GIGA R&D DAY Открытых параллельных датасета для задачи коррекции правописания. Ручная разметка, более 10 текстовых доменов. алгоритма аугментации на основе искажения правописания: Statistic-based spelling corruption и Augmentex. открытых чекпоинтов моделей от 95M до 1.7B, предобученных для задачи коррекции орфографии и пунктуации пунктов метрики F1 над решениями Open.AI и Yandex.Speller
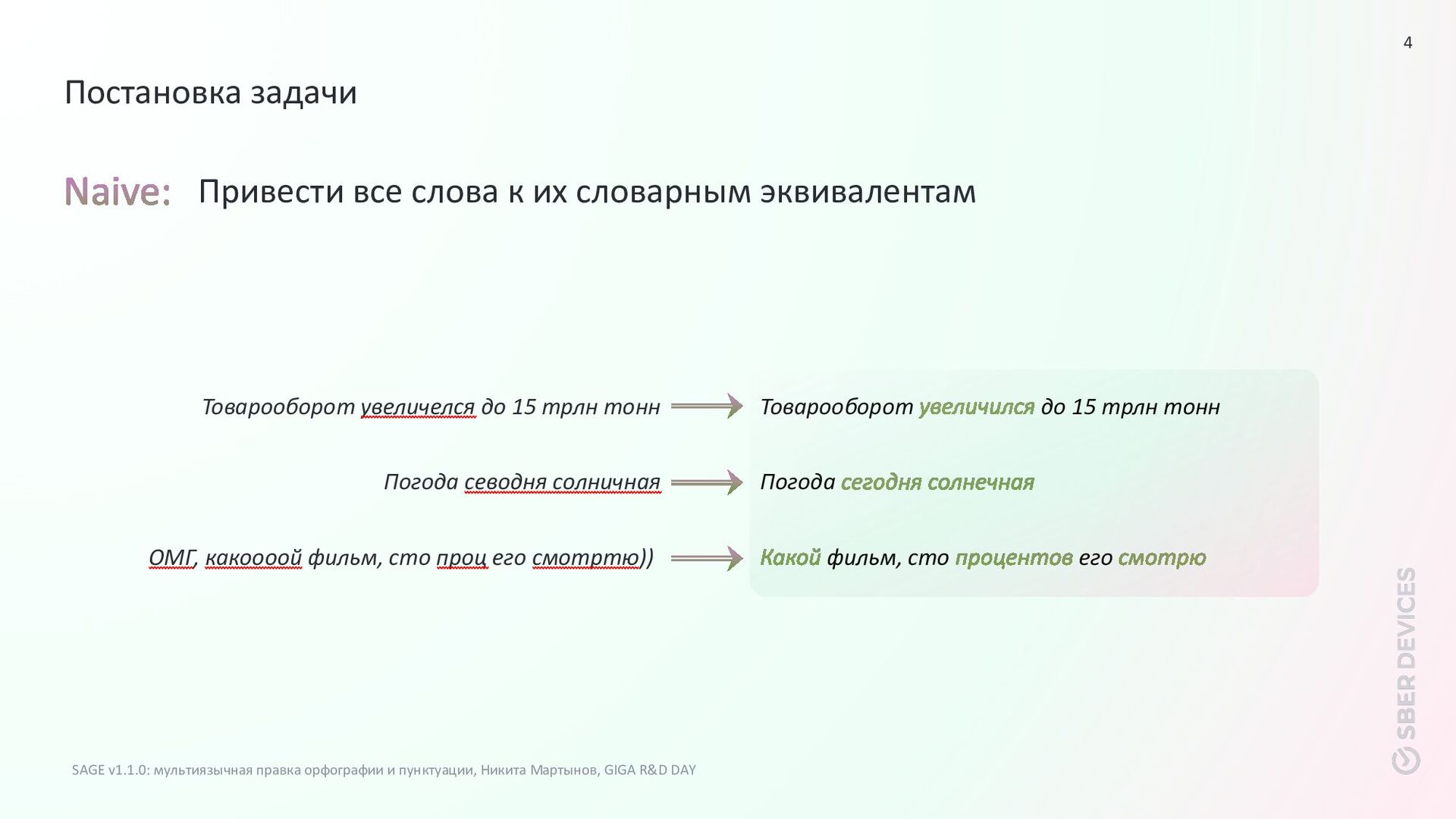
R&D DAY Постановка задачи фильм, сто его ОМГ, какоооой фильм, сто проц его смотртю)) Привести все слова к их словарным эквивалентам Товарооборот увеличелся до 15 трлн тонн Товарооборот до 15 трлн тонн Погода севодня солничная Погода 4
R&D DAY фильм, сто его ОМГ, какоооой фильм, сто проц его смотртю)) Постановка задачи 6 • Влияние контекста; • Сохранять эмоциональную палитру; • Различать намеренные ошибки от ненамеренных.
