Simple linear regression Multivariable linear regression with Incanter Break Categorical data Bayes classification Logistic regression with Apache Commons Math Clustering with Parkour and Apache Mahout
s c l j d s . c h 1 . d a t a ( : r e q u i r e [ i n c a n t e r [ c o r e : a s i ] [ e x c e l : a s x l s ] ] [ c l o j u r e . j a v a . i o : a s i o ] ) ) ( d e f n u k - d a t a [ ] ( - > ( i o / r e s o u r c e " U K 2 0 1 0 . x l s " ) ( s t r ) ( x l s / r e a d - x l s ) ) ) ( i / v i e w ( u k - d a t a ) )
n e g i t @ g i t h u b . c o m : c l o j u r e d a t a s c i e n c e / c h 1 - i n t r o d u c t i o n . g i t c d c h 1 - i n t r o d u c t i o n s c r i p t / d o w n l o a d - d a t a . s h l e i n r u n - e 1 . 1
1 - 1 [ ] ( i / c o l - n a m e s ( u k - d a t a ) ) ) ; ; = > [ " P r e s s A s s o c i a t i o n R e f e r e n c e " " C o n s t i t u e n c y N a m e " " R e g i o n " " E l e c t i o n Y e a r " " E l e c t o r a t e " " V o t e s " " A C " " A D " " A G S " " A P N I " " A P P " " A W L " " A W P " " B B " " B C P " " B e a n " " B e s t " " B G P V " " B I B " " B I C " " B l u e " " B N P " " B P E l v i s " " C 2 8 " " C a m S o c " " C G " " C h M " " C h P " " C I P " " C I T Y " " C N P G " " C o m m " " C o m m L " " C o n " " C o r D " " C P A " " C S P " " C T D P " " C U R E " " D L a b " " D N a t " " D D P " " D U P " " E D " " E I P " " E P A " " F A W G " " F D P " " F F R " " G r n " " G S O T " " H u m " " I C H C " " I E A C " " I F E D " " I L E U " " I m p a c t " " I n d 1 " " I n d 2 " " I n d 3 " " I n d 4 " " I n d 5 " " I P T " " I S G B " " I S Q M " " I U K " " I V H " " I Z B " " J A C " " J o y " " J P " " L a b " " L a n d " " L D " " L i b " " L i b e r t " " L I N D " " L L P B " " L T T " " M A C I " " M C P " " M E D I " " M E P " " M I F " " M K " " M P E A " " M R L P " " M R P " " N a t L i b " " N C D V " " N D " " N e w " " N F " " N F P " " N I C F " " N o b o d y " " N S P S " " P B P " " P C " " P i r a t e " " P N D P " " P o e t " " P P B F " " P P E " " P P N V " " R e f o r m " " R e s p e c t " " R e s t " " R R G " " R T B P " " S A C L " " S c i " " S D L P " " S E P " " S F " " S I G " " S J P " " S K G P " " S M A " " S M R A " " S N P " " S o c " " S o c A l t " " S o c D e m " " S o c L a b " " S o u t h " " S p e a k e r " " S S P " " T F " " T O C " " T r u s t " " T U S C " " T U V " " U C U N F " " U K I P " " U P S " " U V " " V C C A " " V o t e " " W e s s e x R e g " " W R P " " Y o u " " Y o u t h " " Y R D P L " ]
∑n i=1 is a function of x and the mean of x ( − x i μ x )2 ( d e f n v a r i a n c e [ x s ] ( l e t [ m ( m e a n x s ) n ( c o u n t x s ) s q u a r e - e r r o r ( f n [ x ] ( M a t h / p o w ( - x m ) 2 ) ) ] ( / ( r e d u c e + ( m a p s q u a r e - e r r o r x s ) ) n ) ) )
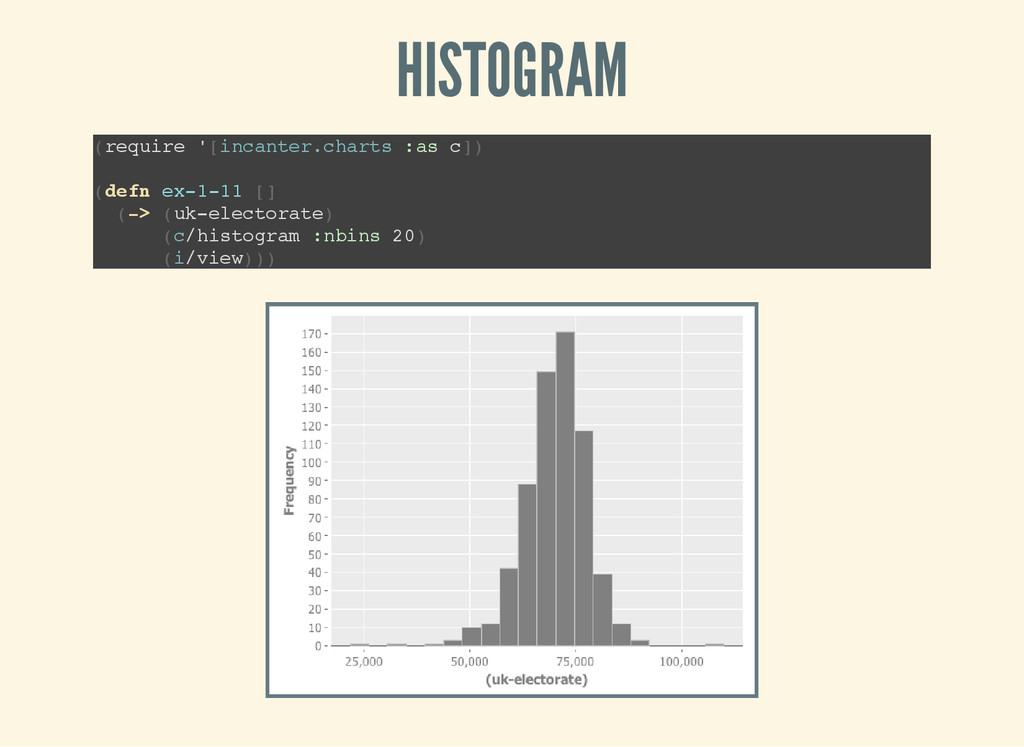
[ i n c a n t e r . c h a r t s : a s c ] ) ( d e f n e x - 1 - 1 1 [ ] ( - > ( u k - e l e c t o r a t e ) ( c / h i s t o g r a m : n b i n s 2 0 ) ( i / v i e w ) ) )
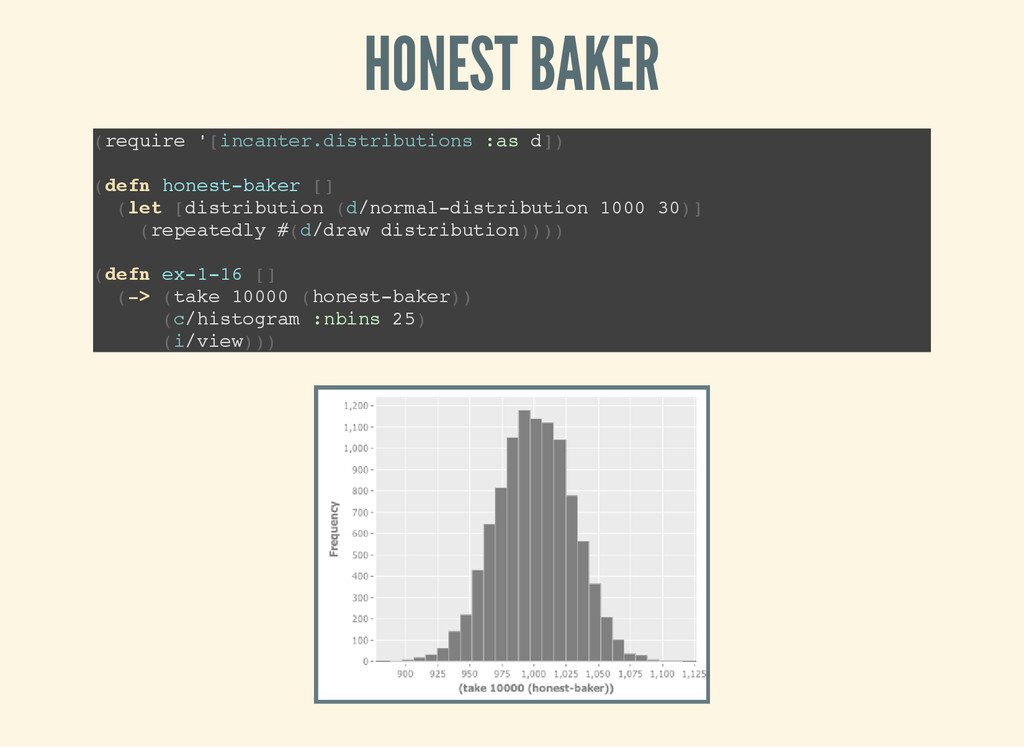
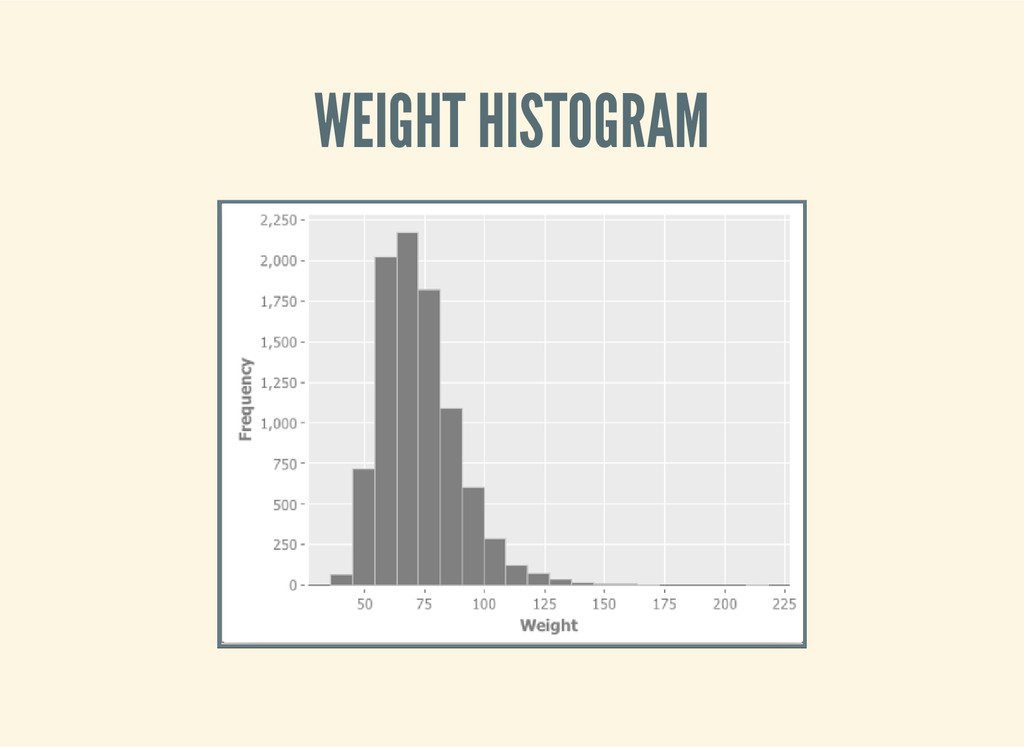
year. He discovered that the weights of the bread followed a normal distribution, but that the peak was at 950g, whereas loaves of bread were supposed to be regulated at 1kg. He reported his baker to the authorities. The next year Poincaré continued to weigh his bread from the same baker, who was now wary of giving him the lighter loaves. After a year the mean loaf weight was 1kg, but this time the distribution had a positive skew. This is consistent with the baker giving Poincaré only the heaviest of his loaves. The baker was reported to the authorities again
