в чем-то своем. А в чем именно? На чем основываться, выбирая NoSQL решение для своего проекта? Может быть на предпочтениях бабушки вашего ведущего программиста или на основе забрасывания сапога за ворота в ночь перед Рождеством? Давайте попробуем разобраться в критериях оценки и выявить различия между самыми популярными вариантами. Нас ждет увлекательный полет над гладью болот MongoDB, Cassandra, Riak, Hbase, Neo4j, CouchDB. А в тихом омуте, как известно, и черти водятся.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
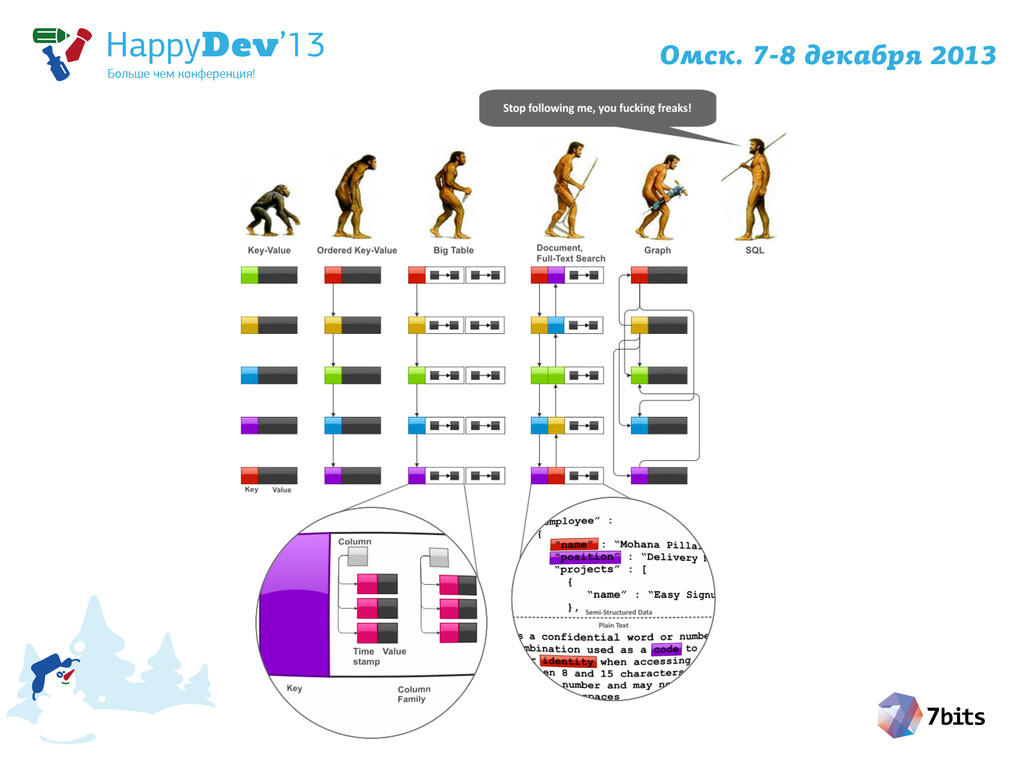{kind=link}
{kind=link}
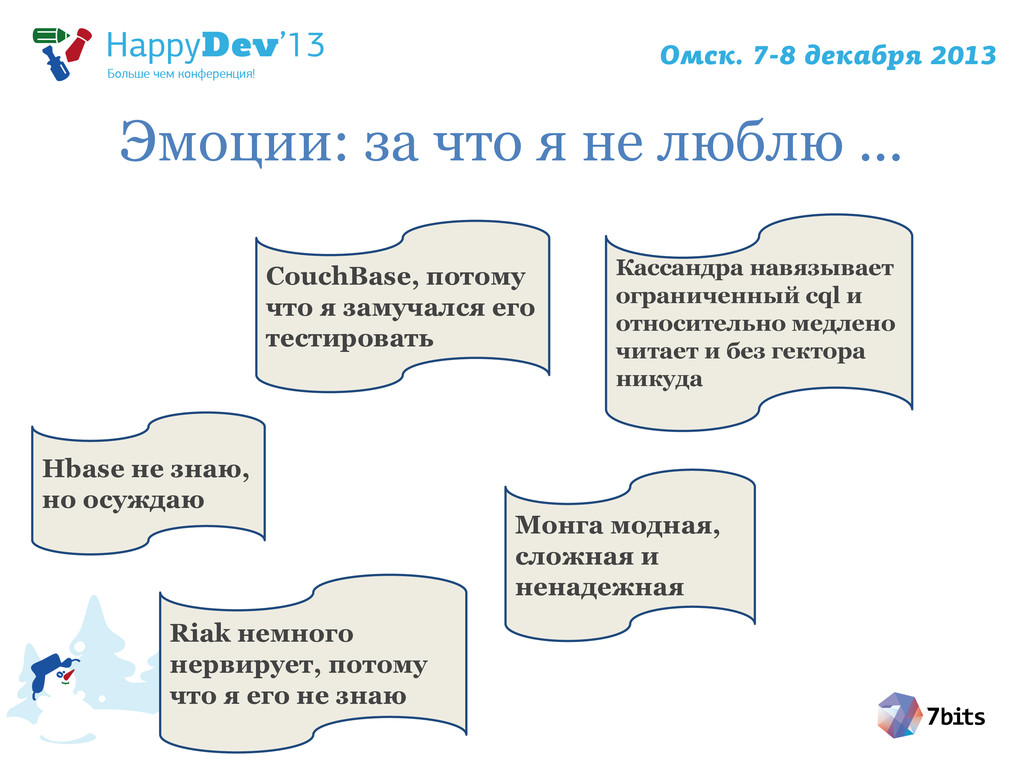{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
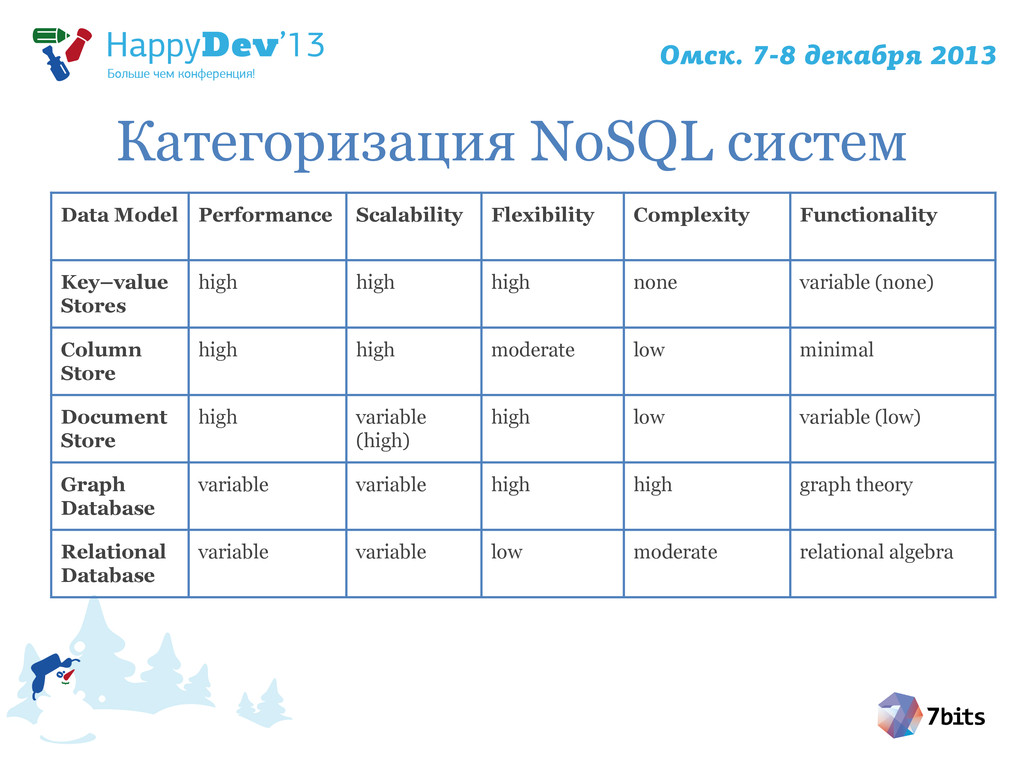{kind=link}
{kind=link}
{kind=link}
