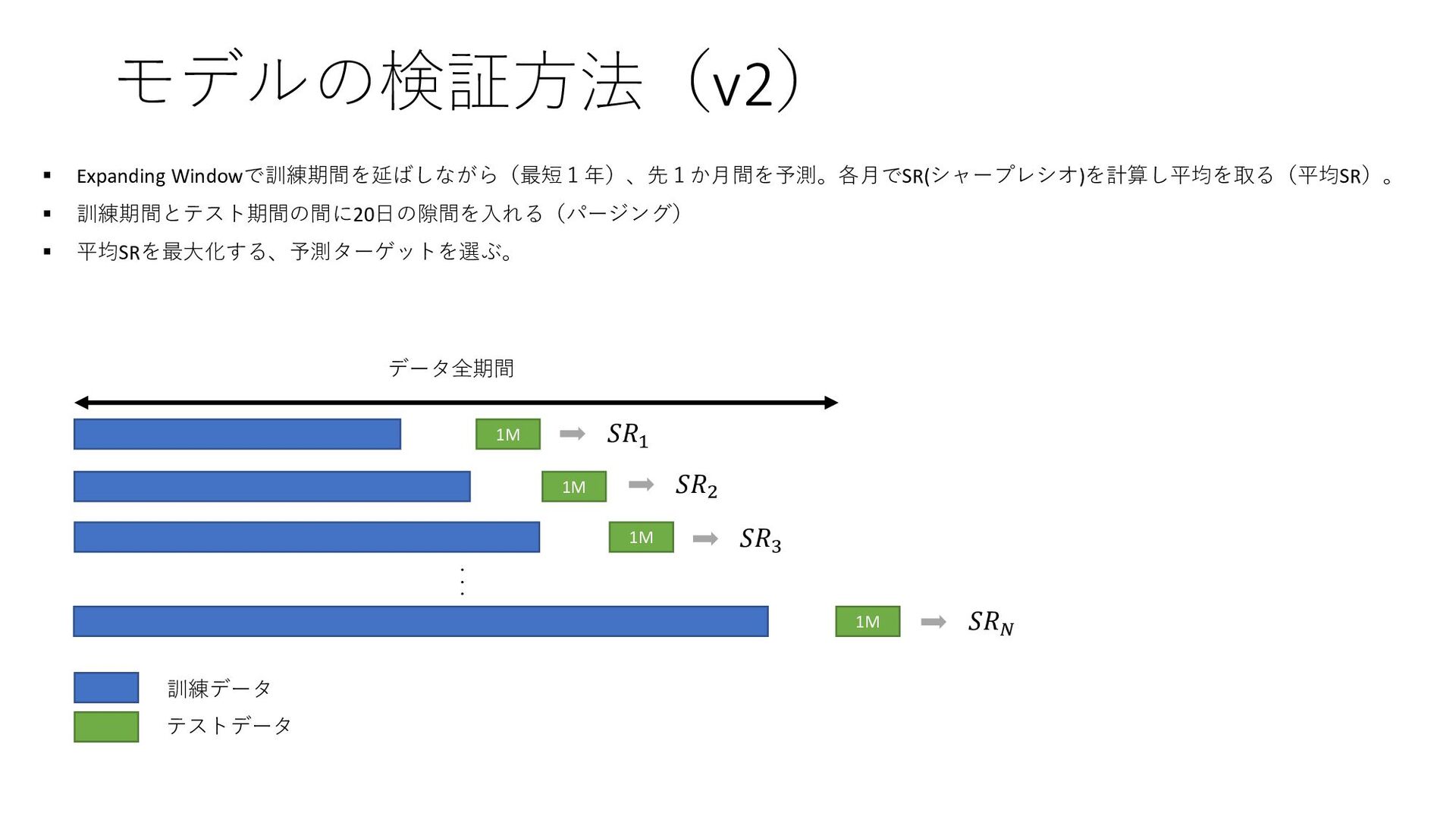
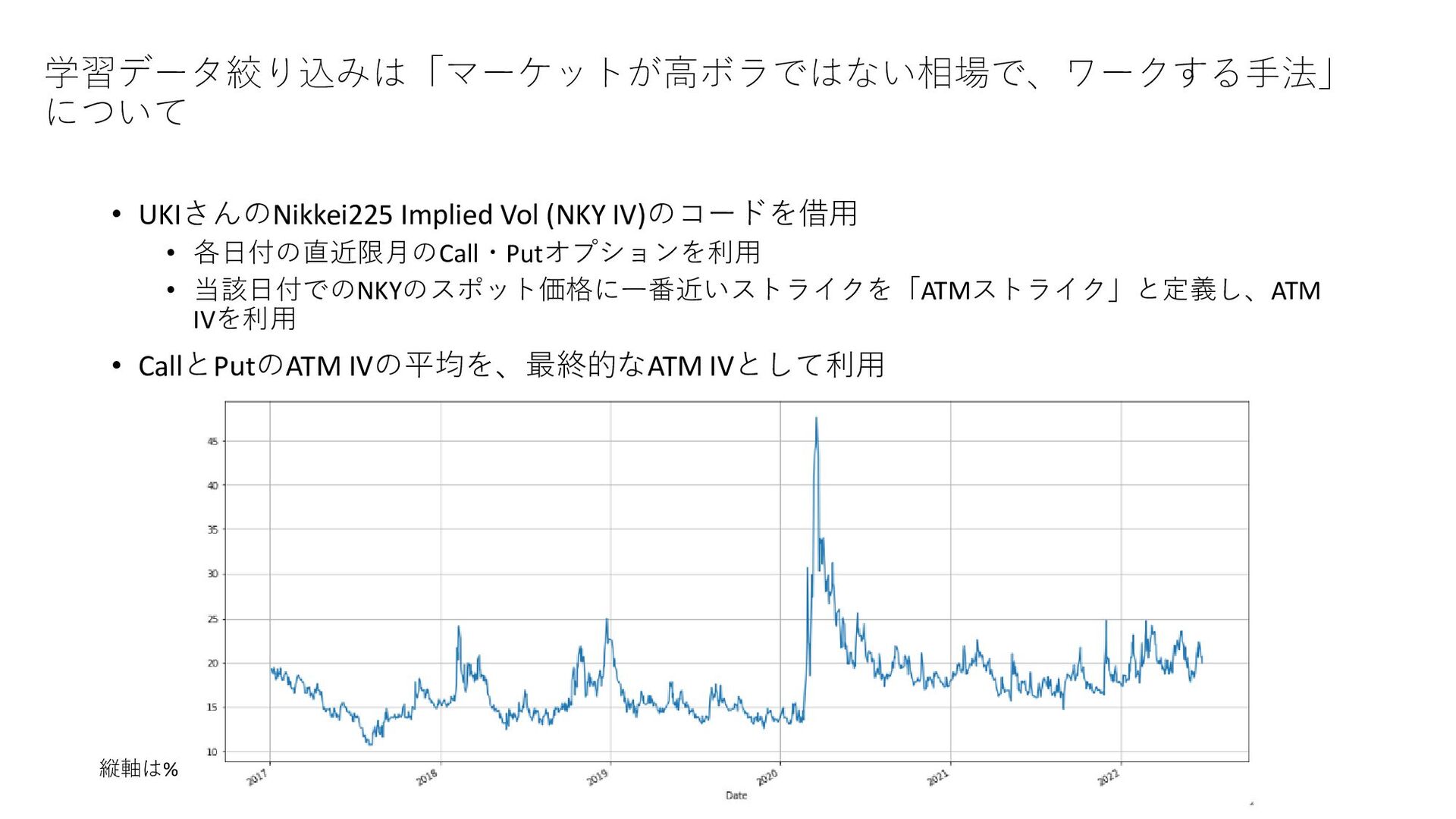
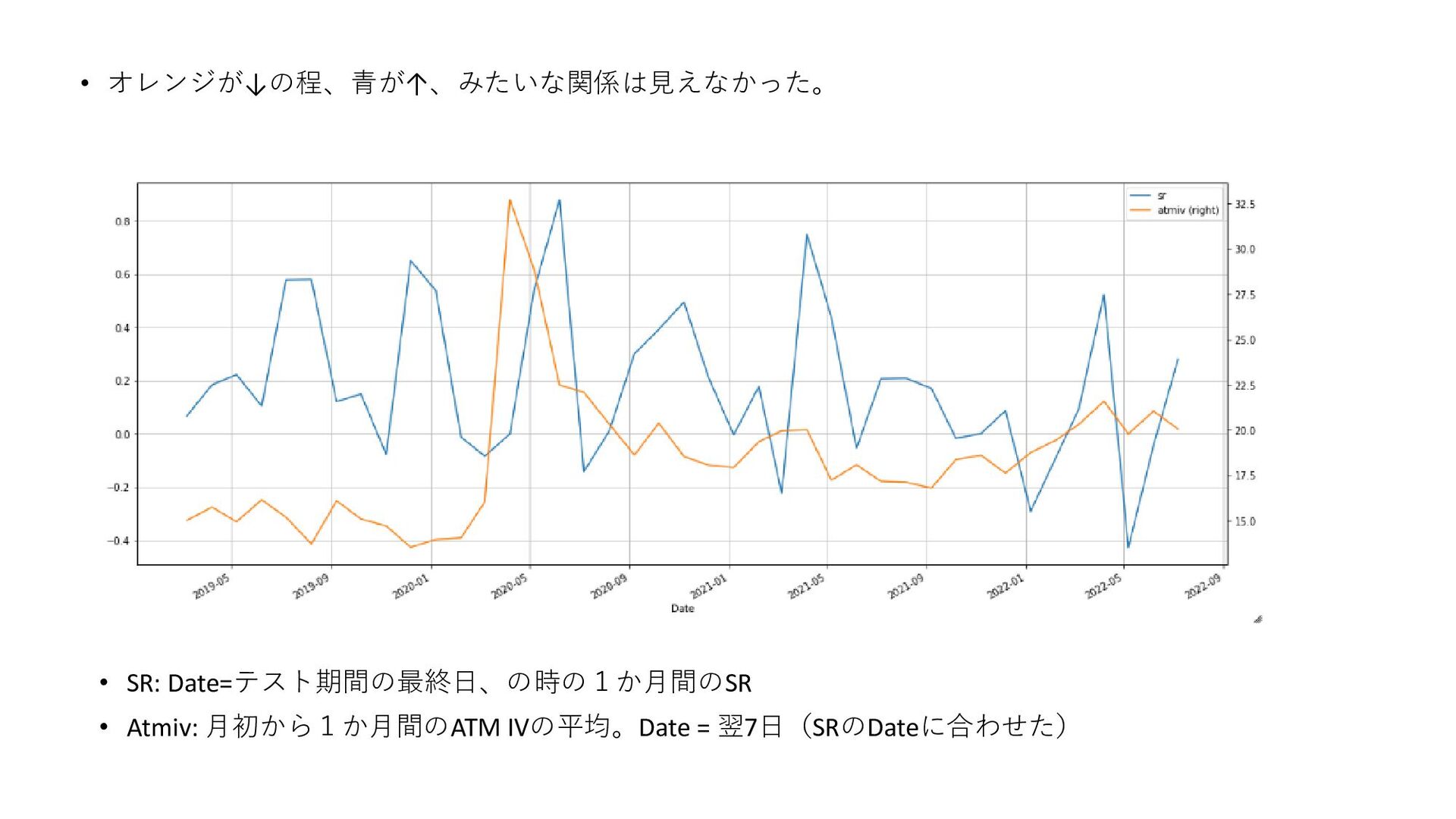
