First tried it 5 years ago • Didn’t like it ($GOPATH WTF!?) • Came back 2 years ago • Loved it (Go modules YES!) ◦ Great CLI tools ◦ One big compiled bundle, no system dependencies ◦ You can use it as a script too: go run script.go ◦ Reproducible builds: great for security! ◦ Truly simple programming concepts: very productive, very readable ◦ Goroutines
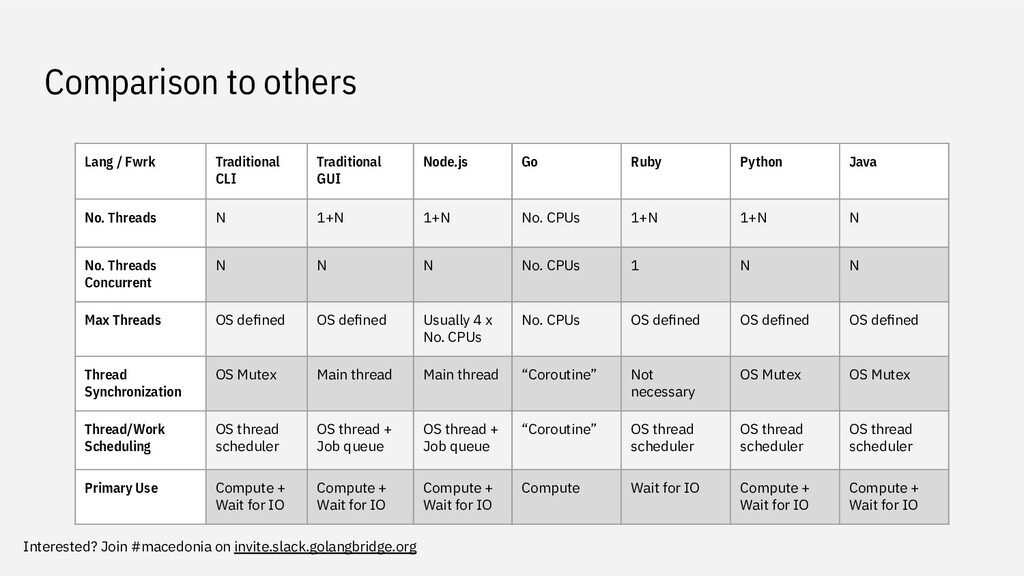
Fwrk Traditional CLI Traditional GUI Node.js Go Ruby Python Java No. Threads N 1+N 1+N No. CPUs 1+N 1+N N No. Threads Concurrent N N N No. CPUs 1 N N Max Threads OS defined OS defined Usually 4 x No. CPUs No. CPUs OS defined OS defined OS defined Thread Synchronization OS Mutex Main thread Main thread “Coroutine” Not necessary OS Mutex OS Mutex Thread/Work Scheduling OS thread scheduler OS thread + Job queue OS thread + Job queue “Coroutine” OS thread scheduler OS thread scheduler OS thread scheduler Primary Use Compute + Wait for IO Compute + Wait for IO Compute + Wait for IO Compute Wait for IO Compute + Wait for IO Compute + Wait for IO
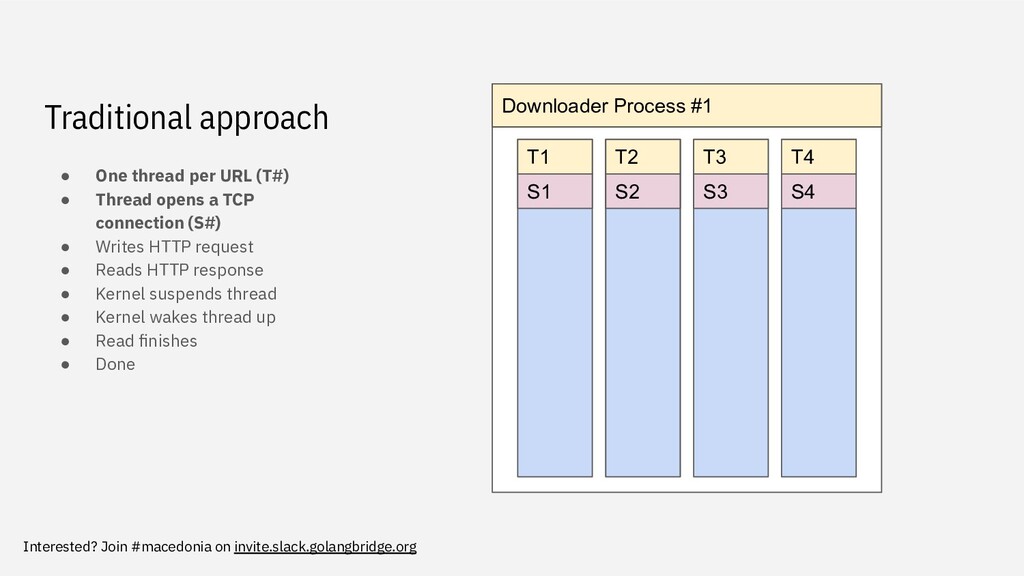
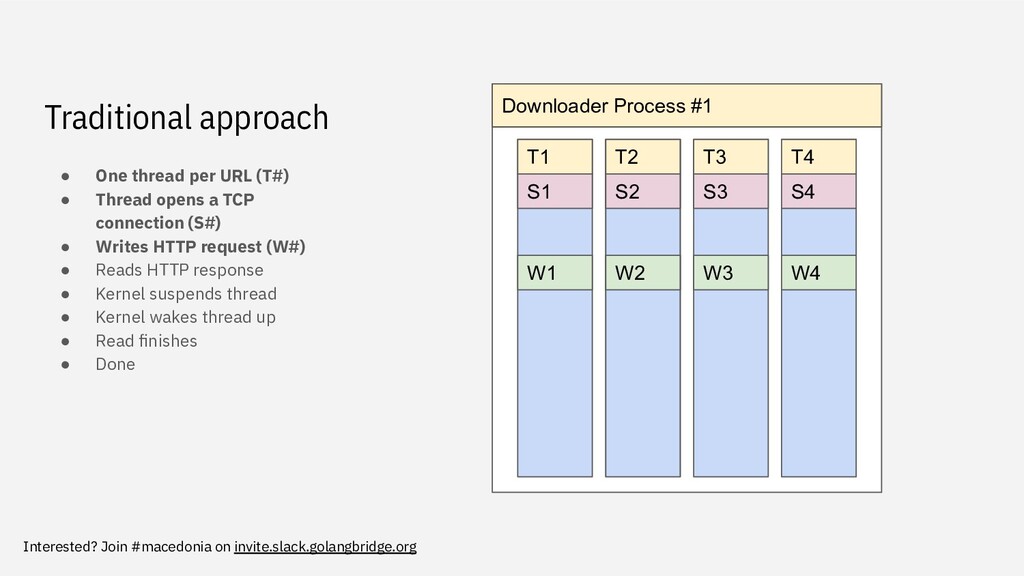
high overhead ◦ It has its own stack memory (default 8MB) ◦ Has a smaller context than processes, but still not insignificant • These threads do very little work (OS is waiting for data on the socket to arrive) ◦ Useless reserved memory Downloader Process #1 T1 T2 T3 T4 S1 S2 S3 S4 W1 W2 W3 W4 R1 R2 R3 R4 KERNEL KERNEL KERNEL KERNEL R1 R2 R3 R4
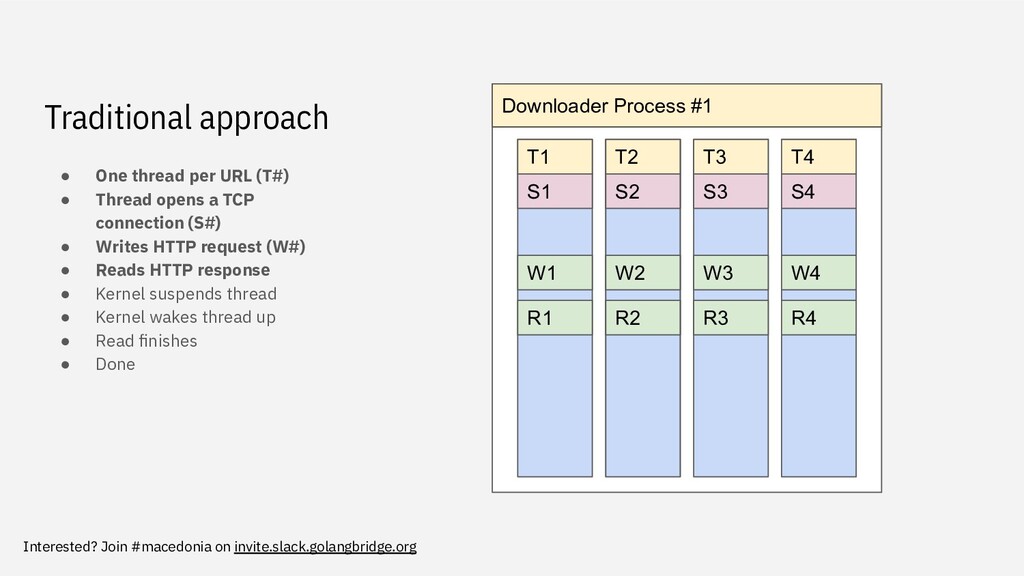