' [ i n c a n t e r . d i s t r i b u t i o n s : a s d ] ) ( d e f n h o n e s t - b a k e r [ ] ( l e t [ d i s t r i b u t i o n ( d / n o r m a l - d i s t r i b u t i o n 1 0 0 0 3 0 ) ] ( r e p e a t e d l y # ( d / d r a w d i s t r i b u t i o n ) ) ) ) ( d e f n e x - 1 - 1 6 [ ] ( - > ( t a k e 1 0 0 0 0 ( h o n e s t - b a k e r ) ) ( c / h i s t o g r a m : n b i n s 2 5 ) ( i / v i e w ) ) )
h o n e s t - b a k e r [ ] ( l e t [ d i s t r i b u t i o n ( d / n o r m a l - d i s t r i b u t i o n 9 5 0 3 0 ) ] ( - > > ( r e p e a t e d l y # ( d / d r a w d i s t r i b u t i o n ) ) ( p a r t i t i o n 1 3 ) ( m a p ( p a r t i a l a p p l y m a x ) ) ) ) ) ( d e f n e x - 1 - 1 7 [ ] ( - > ( t a k e 1 0 0 0 0 ( d i s h o n e s t - b a k e r ) ) ( c / h i s t o g r a m : n b i n s 2 5 ) ( i / v i e w ) ) )
e r - e l e c t i o n - y e a r [ d a t a ] ( i / $ w h e r e { " E l e c t i o n Y e a r " { : $ n e n i l } } d a t a ) ) ( d e f n f i l t e r - v i c t o r - c o n s t i t u e n c i e s [ d a t a ] ( i / $ w h e r e { " C o n " { : $ f n n u m b e r ? } " L D " { : $ f n n u m b e r ? } } d a t a ) )
a t a ) ( f i l t e r - e l e c t i o n - y e a r ) ( f i l t e r - v i c t o r - c o n s t i t u e n c i e s ) ( i / $ [ " R e g i o n " " E l e c t o r a t e " " C o n " " L D " ] ) ( i / a d d - d e r i v e d - c o l u m n " V i c t o r s " [ " C o n " " L D " ] + ) ( i / a d d - d e r i v e d - c o l u m n " V i c t o r s S h a r e " [ " V i c t o r s " " E l e c t o r a t e " ] / ) ( i / v i e w ) )
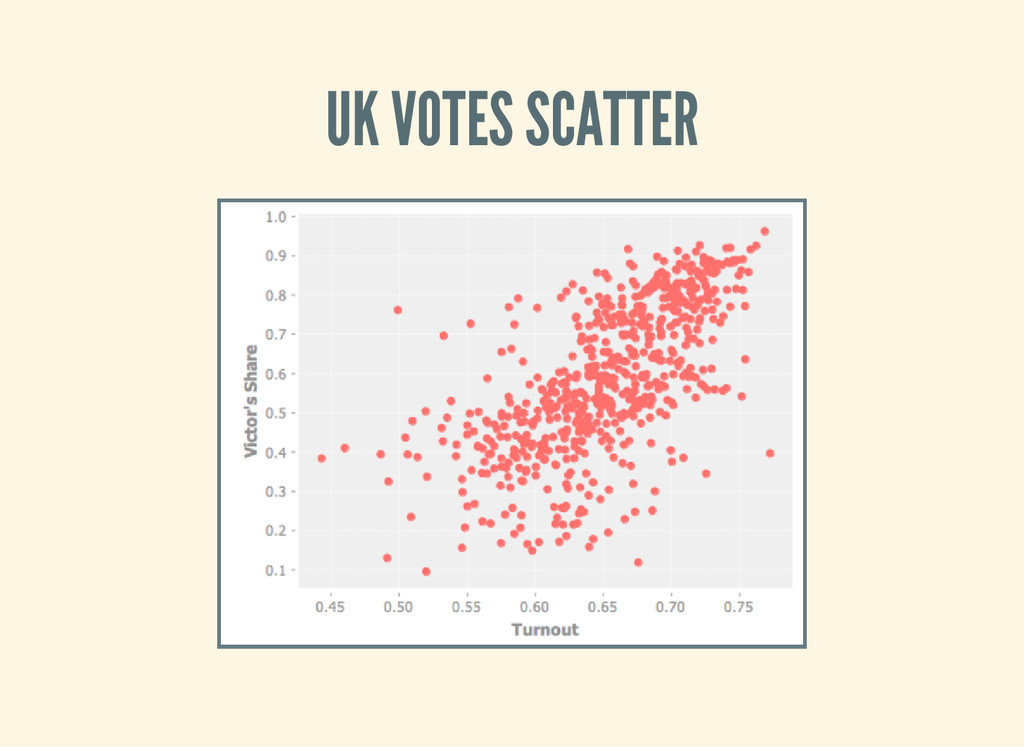
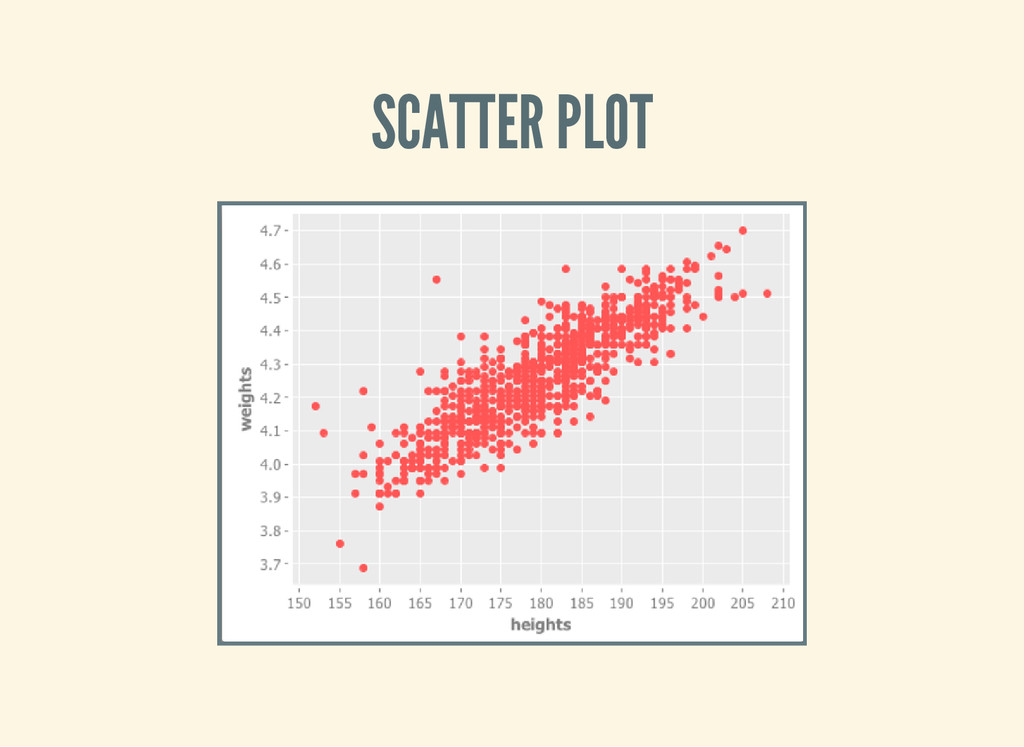
x - 1 - 3 3 [ ] ( l e t [ d a t a ( - > > ( u k - d a t a ) ( c l e a n - u k - d a t a ) ( d e r i v e - u k - d a t a ) ) ] ( - > ( s c a t t e r - p l o t ( $ " T u r n o u t " d a t a ) ( $ " V i c t o r s S h a r e " d a t a ) : x - l a b e l " T u r n o u t " : y - l a b e l " V i c t o r ' s S h a r e " ) ( v i e w ) ) ) )
[ n - b i n s x s ] ( l e t [ m i n - x ( a p p l y m i n x s ) r a n g e - x ( - ( a p p l y m a x x s ) m i n - x ) m a x - b i n ( d e c n - b i n s ) b i n - f n ( f n [ x ] ( - > x ( - m i n - x ) ( / r a n g e - x ) ( * n - b i n s ) i n t ( m i n m a x - b i n ) ) ) ] ( m a p b i n - f n x s ) ) ) ( d e f n e x - 1 - 1 0 [ ] ( - > > ( u k - e l e c t o r a t e ) ( b i n 1 0 ) ( f r e q u e n c i e s ) ) ) ; ; = > { 0 1 , 1 1 , 2 4 , 3 2 2 , 4 1 3 0 , 5 3 2 0 , 6 1 5 6 , 7 1 5 , 9 1 }
s t o g r a m - 2 d [ x s y s n - b i n s ] ( - > ( m a p v e c t o r ( b i n n - b i n s x s ) ( b i n n - b i n s y s ) ) ( f r e q u e n c i e s ) ) ) ( d e f n u k - h i s t o g r a m - 2 d [ ] ( l e t [ d a t a ( - > > ( u k - d a t a ) ( c l e a n - u k - d a t a ) ( d e r i v e - u k - d a t a ) ) ] ( h i s t o g r a m - 2 d ( $ " T u r n o u t " d a t a ) ( $ " V i c t o r s S h a r e " d a t a ) 5 ) ) ) ; ; = > { [ 2 1 ] 5 9 , [ 3 2 ] 9 1 , [ 4 3 ] 3 2 , [ 1 0 ] 8 , [ 2 2 ] 8 9 , [ 3 3 ] 1 0 1 , [ 4 4 ] 6 0 , [ 0 0 ] 2 , [ 1 1 ] 2 2 , [ 2 3 ] 1 9 , [ 3 4 ] 5 3 , [ 0 1 ] 6 , [ 1 2 ] 1 5 , [ 2 4 ] 5 , [ 1 3 ] 2 , [ 0 3 ] 1 , [ 3 0 ] 6 , [ 4 1 ] 3 , [ 3 1 ] 1 7 , [ 4 2 ] 1 7 , [ 2 0 ] 2 3 }
