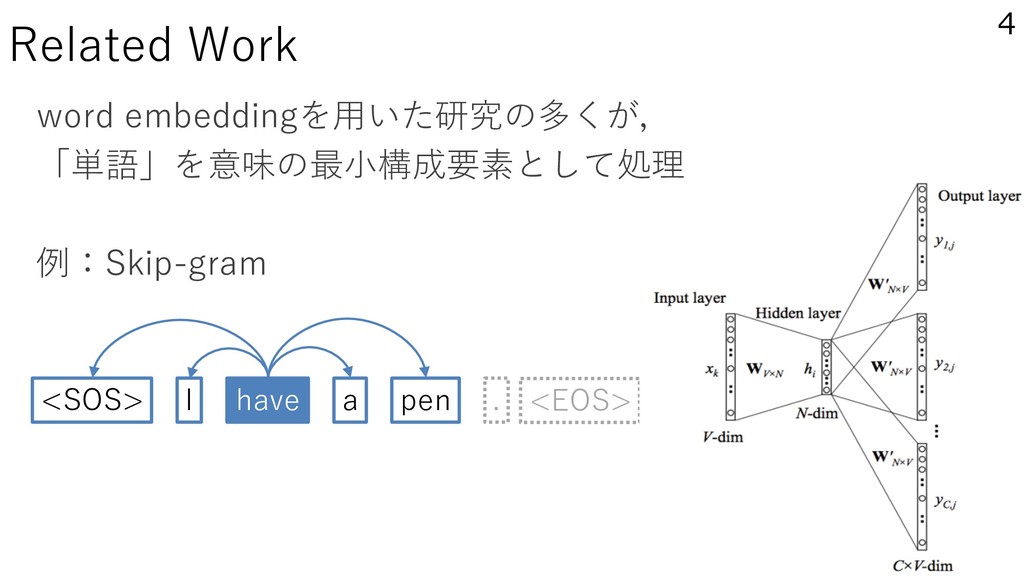
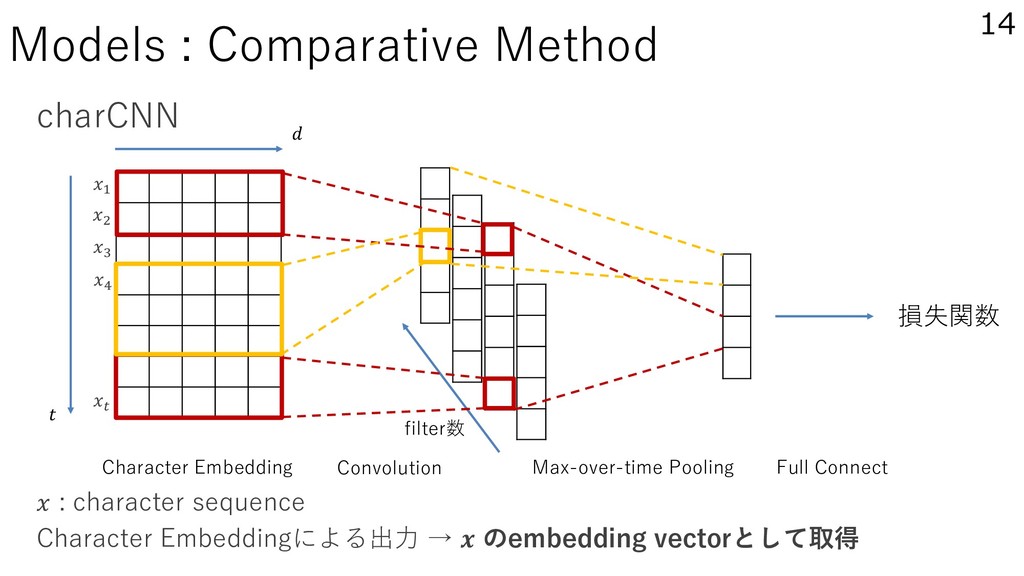
tagging with char Bi-LSTMs (Ling et al., 2015) – Language Modeling with char CNNs (Kim et al., 2015) 5 ex.) literal, literature, literary, literate Subword information × Character based model = Character n-gram(CHARAGRAM)
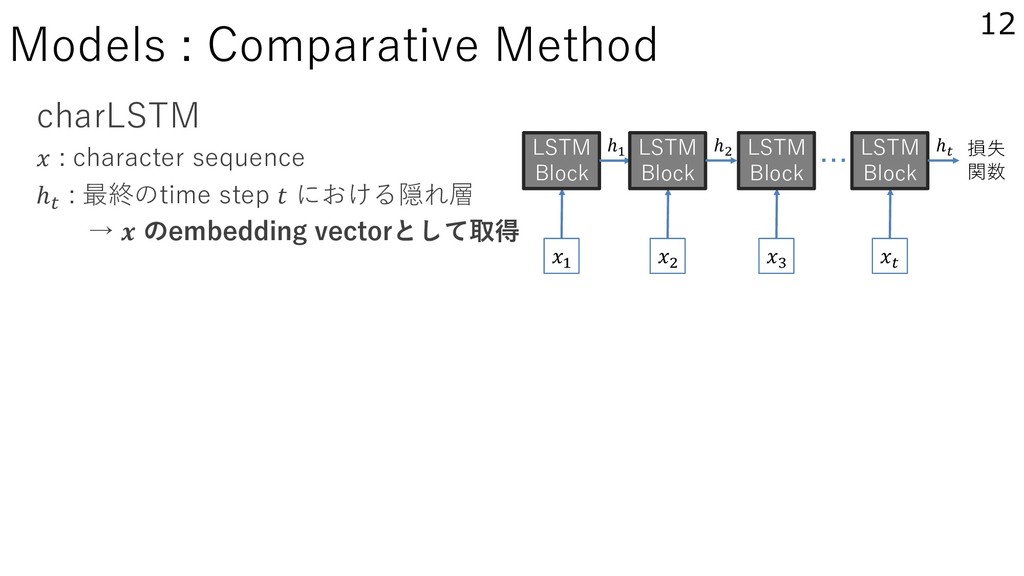
のembedding vectorとして取得 LSTM Block Models : Comparative Method 13 K LSTM Block L LSTM Block M LSTM Block I LSTM Block 損失 関数 ・・・ ℎK ℎL ℎI N O O Input Gate Forget Gate Memory Cell O Output Gate O Hidden layer
(L )と類似度が最も⾼くなるphrase を選択 ( chooses the most similar phrase in some set of phrases ) – MIN = selects negative examples using MAX with probability 0.5 and selects them randomly from the mini-batch otherwise.