R&D DAY Датасеты Один датасет для русского спеллинга RUSpellRU Internet blogs Собрали полноценный бенчмарк Web, news, literature, medical anamnesis, github commits etc. 8
должна рассматриваться отдельно Не получится сделать автоматически Датасеты SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 10
должна рассматриваться отдельно Не получится сделать автоматически — Собрать тексты из разных источников для репрезентативности разных типов ошибок; — Убрать корректные предложения; — Получить корректные варианты оставшихся текстов; — Проверить корректность исправлений; Датасеты SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 11
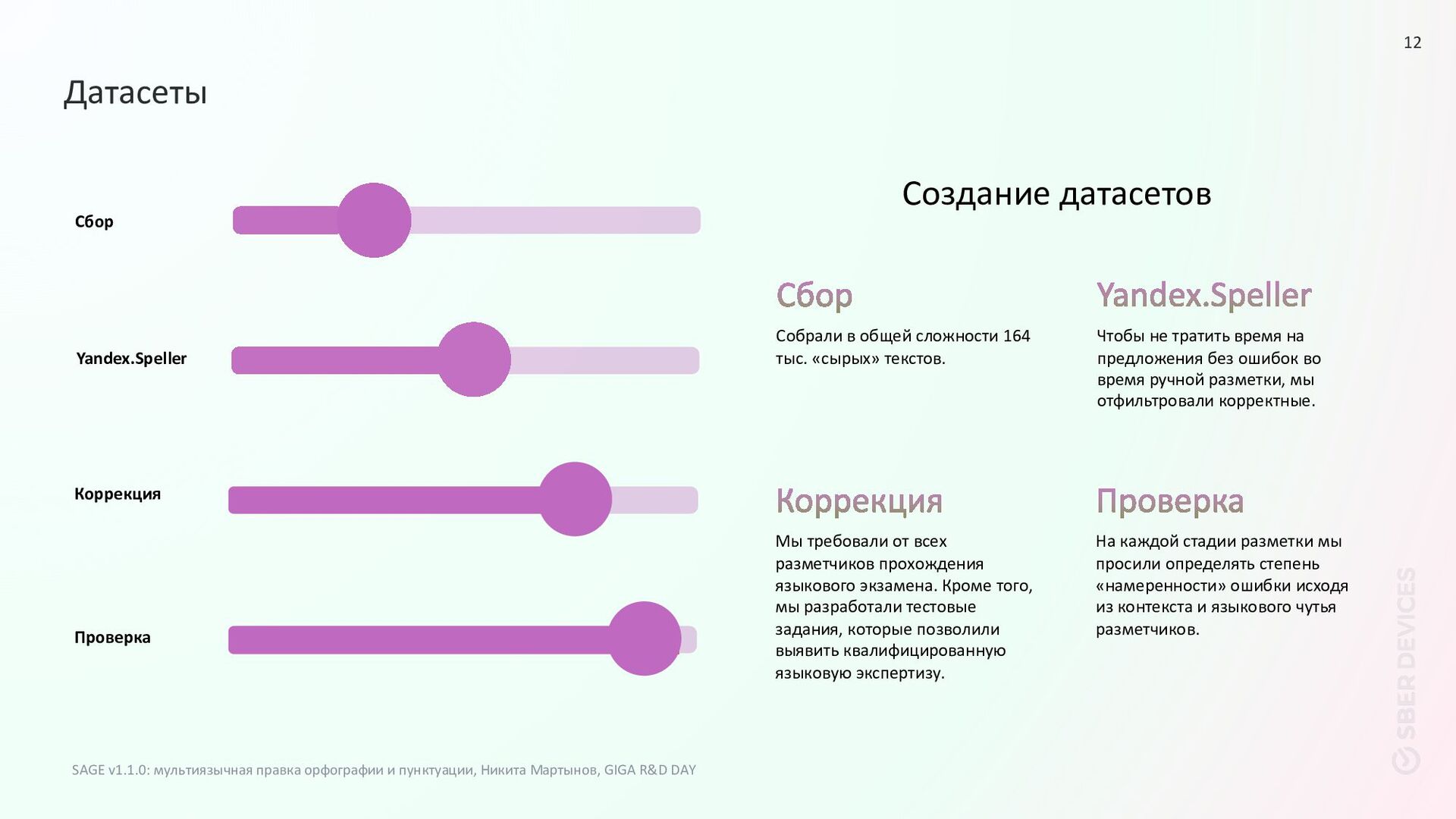
текстов. Чтобы не тратить время на предложения без ошибок во время ручной разметки, мы отфильтровали корректные. Мы требовали от всех разметчиков прохождения языкового экзамена. Кроме того, мы разработали