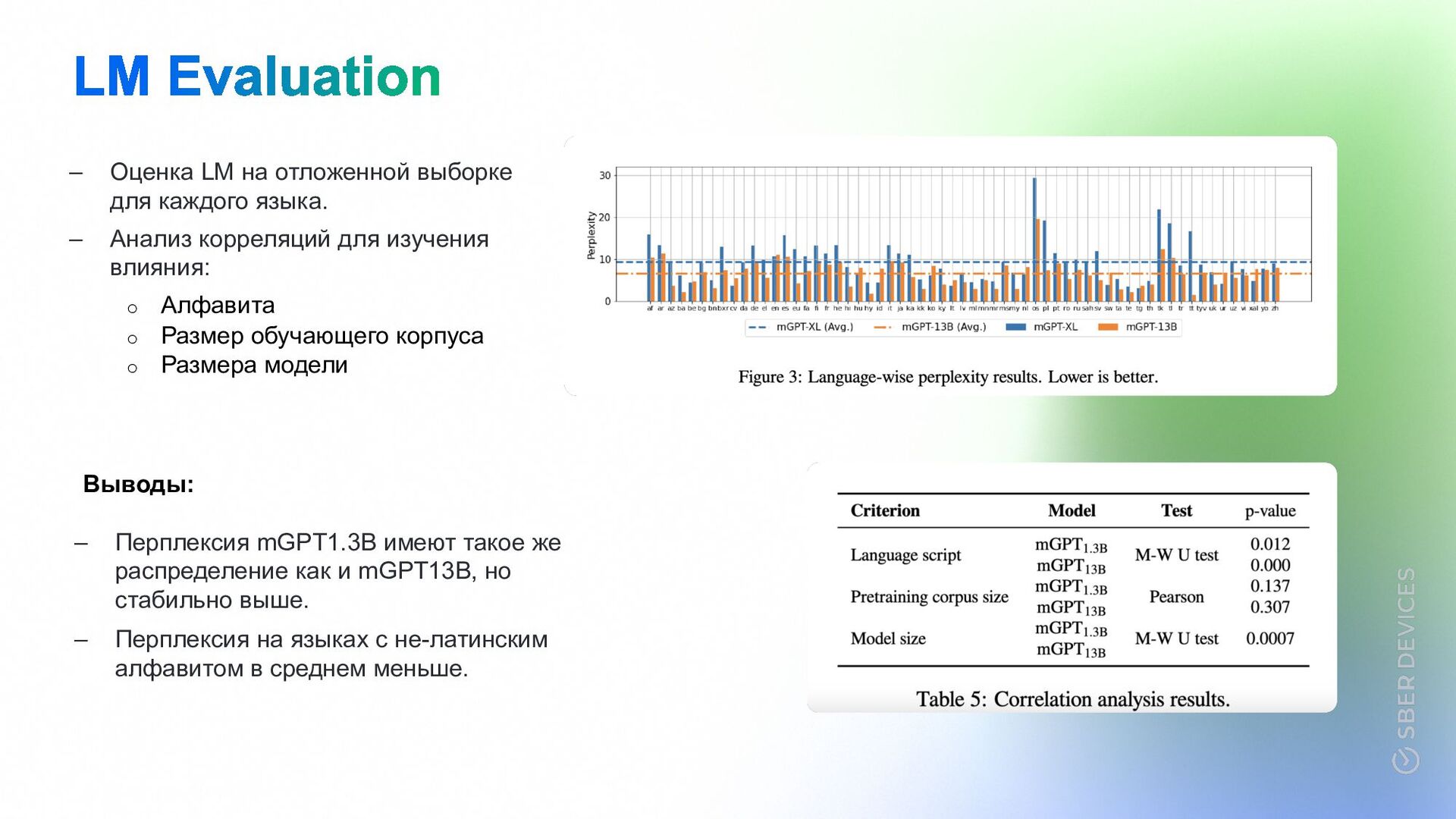
Анализ корреляций для изучения влияния: o Алфавита o Размер обучающего корпуса o Размера модели Выводы: – Перплексия mGPT1.3B имеют такое же распределение как и mGPT13B, но стабильно выше. – Перплексия на языках с не-латинским алфавитом в среднем меньше.