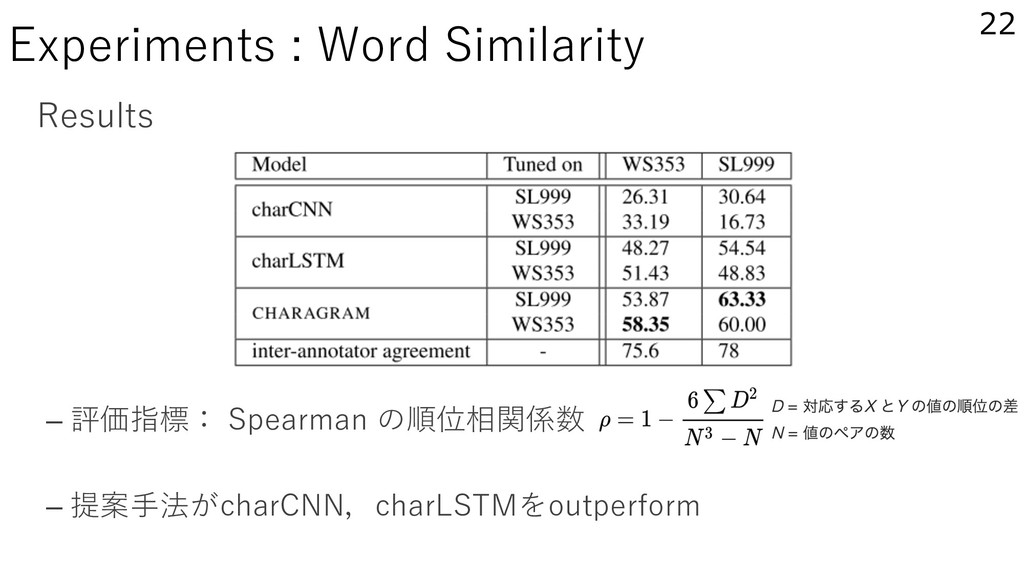
: PPDB(770,007 word pairs) → 1 epoch – Tuning : WordSim-353, SimLex-999 → 50 epoch – Hyperparameter 共通:ミニバッチサイズ( 25 or 50 ),マージン( 0.4 ),次元数( 300 ) 正則化パラメータ( 10-4 or 10-5 or 10-6 ),最適化(Adam lr=0.001) CHARAGRAM:char n-grams( n ∈ {2, 3, 4} ),活性化関数(ℎ or ) charLSTM:output gate (on or off ) charCNN:filter数( 25 or 125 ),dropout (on or off ),活性化関数(ℎ or )
: PPDB(3,033,753 phrase pairs) → 1 epoch – Tuning : PPDB(9,123,575 phrase pairs) → 10 epoch – Hyperparameter 共通:ミニバッチサイズ( 100 ),マージン( 0.4 ),次元数( 300 ) 正則化パラメータ( 10-4 or 10-5 or 10-6 ),最適化(Adam lr=0.001) CHARAGRAM:char n-grams( n ∈ {2, 3, 4} ),活性化関数(ℎ or ) charLSTM:output gate (on or off ) charCNN:filter数( 25 or 125 ),dropout (on or off ),活性化関数(ℎ or )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}