Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
B3 勉強会 第十二回
Search
gumigumi7
March 30, 2016
0
120
B3 勉強会 第十二回
gumigumi7
March 30, 2016
Tweet
Share
More Decks by gumigumi7
See All by gumigumi7
文献紹介 1月24日
gumigumi7
0
250
文献紹介 11月7日
gumigumi7
0
140
文献紹介 10月3日
gumigumi7
0
330
文献紹介 9月3日
gumigumi7
0
270
文献紹介 8月10日
gumigumi7
0
130
文献紹介 7月16日
gumigumi7
0
260
文献紹介 6月12日
gumigumi7
0
330
文献紹介 5月16日
gumigumi7
0
190
文献紹介 4月18日
gumigumi7
0
150
Featured
See All Featured
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
740
Balancing Empowerment & Direction
lara
5
900
Rebuilding a faster, lazier Slack
samanthasiow
85
9.4k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
430
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
1
58
A designer walks into a library…
pauljervisheath
210
24k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
280
Building Adaptive Systems
keathley
44
2.9k
30 Presentation Tips
portentint
PRO
1
220
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
5.8k
Git: the NoSQL Database
bkeepers
PRO
432
66k
Transcript
B3 勉強会 第十二回 (2016/03/30) 長岡技術科学大学 B3 桾澤 優希 機械学習
機械学習 ▪ 人間の認識能力をモデル化し、学習データを用いて人間 の学習能力を再現する ▪ 学習データからルールを自動獲得 ▪ ルールベースなどでは対応できないようなものに対して非常 に有効である。
機械学習(例) ▪ AlphaGo ▪ ディープニューラルネットワーク(深層学習、多層構造のニューラルネット ワークの機械学習)によって実装されたコンピュータ囲碁プログラム ▪ Google DeepMindによって作成 ▪
囲碁は可能な局面の数が非常に多く、力任せな探索ではアマチュア ほどの強さまでしか達することができていない ▪ 韓国のプロ棋士に4勝1敗と勝ち越したことで話題に
機械学習(例) ▪ Gmail ▪ メールのスパム判定に機械学習を用いてメールがスパムかそうでないか を自動判定 ▪ Smart Reply (Inbox)
▪ ユーザーに変わって自動的に返事をするテクノロジー ▪ 「何かを送って欲しい」という文章に対して「送ります」といった形の文を自 動で生成
機械学習の利点 ▪ 大量 ▪ 人手に比べて大量のデータを処理することが可能 ▪ 情報源が多様すぎる場合でも対応可能 ▪ 高速 ▪
人間の処理速度より早い
ルールベースとの比較 ▪ ルールを人手で考えてそれにそって処理を機会にやらせる 方法 ▪ ルールを頑張って作ればそれに沿う形で精度はどこまでも良くなる ▪ ルールが複雑化すればするほど難解かつ保守が難しくなる ▪ ルールだけでうん万行のスクリプトに
▪ ルールの追加によって他のルールへの影響がでる 「ゴルフ」→「スポーツ」 「インテル」→「コンピュータ」 「選挙」→「政治」 「ゴルフ」「VW」→「車」 「インテル」「長友」→「サッカー」 「選挙」「AKB」→「芸能」
機械学習の利点 ▪ ルールベースよりも・・・ ▪ データの変化に強い ▪ 保守が比較的簡単 ▪ 簡単な作業でそれなりの精度が出せる ▪
人手よりも・・・ ▪ 処理が早い ▪ 出力に一貫性がある
機械学習の種類 ▪ 問題設定に合わせて様々な種類が存在 ▪ 大きく分けて2種類 ▪ 教師あり学習 ▪ 入力に対して期待される出力を学習させ、 分析時には未知の入力に対応する出力を予測させる。
▪ スパム判定などの分類、株価などの予測等 ▪ 教師なし学習 ▪ 入力をたくさん与えて、入力情報自体の性質に関して 何かしらの結果を返す ▪ クラスタリングや異常検知 ▪ その他にも多数存在 ▪ 深層学習、強化学習、etc…