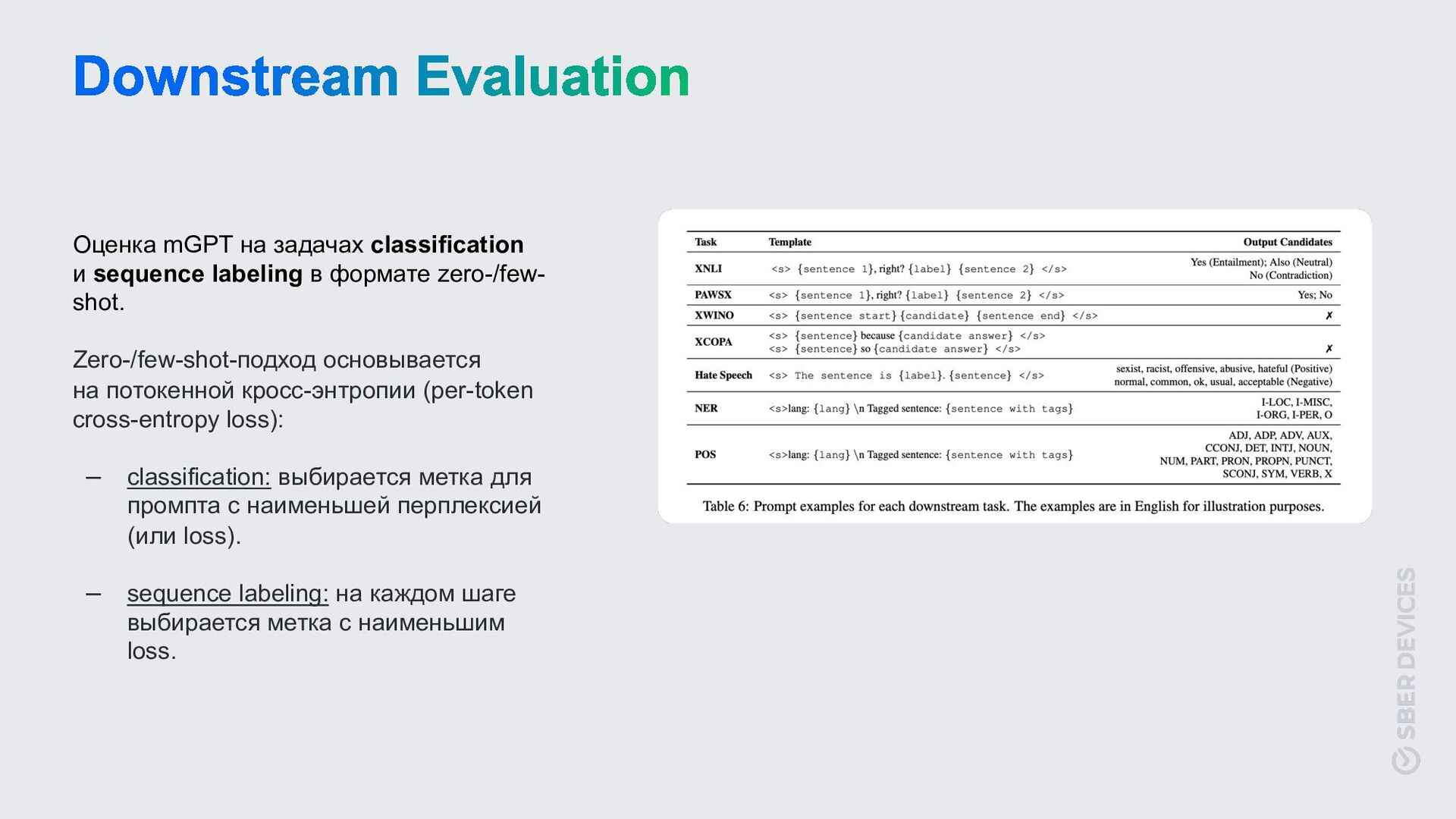
zero-/few- shot. Zero-/few-shot-подход основывается на потокенной кросс-энтропии (per-token cross-entropy loss): – classification: выбирается метка для промпта с наименьшей перплексией (или loss). – sequence labeling: на каждом шаге выбирается метка с наименьшим loss.
испанский и китайский. Метрики: – Entropy1 - энтропия Шеннона для униграмм; – MSTTR - среднее отношение сегментированных токенов к сегментам длиной 100; – Distinct1 - отношение числа отдельных униграмм к общему числу униграмм, а также количество униграмм, которые встречаются один раз в коллекции сгенерированных выходов; – Unique1 – количество униграмм, которые встречаются один раз в коллекции сгенерированных выходов. Выводы: • Показатели метрики разнообразия выше у китайского, а средняя длина сгенерированного текста – самая короткая. • Результаты индоевропейских языков схожи. Показатели для английского языка ниже, так как средняя длина текста больше.
