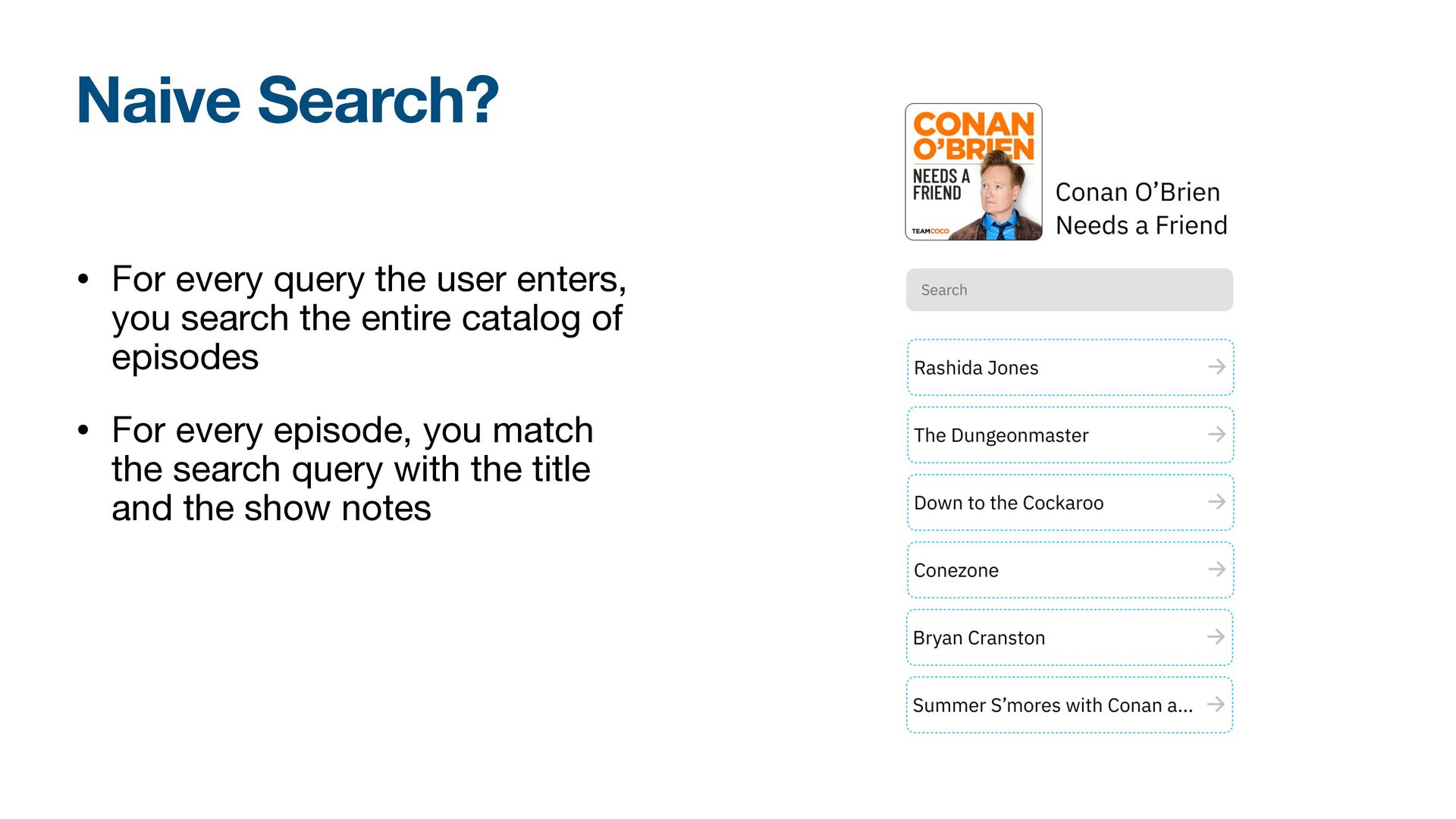
for every query • Inaccurate - You have limited options to check if a string matches your query • Limited - No easy way to order search results according to relevance Naive Search
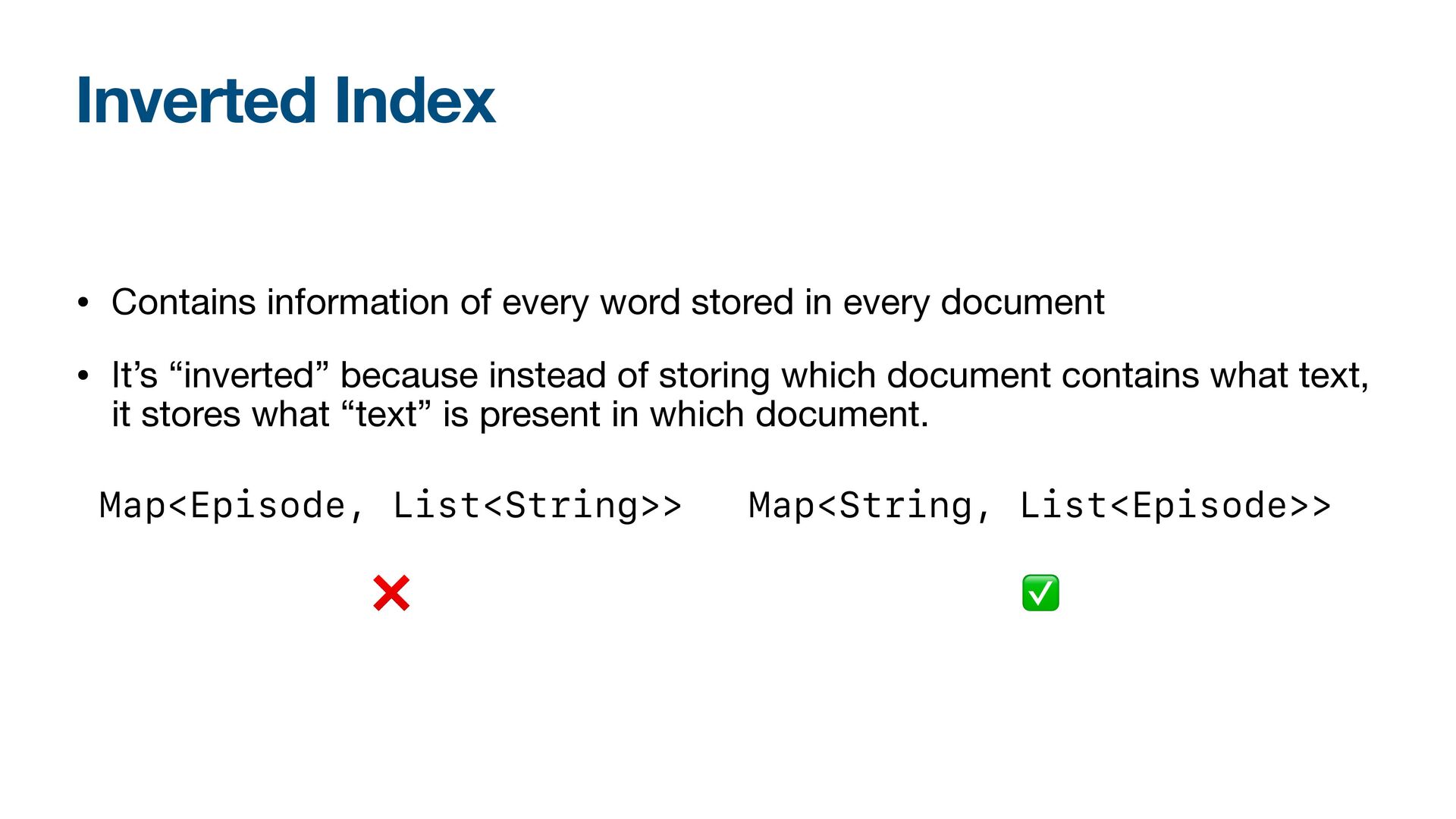
every document • It’s “inverted” because instead of storing which document contains what text, it stores what “text” is present in which document. Map<Episode, List<String>> ❌ Map<String, List<Episode>> ✅
can use it • Building the index takes time, but it speeds up search queries dramatically • Clever text processing allows the index to fi nd search results accurately • Cleverer data structures allow the index to be memory e ff i cient • Clevererer text analysis allows the index to rank search results e ff ectively TL; DR: The Inverted Index is 💫 Magic 💫
