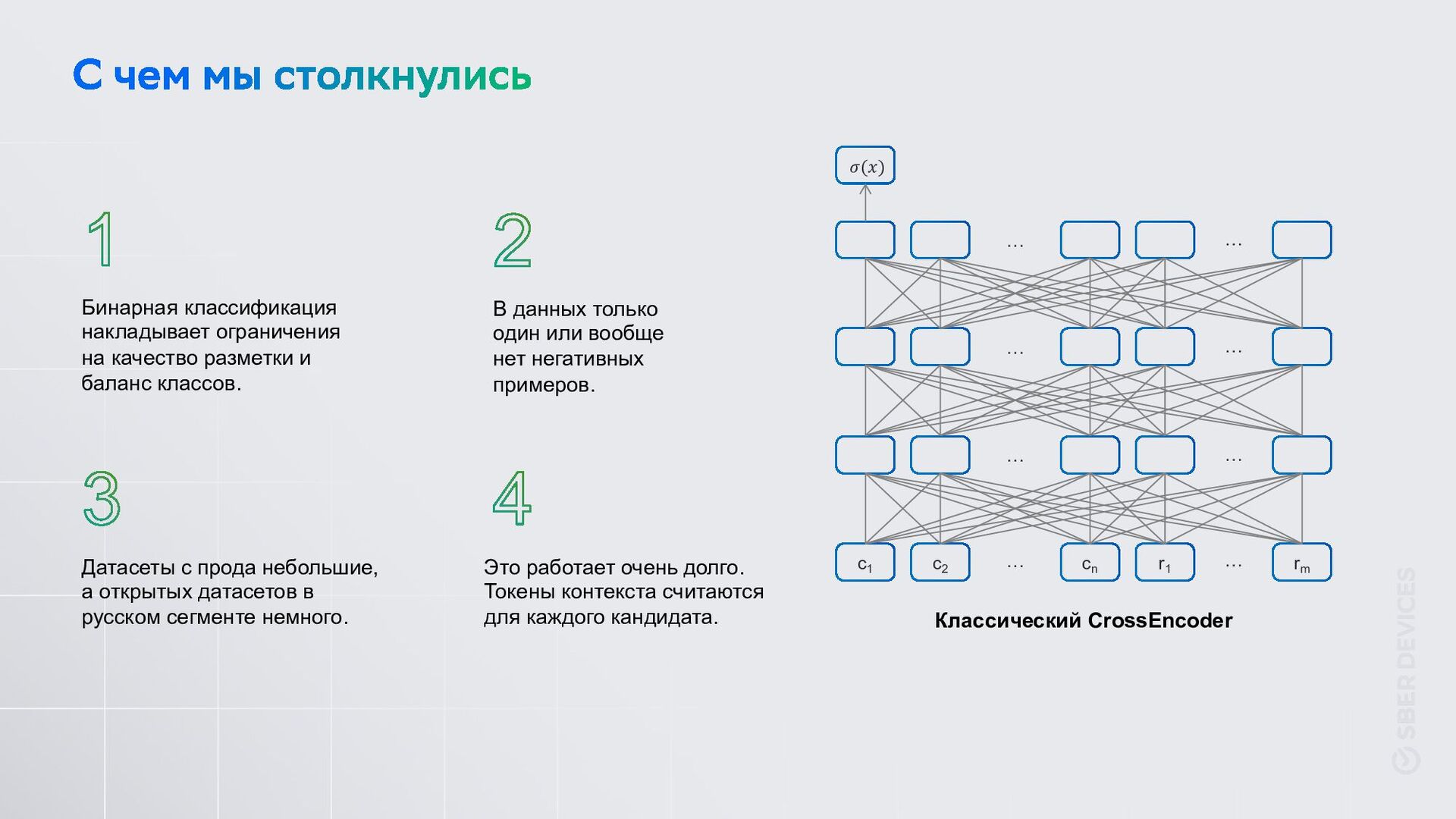
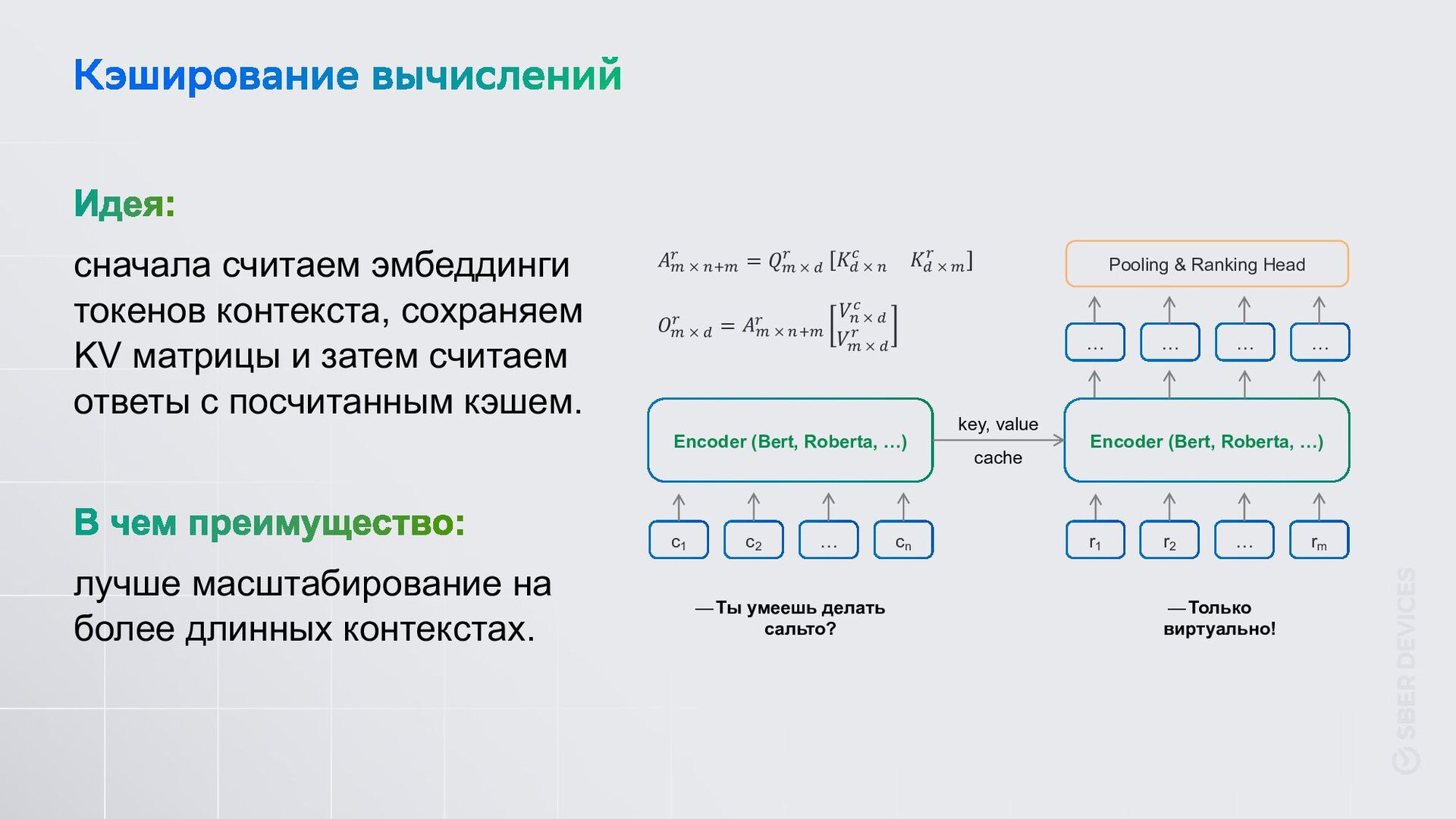
Датасеты с прода небольшие, а открытых датасетов в русском сегменте немного. В данных только один или вообще нет негативных примеров. Это работает очень долго. Токены контекста считаются