backward in the programming paradigm for large-scale data intensive applications ❖ A sub-optimal implementation, in that it uses brute force instead of indexing ❖ Not novel at all -- it represents a specific implementation of well known techniques developed nearly 25 years ago ❖ Missing most of the features that are routinely included in current DBMS ❖ Incompatible with all of the tools DBMS users have come to depend on
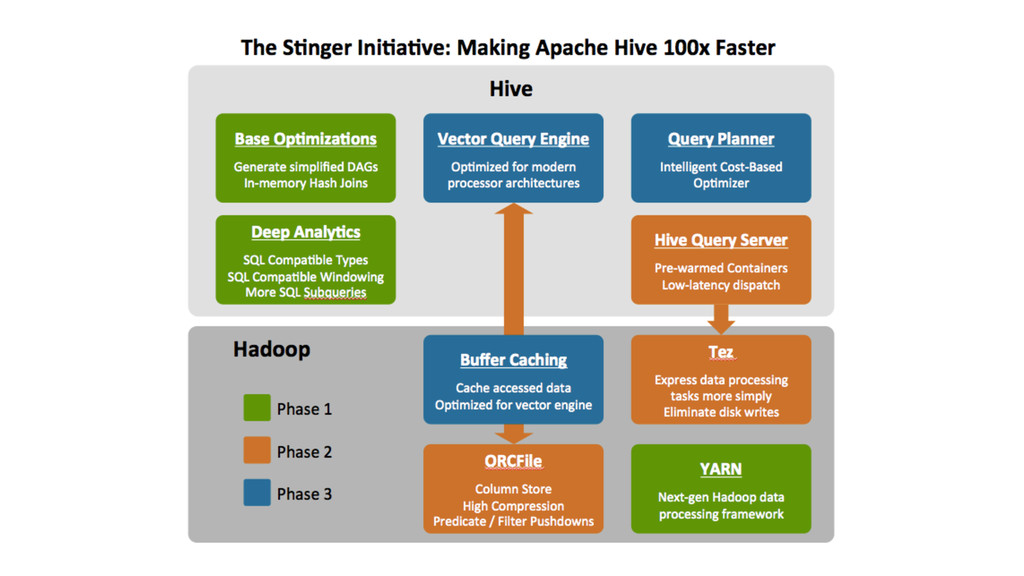
file format & Vectorization ❖ In-memory hash joins (broadcast join) ❖ Window functions ❖ Decimal, Varchar, Date ❖ Limited subquery support ❖ No anti-join support
not build on top of MapReduce ❖ MPP engine for data in HDFS ❖ Execution engine written in C++ (LLVM) ❖ Uses Parquet file format ❖ Currently the fastest OSS SQL for Hadoop
development ❖ Most immature of SQL projects ❖ Currently in a 0.5 (pre-production-ready) beta release ❖ Uses Optiq for CBO ❖ Geared more toward nested / semi- structured data — no metadata definition needed
on Spark ❖ Spark == Alternative to MapReduce ❖ July 2014 announcements ❖ EOL for Shark ❖ Spark SQL ❖ New Hive on Spark (HIVE-7292) ❖ Spark SQL driven by Databricks
rewrite of Big SQL ❖ No longer uses MapReduce ❖ Utilizes native and Java open source–based readers/writers ❖ Rich SQL support ❖ Modern query planner, but new
Summit ❖ X100 engine ported to run distributed on Hadoop ❖ Rich SQL support ❖ Integration with YARN ❖ Scale up/down elasticity ❖ Fastest SQL engine ❖ Custom file format
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Actian Vector[wise] (Project Vortex) ❖ Announced June 2014 at Hadoop](https://files.speakerdeck.com/presentations/fd0454f0598401326f2a4e55f5ecb48c/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}