get same results Isolation - concurrent changes result in the same end state as serial changes Durability - data not lost during failures Monday, March 18, 13
2000 Symposium on Principles of Distributed Computing Primarily about distributed systems, but can apply to single system scenarios as well. Monday, March 18, 13
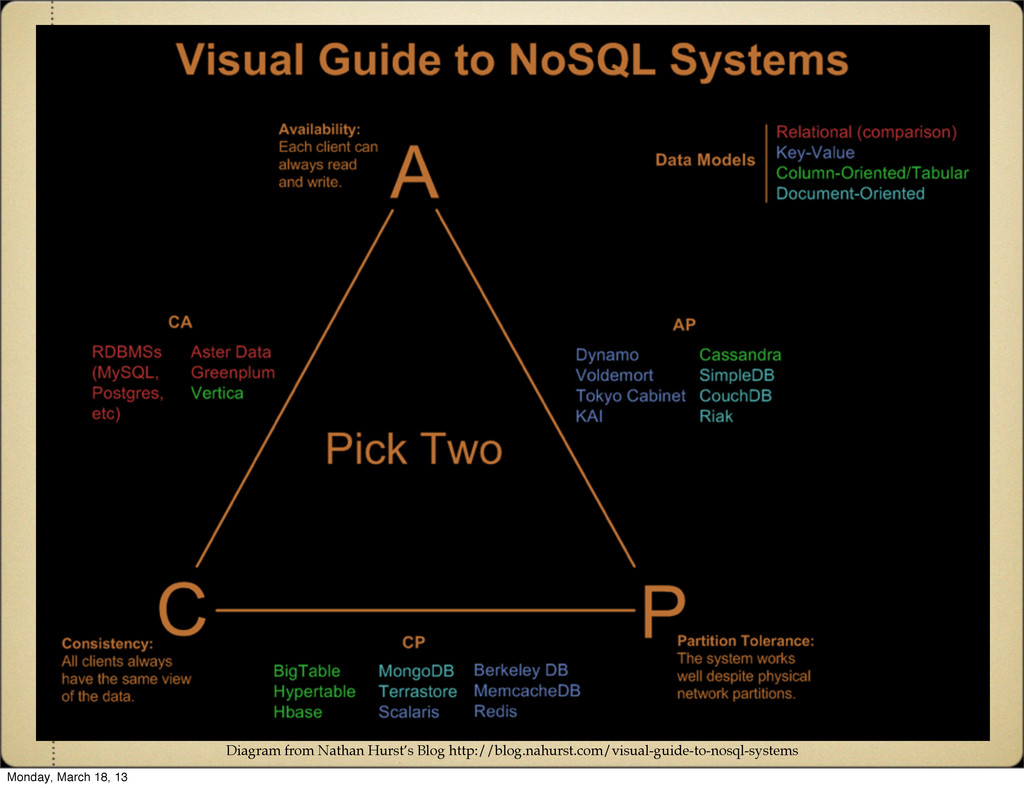
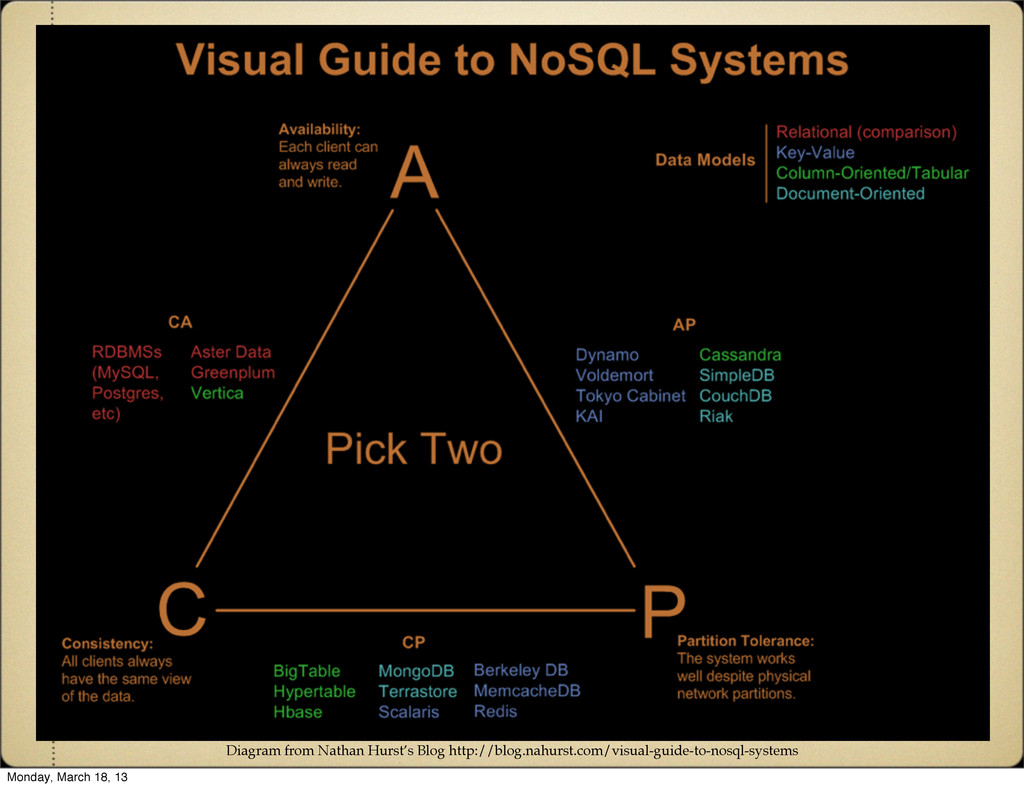
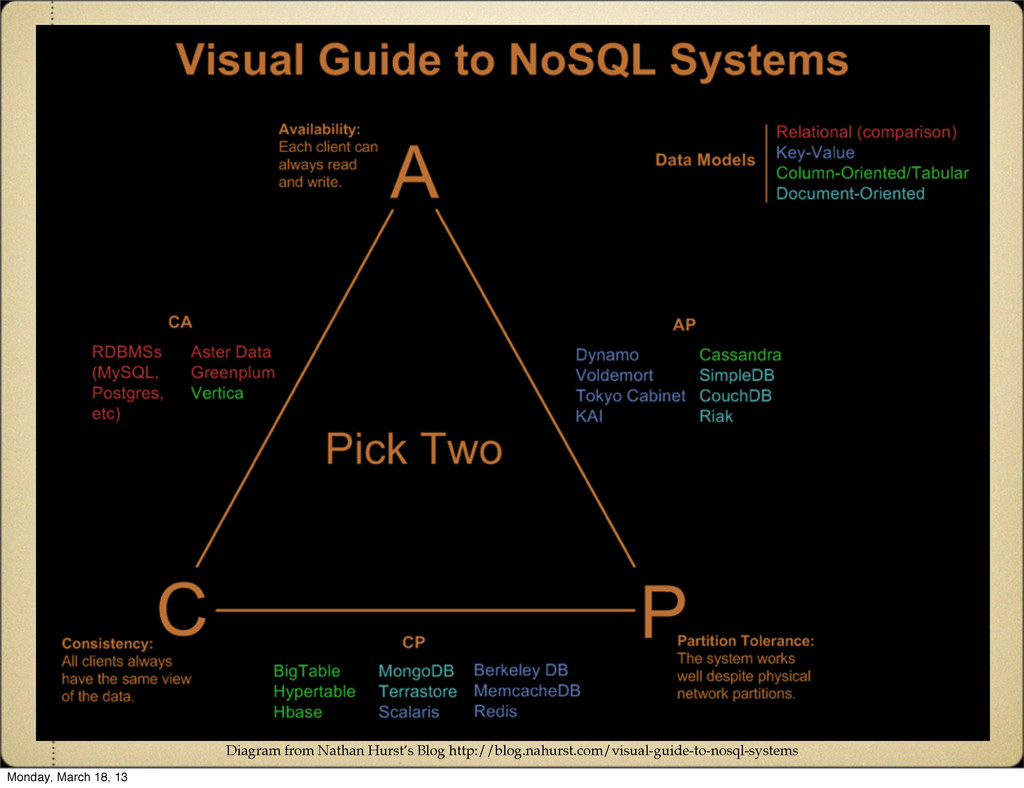
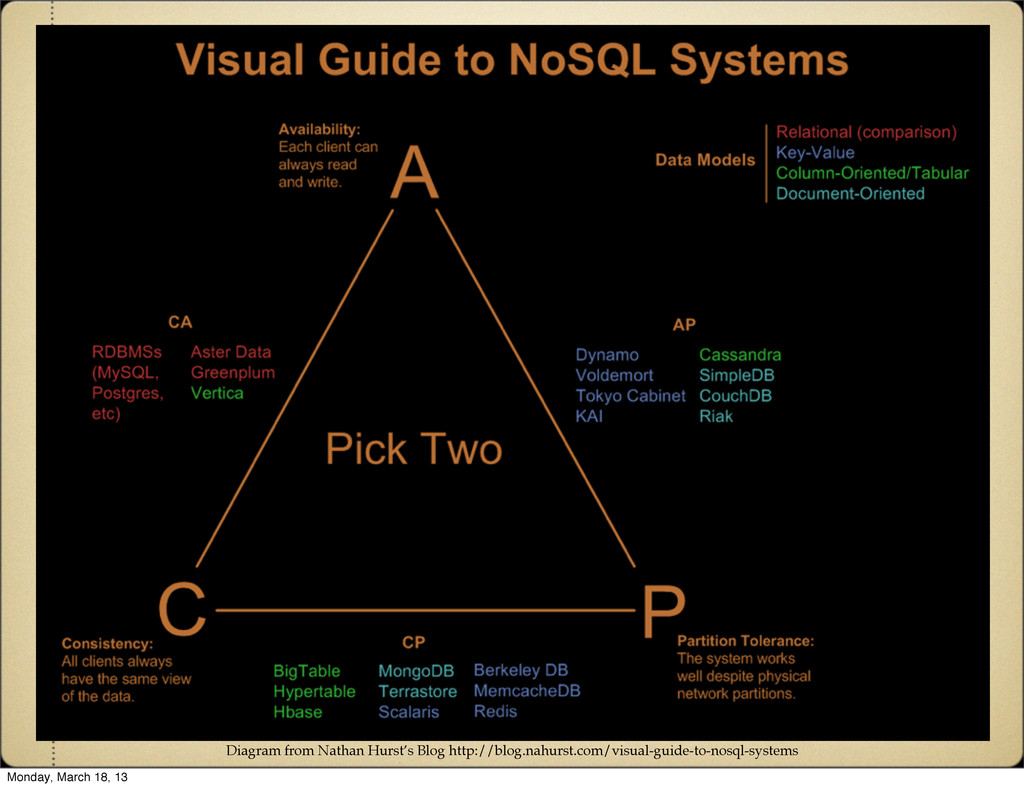
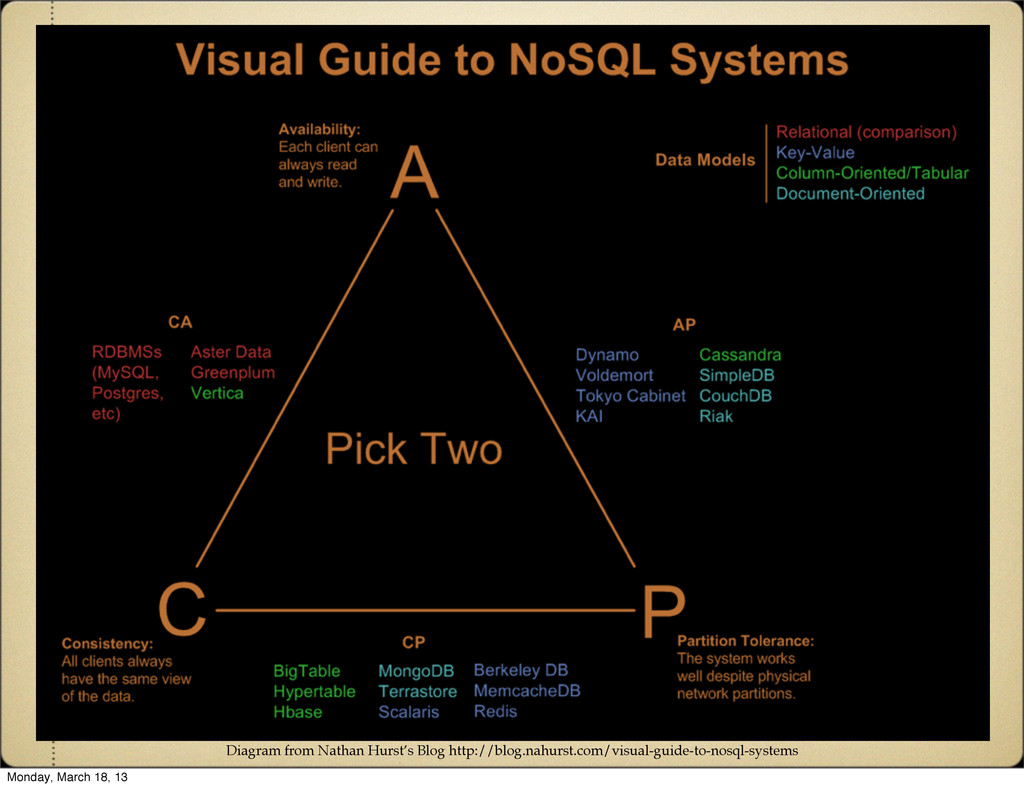
same results. Availability Every request receives a success/failure response. Partition Tolerance System continues to perform even with part of the system failing or failure of the network between system elements. Monday, March 18, 13
but if a partition exists it won't re-sync the state. CP Always consistent between all nodes, but goes down when any part of it goes down. AP Nodes can be partitioned but the system will remain available, and data will re-sync when the partition is removed. Monday, March 18, 13