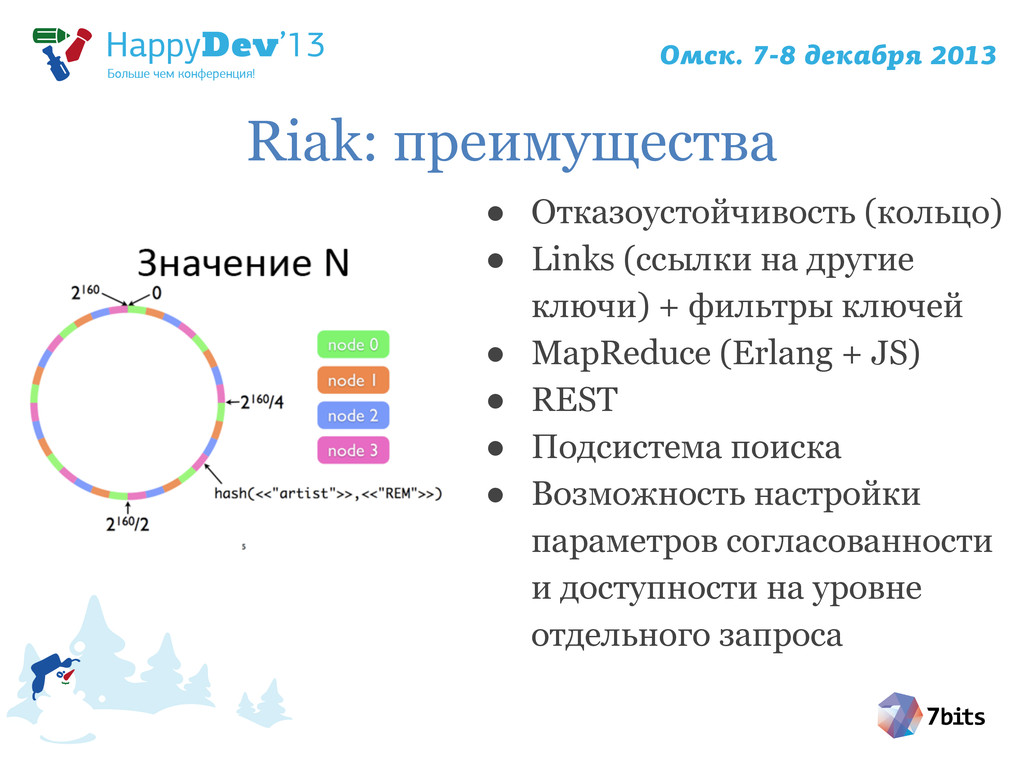{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
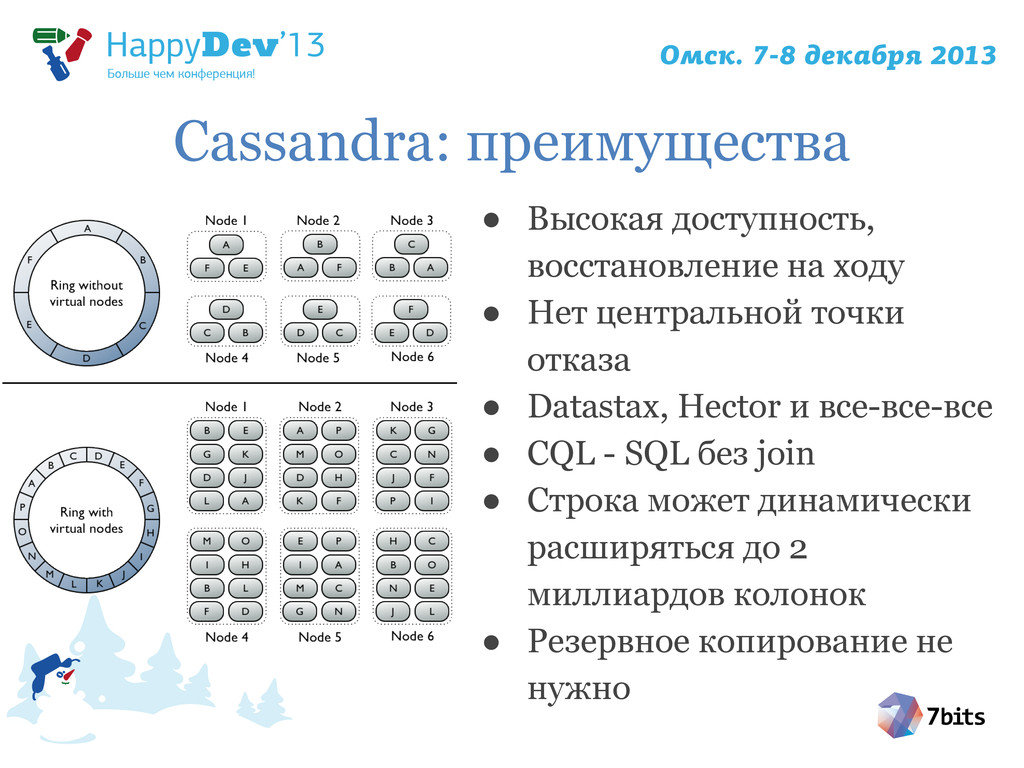{kind=link}
{kind=link}
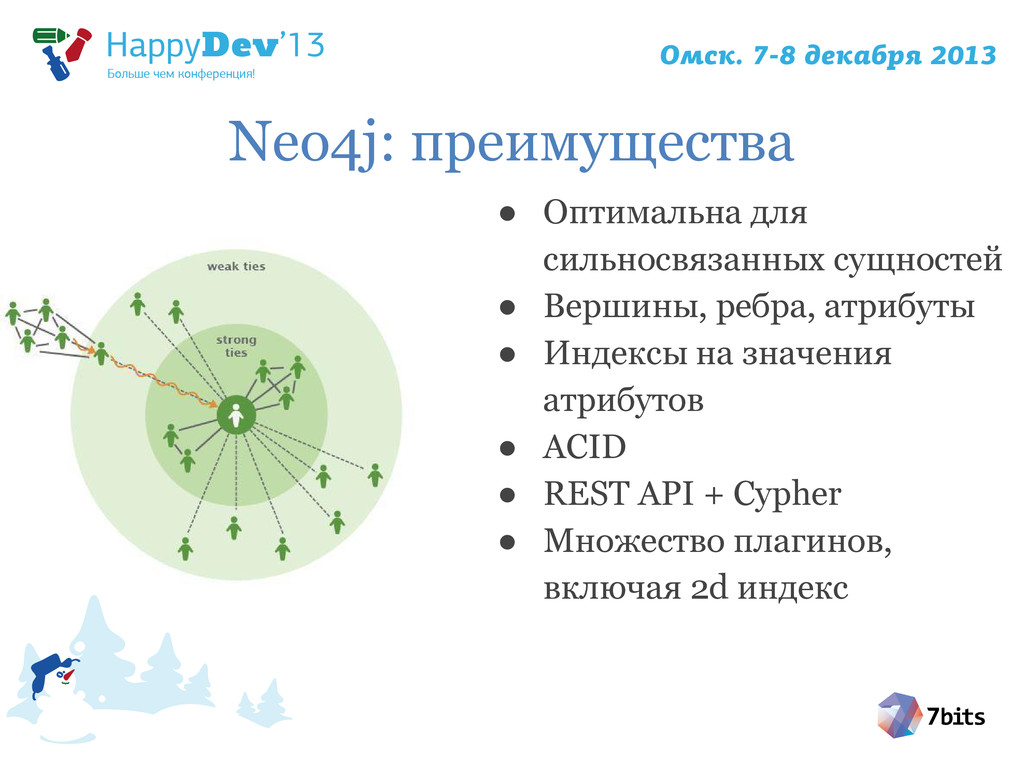{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}