e ' [ q u i l . c o r e : a s q ] ) ( d e f n r a t i o - > g r a y s c a l e [ f ] ( - > f ( * 2 5 5 ) ( i n t ) ( m i n 2 5 5 ) ( m a x 0 ) ( q / c o l o r ) ) ) ( d e f n d r a w - h i s t o g r a m [ d a t a { : k e y s [ n - b i n s s i z e ] } ] ( l e t [ [ w i d t h h e i g h t ] s i z e x - s c a l e ( / w i d t h n - b i n s ) y - s c a l e ( / h e i g h t n - b i n s ) m a x - v a l u e ( a p p l y m a x ( v a l s d a t a ) ) s e t u p ( f n [ ] ( d o s e q [ x ( r a n g e n - b i n s ) y ( r a n g e n - b i n s ) ] ( l e t [ v ( g e t d a t a [ x y ] 0 ) x - p o s ( * x x - s c a l e ) y - p o s ( - h e i g h t ( * y y - s c a l e ) ) ] ( q / f i l l ( r a t i o - > g r a y s c a l e ( / v m a x - v a l u e ) ) ) ( q / r e c t x - p o s y - p o s x - s c a l e y - s c a l e ) ) ) ) ] ( q / s k e t c h : s e t u p s e t u p : s i z e s i z e ) ) )
( d e f n r a t i o - > h e a t [ f ] ( l e t [ c o l o r s [ ( q / c o l o r 0 0 2 5 5 ) ; ; b l u e ( q / c o l o r 0 2 5 5 2 5 5 ) ; ; t u r q u o i s e ( q / c o l o r 0 2 5 5 0 ) ; ; g r e e n ( q / c o l o r 2 5 5 2 5 5 0 ) ; ; y e l l o w ( q / c o l o r 2 5 5 0 0 ) ] ; ; r e d f ( - > f ( m a x 0 . 0 0 0 ) ( m i n 0 . 9 9 9 ) ( * ( d e c ( c o u n t c o l o r s ) ) ) ) ] ( q / l e r p - c o l o r ( n t h c o l o r s f ) ( n t h c o l o r s ( i n c f ) ) ( r e m f 1 ) ) ) )
' [ r e a g e n t . c o r e : a s r ] ) ( d e f n r a n d n [ m e a n s d ] ( . . j s / j S t a t - n o r m a l ( s a m p l e m e a n s d ) ) ) ( d e f n n o r m a l - d i s t r i b u t i o n [ m e a n s d ] ( r e p e a t e d l y # ( r a n d n m e a n s d ) ) ) ( d e f s t a t e ( r / a t o m { : s a m p l e [ ] } ) ) ( d e f n u p d a t e - s a m p l e ! [ s t a t e ] ( s w a p ! s t a t e a s s o c : s a m p l e ( - > > ( n o r m a l - d i s t r i b u t i o n p o p u l a t i o n - m e a n p o p u l a t i o n - s d ) ( m a p i n t ) ( t a k e s a m p l e - s i z e ) ) ) )
w - s a m p l e [ s t a t e ] [ : b u t t o n { : o n - c l i c k # ( u p d a t e - s a m p l e ! s t a t e ) } " N e w S a m p l e " ] ) ( d e f n s a m p l e - l i s t [ s t a t e ] [ : d i v ( l e t [ s a m p l e ( : s a m p l e @ s t a t e ) ] [ : d i v [ : u l ( f o r [ n s a m p l e ] [ : l i n ] ) ] [ : d l [ : d t " S a m p l e M e a n : " ] [ : d d ( m e a n s a m p l e ) ] ] ] ) ] )
a y o u t - i n t e r f a c e [ ] [ : d i v [ : h 1 " N o r m a l S a m p l e " ] [ n e w - s a m p l e s t a t e ] [ s a m p l e - l i s t s t a t e ] ] ) ; ; R e n d e r t h e r o o t c o m p o n e n t ( d e f n r u n [ ] ( r / r e n d e r - c o m p o n e n t [ l a y o u t - i n t e r f a c e ] ( . g e t E l e m e n t B y I d j s / d o c u m e n t " r o o t " ) ) )
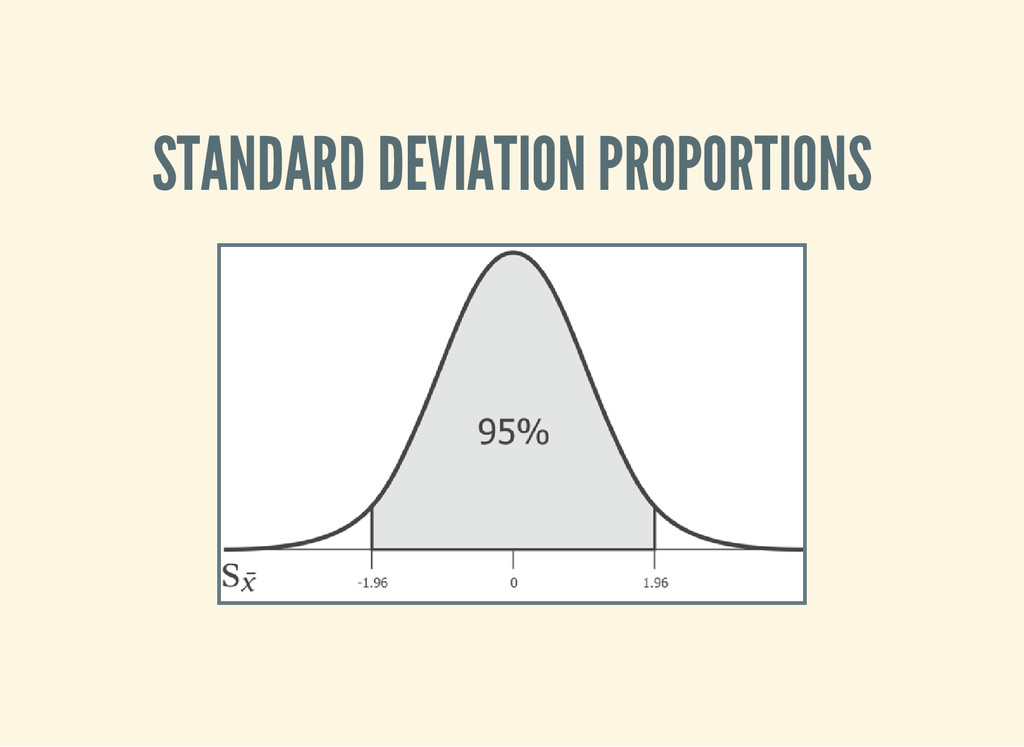
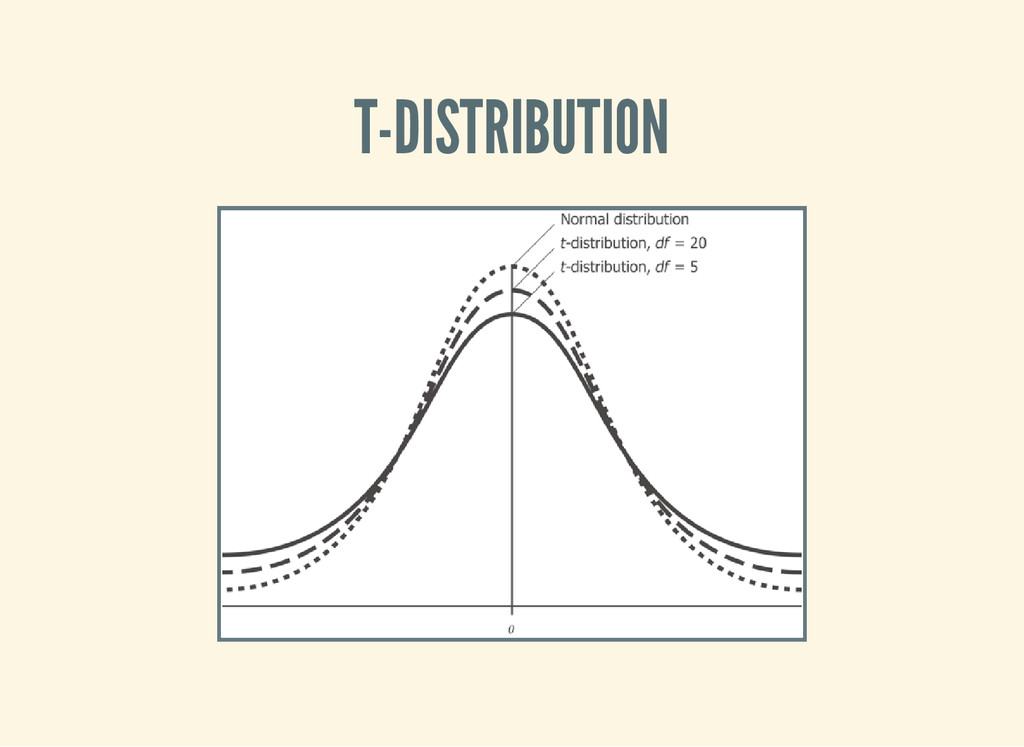
standard deviation, but we don't know it! In practice they're assumed to be the same above around 30 samples, but there is another distribution that models the loss of precision with small samples.
d e f n t - s t a t i s t i c [ s a m p l e t e s t - m e a n ] ( l e t [ s a m p l e - m e a n ( m e a n s a m p l e ) s a m p l e - s i z e ( c o u n t s a m p l e ) s a m p l e - s d ( s t a n d a r d - d e v i a t i o n s a m p l e ) ] ( / ( - s a m p l e - m e a n t e s t - m e a n ) ( / s a m p l e - s d ( M a t h / s q r t s a m p l e - s i z e ) ) ) ) )
support what the researcher is looking for. This conservative assumption is called the null hypothesis and denoted . h 0 The alternate hypothesis, , can then only be supported with a given confidence interval. h 1
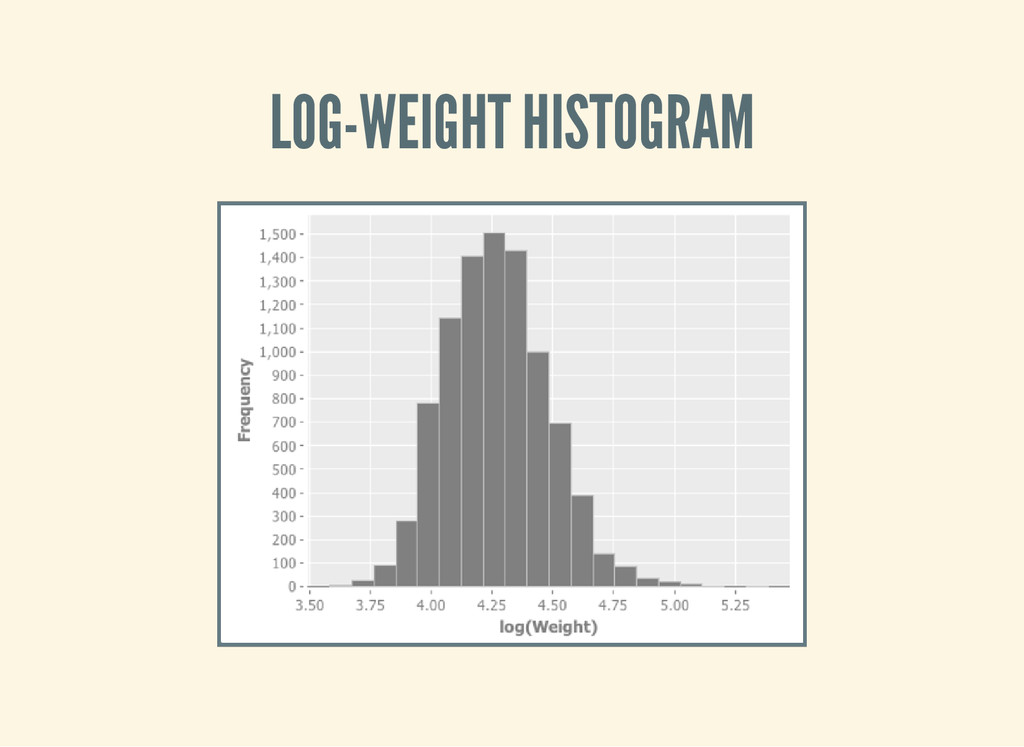
it can be thought of as the multiplicative product of many independent random variables, each of which is positive. This is justified by considering the central limit theorem in the log-domain."
