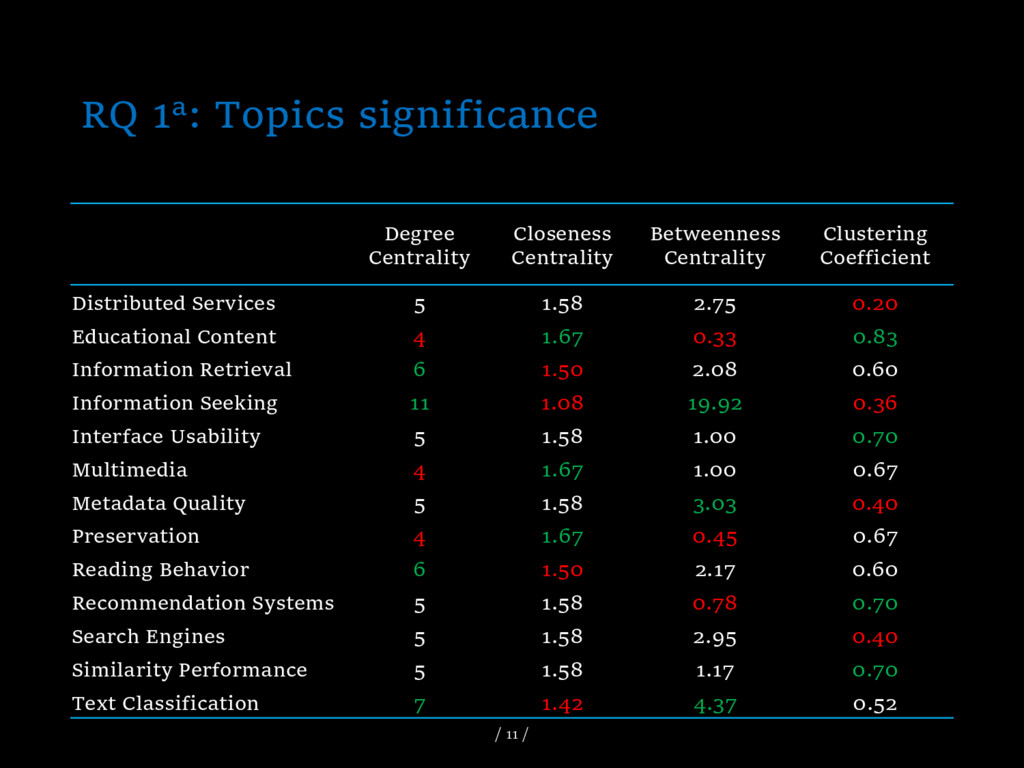
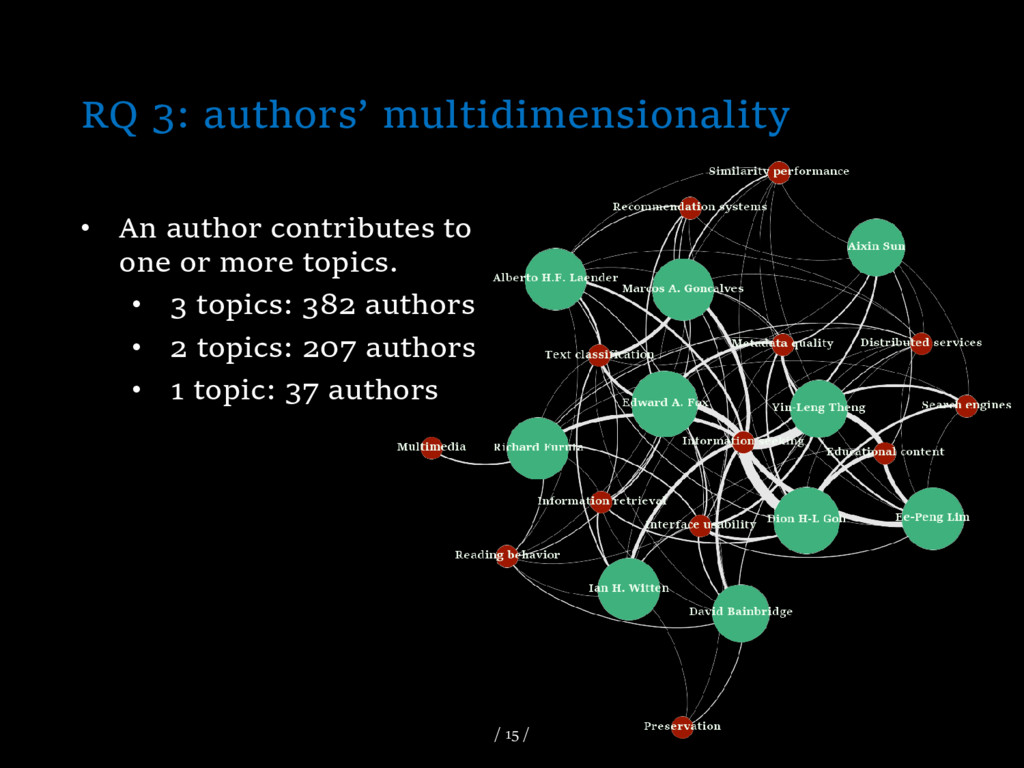
Digital libraries evaluation is characterised as an interdisciplinary and multidisciplinary domain posing a set of challenges to the research communities that intend to utilise and assess criteria, methods and tools. The amount of scientific production, which is published on the field, hinders and disorientates the researchers who are interested in the domain. The researchers need guidance in order to exploit the considerable amount of data and the diversity of methods effectively as well as to identify new research goals and develop their plans for future works. This paper proposes a methodological pathway to investigate the core topics of the digital library evaluation domain, author communities, their relationships, as well as the researchers who significantly contribute to major topics. The proposed methodology exploits topic modelling algorithms and network analysis on a corpus consisting of the digital library evaluation papers presented in JCDL,ECDL/TDPL and ICADL conferences in the period 2001–2013.
Full text at: dx.doi.org/10.1007/978-3-319-43997-6_19
Session: Digital Library Evaluation
Time: Thursday, 08/Sep/2016, 9:00am - 10:30am
Chair: Claus-Peter Klas
Location: Blauer Saal, Hannover Congress Centrum
[CC BY-NC-SA]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}