in a network of unreliable processors. Consensus is the process of agreeing on one result among a group of participants. This problem becomes difficult when the participants or their communication medium may experience failures. Tends to be a high latency process Few complete implementations The primary goal is to deal with edge cases Monday, March 18, 13
aims to ensure that replicas of some mutable shared object converge without foreground synchronisation. Previous approaches to eventual consistency are ad-hoc and error-prone. We study a principled approach: to base the design of shared data types on some simple formal conditions that are sufficient to guarantee eventual consistency. We call these types Convergent or Commutative Replicated Data Types (CRDTs). This paper formalises asynchronous object replication, either state based or operation based, and provides a sufficient condition appropriate for each case. It describes several useful CRDTs, including container data types supporting both add and remove operations with clean semantics, and more complex types such as graphs, montonic DAGs, and sequences. It discusses some properties needed to implement non-trivial CRDTs. Monday, March 18, 13
to scaling your solution. This tends to be the quickest path to scalability if you’re trying to make use of the work of others for implementations of Paxos or CRDTs. Most datastores have known CAP behavior. Monday, March 18, 13
(can be numbers, can increment/decrement) Hashes (hash values can be numbers, can increment/decrement) Lists (basically an array) Sets (great for de-duplication) Sorted Sets (each element has a score for sorting) Pub/Sub (can be used for coordination if you don’t mind SPOF) Transactions (define your own blocking set of commands) Server-Side Scripting (use Lua to control atomicity) Monday, March 18, 13
