Video recording of the talk available here: http://kachkach.com/data-processing-and-machine-learning-with-python/
This is an introductory talk to machine learning and data processing in Python, with some tips on ML tools and methods.
This talk is similar to the workshop I did at KTH (https://speakerdeck.com/halflings/data-processing-and-machine-learning-with-python) but many things were added/removed so check both of them out!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
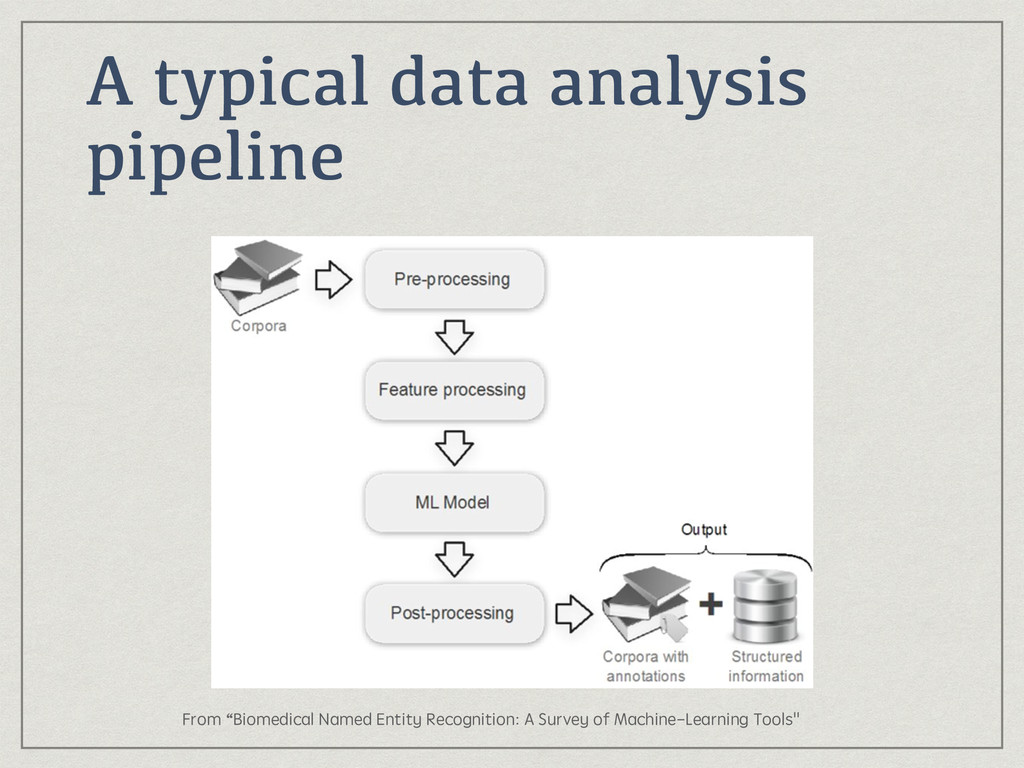{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Communicating with APIs import requests print requests.get(“https://www.googleapis.com/books/v1/volumes”, params={“q”:”machine learning”}).json()[‘items’]](https://files.speakerdeck.com/presentations/cd4ebd6b4c4f486dbf004eec2b471773/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
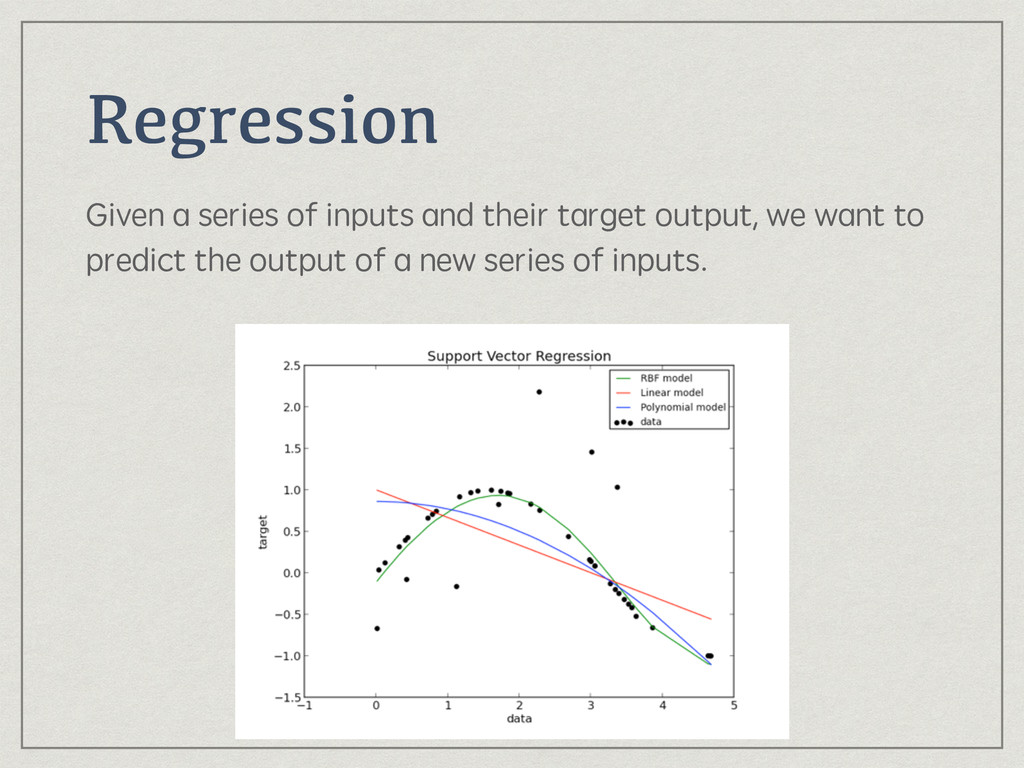{kind=link}
{kind=link}
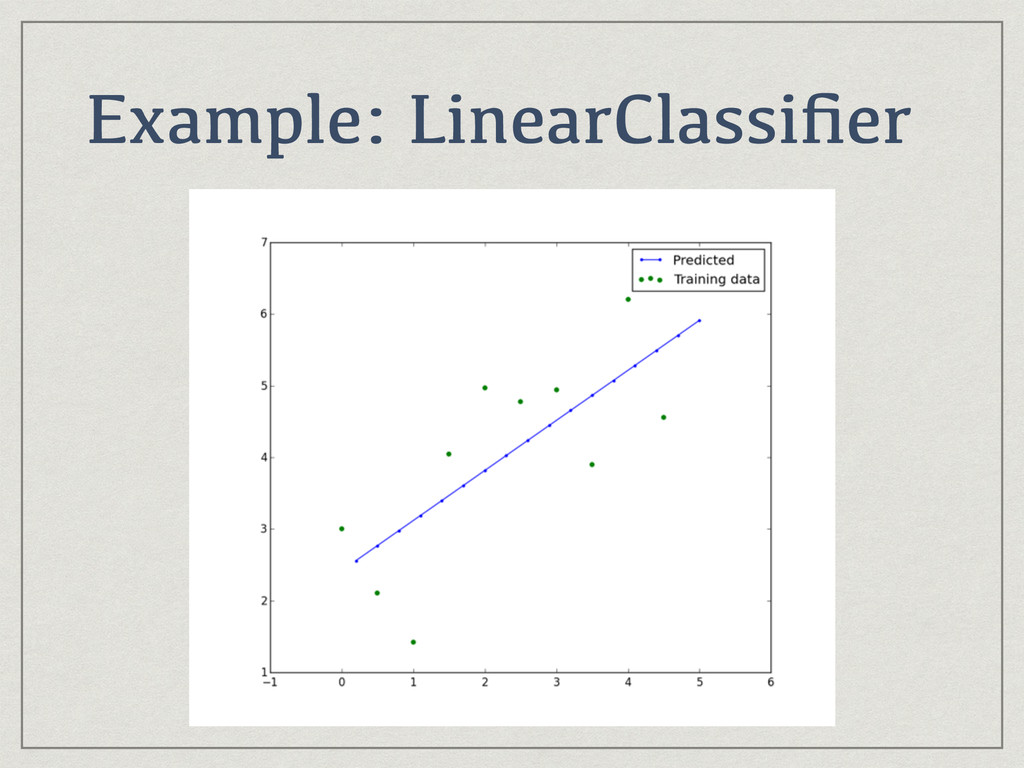{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}