𝑅𝑀𝑁−𝑉𝐴 𝑅𝑘 𝑇, 𝑚, 𝑛 = 𝑃𝑘 𝑇+𝑛 −𝑃𝑘 𝑇+𝑚 𝑃𝑘 𝑇+𝑚 : 銘柄kの、m日先スタートの(n-m)日リターン 𝑅𝑘 𝑀𝑁 𝑇, 𝑚, 𝑛 = 𝑅𝑘 𝑇, 𝑚, 𝑛 − ത 𝑅 𝑇, 𝑚, 𝑛 : 銘柄kの、マーケットニュートラルなリターン 𝑅𝑘 𝑉𝐴 𝑇, 𝑚, 𝑛, 𝑟 = 𝑅𝑘 𝑇,𝑚,𝑛 𝑉𝑜𝑙𝑘 𝑇,𝑚,𝑛,𝑟 :銘柄kの、ボラティリティ調整済みリターン 𝑉𝑜𝑙𝑘 𝑇, 𝑚, 𝑛, 𝑟 = 1 𝑟 σ 𝑡=0 𝑟−1 𝑅𝑘 𝑇 − 𝑡, 𝑚, 𝑛 2 − 1 𝑟 σ 𝑡=0 𝑟−1 𝑅𝑘 𝑇 − 𝑡, 𝑚, 𝑛 2 :銘柄kの、ボラティリティ ത 𝑅 𝑇, 𝑚, 𝑛 :𝑅𝑘 𝑇, 𝑚, 𝑛 の、クロスセクション平均 2種類のリターンから1つ選ぶ ボラティリティ調整をするかどうか?(解法に書いてなかったが、アリかなと思って試した) 実験:4種類の組み合わせ 5位解法の予測ターゲット 𝑅𝑘 𝑀𝑁 𝑇, 0,2 :0日先スタートの2日マーケットニュートラルなリターン ▪ ターゲットを4種類考案。定量的に、5位解法が高精度であることを確認したい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
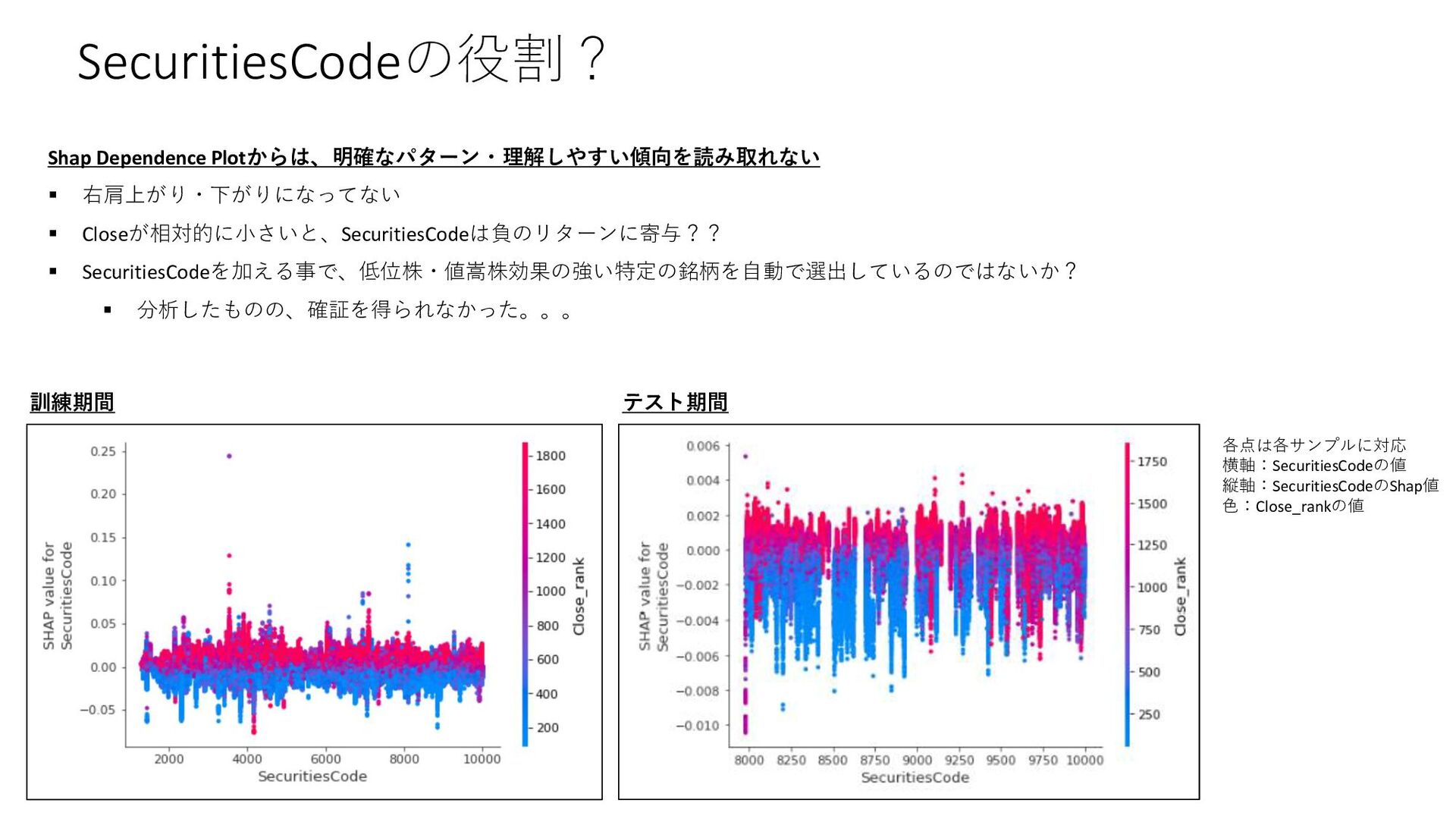{kind=link}
{kind=link}
{kind=link}
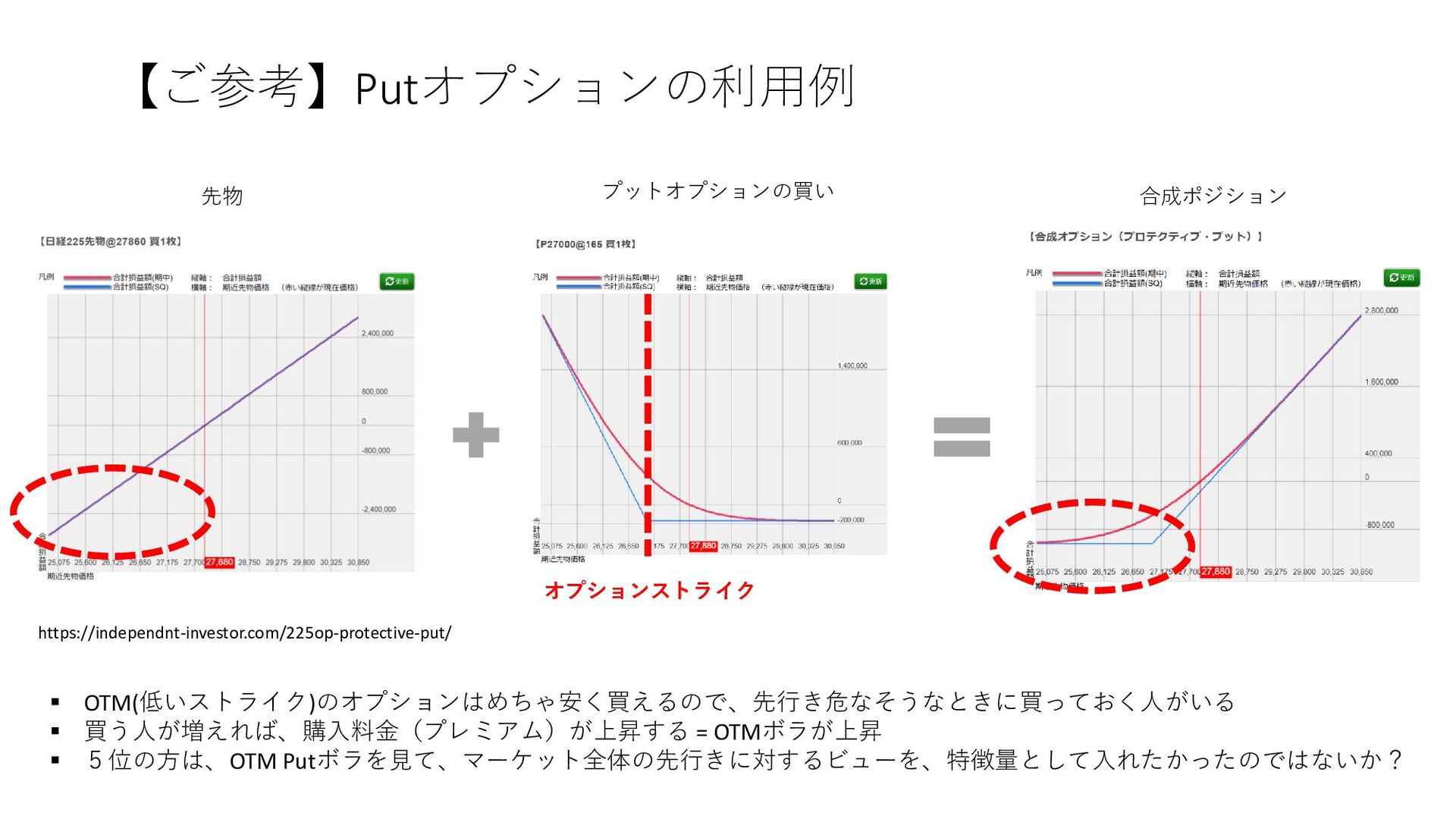{kind=link}
{kind=link}
