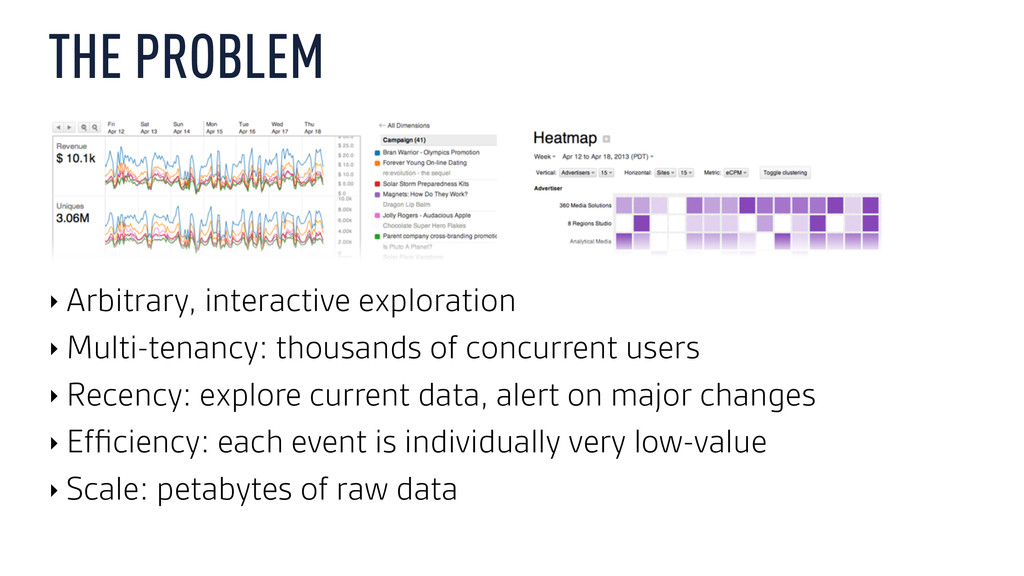
concurrent users ‣ Recency: explore current data, alert on major changes ‣ Efficiency: each event is individually very low-value ‣ Scale: petabytes of raw data
not just in what happened, but why ‣ Dig into the dataset using filters, aggregates, and comparisons ‣ All interesting queries cannot be determined upfront
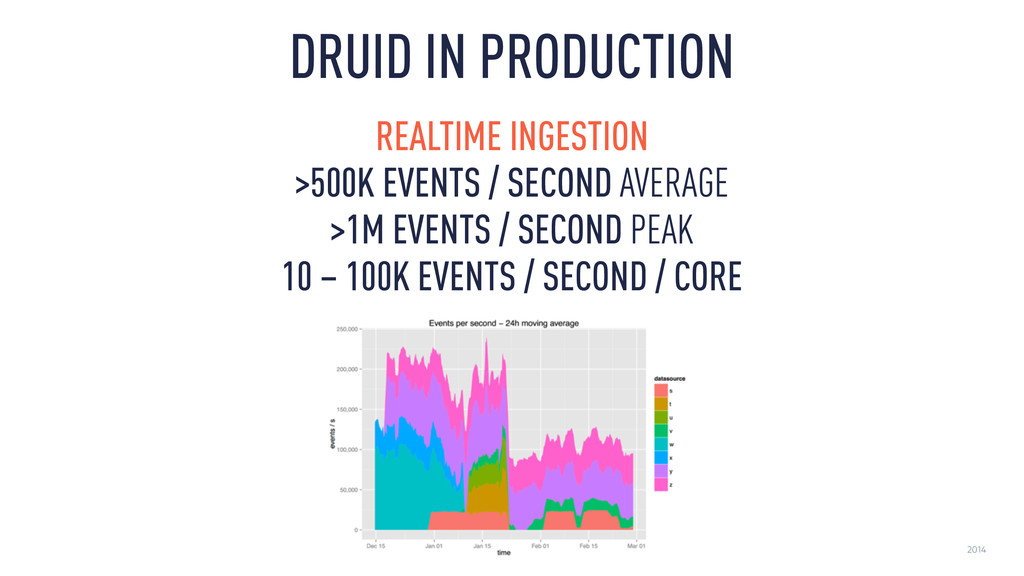
in 2012 ‣ Druid is an event stream database ‣ Low latency ingestion ‣ Ad-hoc aggregations (no precomputation) ‣ Can keep around a lot of history ‣ Community driven • 90+ contributors • In production at Yahoo!, Netflix, Metamarkets, many others
Questions often time-oriented ‣ Monitoring: CPU usage over the past 3 days, in 5-min buckets ‣ Web analytics: Top pages by number of unique users this month ‣ Performance: 99%ile latency over the past hour
