Edited/improved talk available here: https://speakerdeck.com/halflings/pycon-sweden-ml-and-data-science-with-python
These slides were presented as part of workshop I hosted at a small KTH machine learning group, showcasing Python and its useful data-processing/machine learning capabilities.
I recommend running the following IPython notebooks as it shows the code examples included and the slides with their results: http://nbviewer.ipython.org/github/halflings/python-data-workshop/blob/master/data-workshop-notebook.ipynb
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Communicating with APIs import requests print requests.get(“https://www.googleapis.com/books/v1/volumes”, params={“q”:”machine learning”).json()[‘items’]](https://files.speakerdeck.com/presentations/13c373add1044ceab1ee36b052ac020a/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
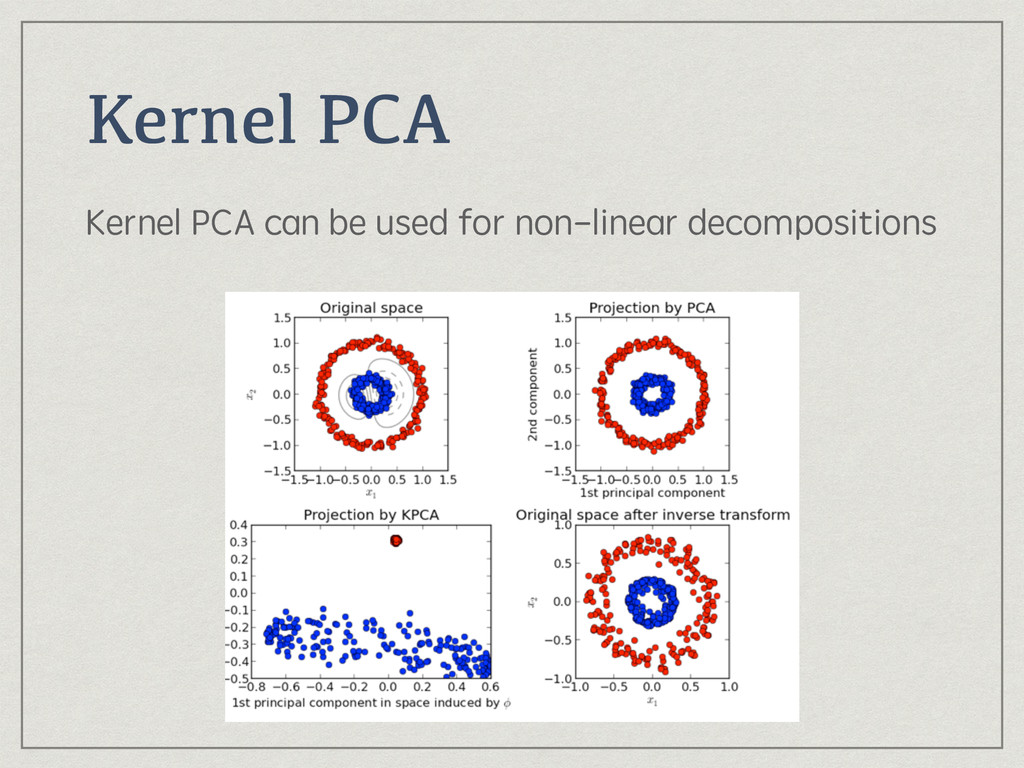{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
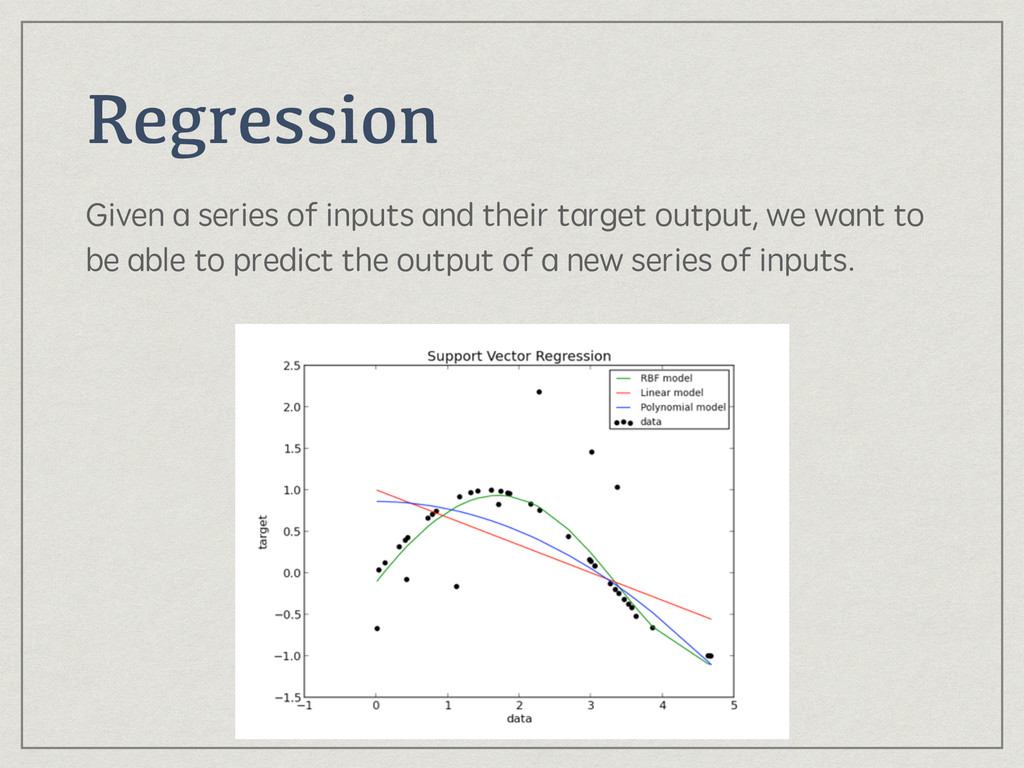{kind=link}
{kind=link}
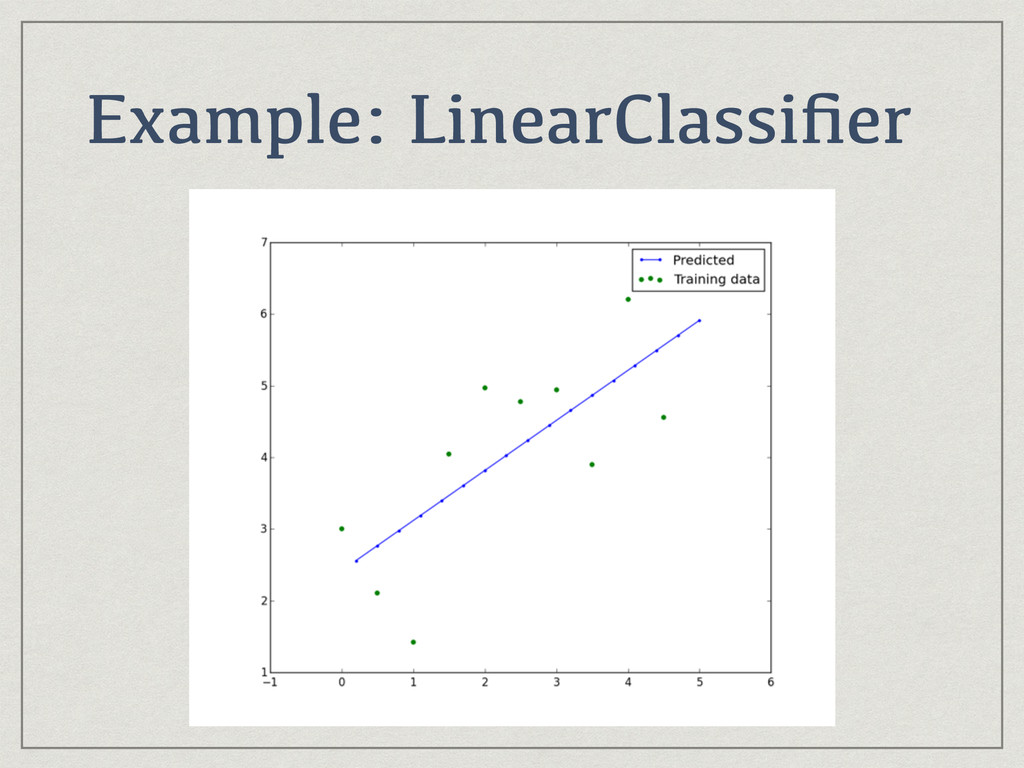{kind=link}
{kind=link}
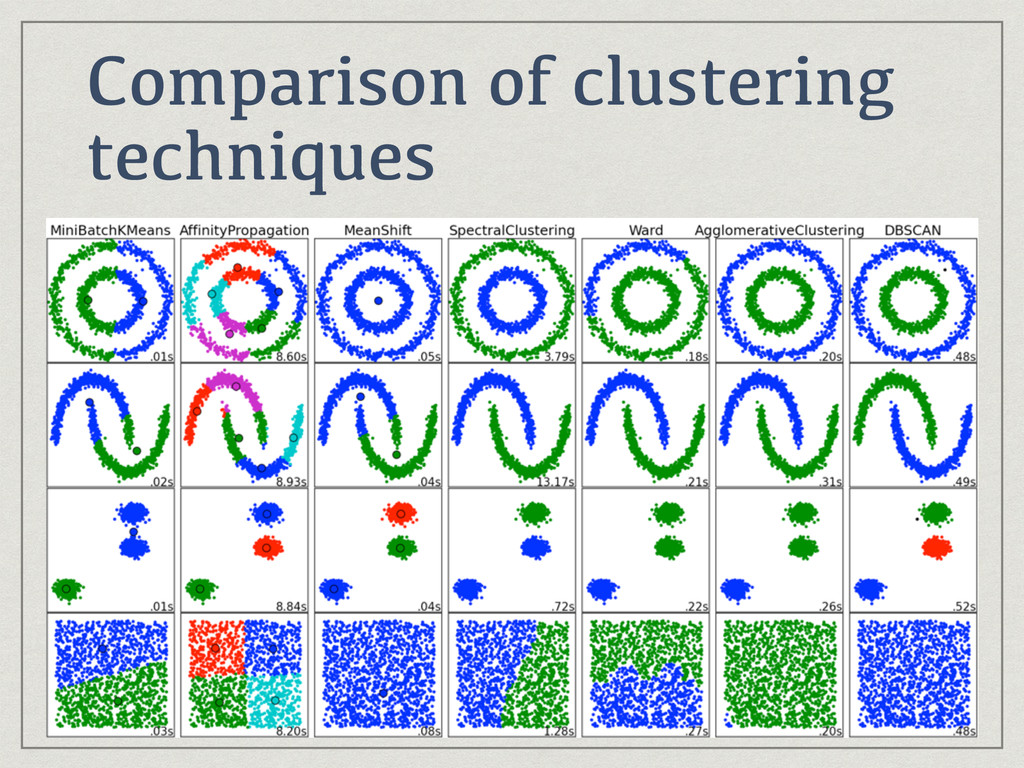{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
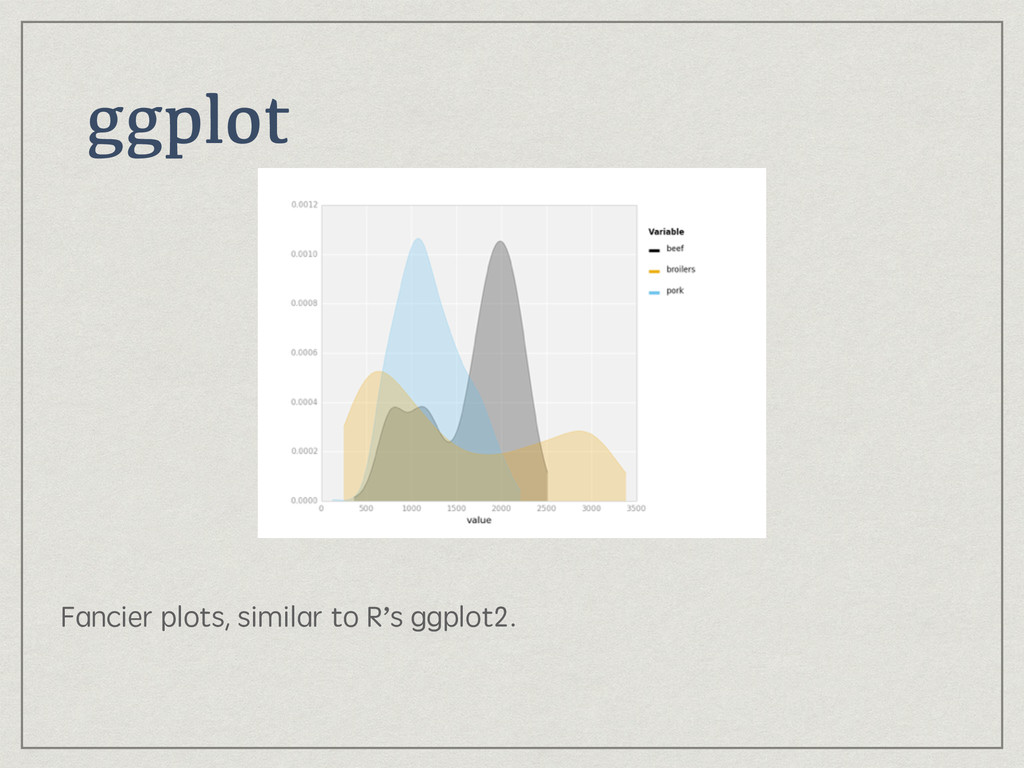{kind=link}
{kind=link}