тестовые задания, которые позволили выявить квалифицированную языковую экспертизу. На каждой стадии разметки мы просили определять степень «намеренности» ошибки исходя из контекста и языкового чутья разметчиков. Создание датасетов Проверка Датасеты SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 12
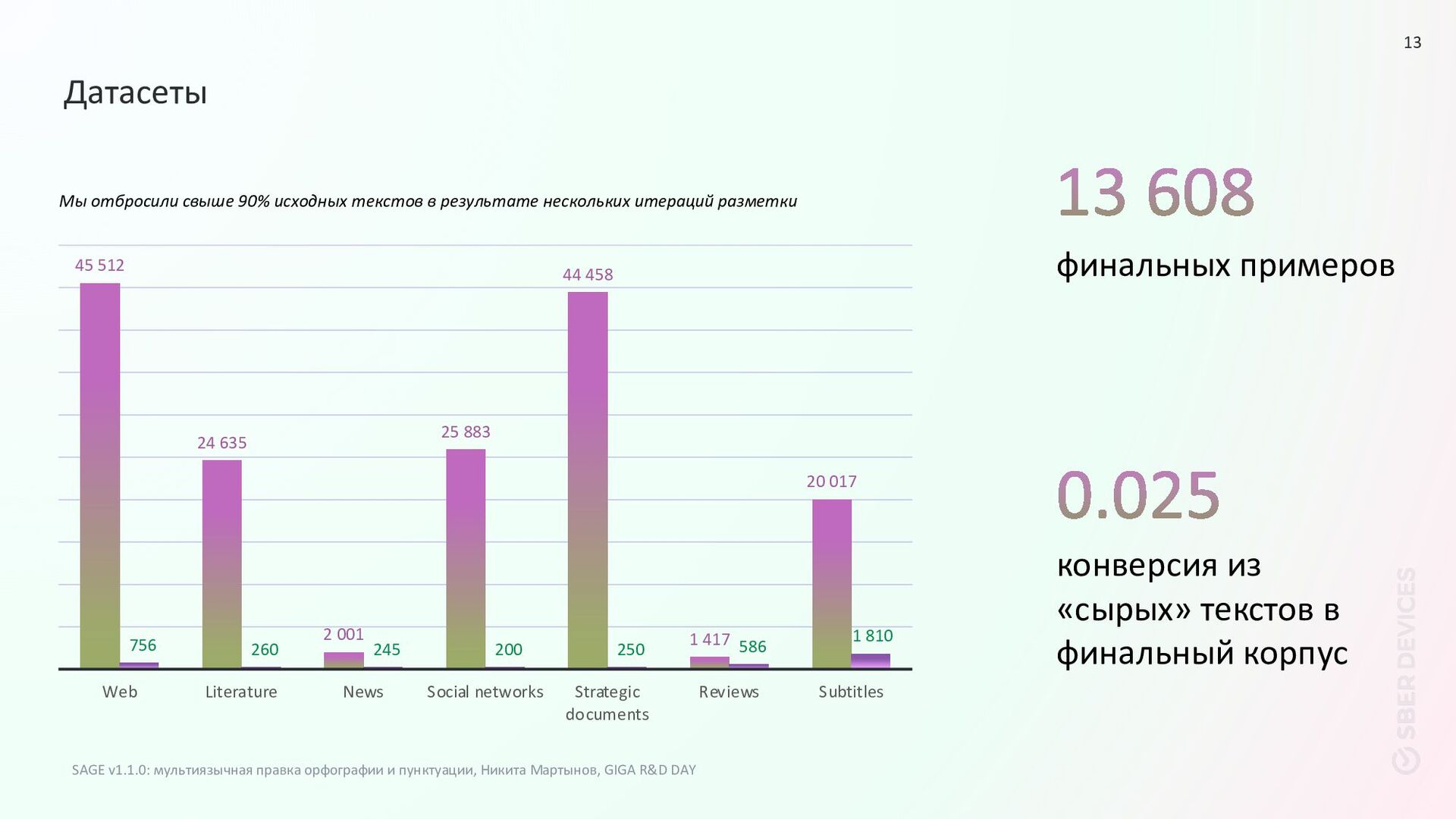
1 417 20 017 756 260 245 200 250 586 1 810 Web Literature News Social networks Strategic documents Reviews Subtitles Мы отбросили свыше 90% исходных текстов в результате нескольких итераций разметки финальных примеров конверсия из «сырых» текстов в финальный корпус Датасеты SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 13
символов; — Naïve справляется достаточно плохо – нужно что-то поумнее; SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 14
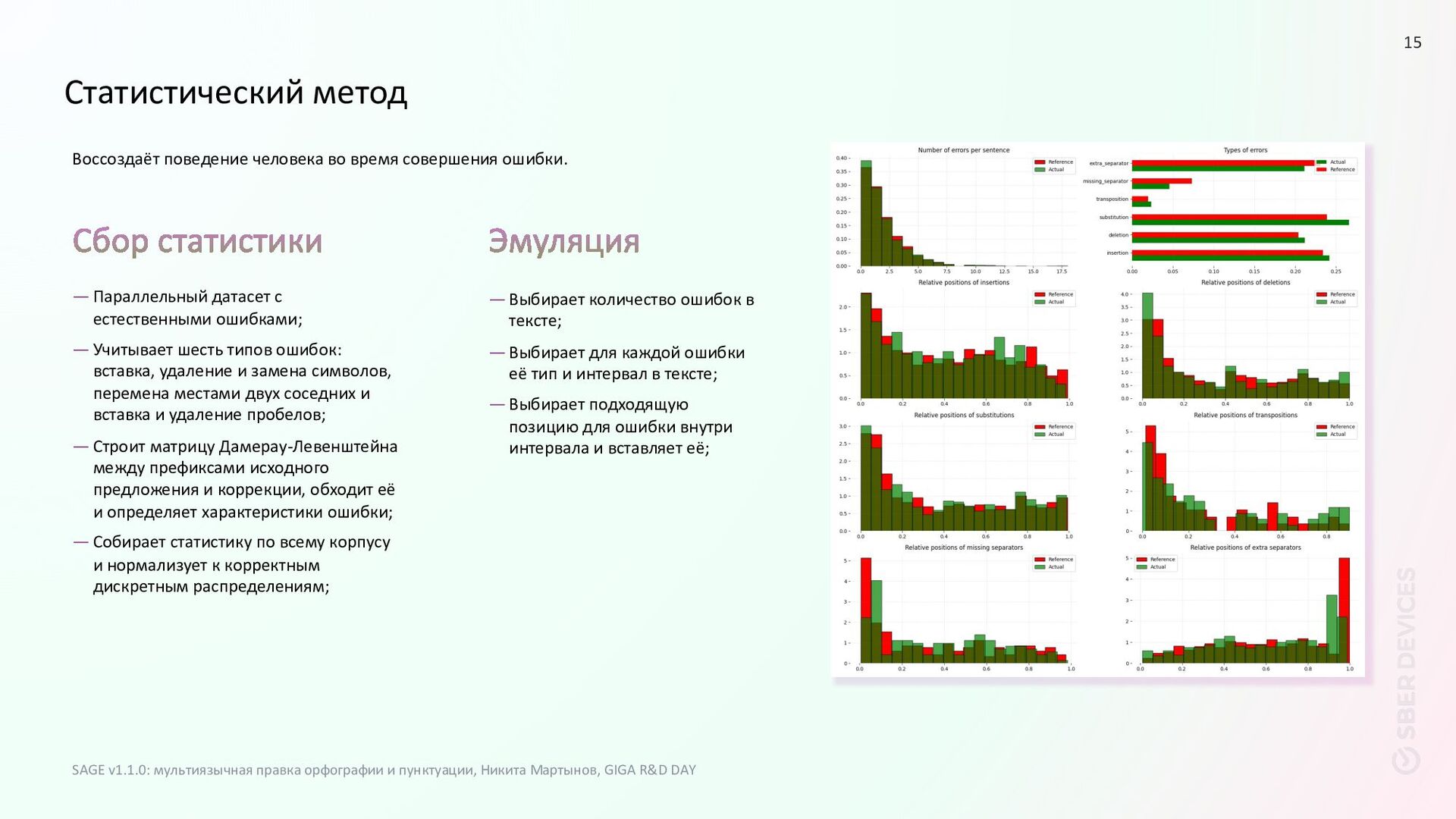
