trackにも採択 [paper] • 開発者は以下のような可視化で有名なJay Alammarさんら ◦ The Illustrated Word2vec ◦ The Illustrated Transformer ◦ The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) ◦ The Illustrated GPT-2 (Visualizing Transformer Language Models) ◦ How GPT3 Works - Visualizations and Animations • PyDataでもチュートリアルを開催 ◦ Jay Alammar - Take A Look Inside Language Models With Ecco | PyData Khobar • 開発者が英語テキストを対象に各種可視化をしている記事 ◦ Interfaces for Explaining Transformer Language Models ◦ Finding the Words to Say: Hidden State Visualizations for Language Models 3
{kind=link}
{kind=link}
![eccoとは? • ニューラル言語モデルの可視化に特化したOSS [repo] ◦ 今回の検証ではバージョン 0.1.2を利用 • 昨年のACL2021 demo](https://files.speakerdeck.com/presentations/1b31ed5908974dcba11416eea24fbf59/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
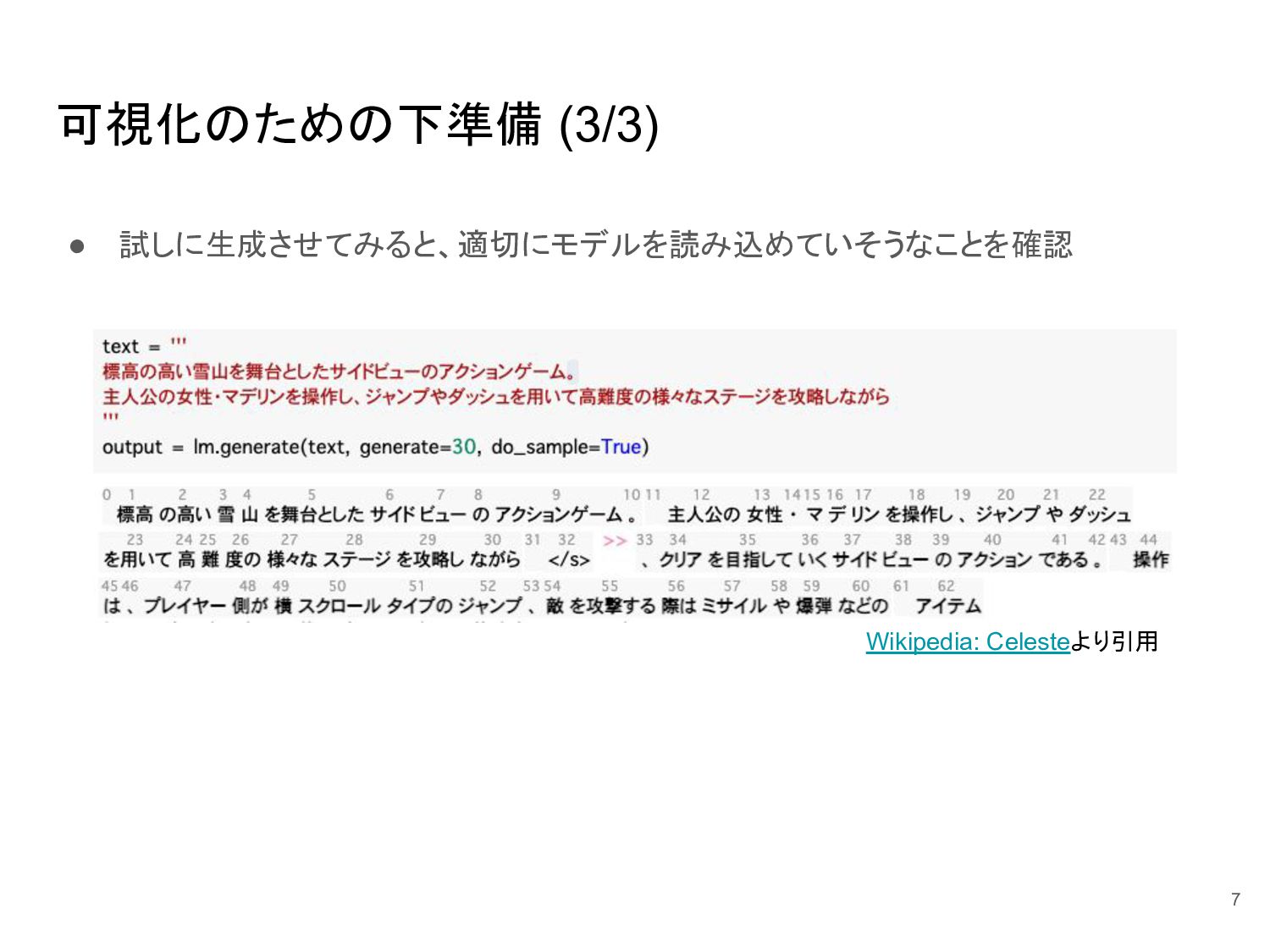{kind=link}
{kind=link}
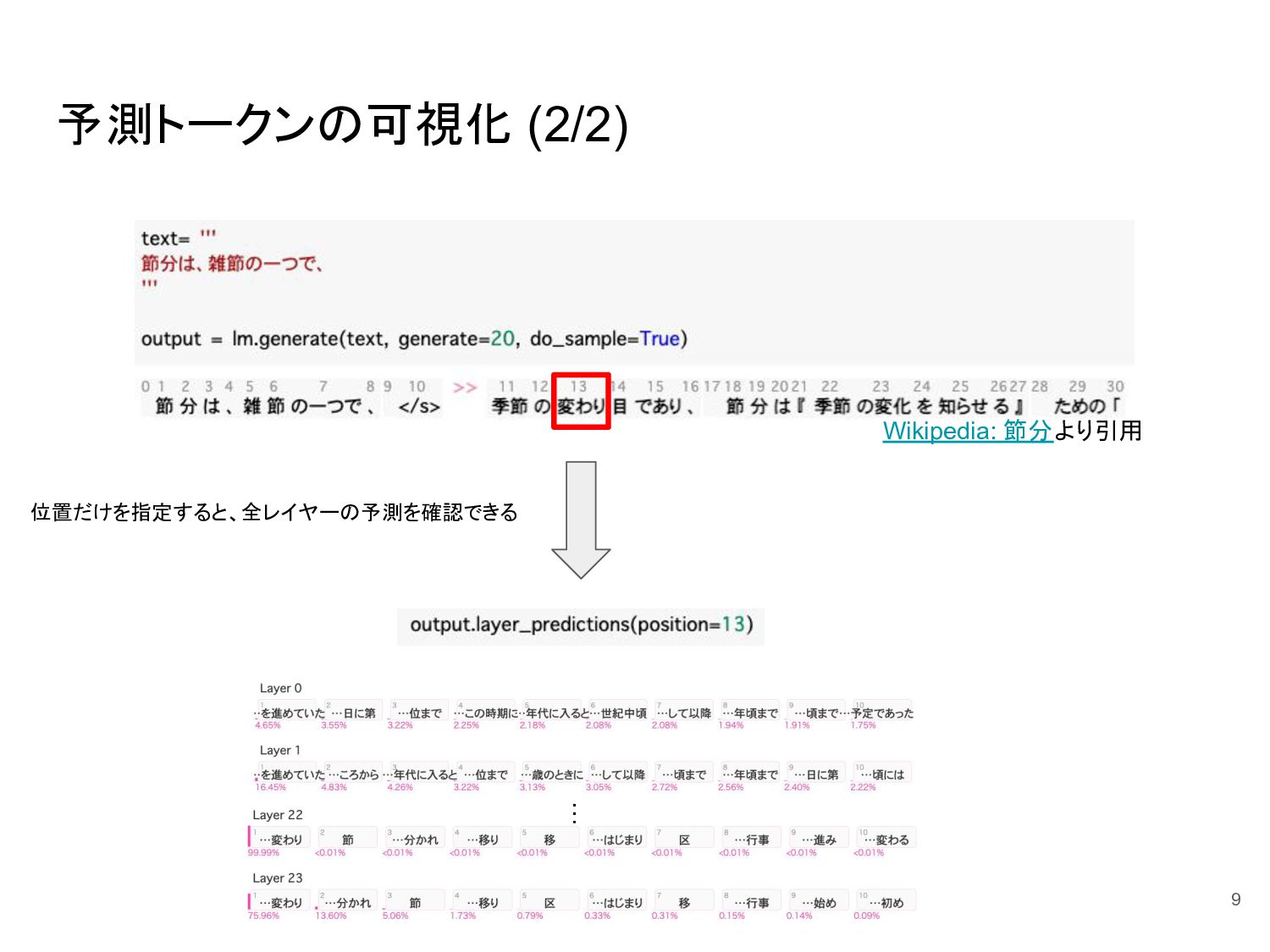{kind=link}
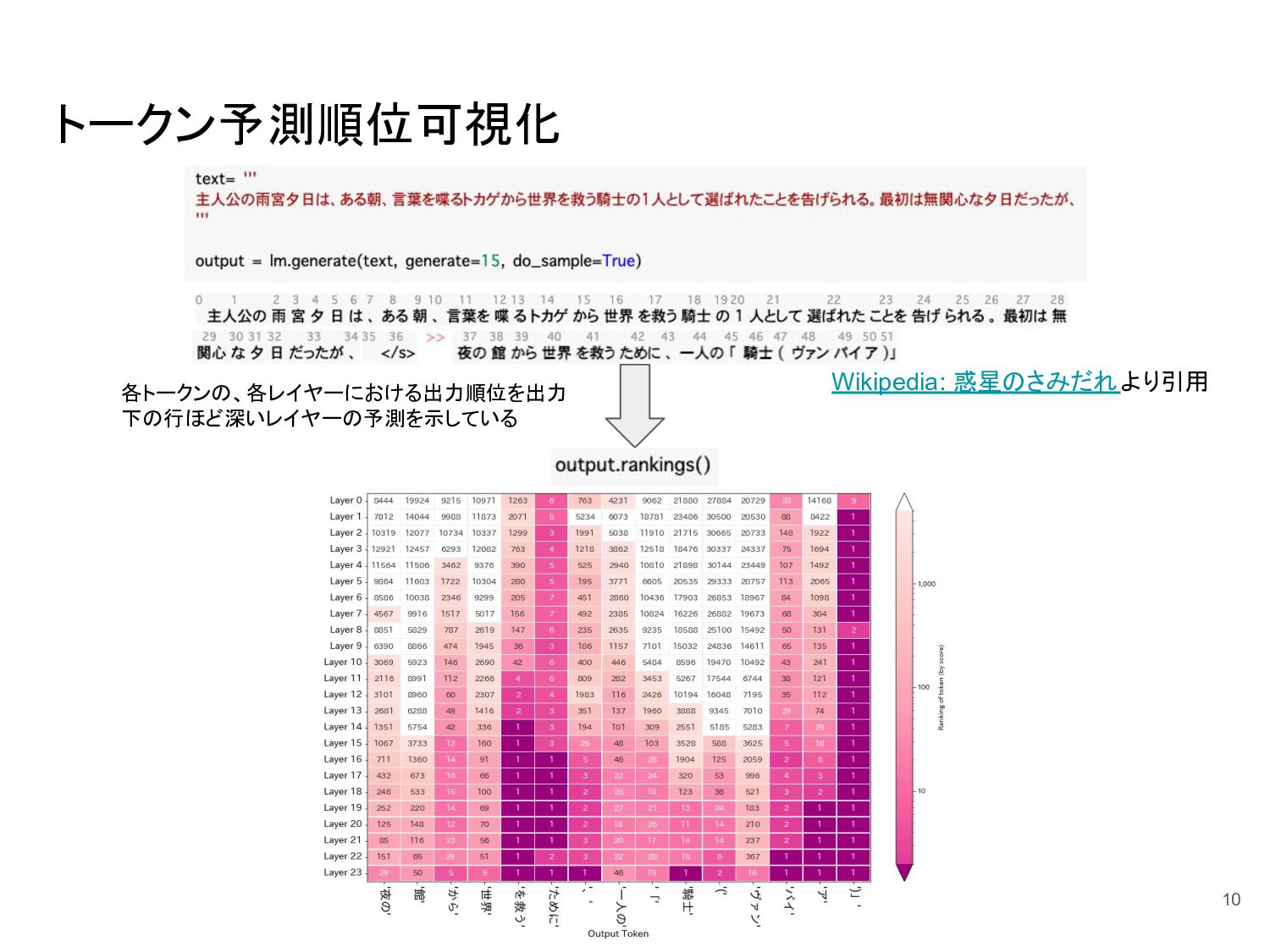{kind=link}
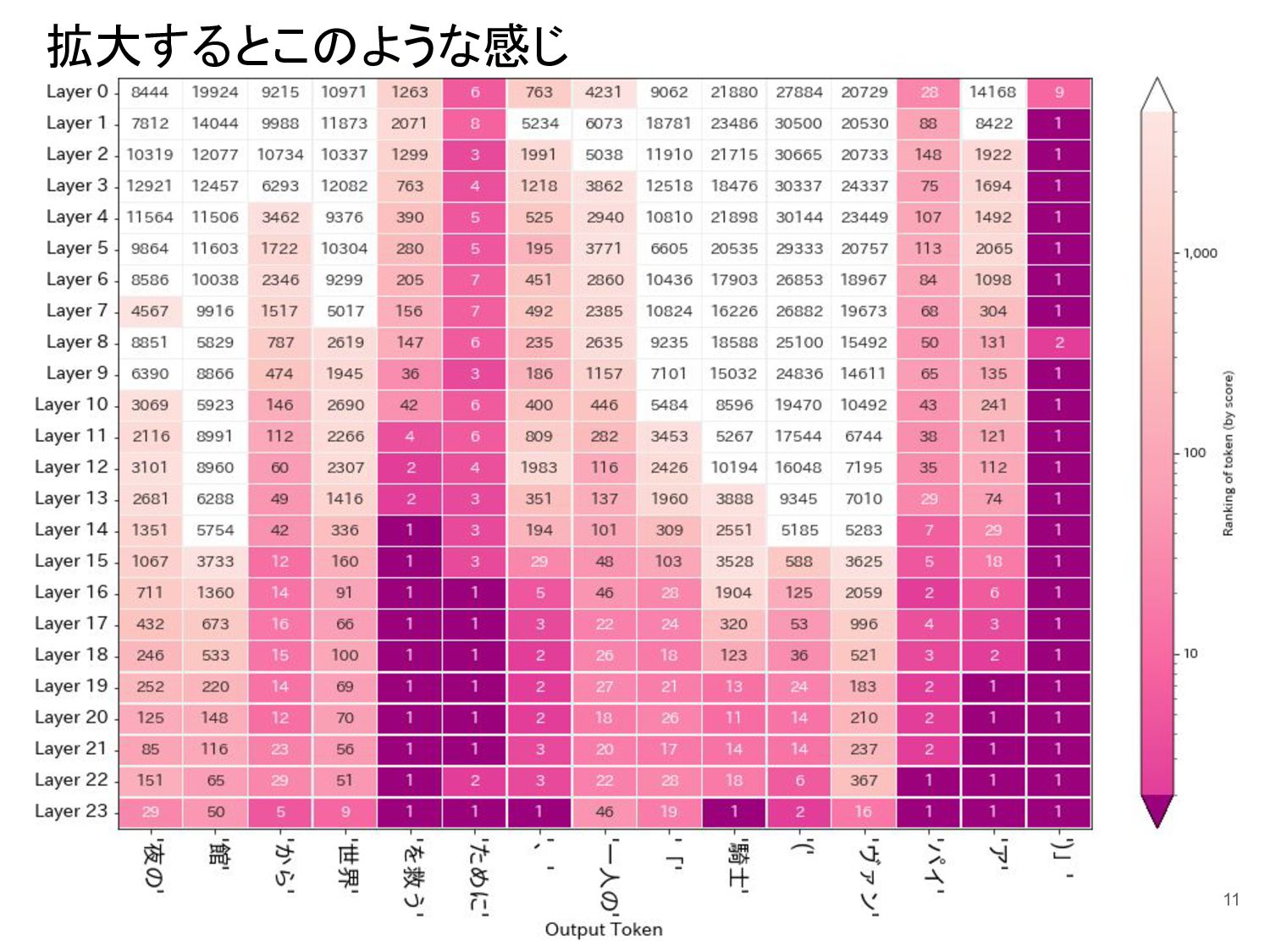{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}