для каждого кандидата. с1 с2 сn r1 rm 𝜎(𝑥) … … … … … … … … Классический CrossEncoder
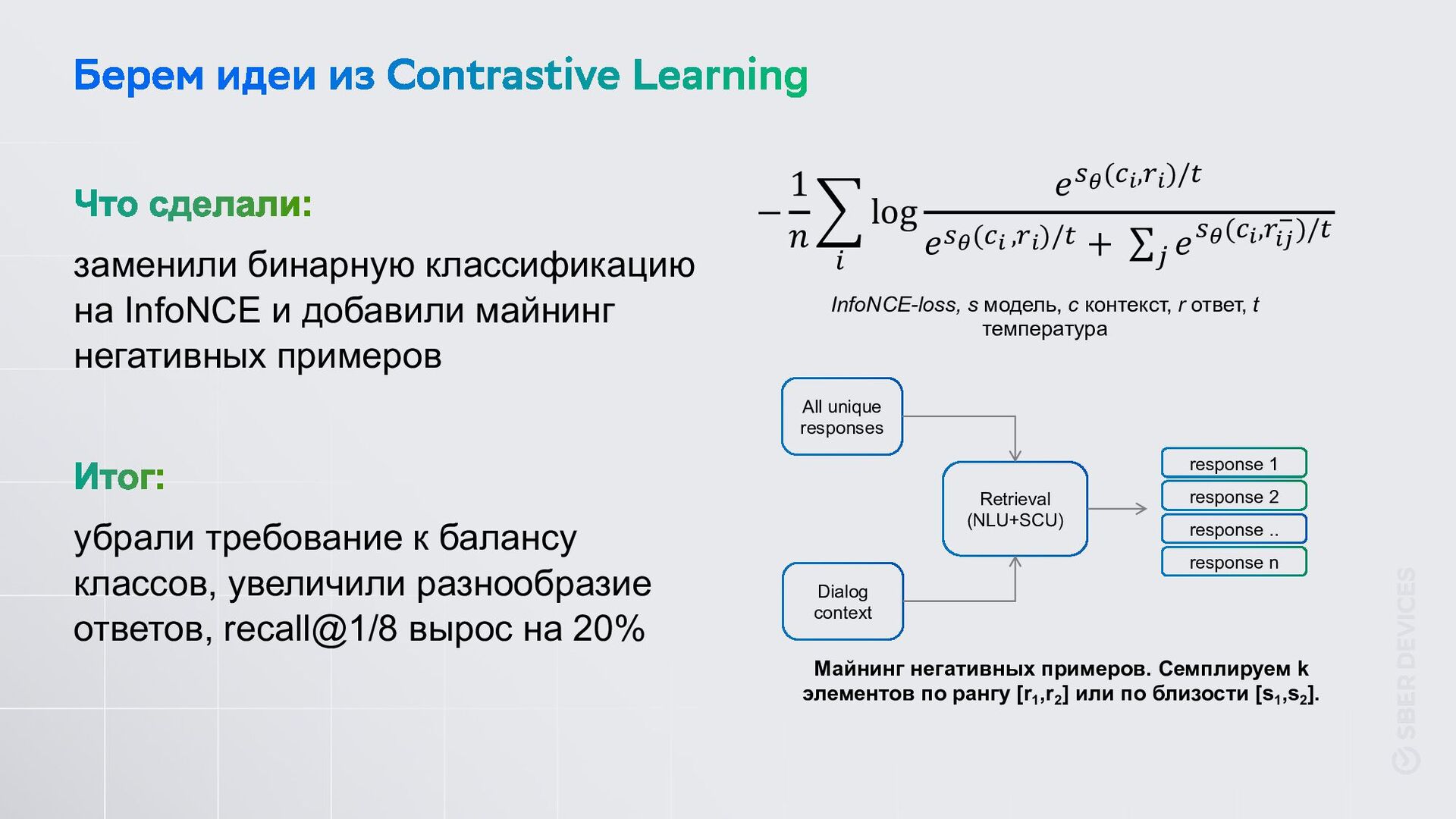
убрали требование к балансу классов, увеличили разнообразие ответов, recall@1/8 вырос на 20% − 1 𝑛 $ ! log 𝑒"!($",&")/) 𝑒"!($" ,&")/) + ∑* 𝑒"!($",&"# $)/) InfoNCE-loss, s модель, c контекст, r ответ, t температура All unique responses Retrieval (NLU+SCU) Dialog context response 1 response 2 response .. response n Майнинг негативных примеров. Семплируем k элементов по рангу [r1 ,r2 ] или по близости [s1 ,s2 ].