ошибок: вставка, удаление и замена символов, перемена местами двух соседних и вставка и удаление пробелов; —Строит матрицу Дамерау-Левенштейна между префиксами исходного предложения и коррекции, обходит её и определяет характеристики ошибки; —Собирает статистику по всему корпусу и нормализует к корректным дискретным распределениям; Воссоздаёт поведение человека во время совершения ошибки. —Выбирает количество ошибок в тексте; —Выбирает для каждой ошибки её тип и интервал в тексте; —Выбирает подходящую позицию для ошибки внутри интервала и вставляет её; SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 15
delete Привет, как дела? Привет, дела? как swap Привет, как дела? Привет, скажем как дела? stopword привет, как дела? reverse 👋 , как дела? text2emoji П р и в е т, как дела? split Превет, как дела? ngram Привет, как дела? Привет, как дела? Привет, как дела? Привет, как дела? Искажение правописания на основе статистик собранных из открытых источников и с помощью эвристик. —Replace: замена случайного слова на его ошибочный эквивалент; —Delete: удаление случайного слова; —Swap: перемена местами двух соседних слов; —Stopword: добавление слов-паразитов; —Reverse: замена регистра первых букв выбранного слова в тексте; —Text2emoji: заменяет слово в тексте на соответствующее эмоджи; —Ngram: заменяет последовательные N символов на их ошибочный эквивалент по статистике употребления; —Split: посимвольно разделяет случайное слово; Привет, как дела? SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 16
T5; — mT5; необходимо для полного цикла обучения любой из представленных архитектур на 8 Nvidia A100; миллионов параметров - размер самой маленькой архитектуры из семейства моделей для коррекции правописания; языка поддерживается на текущий момент: русский и английский. В будущем добавятся также