формате zero-shot и few-shot, используя промпты.Оценка с помощью метрик ROUGE и BLEU. Выводы: Для большого числа языков моноязычные модели показывают лучшее качество, чем оригинальная mGPT, причем зачастую превосходство проявляется в zero- и 4- shot формате, а для ряда языков (например, узбекского, туркменского и азербайджанского) моноязычный чекпоинт с английскими затравками превосходит оригинал во всех форматах.
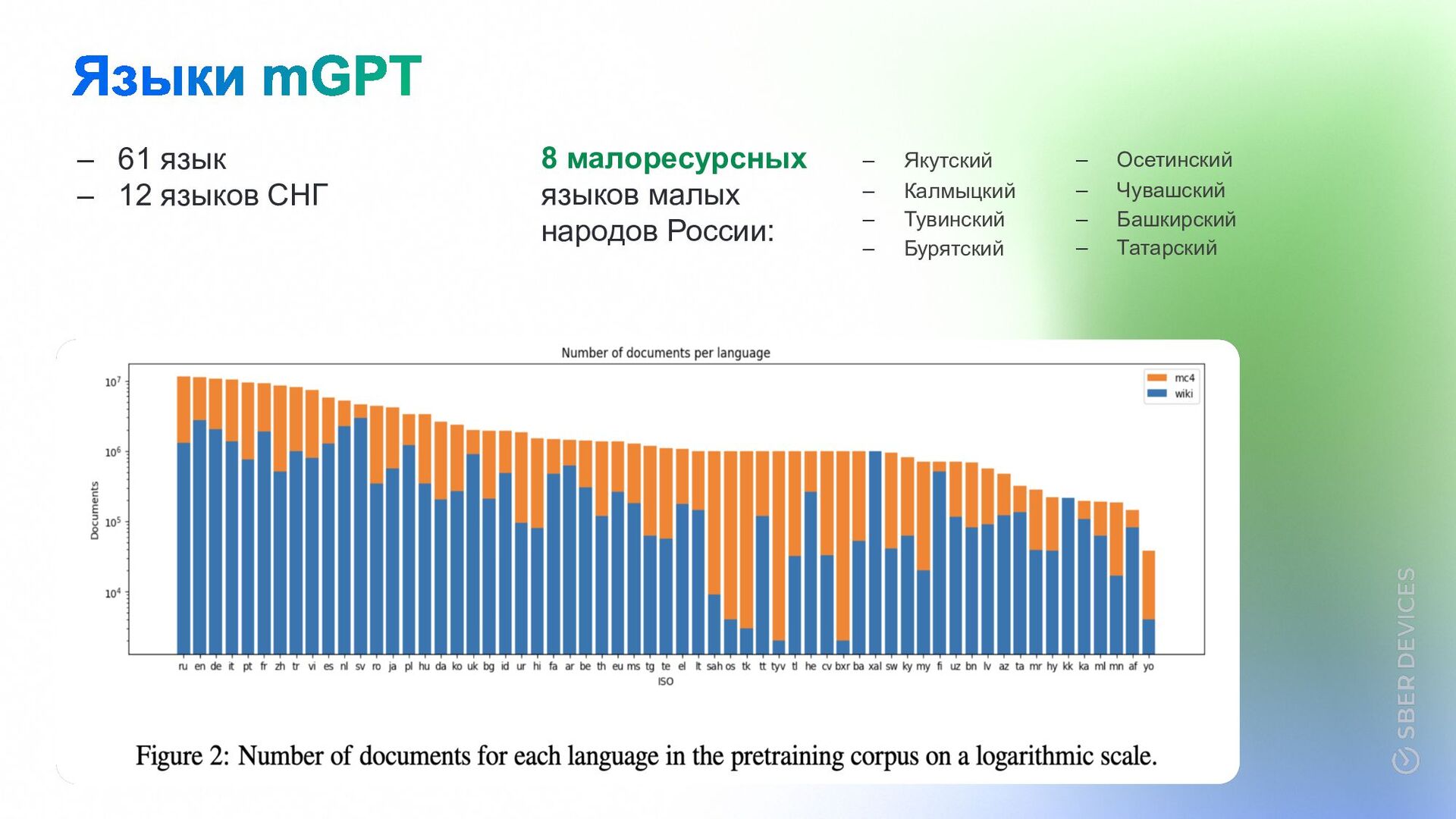
61 язык. – Одна из первых авторегрессивных LM для малоресурсных и СНГ языков. – Выпустили 23 версии mGPT1.3B дообученных на моноязычных корпусах языков стран СНГ и малоресурсных языков малых народов России. – Комплексная оценка mGPT. Телеграм для связи: @averkij
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}