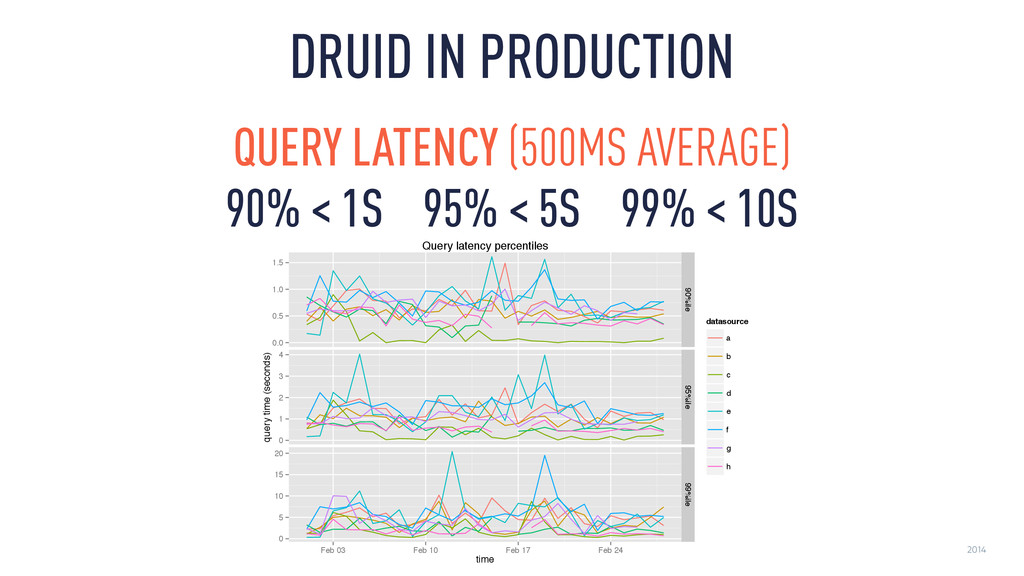
0 5 10 15 20 90%ile 95%ile 99%ile Feb 03 Feb 10 Feb 17 Feb 24 time query time (seconds) datasource a b c d e f g h Query latency percentiles QUERY LATENCY (500MS AVERAGE) 90% < 1S 95% < 5S 99% < 10S DRUID IN PRODUCTION
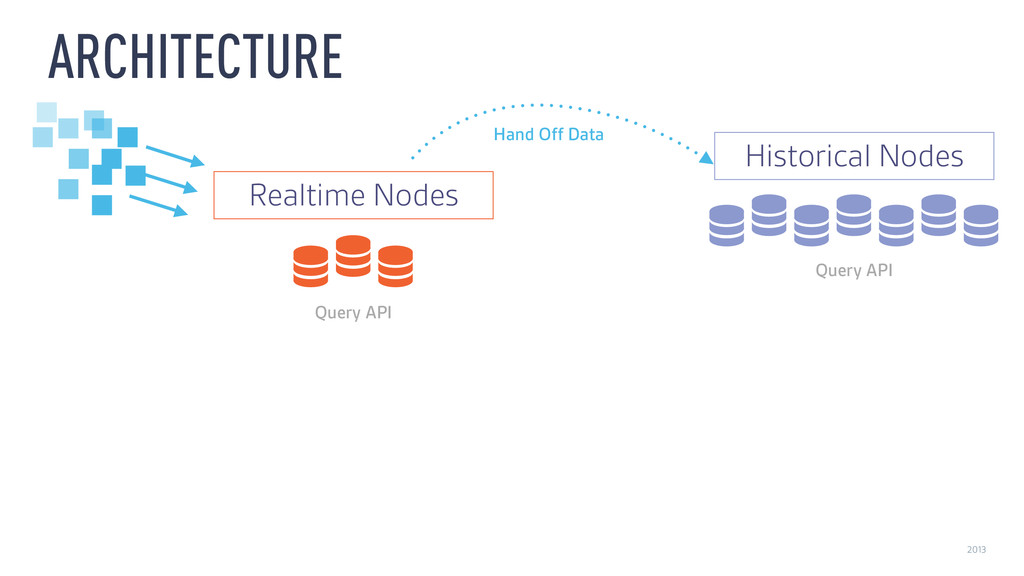
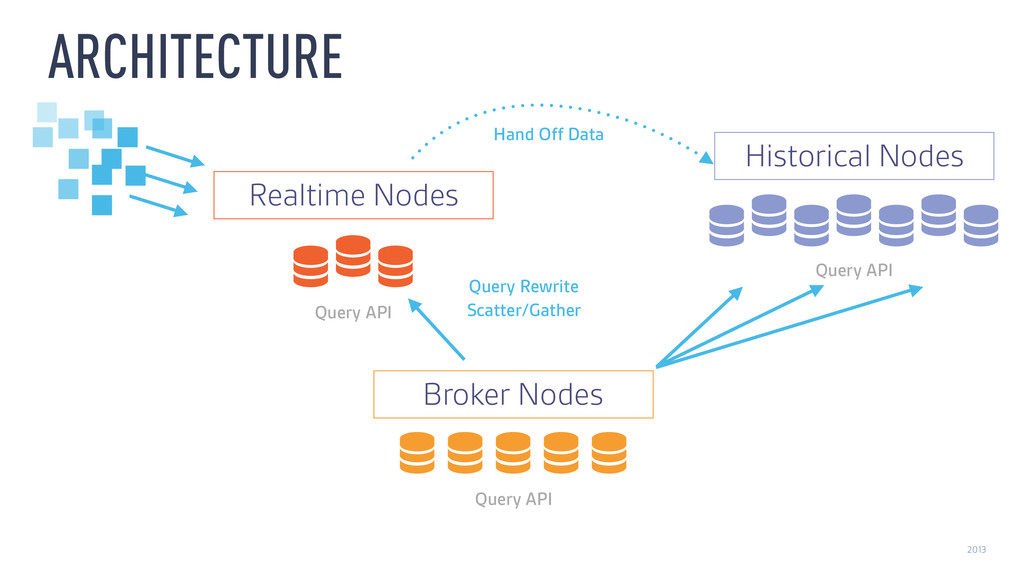
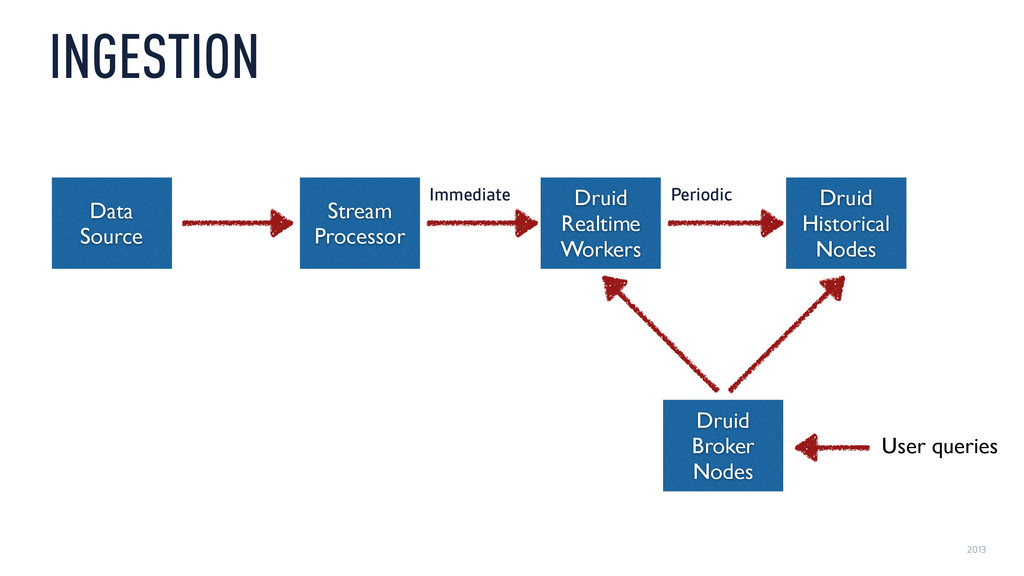
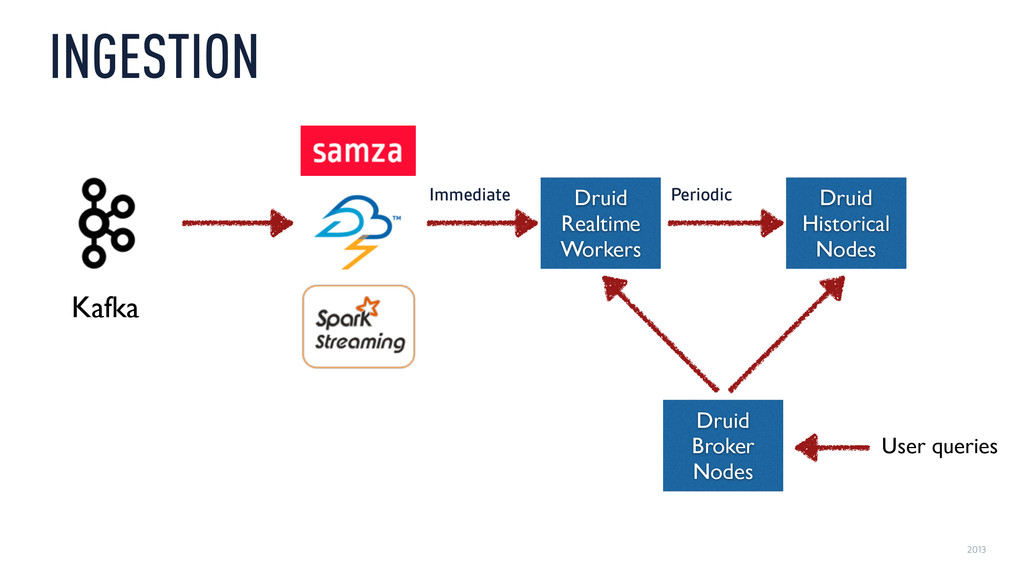
‣ Historical ‣ Time-partitioned, immutable, mmapped “Druid segments” ‣ Locality: Compute partial results on data nodes ‣ Fast filtering: Global time index, local CONCISE/Roaring bitmaps ‣ Fast scans: Column-oriented, compressed
