Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介 5月16日
Search
gumigumi7
May 16, 2016
0
110
文献紹介 5月16日
gumigumi7
May 16, 2016
Tweet
Share
More Decks by gumigumi7
See All by gumigumi7
文献紹介 1月24日
gumigumi7
0
250
文献紹介 11月7日
gumigumi7
0
140
文献紹介 10月3日
gumigumi7
0
330
文献紹介 9月3日
gumigumi7
0
270
文献紹介 8月10日
gumigumi7
0
130
文献紹介 7月16日
gumigumi7
0
260
文献紹介 6月12日
gumigumi7
0
330
文献紹介 5月16日
gumigumi7
0
190
文献紹介 4月18日
gumigumi7
0
150
Featured
See All Featured
The Limits of Empathy - UXLibs8
cassininazir
1
220
Leo the Paperboy
mayatellez
4
1.4k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
120
Docker and Python
trallard
47
3.7k
Skip the Path - Find Your Career Trail
mkilby
0
60
How to Think Like a Performance Engineer
csswizardry
28
2.5k
WCS-LA-2024
lcolladotor
0
450
The Mindset for Success: Future Career Progression
greggifford
PRO
0
240
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Mobile First: as difficult as doing things right
swwweet
225
10k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
5.8k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.6k
Transcript
文献紹介(2016/05/16) 長岡技術科学大学 B4 桾澤 優希 カテゴリ間の兄弟を活用した集合拡張
文献 ▪ 論文 ▪ 高瀬 翔, 岡崎 直観, 乾 健太郎,
カテゴリ間の兄弟を活用した集合拡張.自然言語処理, Vol. 20 (2013) No. 2 p. 273-296 ▪ キーワード ▪ Wikipedia, 知識獲得, 集合拡張 2
概要 ▪ 意味カテゴリに属する固有表現の集合拡張 ▪ wikipediaのカテゴリの兄弟関係を事前知識として利用 する手法の提案 ▪ 既存手法に比べ適合率が向上 3
導入 ▪ 自然言語の理解には常識的知識の獲得が重要 ▪ 意味カテゴリに属する固有名詞リストは様々なタスクで利用される ▪ 例) 質問応答 , 情報抽出
, 文書分類 ▪ 人手での構築はコストがかかる → (半)自動的に獲得する方法が研究されてきた 4
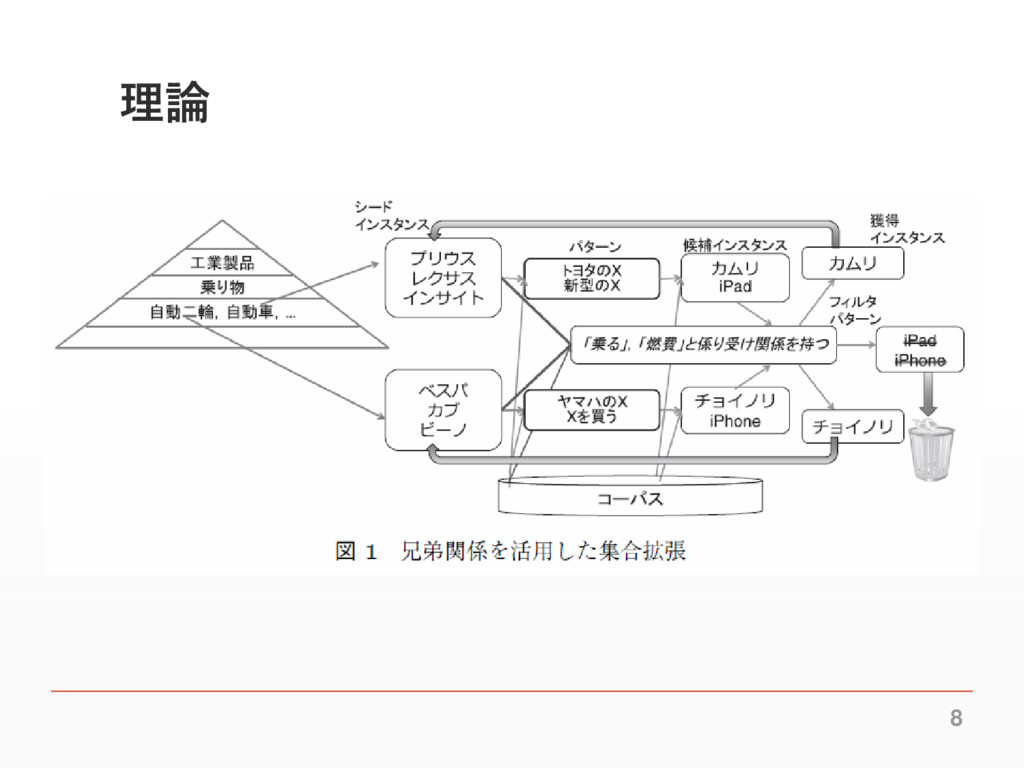
導入 ▪ 集合拡張 ▪ ある意味カテゴリに属する既知の固有表現の集合を入力、そのカテゴ リに属する未知の固有表現を獲得するタスク ▪ 「プリウス」「レクサス」「インサイト」のような自動車カテゴリの固有表現 から、「カローラ」「シビック」「フィット」のようなものを新たに獲得する ▪
既存手法ではシードインスタンス集合と無関係なインスタ ンスを獲得してしまう場合がある ▪ 「プリウス」「レクサス」から「iPad」「ThinkPad」のようなものを取得 ▪ Wikipediaの兄弟関係を用いてこれらの間違いを減らす 5