It measures linear correlation. ρX, Y = COV(X,Y) σ X σ Y ( d e f n p e a r s o n s - c o r r e l a t i o n [ x y ] ( / ( c o v a r i a n c e x y ) ( * ( s t a n d a r d - d e v i a t i o n x ) ( s t a n d a r d - d e v i a t i o n y ) ) ) )
is the Greek letter . We are only able to calculate the sample statistic . ρ r How far we can trust as an estimate of will depend on two factors: r ρ the size of the coefficient the size of the sample rX, Y = COV(X,Y) sX sY
o p e [ x y ] ( / ( c o v a r i a n c e x y ) ( v a r i a n c e x ) ) ) ( d e f n i n t e r c e p t [ x y ] ( - ( m e a n y ) ( * ( m e a n x ) ( s l o p e x y ) ) ) ) ( d e f n p r e d i c t [ a b x ] ( + a ( * b x ) ) )
i m m e r - d a t a [ ] ( - > > ( a t h l e t e - d a t a ) ( $ w h e r e { " H e i g h t , c m " { : $ n e n i l } " W e i g h t " { : $ n e n i l } " S p o r t " { : $ e q " S w i m m i n g " } } ) ) ) ( d e f n e x - 3 - 1 2 [ ] ( l e t [ d a t a ( s w i m m e r - d a t a ) h e i g h t s ( $ " H e i g h t , c m " d a t a ) w e i g h t s ( l o g ( $ " W e i g h t " d a t a ) ) a ( i n t e r c e p t h e i g h t s w e i g h t s ) b ( s l o p e h e i g h t s w e i g h t s ) ] ( p r i n t l n " I n t e r c e p t : " a ) ( p r i n t l n " S l o p e : " b ) ) )
t 1 . 6 9 1 0 . 0 1 4 3 1 8 5 ) ; ; = > 4 . 3 3 6 5 ( i / e x p ( p r e d i c t 1 . 6 9 1 0 . 0 1 4 3 1 8 5 ) ) ; ; = > 7 6 . 4 4 Corresponding to a predicted weight of 76.4kg In 1979, Mark Spitz was 79kg. http://www.topendsports.com/sport/swimming/profiles/spitz- mark.htm
t u r e s [ d a t a s e t c o l - n a m e s ] ( - > > ( i / $ c o l - n a m e s d a t a s e t ) ( i / t o - m a t r i x ) ) ) ( d e f n g e n d e r - d u m m y [ g e n d e r ] ( i f ( = g e n d e r " F " ) 0 . 0 1 . 0 ) ) ( d e f n e x - 3 - 2 6 [ ] ( l e t [ d a t a ( - > > ( s w i m m e r - d a t a ) ( i / a d d - d e r i v e d - c o l u m n " G e n d e r D u m m y " [ " S e x " ] g e n d e r - d u m m y ) ) x ( f e a t u r e s d a t a [ " H e i g h t , c m " " A g e " " G e n d e r D u m m y " ] ) y ( i / l o g ( $ " W e i g h t " d a t a ) ) m o d e l ( s / l i n e a r - m o d e l y x ) ] ( : c o e f s m o d e l ) ) ) ; ; = > [ 2 . 2 3 0 7 5 2 9 4 3 1 4 2 2 6 3 7 0 . 0 1 0 7 1 4 6 9 7 8 2 7 1 2 1 0 8 9 0 . 0 0 2 3 7 2 1 8 8 7 4 9 4 0 8 5 7 4 0 . 0 9 7 5 4 1 2 5 3 2 4 9 2 0 2 6 ]
n p r e d i c t [ t h e t a x ] ( - > ( c l / t t h e t a ) ( c l / * x ) ( f i r s t ) ) ) ( d e f n e x - 3 - 2 7 [ ] ( l e t [ d a t a ( - > > ( s w i m m e r - d a t a ) ( i / a d d - d e r i v e d - c o l u m n " G e n d e r D u m m y " [ " S e x " ] g e n d e r - d u m m y ) ) x ( f e a t u r e s d a t a [ " H e i g h t , c m " " A g e " " G e n d e r D u m m y " ] ) y ( i / l o g ( $ " W e i g h t " d a t a ) ) m o d e l ( s / l i n e a r - m o d e l y x ) ] ( i / e x p ( p r e d i c t ( i / m a t r i x ( : c o e f s m o d e l ) ) ( i / m a t r i x [ 1 1 8 5 2 2 1 ] ) ) ) ) ) ; ; = > 7 8 . 4 6 8 8 2 7 7 2 6 3 1 6 9 7
n ‾ ‾ ‾‾‾‾‾‾‾ √ ( d e f n s t a n d a r d - e r r o r - p r o p o r t i o n [ p n ] ( - > ( - 1 p ) ( * p ) ( / n ) ( M a t h / s q r t ) ) ) = = 0.61 161 + 339 682 + 127 500 809 SE = 0.013
P1: the proportion of women who survived is = 0.76 339 446 P2: the proportion of men who survived = = 0.19 161 843 SE: 0.013 z = 20.36 This is essentially impossible.
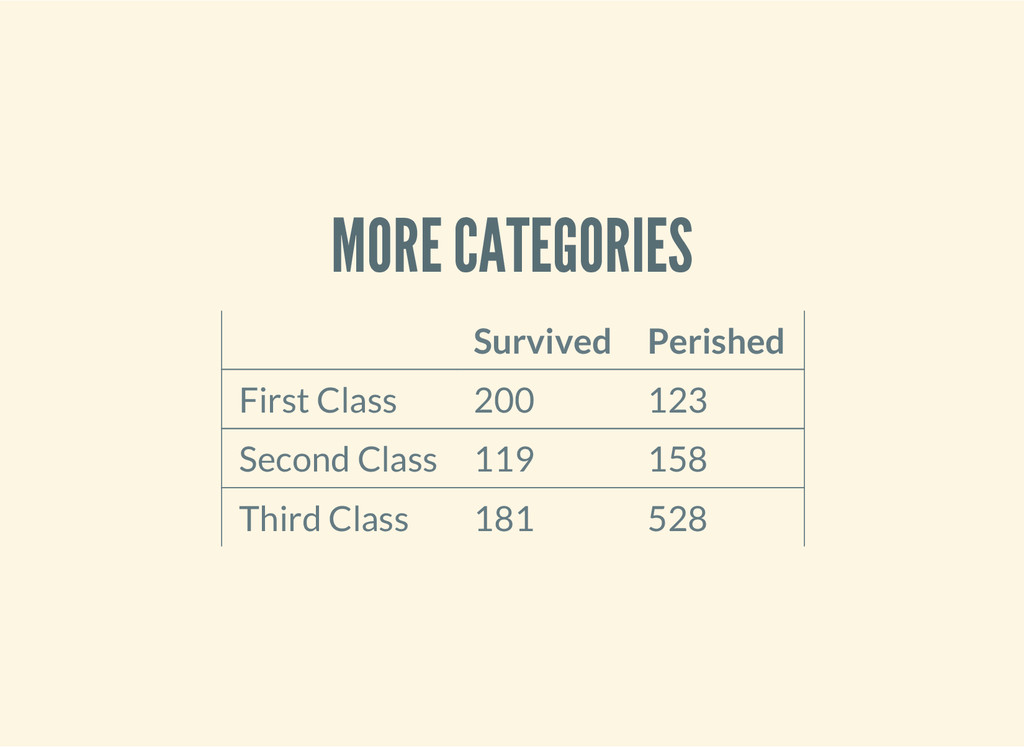
( d e f n e x - 5 - 5 [ ] ( l e t [ o b s e r v a t i o n s ( i / m a t r i x [ [ 2 0 0 1 1 9 1 8 1 ] [ 1 2 3 1 5 8 5 2 8 ] ] ) ] ( s / c h i s q - t e s t : t a b l e o b s e r v a t i o n s ) ) ) How likely is that this distribution occurred via chance? { : X - s q 1 2 7 . 8 5 9 1 5 6 4 3 9 3 0 3 2 6 , : c o l - l e v e l s ( 0 1 2 ) , : r o w - m a r g i n s { 0 5 0 0 . 0 , 1 8 0 9 . 0 } , : t a b l e [ m a t r i x ] , : p - v a l u e 1 . 7 2 0 8 2 5 9 5 8 8 2 5 6 1 7 5 E - 2 8 , : d f 2 , : p r o b s n i l , : c o l - m a r g i n s { 0 3 2 3 . 0 , 1 2 7 7 . 0 , 2 7 0 9 . 0 } , : E ( 1 2 3 . 3 7 6 6 2 3 3 7 6 6 2 3 3 7 1 9 9 . 6 2 3 3 7 6 6 2 3 3 7 6 6 3 1 0 5 . 8 0 5 9 5 8 7 4 7 1 3 5 2 2 1 7 1 . 1 9 4 0 4 1 2 5 2 8 6 4 8 2 7 0 . 8 1 7 4 1 7 8 7 6 2 4 1 4 4 3 8 . 1 8 2 5 8 2 1 2 3 7 5 8 6 ) , : r o w - l e v e l s ( 0 1 ) , : t w o - s a m p ? t r u e , : N 1 3 0 9 . 0 }
c - s a m p l e s ) ; ; = > ( { : s u r v i v e d t r u e , : g e n d e r : f e m a l e , : c l a s s : f i r s t , : e m b a r k e d " S " , : a g e " 2 0 - 3 0 " } { : s u r v i v e d t r u e , : g e n d e r : m a l e , : c l a s s : f i r s t , : e m b a r k e d " S " , : a g e " 3 0 - 4 0 " } . . . )
s a f e - i n c [ v ] ( i n c ( o r v 0 ) ) ) ( d e f n i n c - c l a s s - t o t a l [ m o d e l c l a s s ] ( u p d a t e - i n m o d e l [ c l a s s : t o t a l ] s a f e - i n c ) ) ( d e f n i n c - p r e d i c t o r s - c o u n t - f n [ r o w c l a s s ] ( f n [ m o d e l a t t r ] ( l e t [ v a l ( g e t r o w a t t r ) ] ( u p d a t e - i n m o d e l [ c l a s s a t t r v a l ] s a f e - i n c ) ) ) )
a s s o c - r o w - f n [ c l a s s - a t t r p r e d i c t o r s ] ( f n [ m o d e l r o w ] ( l e t [ c l a s s ( g e t r o w c l a s s - a t t r ) ] ( r e d u c e ( i n c - p r e d i c t o r s - c o u n t - f n r o w c l a s s ) ( i n c - c l a s s - t o t a l m o d e l c l a s s ) p r e d i c t o r s ) ) ) ) ( d e f n n a i v e - b a y e s [ d a t a c l a s s - a t t r p r e d i c t o r s ] ( r e d u c e ( a s s o c - r o w - f n c l a s s - a t t r p r e d i c t o r s ) { } d a t a ) )
- 5 - 6 [ ] ( l e t [ d a t a ( t i t a n i c - s a m p l e s ) ] ( p p r i n t ( n a i v e - b a y e s d a t a : s u r v i v e d [ : g e n d e r : c l a s s ] ) ) ) ) …produces the following output… ; ; { f a l s e ; ; { : c l a s s { : t h i r d 5 2 8 , : s e c o n d 1 5 8 , : f i r s t 1 2 3 } , ; ; : g e n d e r { : m a l e 6 8 2 , : f e m a l e 1 2 7 } , ; ; : t o t a l 8 0 9 } , ; ; t r u e ; ; { : c l a s s { : t h i r d 1 8 1 , : s e c o n d 1 1 9 , : f i r s t 1 9 8 } , ; ; : g e n d e r { : m a l e 1 6 1 , : f e m a l e 3 3 7 } , ; ; : t o t a l 4 9 8 } }
o d e l ] ( - > > ( v a l s m o d e l ) ( m a p : t o t a l ) ( a p p l y + ) ) ) ( d e f n c o n d i t i o n a l - p r o b a b i l i t y [ m o d e l t e s t c l a s s ] ( l e t [ e v i d e n c e ( g e t m o d e l c l a s s ) p r i o r ( / ( : t o t a l e v i d e n c e ) ( n m o d e l ) ) ] ( a p p l y * p r i o r ( f o r [ k v t e s t ] ( / ( g e t - i n e v i d e n c e k v ) ( : t o t a l e v i d e n c e ) ) ) ) ) ) ( d e f n b a y e s - c l a s s i f y [ m o d e l t e s t ] ( l e t [ p r o b s ( m a p ( f n [ c l a s s ] [ c l a s s ( c o n d i t i o n a l - p r o b a b i l i t y m o d e l t e s t c l a s s ) ] ) ( k e y s m o d e l ) ) ] ( - > ( s o r t - b y s e c o n d > p r o b s ) ( f f i r s t ) ) ) )
- 5 - 7 [ ] ( l e t [ d a t a ( t i t a n i c - s a m p l e s ) m o d e l ( n a i v e - b a y e s d a t a : s u r v i v e d [ : g e n d e r : c l a s s ] ) ] ( b a y e s - c l a s s i f y m o d e l { : g e n d e r : m a l e : c l a s s : t h i r d } ) ) ) ; ; = > f a l s e ( d e f n e x - 5 - 8 [ ] ( l e t [ d a t a ( t i t a n i c - s a m p l e s ) m o d e l ( n a i v e - b a y e s d a t a : s u r v i v e d [ : g e n d e r : c l a s s ] ) ] ( b a y e s - c l a s s i f y m o d e l { : g e n d e r : f e m a l e : c l a s s : f i r s t } ) ) ) ; ; = > t r u e
know they are not (e.g. being male and in third class) but naive bayes weights all attributes equally. In practice it works surprisingly well, particularly where there are large numbers of features.