‣ Real-time ‣ In-memory k/v tree + mmapped Druid segments ‣ Similar to memtable + sstable in RocksDB ‣ …but Druid segments can be queried much faster than sstables ‣ Periodically, merge and hand off Druid segments
2011-01-01T01:01:35Z bieberfever.com google.com Male USA 0 0.65 2011-01-01T01:03:63Z bieberfever.com google.com Male USA 0 0.62 2011-01-01T01:04:51Z bieberfever.com google.com Male USA 1 0.45 ... 2011-01-01T01:00:00Z ultratrimfast.com google.com Female UK 0 0.87 2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 0 0.99 2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 1 1.53
revenue 2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70 2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18 2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31 2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01 ‣ Truncate timestamps ‣ GroupBy over string columns (dimensions) ‣ Aggregate during ingestion when possible ‣ Can incrementally update aggregate rows
revenue 2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70 2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18 2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31 2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01 ‣ Shard segments by time Segment 2011-01-01T02/2011-01-01T03 Segment 2011-01-01T01/2011-01-01T02
impressions clicks revenue 2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70 2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18 ‣ Scan/load only what you need ‣ Per-column compression (dictionary encoding, LZ4) ‣ Per-column indexes (CONCISE/Roaring bitmaps)
than time series ‣ Druid is good for large datasets you want to query interactively ‣ Supporting infrastructure is a bit complex in current versions ‣ But not too bad if you already use Kafka ‣ …which you should!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LATENCY HEAT MAP ‣ Credit: Roger Hoover ([email protected])](https://files.speakerdeck.com/presentations/77d73baa9d154179bc1be4f89d24db05/slide_50.jpg){kind=link}
![LATENCY TREE MAP BY SERVICE ‣ Credit: Roger Hoover ([email protected])](https://files.speakerdeck.com/presentations/77d73baa9d154179bc1be4f89d24db05/slide_51.jpg){kind=link}
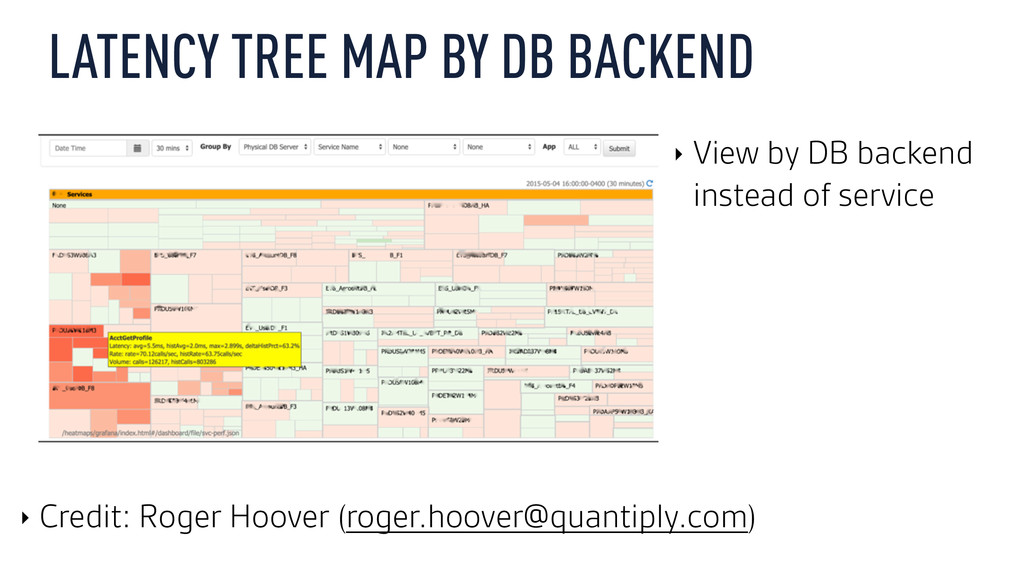{kind=link}