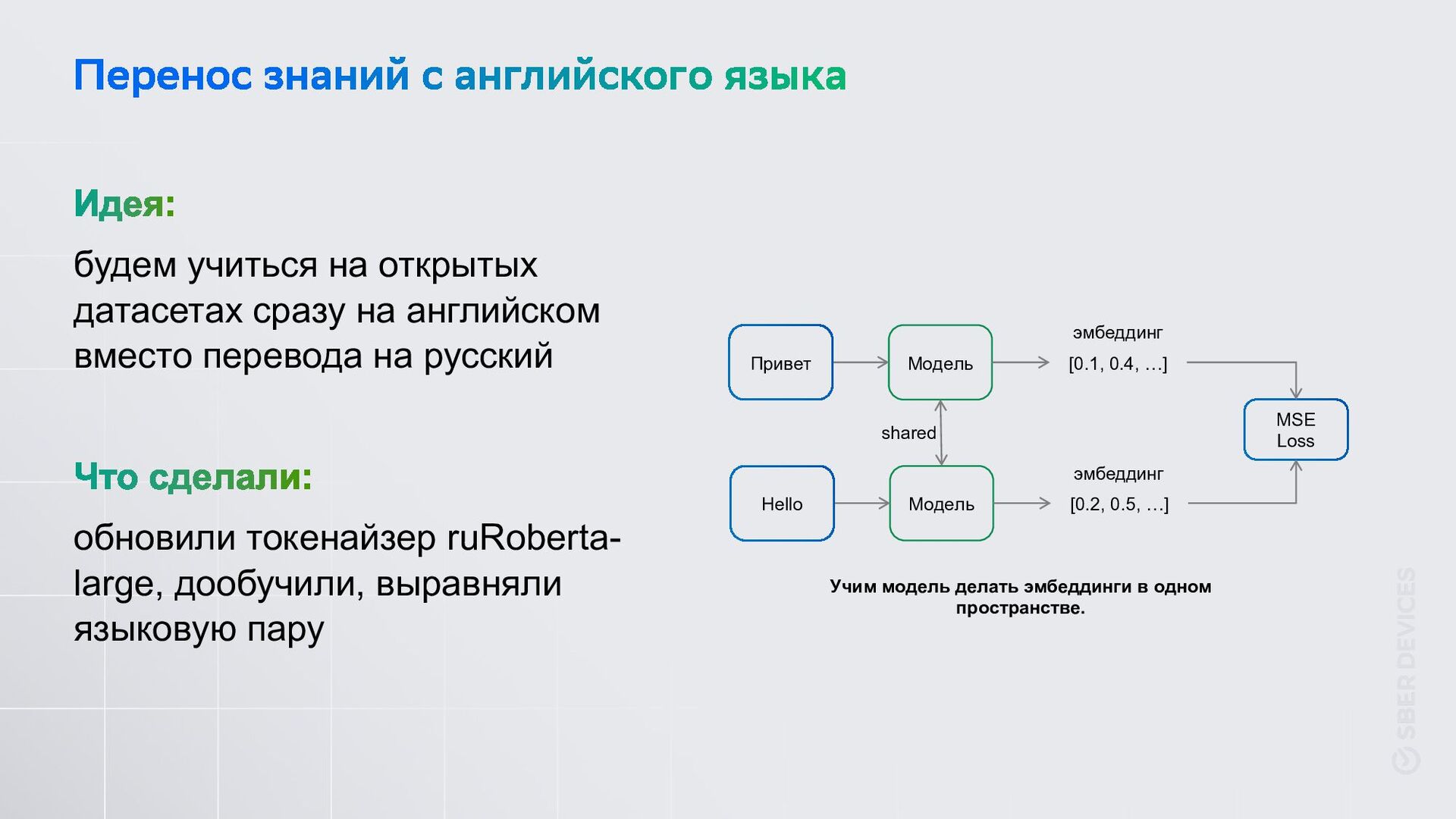
на русский обновили токенайзер ruRoberta- large, дообучили, выравняли языковую пару Модель Привет [0.1, 0.4, …] MSE Loss Модель Hello [0.2, 0.5, …] эмбеддинг эмбеддинг shared Учим модель делать эмбеддинги в одном пространстве.