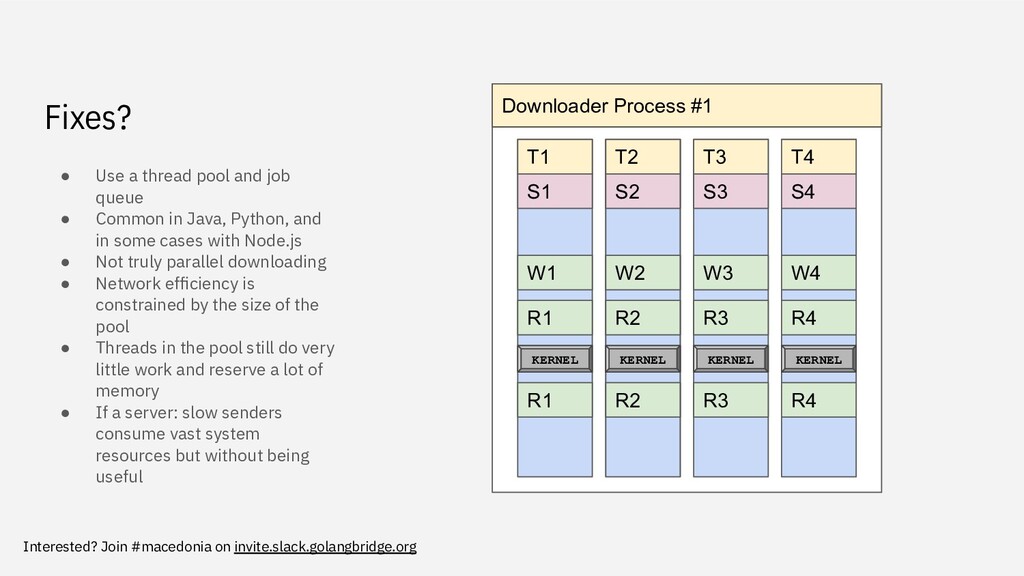
pool and job queue • Common in Java, Python, and in some cases with Node.js • Not truly parallel downloading • Network efficiency is constrained by the size of the pool • Threads in the pool still do very little work and reserve a lot of memory • If a server: slow senders consume vast system resources but without being useful Downloader Process #1 T1 T2 T3 T4 S1 S2 S3 S4 W1 W2 W3 W4 R1 R2 R3 R4 KERNEL KERNEL KERNEL KERNEL R1 R2 R3 R4
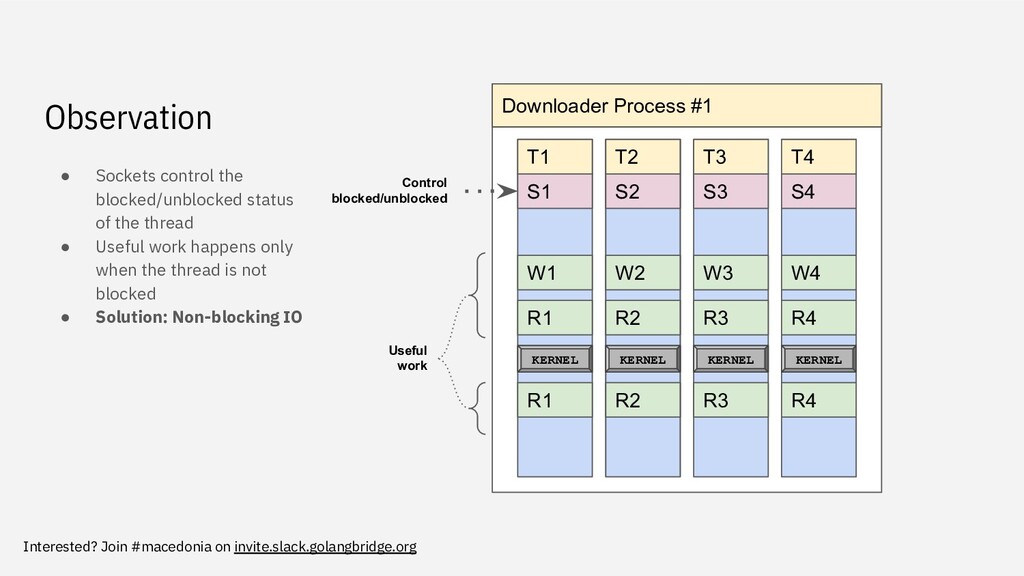
blocked/unblocked status of the thread • Useful work happens only when the thread is not blocked • Solution: Non-blocking IO Downloader Process #1 T1 T2 T3 T4 S1 S2 S3 S4 W1 W2 W3 W4 R1 R2 R3 R4 KERNEL KERNEL KERNEL KERNEL R1 R2 R3 R4 Control blocked/unblocked Useful work
(syscall) as blocking IO (connect, read, write, …) • O_NONBLOCK option when creating • read() and write() return EWOULDBLOCK or EAGAIN • Example: Use number of CPU (2) threads: ◦ 2 sockets per thread ◦ Read in a busy loop for each socket while EWOULDBLOCK ◦ Not truly parallel (1 always must complete before 3) ◦ Less useless memory ◦ Busy loop is a problem Downloader Process #1 T1 T2 S1 S2 W1 W2 R1 R2 S3 S4 W3 W4 R3 R4
• poll() and select() syscalls ◦ poll() is newer ◦ select() is older ◦ Pass multiple File Descriptors you want to read() on ◦ Linux wakes up your thread when one or more are ready for read()-ing (“event”) • True parallelism, no busy-loop, no useless memory • Issue: every poll() sends all file descriptors every time ◦ Thousands or hundreds of thousands are an issue ◦ 132K file descriptors (normal for server) are about 1MB per call • Solution ◦ In Linux epoll() ◦ In BSD/Darwin kqueue() ◦ List of FD is managed in-kernel Downloader Process #1 T1 T2 S1 S2 W1 W2 poll(R, S1, S3) S3 S4 W3 W4 R3 poll(R, S2, S4) R1 R2 R4 KERNEL
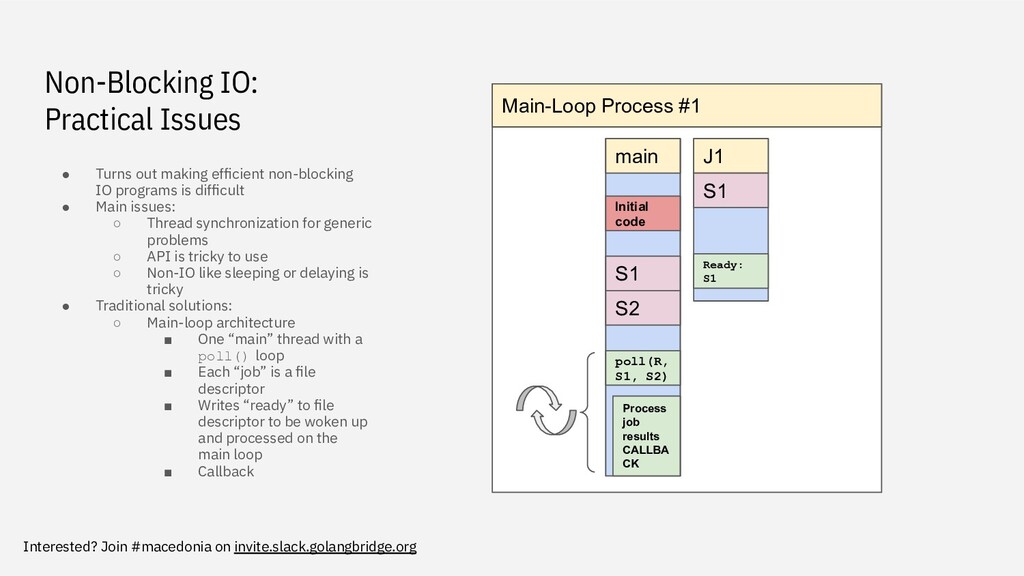
Turns out making efficient non-blocking IO programs is difficult • Main issues: ◦ Thread synchronization for generic problems ◦ API is tricky to use ◦ Non-IO like sleeping or delaying is tricky • Traditional solutions: ◦ Main-loop architecture ▪ One “main” thread with a poll() loop ▪ Each “job” is a file descriptor ▪ Writes “ready” to file descriptor to be woken up and processed on the main loop ▪ Callback Main-Loop Process #1 main J1 S1 S1 poll(R, S1, S2) S2 Process job results CALLBA CK Ready: S1 Initial code
Turns out making efficient non-blocking IO programs is difficult • Main issues: ◦ Thread synchronization for generic problems ◦ API is tricky to use ◦ Non-IO like sleeping or delaying is tricky • Traditional solutions: ◦ Main-loop architecture ▪ One “main” thread with a poll() loop ▪ Each “job” is a file descriptor ▪ Writes “ready” to file descriptor to be woken up and processed on the main loop ▪ Callback callbacks := map[Socket]func(){ “S1”: func(event ...) { // do something }, “S2”: func(event ...) { newSocket := socket() callbacks[newSocket] = func() { // do something } delete callbacks[event.Socket] } } // initial code for { events := poll(<keys in callbacks>) for _, event := range events { callbacks[event.Socket](event) } } Main-Loop Process #1