教師あり学習 ▪ 入力xから出力yへの関数f(x)=yを学習データを元に学 習する ▪ 出力yがカテゴリの場合は分類、連続値の場合は回帰と呼ぶ ▪ ; , :
損失関数 ▪ 予測結果 ; と正解が大きく違う場合に大きな値を返す ▪ () : 正規化項 ▪ C>0 はトレードオフパラメータ ∗ = min ; , + ()
線形分類器(二値) ▪ ; = () ▪ 入力 ∈ から出力を1,-1で予測する識別関数 ▪
重み付き多数決のイメージ 特徴 男性 女性 長髪 +3 短髪 +2 Tシャツ +1 ブラウス +2 ジーンズ +2 スカート +5 チノパン +3 長髪、Tシャツ、スカート なら・・・ 3 − 1 + 5 = 7 よって女性と推定することができる
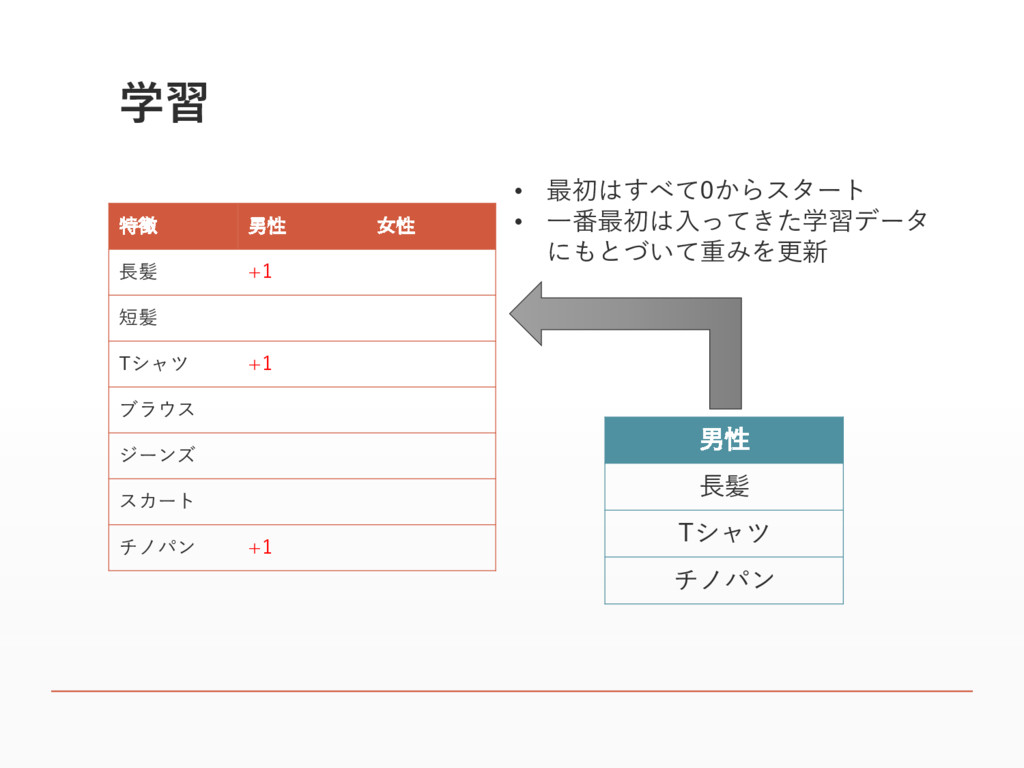
学習 特徴 男性 女性 長髪 +1 短髪 Tシャツ +1 ブラウス
ジーンズ スカート チノパン +1 • 最初はすべて0からスタート • 一番最初は入ってきた学習データ にもとづいて重みを更新 男性 長髪 Tシャツ チノパン
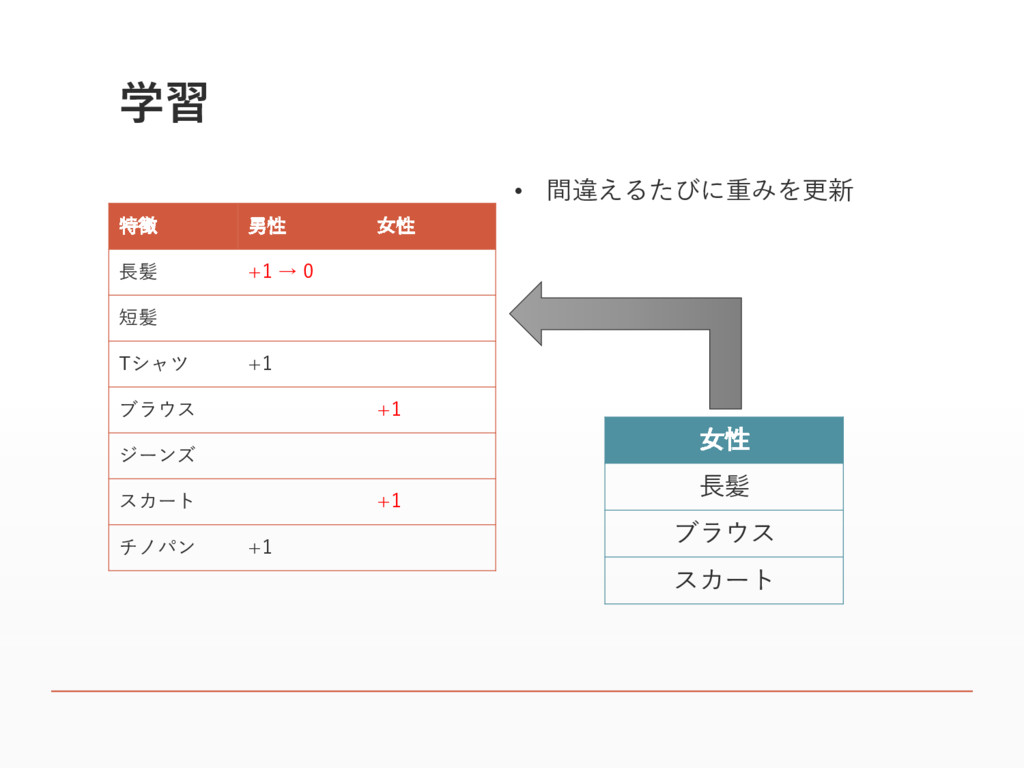
学習 特徴 男性 女性 長髪 +1 → 0 短髪 Tシャツ
+1 ブラウス +1 ジーンズ スカート +1 チノパン +1 • 間違えるたびに重みを更新 女性 長髪 ブラウス スカート
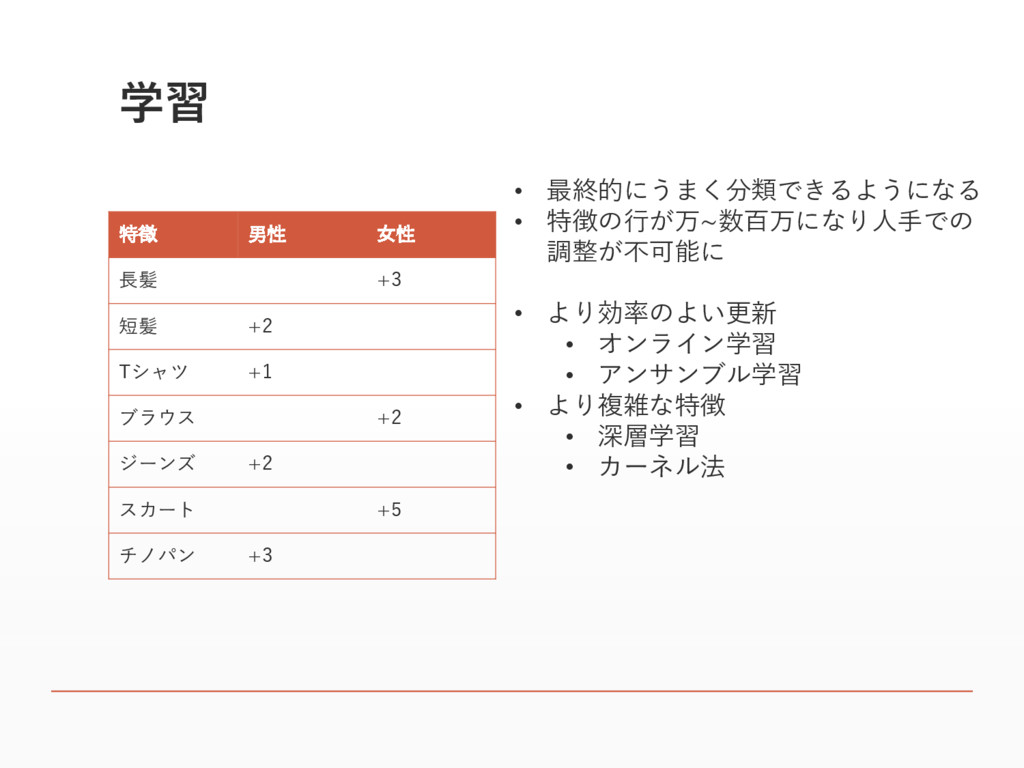
学習 • 最終的にうまく分類できるようになる • 特徴の行が万~数百万になり人手での 調整が不可能に • より効率のよい更新 • オンライン学習
• アンサンブル学習 • より複雑な特徴 • 深層学習 • カーネル法 特徴 男性 女性 長髪 +3 短髪 +2 Tシャツ +1 ブラウス +2 ジーンズ +2 スカート +5 チノパン +3
参考文献 ▪ 機械学習の理論と実践、大野原 大輔 http://www.slideshare.net/pfi/sacsis2013mlokanohara ▪ 機械学習チュートリアル、海野 裕也 http://www.slideshare.net/unnonouno/jubatus-casual- talks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}