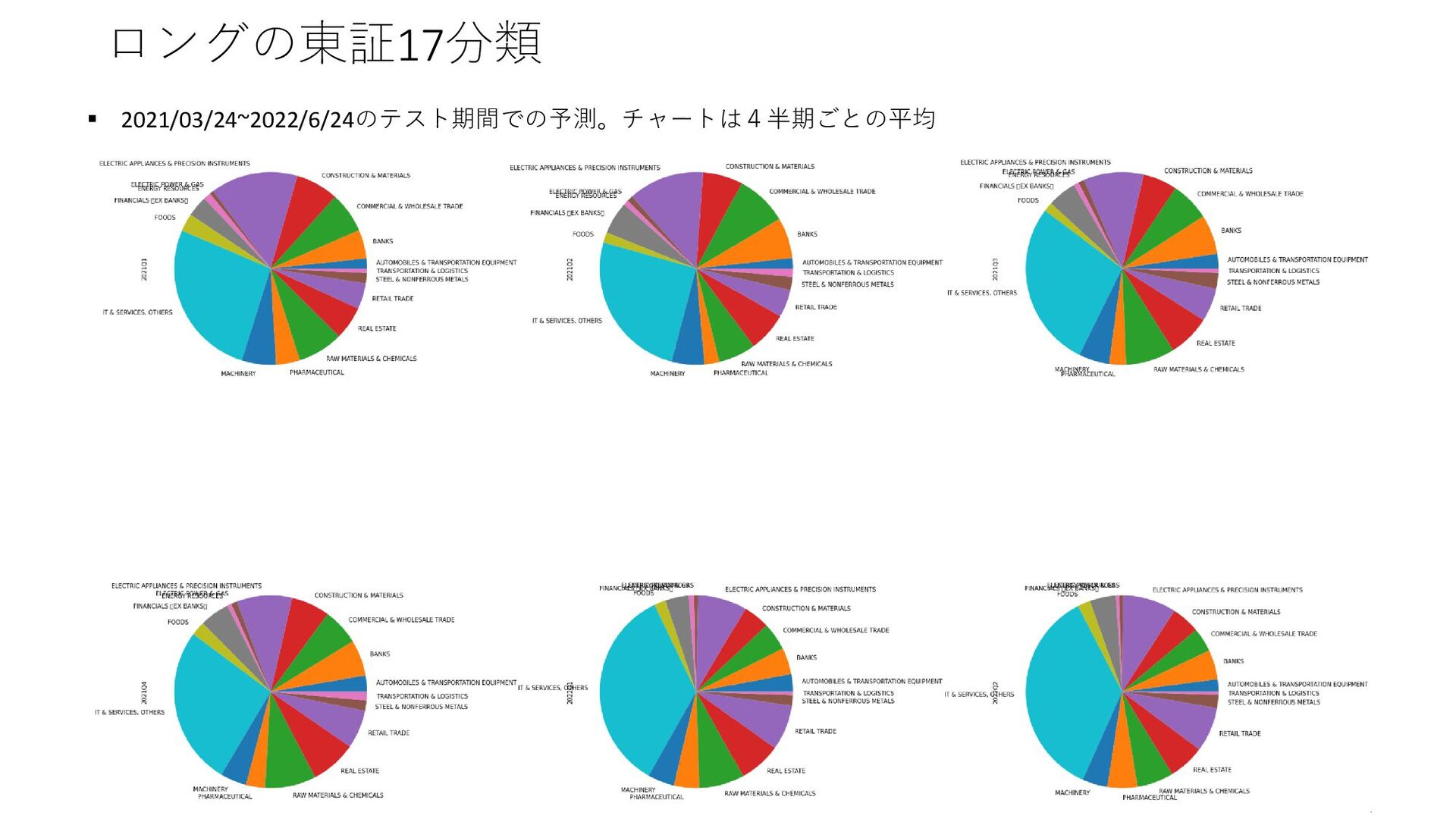{kind=link}
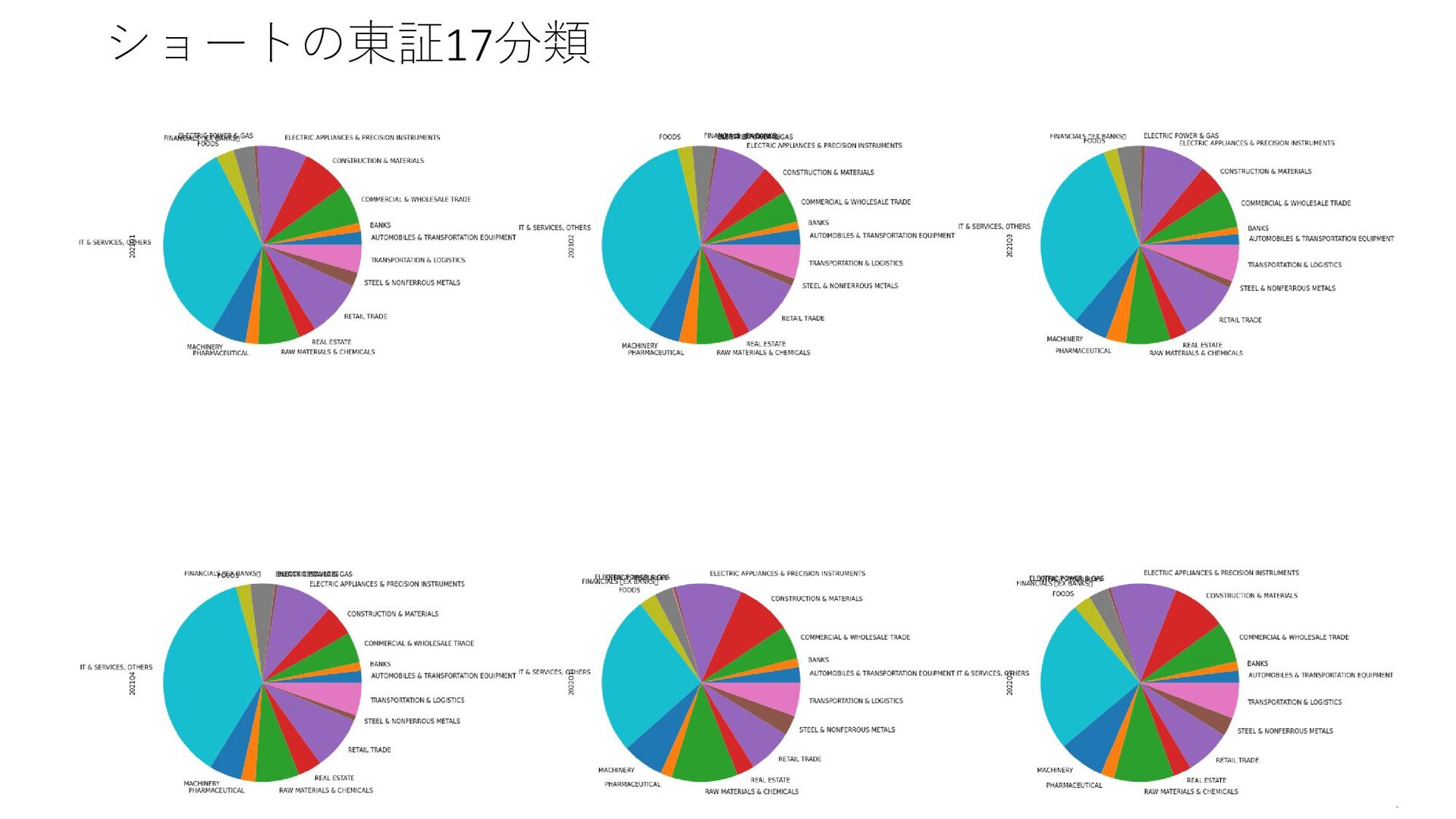{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}