runtime is essentially a multiple main-loop engine ◦ There are as many threads and main-loops as there are number of CPUs • Go intercepts all IO calls like read() and write() in a function ◦ Saves the function state up to that moment ◦ Adds the socket’s file descriptor to the callbacks map ◦ When the event occurs, it restores the function state and resumes execution • Go’s language and compiler makes functions easy to save and continue • Optimizations: ◦ All threads have the same loop ◦ Uses Edge-Triggered events to wake up only one thread per file descriptor, even though all are listening type SavedFn struct{} func (fn SavedFn) Continue() (Socket, SavedFn) { // do the work // return next socket and current saved state } callbacks := make(map[Socket]SavedFn) // initial code // in each Go thread for { events := poll(<keys in callbacks>) for _, ev := range events { ns, nf := callbacks[ev.Socket].Continue() callbacks[ns] = nf } } Go Process #1
B IO C C C C A A A A A GO A D IO E Bringing it Together: Illustrated • Program is split up in 5 sections: ◦ A: initial code ◦ B: reading the response ◦ C: after reading the response ◦ D: waiting for all goroutines to finish ◦ E: terminate the program • Using go only tells Go to poll the socket (C) of each call of the download function after the current loop has finished • Otherwise, it would have saved main immediately and run poll() right after func download(wg *sync.WaitGroup, url string) { defer wg.Done() resp, err := http.Get(url) if nil != err { panic(err) } body, err := ioutil.ReadAll(resp.Body) if nil != err { panic(err) } fmt.Printf("%v\n%v\n%q\n", url, resp.Status, body) } func main() { urls := os.Args[1:] wg := sync.WaitGroup{} wg.Add(len(urls)) for _, url := range urls { go download(&wg, url) } wg.Wait() }
(Lock) • A channel is just a file descriptor for an anonymous file ◦ ch <- ob write()-s the pointer of the object to the FD ◦ ob <- ch read()-s the pointer from the FD • OS Signals - SIGKILL, SIGINT… ◦ Uses signalfd() when available ◦ Uses various other techniques when not available • Sleep ◦ Sleeping the thread is not possible ◦ Uses timerfd_create() when available ◦ poll() can tell Linux to sleep the thread for some time • WaitGroups, Mutex ◦ Using eventfd()
channel is only a file descriptor for an anonymous file • Go’s select registers a different continuation for any case • Each case is an event on the channels file descriptor • For default it registers a continuation if no event is available ◦ This means poll() has been called without sleep ◦ Thus the Go loop uses two poll(): one without sleeping, and one with sleeping select { case <- ch1: // if poll on ch1 registered an event case <- ch2: // if poll on ch2 registered an event default: // if poll on ch1, ch2 did not // register any event }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}