другие европейские языки, языки СНГ и малые языки России; Специально спроектированная процедура предобучения позволила моделям для коррекции правописания добиться повышения метрики F1-score на 20 пунктов Процедура предобучения для коррекции орфографии — Собрать большой корпус чистых текстов: Википедия и транскрипты видео (новости для английского языка); — Вставить ошибки с помощью статистического метода, инициализированном статистикой с RUSpellRU; — seq2seq обучение: зашумлённое предложение на вход модели, просим сгенерировать корректное; — Дополнительная задача на энкодер по предсказанию типа и позиции ошибки в исходном предложении; SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 17
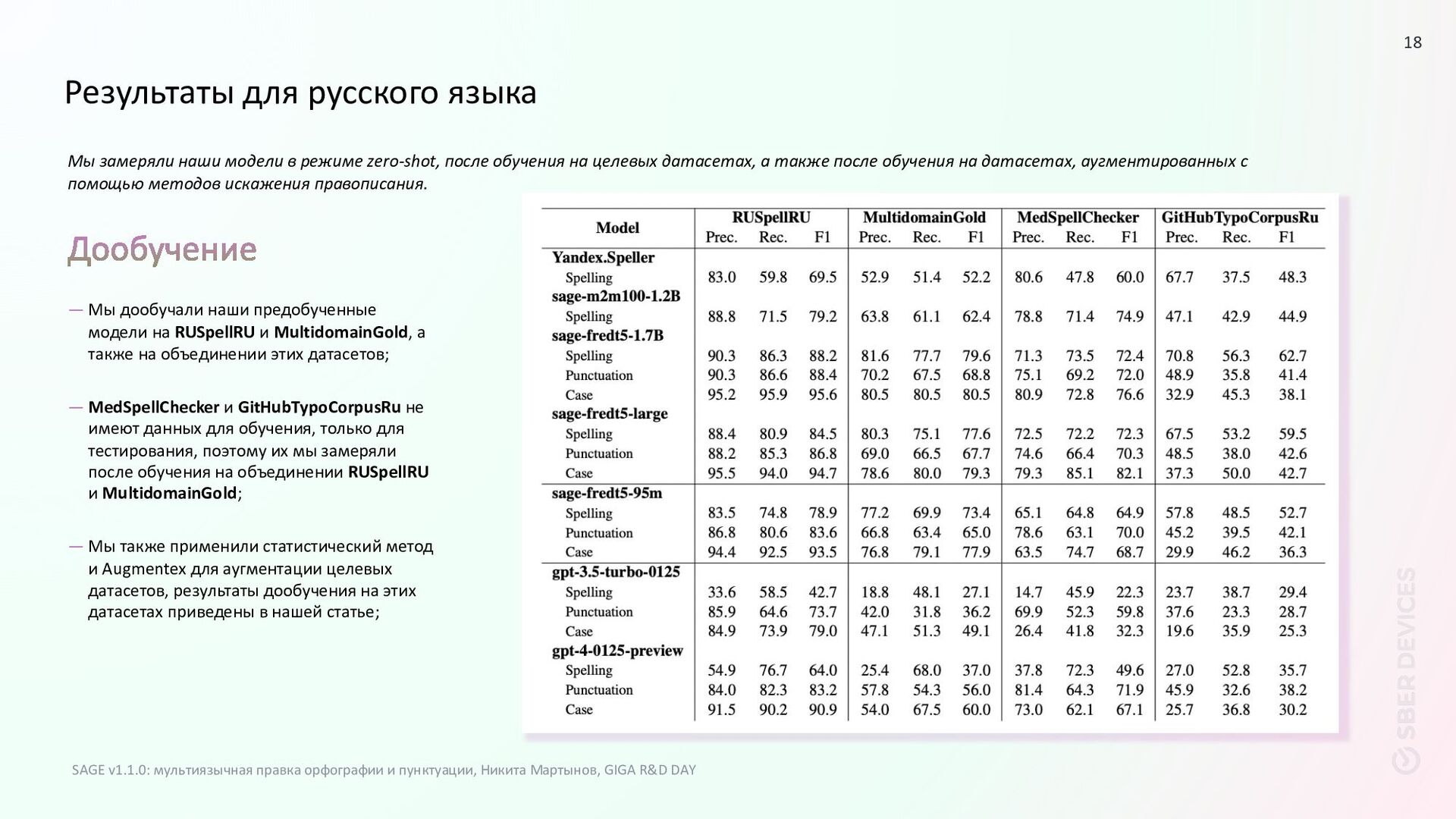
на RUSpellRU и MultidomainGold, а также на объединении этих датасетов; — MedSpellChecker и GitHubTypoCorpusRu не имеют данных для обучения, только для