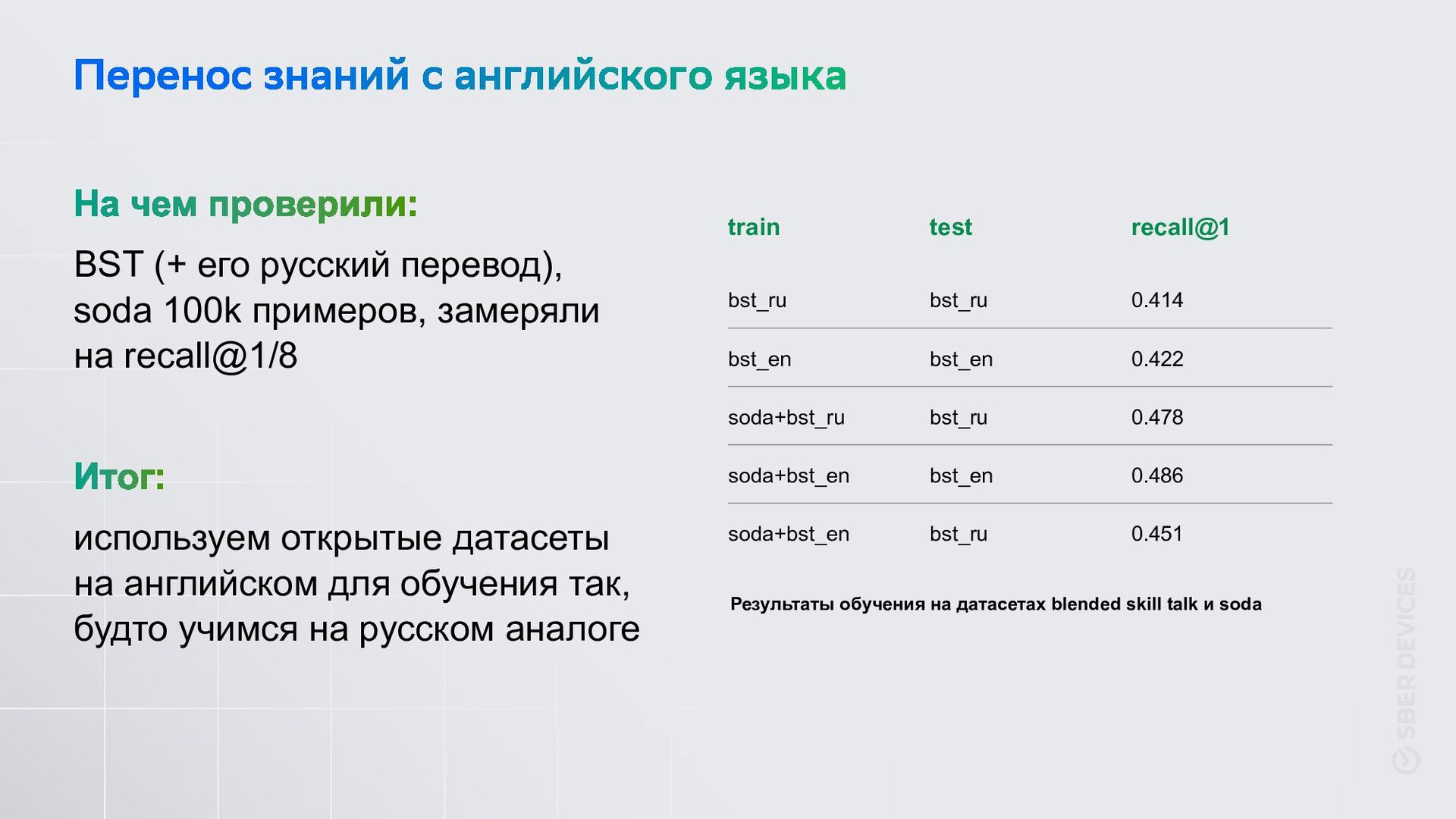
recall@1/8 используем открытые датасеты на английском для обучения так, будто учимся на русском аналоге train test recall@1 bst_ru bst_ru 0.414 bst_en bst_en 0.422 soda+bst_ru bst_ru 0.478 soda+bst_en bst_en 0.486 soda+bst_en bst_ru 0.451 Результаты обучения на датасетах blended skill talk и soda
навреди” по отношению к себе, пользователю и другим. Релевантность Главное понимать намерение пользователя, смысл диалога, отвечать «в тему», без учета других критериев. Достоверность Мы проверяем постоянные факты для которых возможно найти достоверный источник. Логика Смотрим есть ли противоречия со всем контекстом диалога и общими знаниями о мире. —У меня есть собака породы колли. —Здорово! А какой породы ваша собака? —Мне родители подарили компьютер. —Это отличная новость. Ты уже познакомился с родителями? —А лисы рожают лисят или медвежат? —Возможны оба варианта! —Получается по закону им жить нельзя? —В какой-то степени — да.
2.3 2.9 3.1 3.1 256 3.6 4.7 5.2 5.7 512 5.4 7.0 8.6 9.9 Количество кандидатов Длина в токенах Уменьшение latency (в n раз) в зависимости от длины последовательности и количества кандидатов. 16 32 64 128 64 1.0 1.0 1.0 1.0 128 1.0 1.0 1.1 1.2 256 1.1 1.2 1.3 1.6 512 1.3 1.6 2.1 2.6 Количество кандидатов Длина в токенах Уменьшение памяти (в n раз) в зависимости от длины последовательности и количества кандидатов. В замерах использовали bert-large в fp32, длина ответа всегда 32 токена (включена), вычисления произведены на картах A100.