to be careful about master, slave and RDB vs AOF Sentinel could provide some degree of oversight Cluster would be great... but I'm not getting my hopes up Monday, March 18, 13
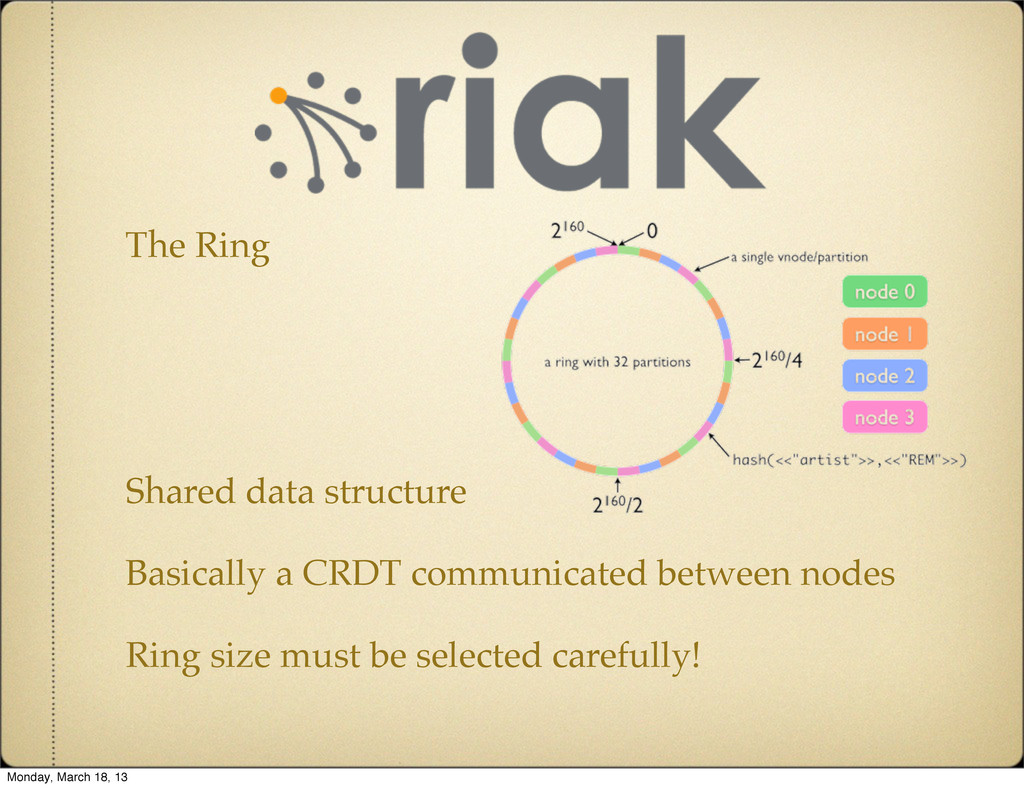
understand conceptually. Keys are partitioned into buckets. Values are stored as binary with a content-type. Secondary indexes are good, but may not ROFLScale. Never List Keys Monday, March 18, 13
datastore, however I MUST be prepared to change my implementation such that eventual consistency won't invalidate the primary theory of the algorithm. (RFC 30981) Monday, March 18, 13
this data we may at some point need, and divide that by the amount we just lost. Luckily I’ve been keeping the server logs so we just need to write some regex to repopulate our data store. Monday, March 18, 13
versions. Data is stored as byte arrays, so can be any type. Sometimes can be challenging in creating serialization/deserialization approaches. Monday, March 18, 13
lowest value. Regions are determined from the rowkey. Using a simple timestamp as a rowkey hotspots the region server, and makes it difficult to access the most recent data. Typical solution is to prefix the timestamp, and use a timestamp that counts down instead of up. Monday, March 18, 13
you have to be pretty frugal. Columns are sparse, so you can have tons of columns in one row, and only a few in the next row. myrow1: cf1:alpha=foo cf1:bravo=bar cf1:charlie=baz myrow2: cf1:alpha=foo cf1:charlie=baz Monday, March 18, 13
Can have multiple hot masters which zookeeper will switch between Allows mostly ACID stuff at the row level Fast writes and good read times Monday, March 18, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Push IO is hiring DevOps and Devs! [email protected] Q&A Monday,](https://files.speakerdeck.com/presentations/0c15011072820130d91822000a91a771/slide_67.jpg){kind=link}
{kind=link}