理論 ▪ Espressoアルゴリズム ▪ パターンの取得とインスタンスの取得の2つを反復する集合拡張アルゴ リズム ▪ 「新型のX」「Xの性能」といった多くのカテゴリのインスタンスと共起する パーンが得られてしまうため、「プリウス」から「iPad」のようなインスタンス が出され得る
6
理論 ▪ 同一の兄弟グループに含まれるインスタンスは共通の特徴 を保有していると仮定 ▪ 自動車、自動二輪の兄弟グループに含まれるインスタンスは「乗る」や 「燃費」などの語と係り受け関係を持ちやすい ▪ これらの特徴を取得しインスタンスが特徴を保有している か否かで誤ったインスタンスの獲得を防ぐ
7
理論 8
理論 9
理論 ▪ フィルタパターンの取得 ▪ 候補の抽出 ▪ 係り先や係り元の関係は考慮しない ▪ 名詞と動詞を対象にする。 ▪
例) 「乗る」、「エンジン」、「愛車」 ▪ ランキング ▪ 最適なフィルタパターンを選択する ▪ 網羅性と平等性の2つでランキング 10
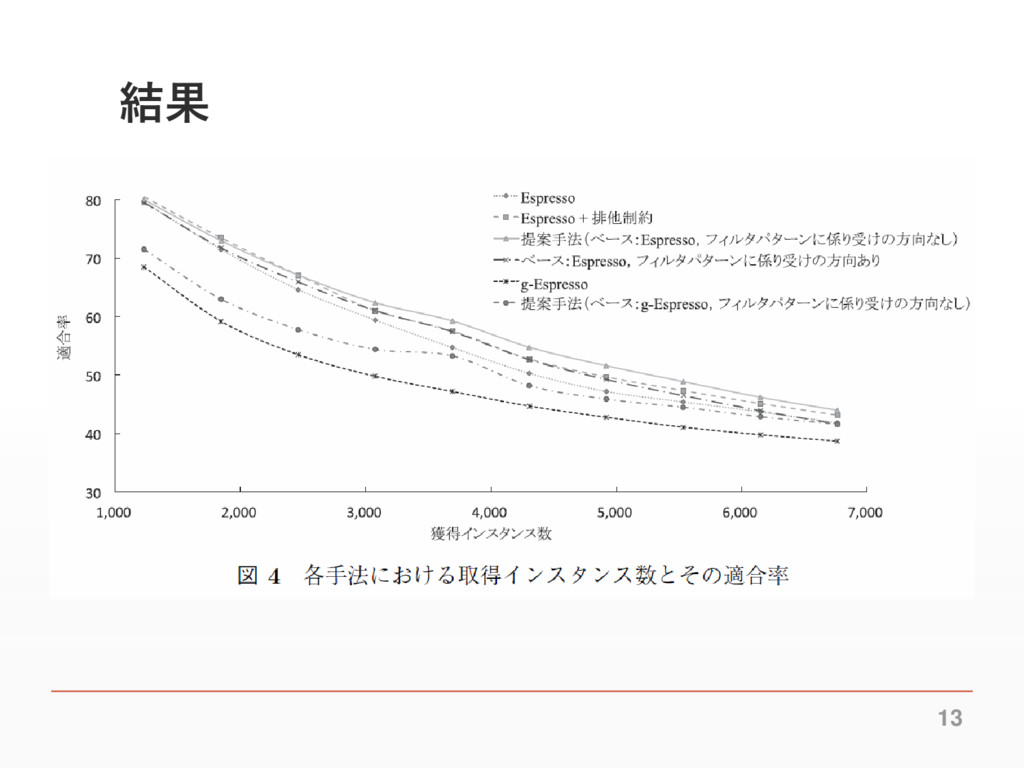
実験 ▪ カテゴリ間の兄弟関係を事前知識として使用することの効 果を検証する。 ▪ ベースラインはEspressoアルゴリズム、Espressoアルゴリ ズムに排他制約を加えたものなどを使用 ▪ 同じ数のインスタンスを取得した際の適合率を比較するこ とで評価
11
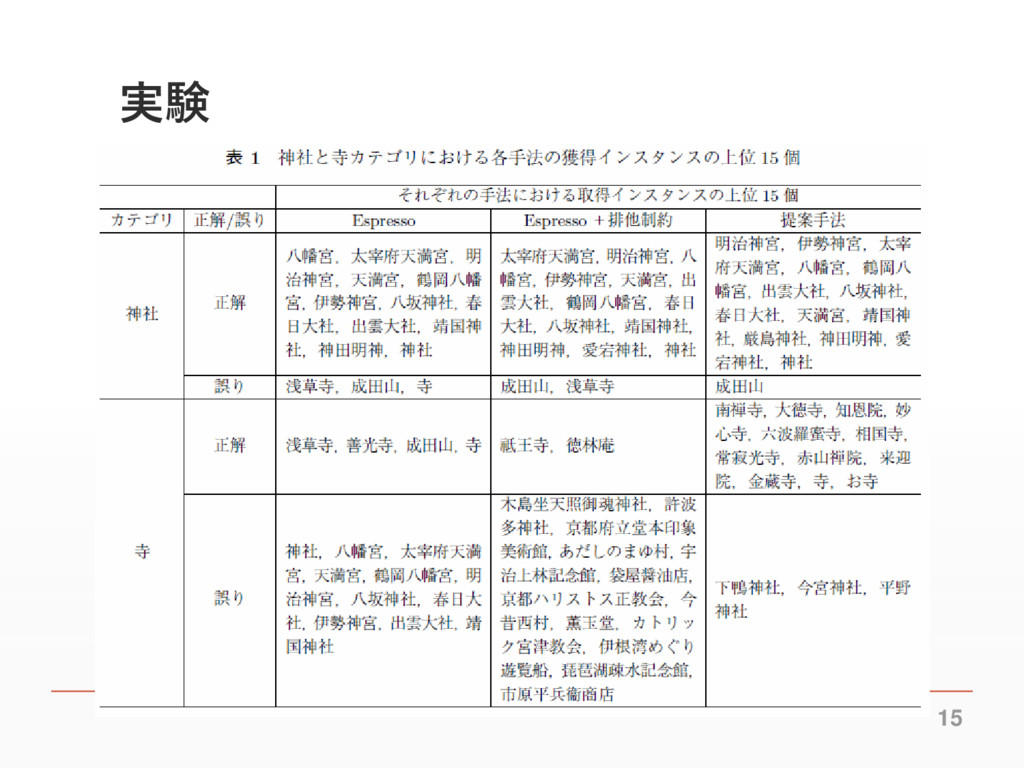
実験 ▪ シードインスタンスをWikipediaから取得 ▪ 41個のカテゴリに対して15個ずつインスタンスを用意 ▪ 実験には1億1千万の日本語ウェブページをコーパスとして 使用 ▪ KNPによって係り受け構造を解析
12
結果 13
結果 14
実験 15
まとめ ▪ 一既存手法に対してカテゴリ間の兄弟関係を事前知識と して利用する手法を提案した ▪ ベースラインであるEspressoアルゴリズムに比べ適合率を 最大で4.4%向上させた 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}