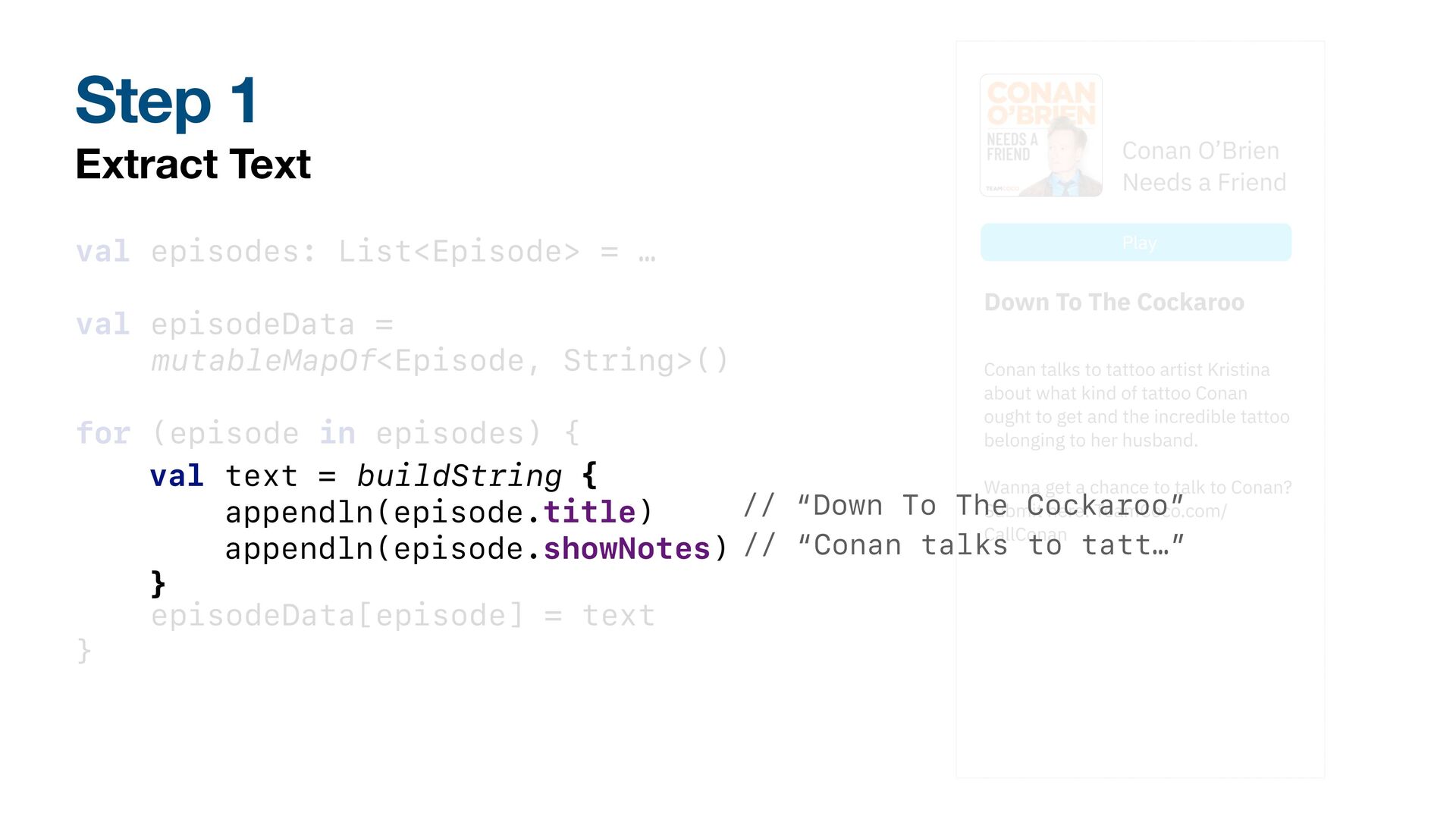
mutableMapOf<Episode, String>() for (episode in episodes) { val text = buildString { append(episode.title) append(episode.showNotes) } episodeData[episode] = text } Step 1
Comedian Comedian Patton Oswalt feels...", "Dating Your Family In Iceland Conan talks with Bjarki from Reykjavik...", "Bowen Yang Comedian Bowen Yang feels dissociative about being Conan...", "The Fiddler and The Ski Mall Conan speaks with Jesse at the World...", "Zach Galifianakis Returns Comedian Zach Galifianakis feels…sincere...", "Skull Soup Conan chats with Phil in Fall River, MA about working…", ... )
for words • Makes sense to break input text into words, or “tokens” • Tokens can be indexed by the Inverted Index • But tokens contain noise, and must be cleaned before indexing Step 2
• If they search for “sit”, they expect to see results for “sits” and “sitting” too • “Stemming” is a technique that helps reduce text to its original core Step 3 “After 25 years at the Late Night desk Conan realized that the only people at his holiday party are the men and women who work for him. Over the years and despite thousands of interviews Conan has never made a real and lasting friendship with any of his celebrity guests So he started a podcast to do just that.”
cient and customisable in-memory Full Text Search library for Kotlin - Memory e ff i cient FTS Index - Customisable Text Processing Pipeline - TF-IDF based search result ranking - Dead simple, concise API
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}