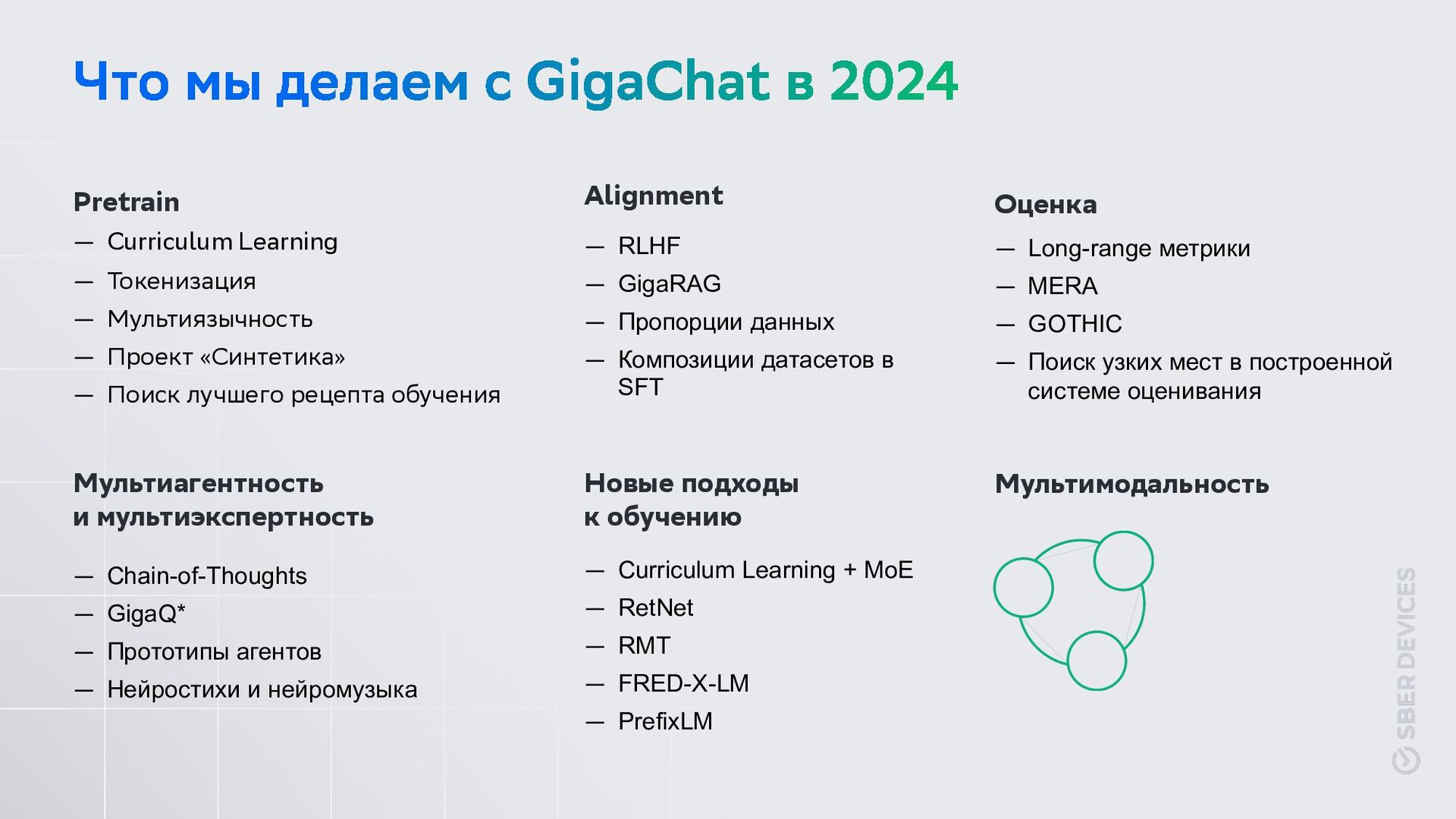
юзера. Идея: Создаём метки под «источники данных» — банк реплик, база QA, библиотека гигауниверситета: физика, математика, …, индекс СС (вместо интернета) и т.п. Любой запрос юзера отвечается в два прохода: — Первый запуск – модель отвечает мультилейбл спецтокены, в какие источники данных ей нужно сходить (из п.1), а также формулирует запросы в эти источники данных, т.к. логика поиска в них может быть разной. — Далее ретривал-компонента извлекает искомую инфу, подставляется в промпт — LLM генерирует финальный ответ Что было бы, если бы у Юпитера масса уменьшилась в 10 раз? Пример: LLM: Для ответа на вопрос нужна инфа из следующих баз: — QA-база, запрос «Юпитер» — Научная библиотека гигауниверситета, физика, запрос «Солнечная система, массы планет», «Небесная механика» Ретривал: <Выполняется поиск, выдаёт сниппеты> LLM: По объединенному промпту генерит ответ
представить как: — улучшение технологии мы ищем способы усилить разные стадии работы с LLM в ситуации, когда бОльшая часть низко висящих фруктов собрана.