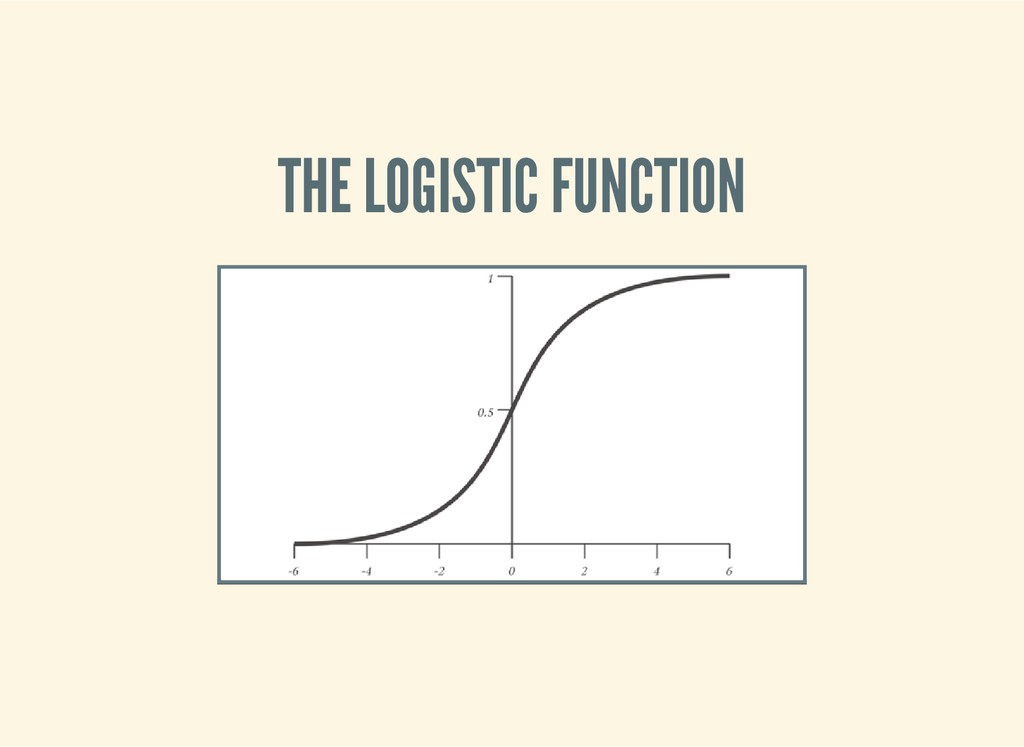
g i s t i c - f u n c t i o n [ t h e t a ] ( l e t [ t t ( m a t r i x / t r a n s p o s e ( v e c t h e t a ) ) z ( f n [ x ] ( - ( m a t r i x / m m u l t t ( v e c x ) ) ) ) ] ( f n [ x ] ( / 1 ( + 1 ( M a t h / e x p ( z x ) ) ) ) ) ) )
g i s t i c - f u n c t i o n [ 0 ] ) ] ( f [ 1 ] ) ; ; = > 0 . 5 ( f [ - 1 ] ) ; ; = > 0 . 5 ( f [ 4 2 ] ) ; ; = > 0 . 5 ) ( l e t [ f ( l o g i s t i c - f u n c t i o n [ 0 . 2 ] ) g ( l o g i s t i c - f u n c t i o n [ - 0 . 2 ] ) ] ( f [ 5 ] ) ; ; = > 0 . 7 3 ( g [ 5 ] ) ; ; = > 0 . 2 7 )
( d e f n c o s t - f u n c t i o n [ y y - h a t ] ( - ( i f ( z e r o ? y ) ( M a t h / l o g ( m a x ( - 1 y - h a t ) D o u b l e / M I N _ V A L U E ) ) ( M a t h / l o g ( m a x y - h a t ( D o u b l e / M I N _ V A L U E ) ) ) ) ) ) ( d e f n l o g i s t i c - c o s t [ y s y - h a t s ] ( a v g ( m a p c o s t - f u n c t i o n y s y - h a t s ) ) )
t i t a n i c - f e a t u r e s [ ] ( r e m o v e ( p a r t i a l s o m e n i l ? ) ( f o r [ r o w ( t i t a n i c - d a t a ) ] [ ( : s u r v i v e d r o w ) ( : p c l a s s r o w ) ( : s i b s p r o w ) ( : p a r c h r o w ) ( i f ( n i l ? ( : a g e r o w ) ) 3 0 ( : a g e r o w ) ) ( i f ( = ( : s e x r o w ) " f e m a l e " ) 1 . 0 0 . 0 ) ( i f ( = ( : e m b a r k e d r o w ) " S " ) 1 . 0 0 . 0 ) ( i f ( = ( : e m b a r k e d r o w ) " C " ) 1 . 0 0 . 0 ) ( i f ( = ( : e m b a r k e d r o w ) " Q " ) 1 . 0 0 . 0 ) ] ) ) )
a d i e n t - f n [ h - t h e t a x s y s ] ( l e t [ g ( f n [ x y ] ( m a t r i x / m m u l ( - ( h - t h e t a x ) y ) x ) ) ] ( - > > ( m a p g x s y s ) ( m a t r i x / t r a n s p o s e ) ( m a p a v g ) ) ) ) We transpose to calculate the average for each feature across all xs rather than average for each x across all features.
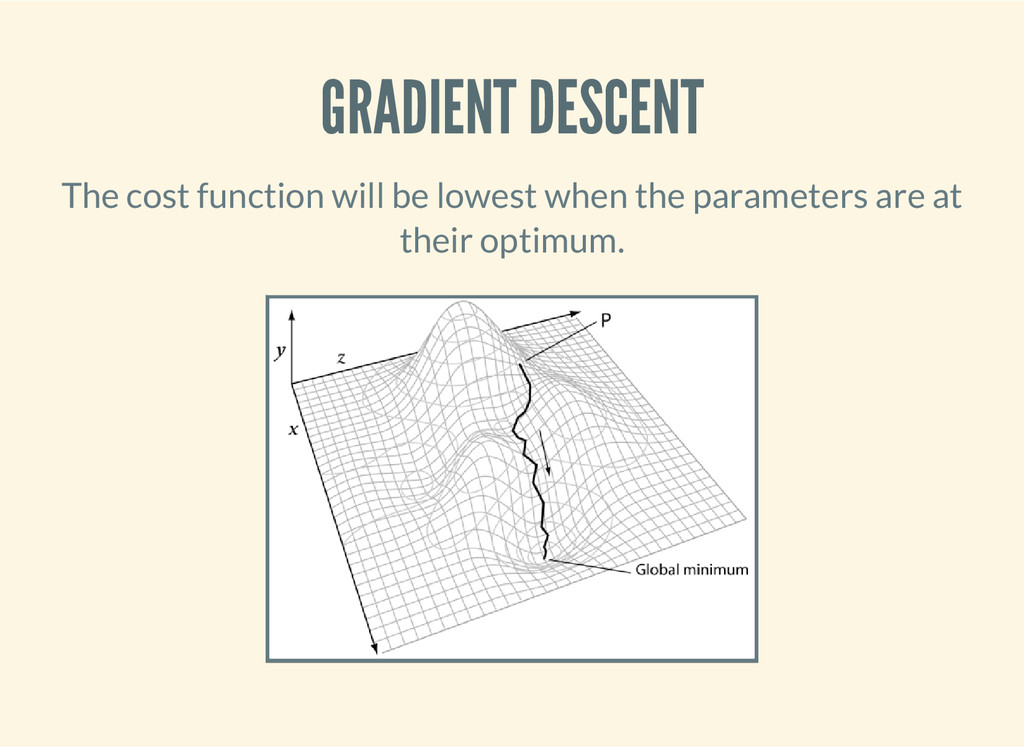
descent. ( : i m p o r t [ o r g . a p a c h e . c o m m o n s . m a t h 3 . a n a l y s i s M u l t i v a r i a t e F u n c t i o n M u l t i v a r i a t e V e c t o r F u n c t i o n ] [ o r g . a p a c h e . c o m m o n s . m a t h 3 . o p t i m I n i t i a l G u e s s M a x E v a l S i m p l e B o u n d s O p t i m i z a t i o n D a t a S i m p l e V a l u e C h e c k e r P o i n t V a l u e P a i r ] [ o r g . a p a c h e . c o m m o n s . m a t h 3 . o p t i m . n o n l i n e a r . s c a l a r O b j e c t i v e F u n c t i o n O b j e c t i v e F u n c t i o n G r a d i e n t G o a l T y p e ] [ o r g . a p a c h e . c o m m o n s . m a t h 3 . o p t i m . n o n l i n e a r . s c a l a r . g r a d i e n t N o n L i n e a r C o n j u g a t e G r a d i e n t O p t i m i z e r N o n L i n e a r C o n j u g a t e G r a d i e n t O p t i m i z e r $ F o r m u l a ] )
too many levels of indirection?! ( d e f n o b j e c t i v e - f u n c t i o n [ f ] ( O b j e c t i v e F u n c t i o n . ( r e i f y M u l t i v a r i a t e F u n c t i o n ( v a l u e [ _ v ] ( a p p l y f ( v e c v ) ) ) ) ) ) ( d e f n o b j e c t i v e - f u n c t i o n - g r a d i e n t [ f ] ( O b j e c t i v e F u n c t i o n G r a d i e n t . ( r e i f y M u l t i v a r i a t e V e c t o r F u n c t i o n ( v a l u e [ _ v ] ( d o u b l e - a r r a y ( a p p l y f ( v e c v ) ) ) ) ) ) )
e - n c g - o p t i m i z e r [ ] ( N o n L i n e a r C o n j u g a t e G r a d i e n t O p t i m i z e r . N o n L i n e a r C o n j u g a t e G r a d i e n t O p t i m i z e r $ F o r m u l a / F L E T C H E R _ R E E V E S ( S i m p l e V a l u e C h e c k e r . ( d o u b l e 1 e - 6 ) ( d o u b l e 1 e - 6 ) ) ) ) ( d e f n i n i t i a l - g u e s s [ g u e s s ] ( I n i t i a l G u e s s . ( d o u b l e - a r r a y g u e s s ) ) ) ( d e f n m a x - e v a l u a t i o n s [ n ] ( M a x E v a l . n ) ) ( d e f n g r a d i e n t - d e s c e n t [ f g e s t i m a t e n ] ( l e t [ o p t i o n s ( i n t o - a r r a y O p t i m i z a t i o n D a t a [ ( o b j e c t i v e - f u n c t i o n f ) ( o b j e c t i v e - f u n c t i o n - g r a d i e n t g ) ( i n i t i a l - g u e s s e s t i m a t e ) ( m a x - e v a l u a t i o n s n ) G o a l T y p e / M I N I M I Z E ] ) ] ( - > ( m a k e - n c g - o p t i m i z e r ) ( . o p t i m i z e o p t i o n s ) ( . g e t P o i n t ) ( v e c ) ) ) )
n - l o g i s t i c - r e g r e s s i o n [ d a t a i n i t i a l - g u e s s ] ( l e t [ p o i n t s ( t i t a n i c - f e a t u r e s ) x s ( - > > p o i n t s ( m a p r e s t ) ( m a p # ( c o n s 1 % ) ) ) y s ( m a p f i r s t p o i n t s ) ] ( g r a d i e n t - d e s c e n t ( f n [ & t h e t a ] ( l e t [ f ( l o g i s t i c - f u n c t i o n t h e t a ) ] ( l o g i s t i c - c o s t ( m a p f x s ) y s ) ) ) ( f n [ & t h e t a ] ( g r a d i e n t - f n ( l o g i s t i c - f u n c t i o n t h e t a ) x s y s ) ) i n i t i a l - g u e s s 2 0 0 0 ) ) )