тестирования, поэтому их мы замеряли после обучения на объединении RUSpellRU и MultidomainGold; — Мы также применили статистический метод и Augmentex для аугментации целевых датасетов, результаты дообучения на этих датасетах приведены в нашей статье; Мы замеряли наши модели в режиме zero-shot, после обучения на целевых датасетах, а также после обучения на датасетах, аугментированных с помощью методов искажения правописания. SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 18
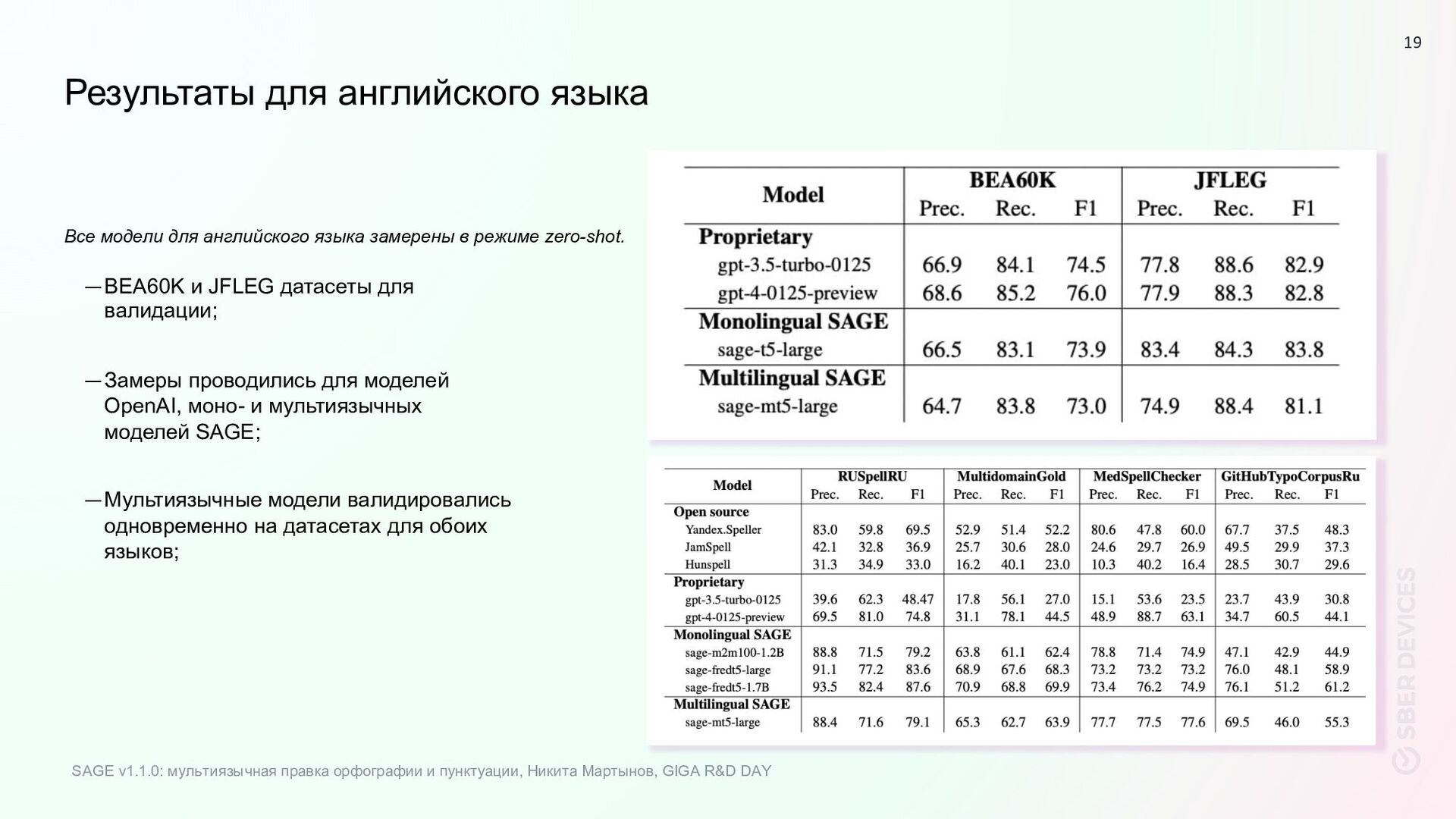
—Замеры проводились для моделей OpenAI, моно- и мультиязычных моделей SAGE; —Мультиязычные модели валидировались одновременно на датасетах для обоих языков; Все модели для английского языка замерены в режиме zero-shot. SAGE v1.1.0: мультиязычная правка орфографии и пунктуации, Никита Мартынов, GIGA R&D DAY 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}