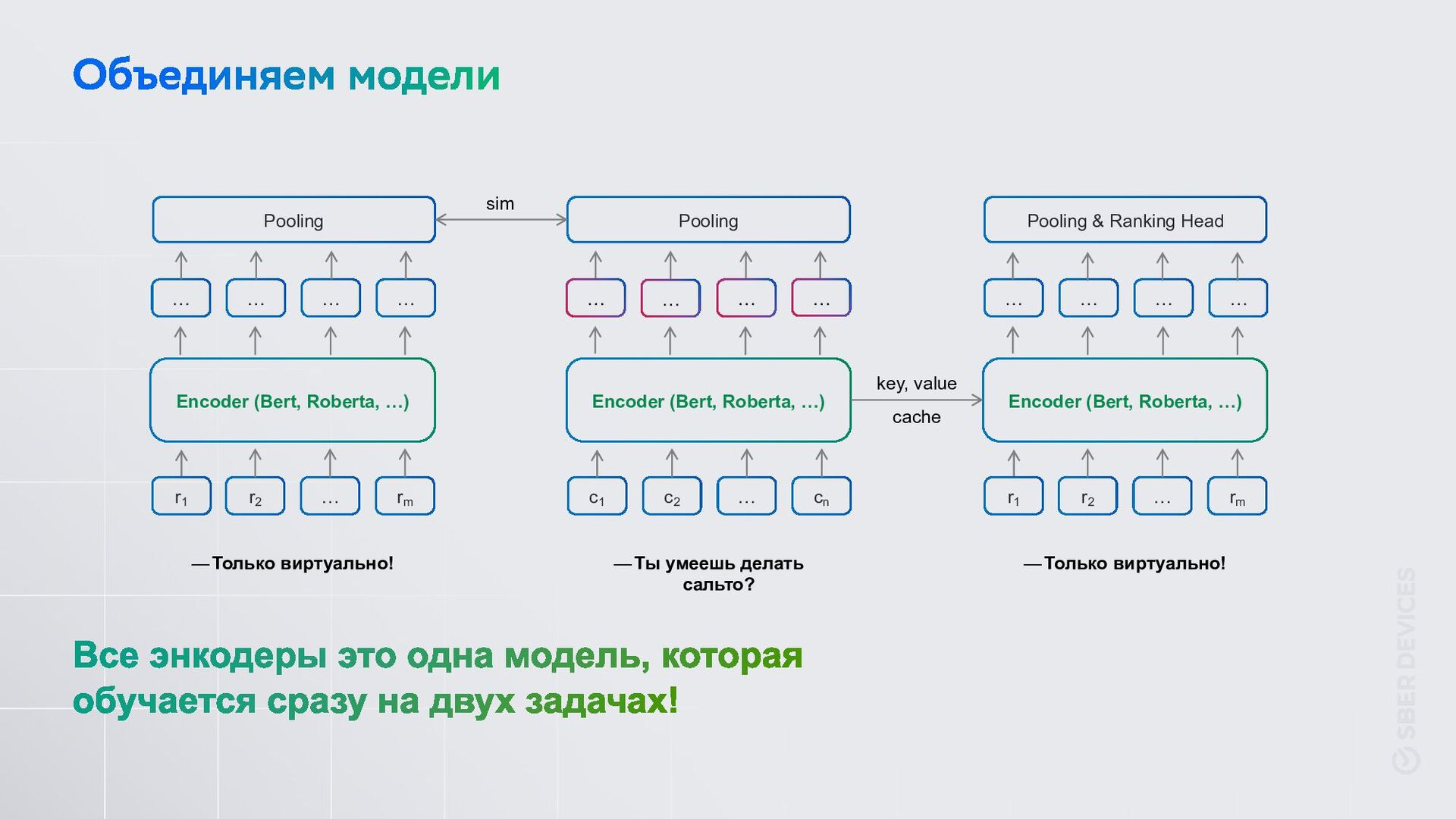
Можем добавить знаний за счет двуязычной модели и данных на английском Нашли способ ранжировать быстрее в ~7 раз и меньше по памяти в ~1.6 раз Можем использовать сеты без ручной разметки на негативные примеры
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}