- 5 - 1 1 [ ] ( l e t [ d a t a ( t i t a n i c - f e a t u r e s ) i n i t i a l - g u e s s ( - > d a t a f i r s t c o u n t ( t a k e ( r e p e a t e d l y r a n d ) ) ) ] ( r u n - l o g i s t i c - r e g r e s s i o n d a t a i n i t i a l - g u e s s ) ) )
a [ 0 . 6 9 0 8 0 7 8 2 4 6 2 3 4 0 4 - 0 . 9 0 3 3 8 2 8 0 0 1 3 6 9 4 3 5 - 0 . 3 1 1 4 3 7 5 2 7 8 6 9 8 7 6 6 - 0 . 0 1 8 9 4 3 1 9 6 7 3 2 8 7 2 1 9 - 0 . 0 3 1 0 0 3 1 5 5 7 9 7 6 8 6 6 1 2 . 5 8 9 4 8 5 8 3 6 6 0 3 3 2 7 3 0 . 7 9 3 9 1 9 0 7 0 8 1 9 3 3 7 4 1 . 3 7 1 1 3 3 4 8 8 7 9 4 7 3 8 8 0 . 6 6 7 2 5 5 5 2 5 7 8 2 8 9 1 9 ] ) ( d e f n r o u n d [ x ] ( M a t h / r o u n d x ) ) ( d e f l o g i s t i c - m o d e l ( l o g i s t i c - f u n c t i o n t h e t a ) ) ( d e f n e x - 5 - 1 3 [ ] ( l e t [ d a t a ( t i t a n i c - f e a t u r e s ) t e s t ( f n [ x ] ( = ( r o u n d ( l o g i s t i c - m o d e l ( c o n s 1 ( r e s t x ) ) ) ) ( r o u n d ( f i r s t x ) ) ) ) r e s u l t s ( f r e q u e n c i e s ( m a p t e s t d a t a ) ) ] ( / ( g e t r e s u l t s t r u e ) ( a p p l y + ( v a l s r e s u l t s ) ) ) ) ) ; ; = > 1 0 3 0 / 1 3 0 9
∥ ( d e f n c o s i n e [ a b ] ( l e t [ d o t - p r o d u c t ( - > > ( m a p * a b ) ( a p p l y + ) ) m a g n i t u d e ( f n [ d ] ( - > > ( m a p # ( M a t h / p o w % 2 ) d ) ( a p p l y + ) M a t h / s q r t ) ) ] ( / d o t - p r o d u c t ( * ( m a g n i t u d e a ) ( m a g n i t u d e b ) ) ) ) )
t i o n a r y ( a t o m { : c o u n t 0 : w o r d s { } } ) ) ( d e f n a d d - w o r d - t o - d i c t [ d i c t w o r d ] ( i f ( g e t - i n d i c t [ : w o r d s w o r d ] ) d i c t ( - > d i c t ( u p d a t e - i n [ : w o r d s ] a s s o c w o r d ( g e t d i c t : c o u n t ) ) ( u p d a t e - i n [ : c o u n t ] i n c ) ) ) ) ( d e f n u p d a t e - w o r d s [ d i c t d o c w o r d ] ( l e t [ w o r d - i d ( - > ( s w a p ! d i c t a d d - w o r d - t o - d i c t w o r d ) ( g e t - i n [ : w o r d s w o r d ] ) ) ] ( u p d a t e - i n d o c [ w o r d - i d ] # ( i n c ( o r % 0 ) ) ) ) ) ( d e f n d o c u m e n t - v e c t o r [ d i c t n g r a m s ] ( r / r e d u c e ( p a r t i a l u p d a t e - w o r d s d i c t ) { } n g r a m s ) )
t " t h e q u i c k b r o w n f o x j u m p s o v e r t h e l a z y d o g " # " \ W + " ) ( d o c u m e n t - v e c t o r d i c t i o n a r y ) ) ; ; = > { 7 1 , 6 1 , 5 1 , 4 1 , 3 1 , 2 1 , 1 1 , 0 2 } @ d i c t i o n a r y ; ; = > { : w o r d s { " d o g " 7 , " l a z y " 6 , " o v e r " 5 , " j u m p s " 4 , " f o x " 3 , " b r o w n " 2 , " q u i c k " 1 , " t h e " 0 } , : c o u n t 8 }
p a r s e ( - > > " m u s i c i s t h e f o o d o f l o v e " s t e m m e r / s t e m s ( d o c u m e n t - v e c t o r d i c t i o n a r y ) ) ( - > > " w a r i s t h e l o c o m o t i v e o f h i s t o r y " s t e m m e r / s t e m s ( d o c u m e n t - v e c t o r d i c t i o n a r y ) ) ) ; ; = > 0 . 0 ( c o s i n e - s p a r s e ( - > > " m u s i c i s t h e f o o d o f l o v e " s t e m m e r / s t e m s ( d o c u m e n t - v e c t o r d i c t i o n a r y ) ) ( - > > " i t ' s l o v e l y t h a t y o u ' r e m u s i c a l " s t e m m e r / s t e m s ( d o c u m e n t - v e c t o r d i c t i o n a r y ) ) ) ; ; = > 0 . 8 1 6 4 9 6 5 8 0 9 2 7 7 2 5 9
l o v e l y t h a t y o u ' r e m u s i c a l " s t e m m e r / s t e m s ( d o c u m e n t - v e c t o r d i c t i o n a r y ) ) ; ; = > { 0 1 , 2 1 } @ d i c t i o n a r y ; ; = > { : c o u n t 6 , : w o r d s { " h i s t o r i " 5 , " l o c o m o t " 4 , " w a r " 3 , " l o v e " 2 , " f o o d " 1 , " m u s i c " 0 } }
dataset. Follow the readme instructions: b r e w i n s t a l l m a h o u t s c r i p t / d o w n l o a d - r e u t e r s . s h l e i n r u n - e 6 . 7 m a h o u t s e q d i r e c t o r y - i d a t a / r e u t e r s - t x t - o d a t a / r e u t e r s - s e q u e n c e f i l e
' [ c l o j u r e . c o r e . r e d u c e r s : a s r ] ' [ p a r k o u r . m a p r e d u c e : a s m r ] ) ( d e f n d o c u m e n t - > t e r m s [ d o c ] ( c l o j u r e . s t r i n g / s p l i t d o c # " \ W + " ) ) ( d e f n d o c u m e n t - c o u n t - m " E m i t s t h e u n i q u e w o r d s f r o m e a c h d o c u m e n t " { : : m r / s o u r c e - a s : v a l s } [ d o c u m e n t s ] ( - > > d o c u m e n t s ( r / m a p c a t ( c o m p d i s t i n c t d o c u m e n t - > t e r m s ) ) ( r / m a p # ( v e c t o r % 1 ) ) ) )
; ; R e - s h a p e a s v e c t o r s o f k e y - v a l s p a i r s . : k e y s ; ; J u s t t h e k e y s f r o m e a c h k e y - v a l u e p a i r . : v a l s ; ; J u s t t h e v a l u e s f r o m e a c h k e y - v a l u e p a i r .