![DRILL DOWN ‣ Credit: Roger Hoover ([email protected]) ‣ Drill down](https://files.speakerdeck.com/presentations/77d73baa9d154179bc1be4f89d24db05/slide_53.jpg){kind=link}
![GRAFANA ‣ https://github.com/Quantiply/grafana-plugins/tree/master/ features/druid ‣ Written by Roger Hoover ([email protected])](https://files.speakerdeck.com/presentations/77d73baa9d154179bc1be4f89d24db05/slide_54.jpg){kind=link}
![GRAFANA ‣ Credit: Roger Hoover ([email protected])](https://files.speakerdeck.com/presentations/77d73baa9d154179bc1be4f89d24db05/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
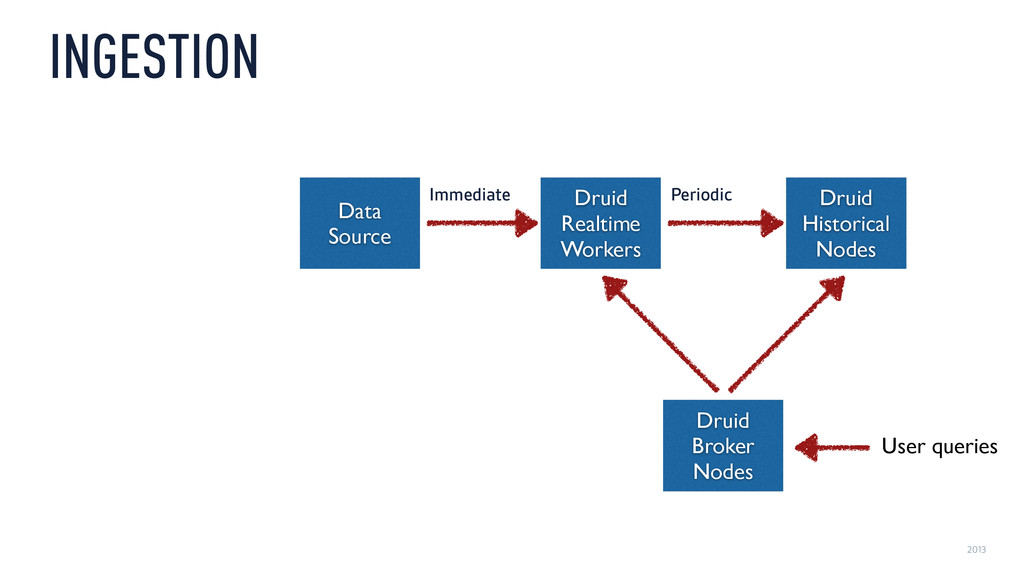{kind=link}
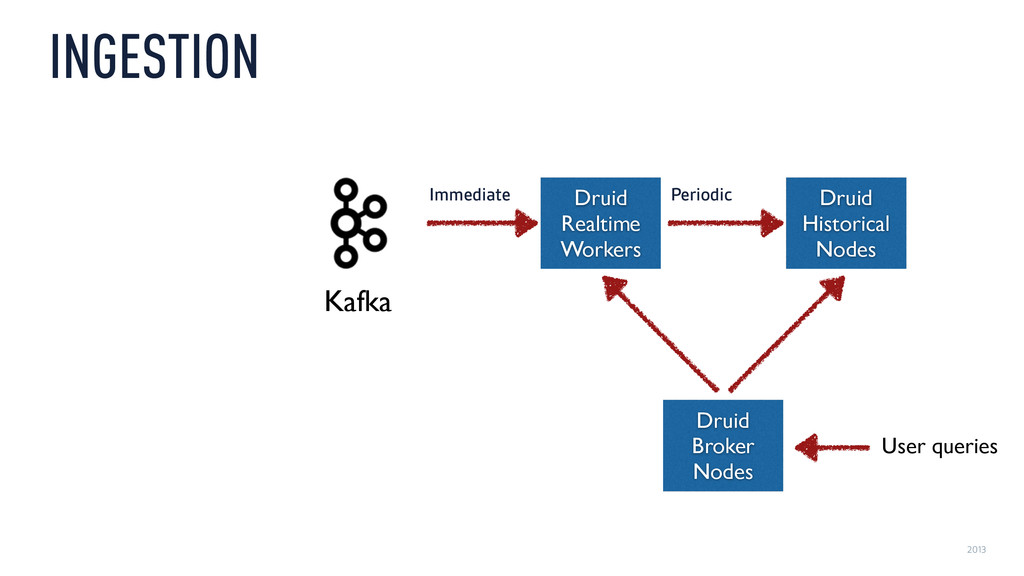{kind=link}
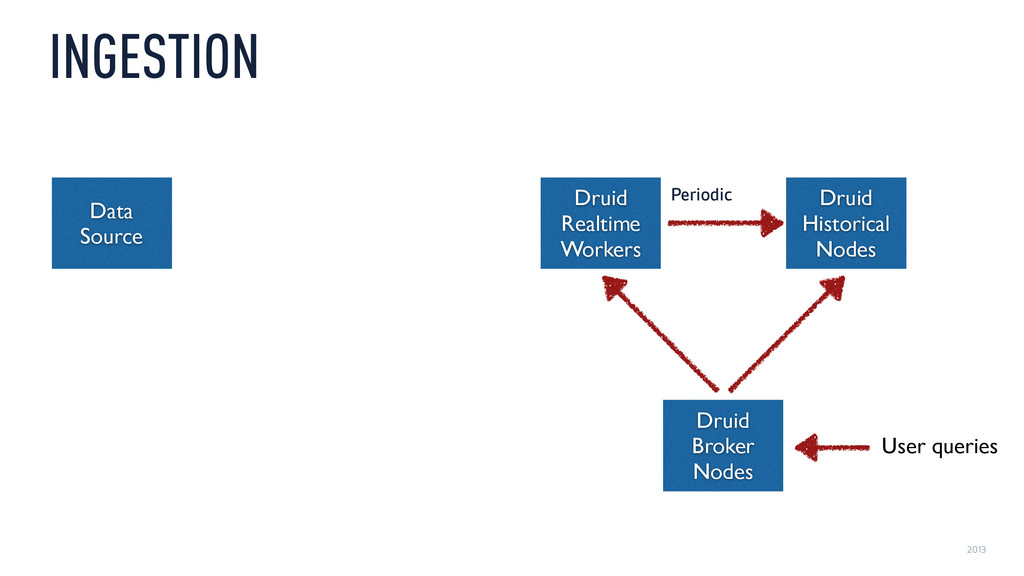{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}