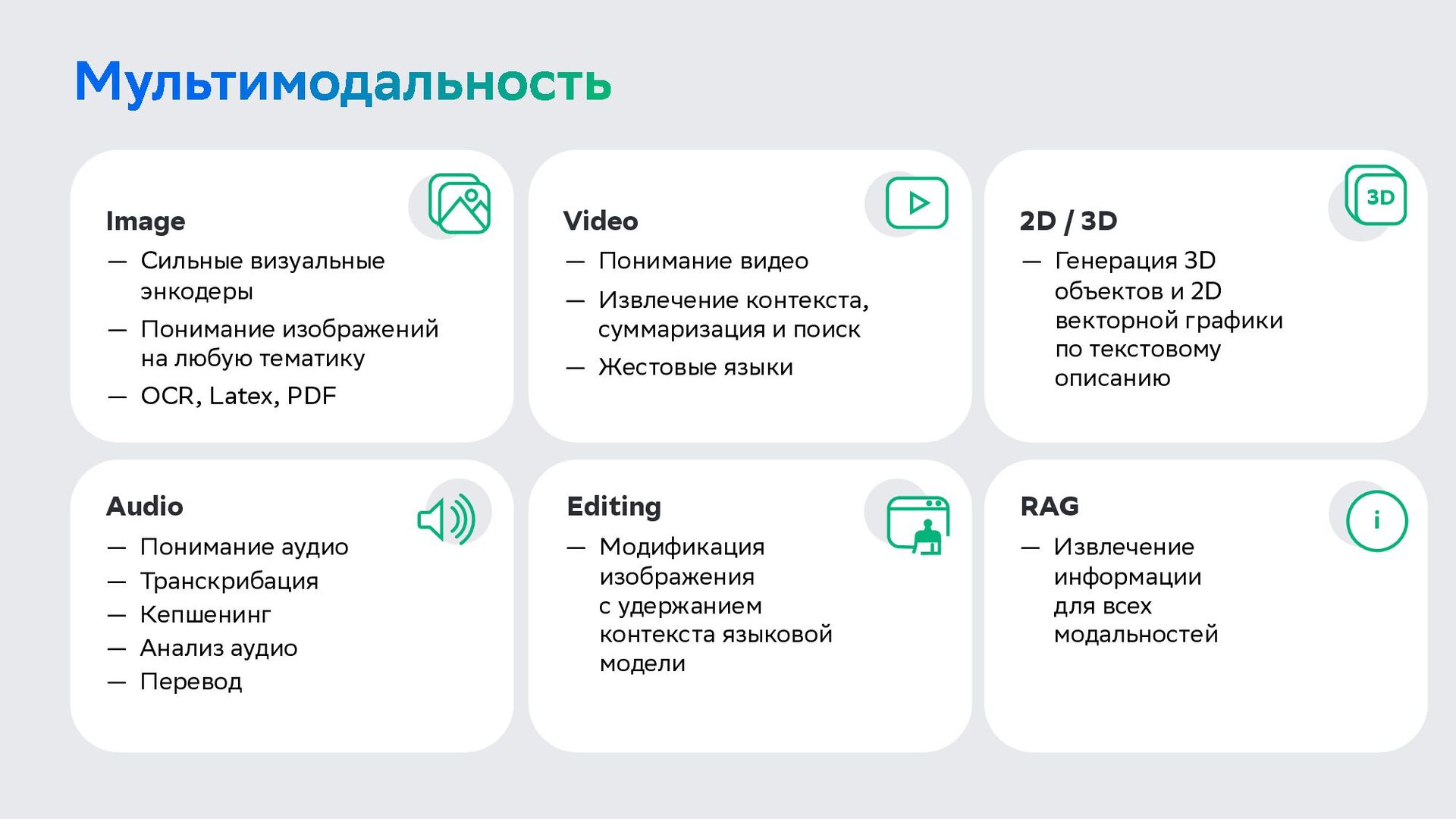
— OCR, Latex, PDF Image — Понимание видео — Извлечение контекста, суммаризация и поиск — Жестовые языки Video — Модификация изображения с удержанием контекста языковой модели Editing — Понимание аудио — Транскрибация — Кепшенинг — Анализ аудио — Перевод Audio — Генерация 3D объектов и 2D векторной графики по текстовому описанию 2D / 3D — Извлечение информации для всех модальностей RAG 3D i
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}