c u m e n t - c o u n t - m [ " i t ' s l o v e l y t h a t y o u ' r e m u s i c a l " " m u s i c i s t h e f o o d o f l o v e " " w a r i s t h e l o c o m o t i v e o f h i s t o r y " ] ) ( i n t o [ ] ) ) ; ; = > [ [ " l o v e " 1 ] [ " m u s i c " 1 ] [ " m u s i c " 1 ] [ " f o o d " 1 ] [ " l o v e " 1 ] [ " w a r " 1 ] [ " l o c o m o t " 1 ] [ " h i s t o r i " 1 ] ]
' [ p a r k o u r . i o . d u x : a s d u x ] ' [ t r a n s d u c e . r e d u c e r s : a s t r ] ) ( d e f n u n i q u e - i n d e x - r { : : m r / s o u r c e - a s : k e y v a l g r o u p s , : : m r / s i n k - a s d u x / n a m e d - k e y v a l s } [ c o l l ] ( l e t [ g l o b a l - o f f s e t ( c o n f / g e t - l o n g m r / * c o n t e x t * " m a p r e d . t a s k . p a r t i t i o n " - 1 ) ] ( t r / m a p c a t - s t a t e ( f n [ l o c a l - o f f s e t [ w o r d c o u n t s ] ] [ ( i n c l o c a l - o f f s e t ) ( i f ( i d e n t i c a l ? : : f i n i s h e d w o r d ) [ [ : c o u n t s [ g l o b a l - o f f s e t l o c a l - o f f s e t ] ] ] [ [ : d a t a [ w o r d [ [ g l o b a l - o f f s e t l o c a l - o f f s e t ] ( a p p l y + c o u n t s ) ] ] ] ] ) ] ) 0 ( r / m a p c a t i d e n t i t y [ c o l l [ [ : : f i n i s h e d n i l ] ] ] ) ) ) )
e ' [ p a r k o u r . g r a p h : a s p g ] ' [ p a r k o u r . a v r o : a s m r a ] ' [ a b r a c a d . a v r o : a s a v r o ] ) ( d e f l o n g - p a i r ( a v r o / t u p l e - s c h e m a [ : l o n g : l o n g ] ) ) ( d e f i n d e x - v a l u e ( a v r o / t u p l e - s c h e m a [ l o n g - p a i r : l o n g ] ) ) ( d e f n d f - j [ d s e q ] ( - > ( p g / i n p u t d s e q ) ( p g / m a p # ' d o c u m e n t - c o u n t - m ) ( p g / p a r t i t i o n ( m r a / s h u f f l e [ : s t r i n g : l o n g ] ) ) ( p g / r e d u c e # ' u n i q u e - i n d e x - r ) ( p g / o u t p u t : d a t a ( m r a / d s i n k [ : s t r i n g i n d e x - v a l u e ] ) : c o u n t s ( m r a / d s i n k [ : l o n g : l o n g ] ) ) ) )
r e ' [ p a r k o u r . i o . d v a l : a s d v a l ] ) ( d e f n c a l c u l a t e - o f f s e t s " B u i l d m a p o f o f f s e t s f r o m d s e q o f c o u n t s . " [ d s e q ] ( - > > d s e q ( i n t o [ ] ) ( s o r t - b y f i r s t ) ( r e d u c t i o n s ( f n [ [ _ t ] [ i n ] ] [ ( i n c i ) ( + t n ) ] ) [ 0 0 ] ) ( i n t o { } ) ) ) ( d e f n d f - e x e c u t e [ c o n f d s e q ] ( l e t [ [ d f - d a t a d f - c o u n t s ] ( p g / e x e c u t e ( d f - j d s e q ) c o n f ` d f ) o f f s e t s - d v a l ( d v a l / e d n - d v a l ( c a l c u l a t e - o f f s e t s d f - c o u n t s ) ) ] . . . ) )
l o b a l - i d " U s e o f f s e t s t o c a l c u l a t e u n i q u e i d f r o m g l o b a l a n d l o c a l o f f s e t " [ o f f s e t s [ g l o b a l - o f f s e t l o c a l - o f f s e t ] ] ( + l o c a l - o f f s e t ( g e t o f f s e t s g l o b a l - o f f s e t ) ) ) ( d e f n w o r d s - i d f - m " C a l c u l a t e t h e u n i q u e i d a n d i n v e r s e d o c u m e n t f r e q u e n c y f o r e a c h w o r d " { : : m r / s i n k - a s : k e y s } [ o f f s e t s - d v a l n c o l l ] ( l e t [ o f f s e t s @ o f f s e t s - d v a l ] ( r / m a p ( f n [ [ w o r d [ w o r d - o f f s e t d f ] ] ] [ w o r d ( g l o b a l - i d o f f s e t s w o r d - o f f s e t ) ( M a t h / l o g ( / n d f ) ) ] ) c o l l ) ) ) ( d e f n m a k e - d i c t i o n a r y [ c o n f d f - d a t a d f - c o u n t s d o c - c o u n t ] ( l e t [ o f f s e t s - d v a l ( d v a l / e d n - d v a l ( c a l c u l a t e - o f f s e t s d f - c o u n t s ) ) ] ( - > ( p g / i n p u t d f - d a t a ) ( p g / m a p # ' w o r d s - i d f - m o f f s e t s - d v a l d o c - c o u n t ) ( p g / o u t p u t ( m r a / d s i n k [ w o r d s ] ) ) ( p g / f e x e c u t e c o n f ` i d f ) ( - > > ( r / m a p p a r s e - i d f ) ( i n t o { } ) ) ( d v a l / e d n - d v a l ) ) ) )
