http://strataconf.com/stratany2014/public/schedule/detail/36275
SQL functionality and performance for Hadoop has been a hot topic over the past few years. In October of 2012 at Strata + Hadoop World Cloudera released Impala, in February of 2013 Hortonworks announced the Stinger Initiative for Hive, and in November of 2013 Facebook released Presto. There’s been no shortage of claims, but what is the reality of these claims? This session will take an independent look at these open source SQL engines for Hadoop and compare and contrast them on both functionality and performance, all from a non-vendor, unsponsored, independent point of view.
Note: there are some additional annotations and a few fixes in this version compared to the one presented at Strata.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
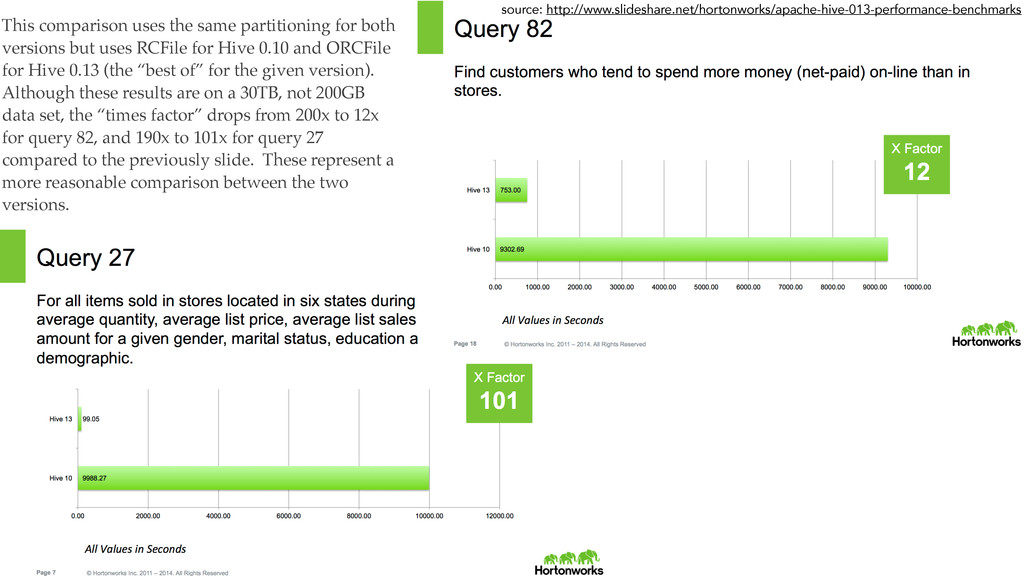{kind=link}
{kind=link}
{kind=link}
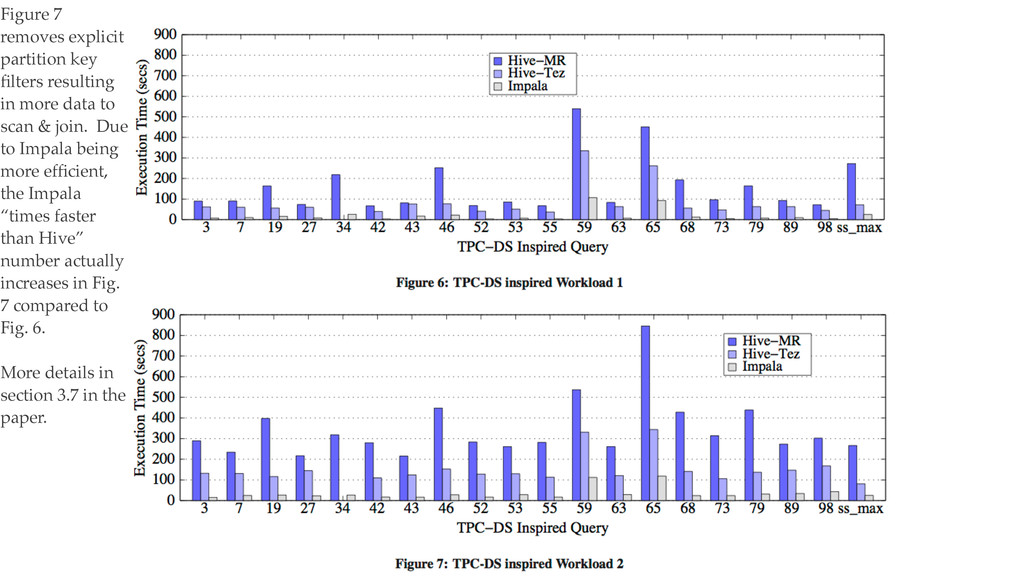{kind=link}
{kind=link}
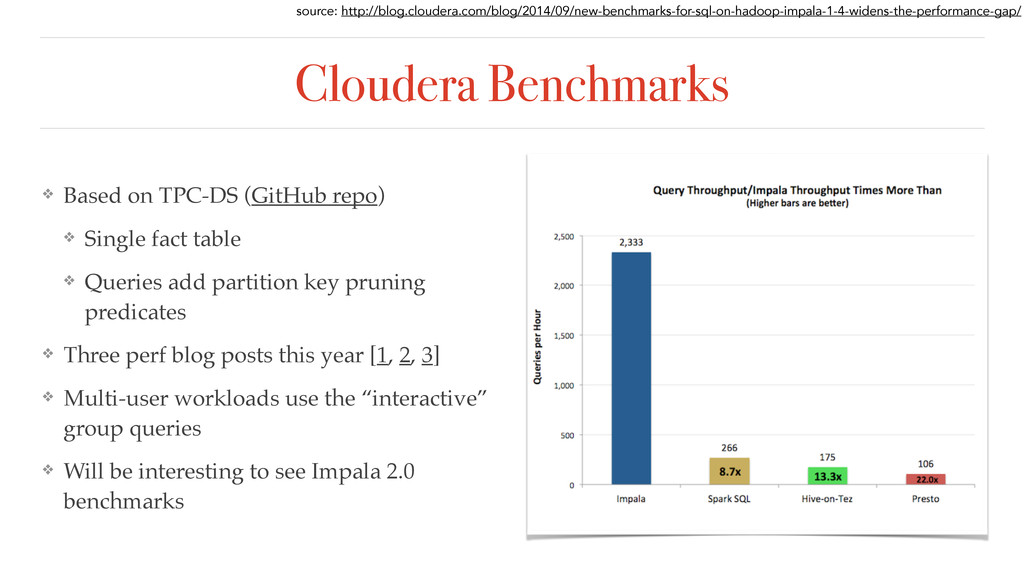{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Closing Thoughts On Benchmarks ❖ Most benchmark[eting] reports are lossy](https://files.speakerdeck.com/presentations/1eb232f0392b0132e0fe3e50d861d083/slide_37.jpg){kind=link}
{kind=link}
{kind=link}