' [ o r g . a p a c h e . m a h o u t . m a t h R a n d o m A c c e s s S p a r s e V e c t o r ] ) ( d e f n c r e a t e - s p a r s e - v e c t o r [ d i c t i o n a r y [ i d d o c ] ] ( l e t [ v e c t o r ( R a n d o m A c c e s s S p a r s e V e c t o r . ( c o u n t d i c t i o n a r y ) ) ] ( d o s e q [ [ t e r m f r e q ] ( - > d o c d o c u m e n t - > t e r m s f r e q u e n c i e s ) ] ( l e t [ t e r m - i n f o ( g e t d i c t i o n a r y t e r m ) ] ( . s e t Q u i c k v e c t o r ( : i d t e r m - i n f o ) ( * f r e q ( : i d f t e r m - i n f o ) ) ) ) ) [ i d v e c t o r ] ) ) ( d e f n c r e a t e - v e c t o r s - m [ d i c t i o n a r y c o l l ] ( l e t [ d i c t i o n a r y @ d i c t i o n a r y ] ( r / m a p # ( c r e a t e - s p a r s e - v e c t o r d i c t i o n a r y % ) c o l l ) ) )
' [ o r g . a p a c h e . h a d o o p . i o T e x t ] ' [ o r g . a p a c h e . m a h o u t . m a t h V e c t o r W r i t a b l e ] ) ( d e f n t f i d f [ c o n f d s e q d i c t i o n a r y - p a t h v e c t o r - p a t h ] ( l e t [ d o c - c o u n t ( - > > d s e q ( i n t o [ ] ) c o u n t ) [ d f - d a t a d f - c o u n t s ] ( p g / e x e c u t e ( d f - j d s e q ) c o n f ` d f ) d i c t i o n a r y - d v a l ( m a k e - d i c t i o n a r y c o n f d f - d a t a d f - c o u n t s d o c - c o u n t ) ] ( w r i t e - d i c t i o n a r y d i c t i o n a r y - p a t h d i c t i o n a r y - d v a l ) ( - > ( p g / i n p u t d s e q ) ( p g / m a p # ' c r e a t e - v e c t o r s - m d i c t i o n a r y - d v a l ) ( p g / o u t p u t ( s e q f / d s i n k [ T e x t V e c t o r W r i t a b l e ] v e c t o r - p a t h ) ) ( p g / f e x e c u t e c o n f ` v e c t o r i z e ) ) ) ) ( d e f n t o o l [ c o n f i n p u t o u t p u t ] ( l e t [ d s e q ( s e q f / d s e q i n p u t ) d i c t i o n a r y - p a t h ( d o t o ( s t r o u t p u t " / d i c t i o n a r y " ) f s / p a t h - d e l e t e ) v e c t o r - p a t h ( d o t o ( s t r o u t p u t " / v e c t o r s " ) f s / p a t h - d e l e t e ) ] ( t f i d f c o n f d s e q d i c t i o n a r y - p a t h v e c t o r - p a t h ) ) ) ( d e f n - m a i n [ & a r g s ] ( S y s t e m / e x i t ( t o o l / r u n t o o l a r g s ) ) )
- 6 - 1 4 [ ] ( l e t [ i n p u t " d a t a / r e u t e r s - s e q u e n c e f i l e " o u t p u t " d a t a / p a r k o u r - v e c t o r s " ] ( t o o l / r u n v e c t o r i z e r / t o o l [ i n p u t o u t p u t ] ) ) )
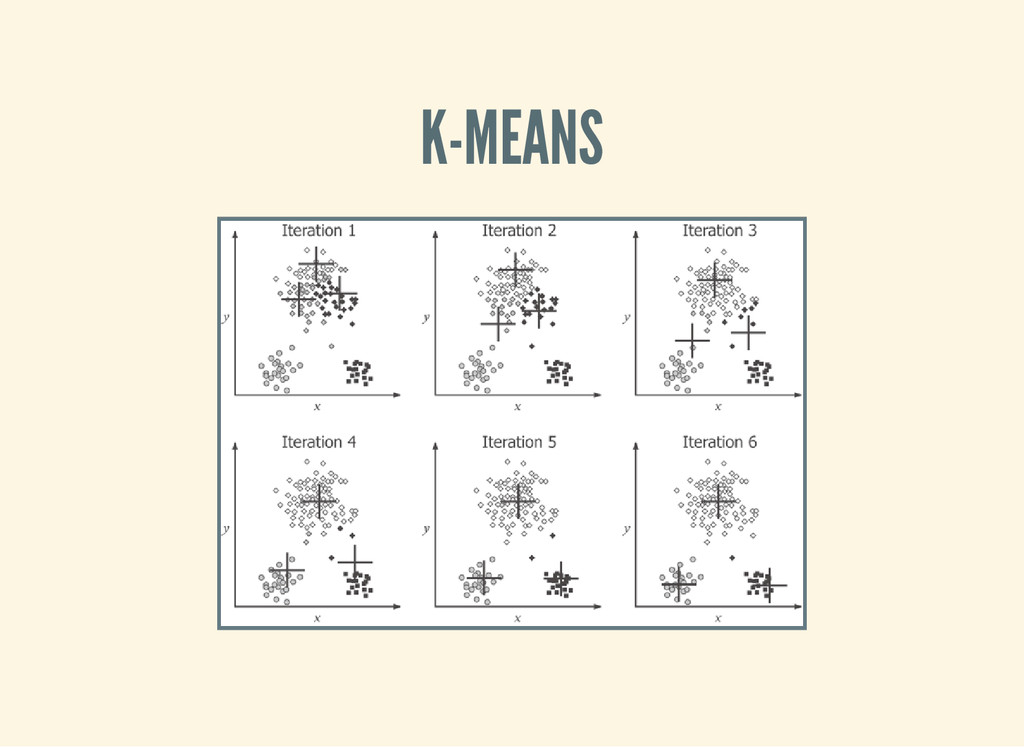
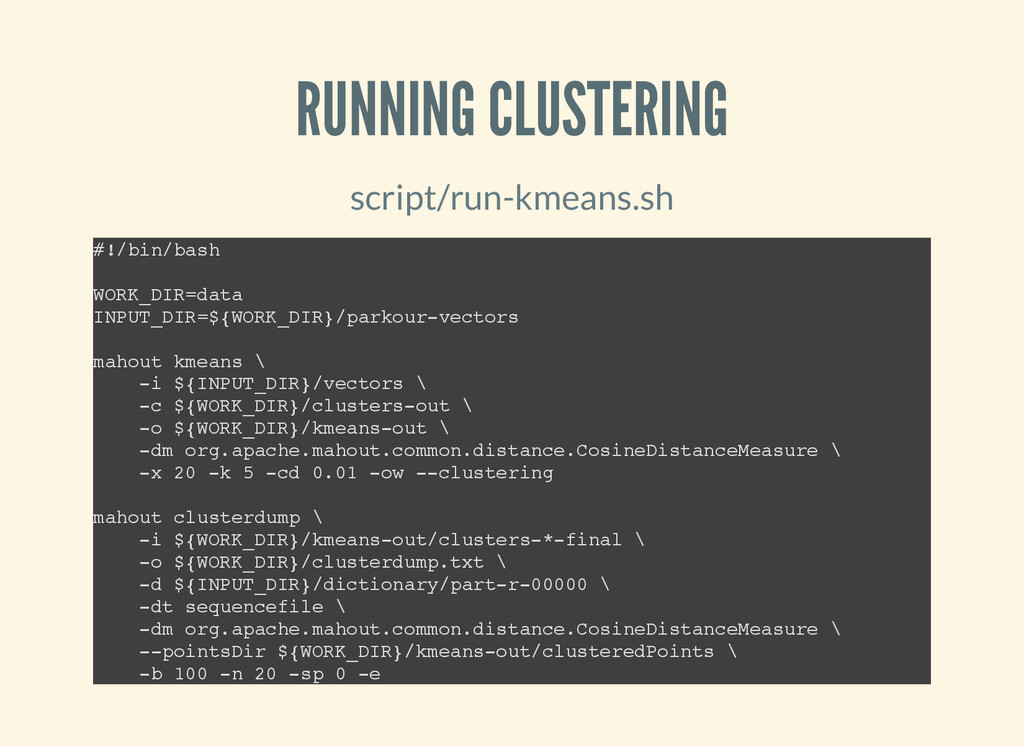
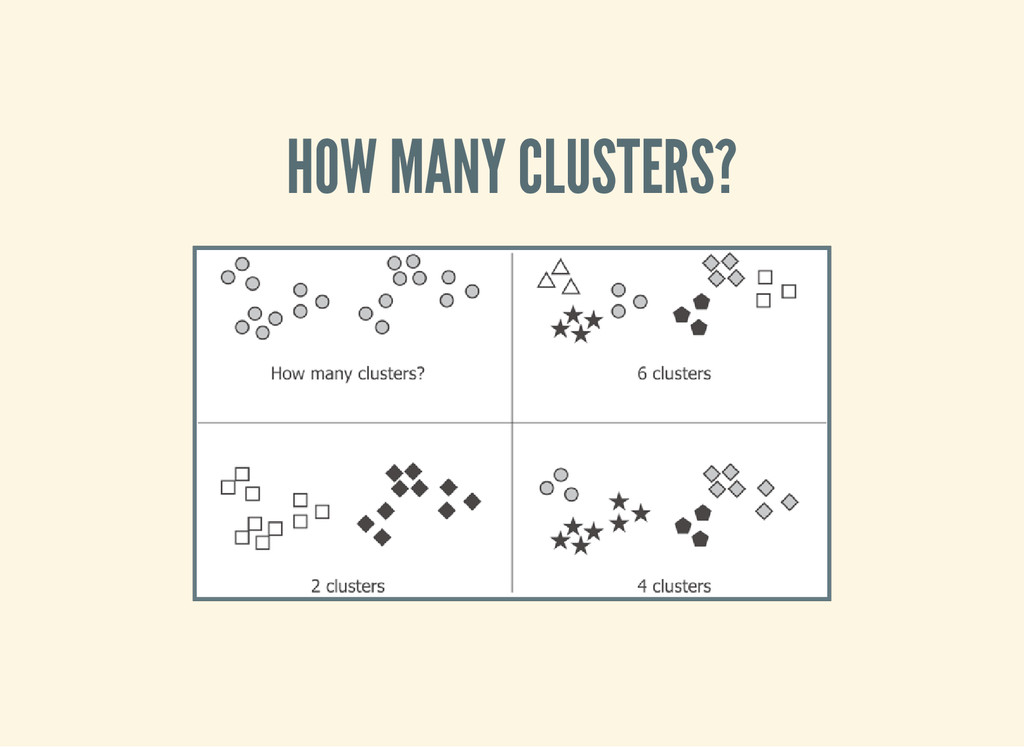
b a s h W O R K _ D I R = d a t a I N P U T _ D I R = $ { W O R K _ D I R } / p a r k o u r - v e c t o r s m a h o u t k m e a n s \ - i $ { I N P U T _ D I R } / v e c t o r s \ - c $ { W O R K _ D I R } / c l u s t e r s - o u t \ - o $ { W O R K _ D I R } / k m e a n s - o u t \ - d m o r g . a p a c h e . m a h o u t . c o m m o n . d i s t a n c e . C o s i n e D i s t a n c e M e a s u r e \ - x 2 0 - k 5 - c d 0 . 0 1 - o w - - c l u s t e r i n g m a h o u t c l u s t e r d u m p \ - i $ { W O R K _ D I R } / k m e a n s - o u t / c l u s t e r s - * - f i n a l \ - o $ { W O R K _ D I R } / c l u s t e r d u m p . t x t \ - d $ { I N P U T _ D I R } / d i c t i o n a r y / p a r t - r - 0 0 0 0 0 \ - d t s e q u e n c e f i l e \ - d m o r g . a p a c h e . m a h o u t . c o m m o n . d i s t a n c e . C o s i n e D i s t a n c e M e a s u r e \ - - p o i n t s D i r $ { W O R K _ D I R } / k m e a n s - o u t / c l u s t e r e d P o i n t s \ - b 1 0 0 - n 2 0 - s p 0 - e
LDA clustering Collaborative filtering with Mahout Random forests Spark for movie recommendations with Sparkling Graph data with Loom and Datomic MapReduce with Cascalog and PigPen Adapting algorithms for massive scale Time series and forecasting Dimensionality reduction, feature selection More visualisation techniques Lots more…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
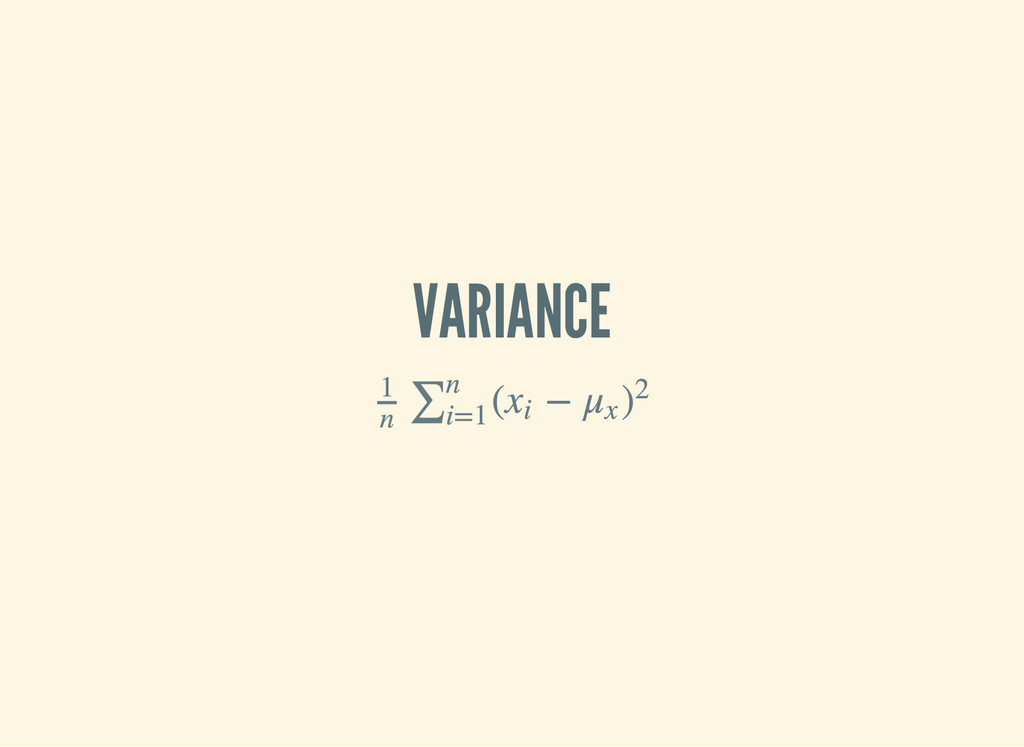{kind=link}
{kind=link}
{kind=link}
![DISTIBUTIONS AS MODELS [PDF] http://cljds.com/matura-2013](https://files.speakerdeck.com/presentations/324a4d25b6d541dbadd9e0fb14dc1a51/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
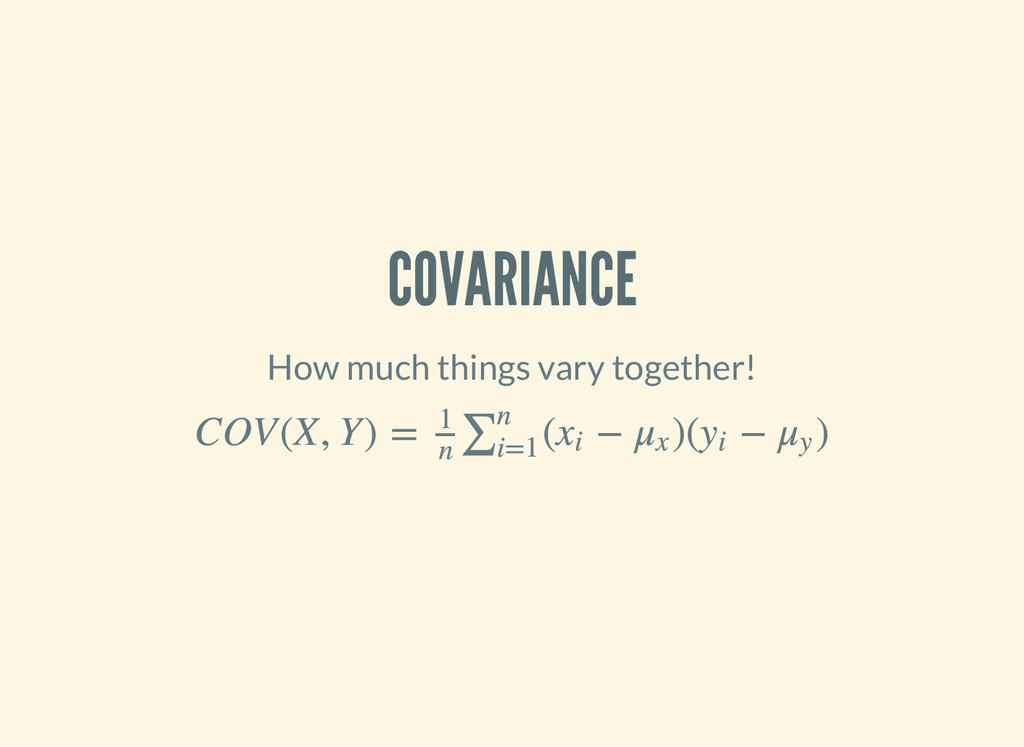{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
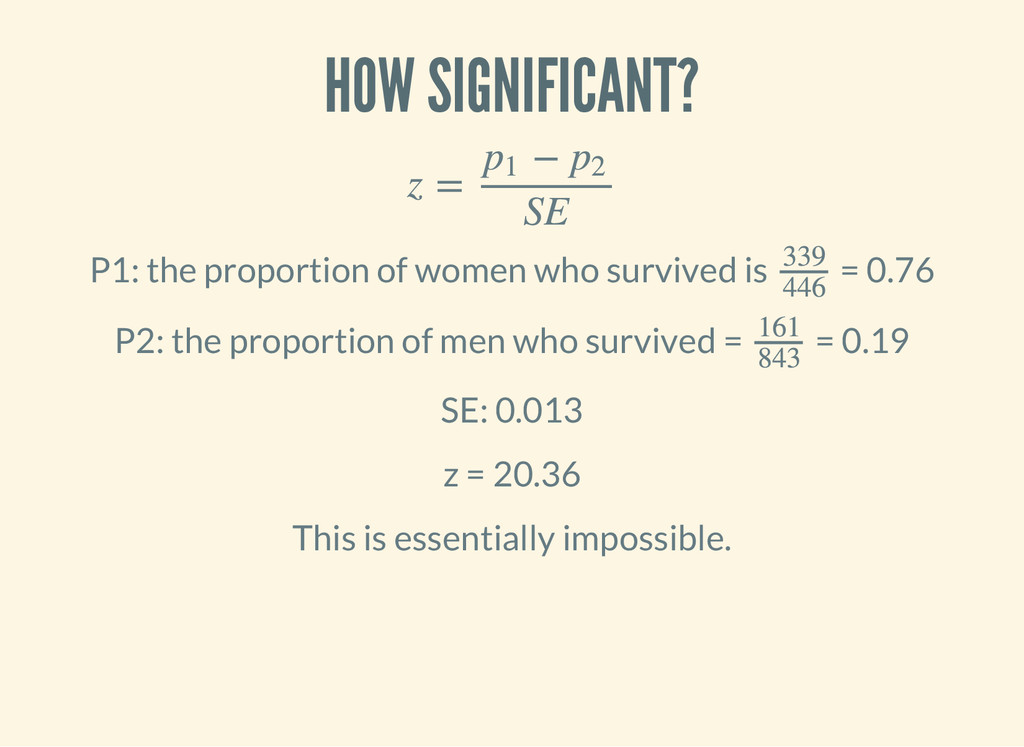{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}