2023/09/13に開催された大阪駆動開発様主催の「AIミーティング」で発表した資料です。
"LISA: Reasoning Segmentation via Large Language Model" (Lai et al., 2023)を使ってみた感想です。
スライドの内容について誤りやご意見がありましたら[email protected]までご連絡ください。
大阪駆動開発
conpass: https://osaka-driven-dev.connpass.com/
AIミーティング 2023/09/13 #AIMTG #ChatGPT #GPT4 #PaLM
connpass: https://osaka-driven-dev.connpass.com/event/292953/
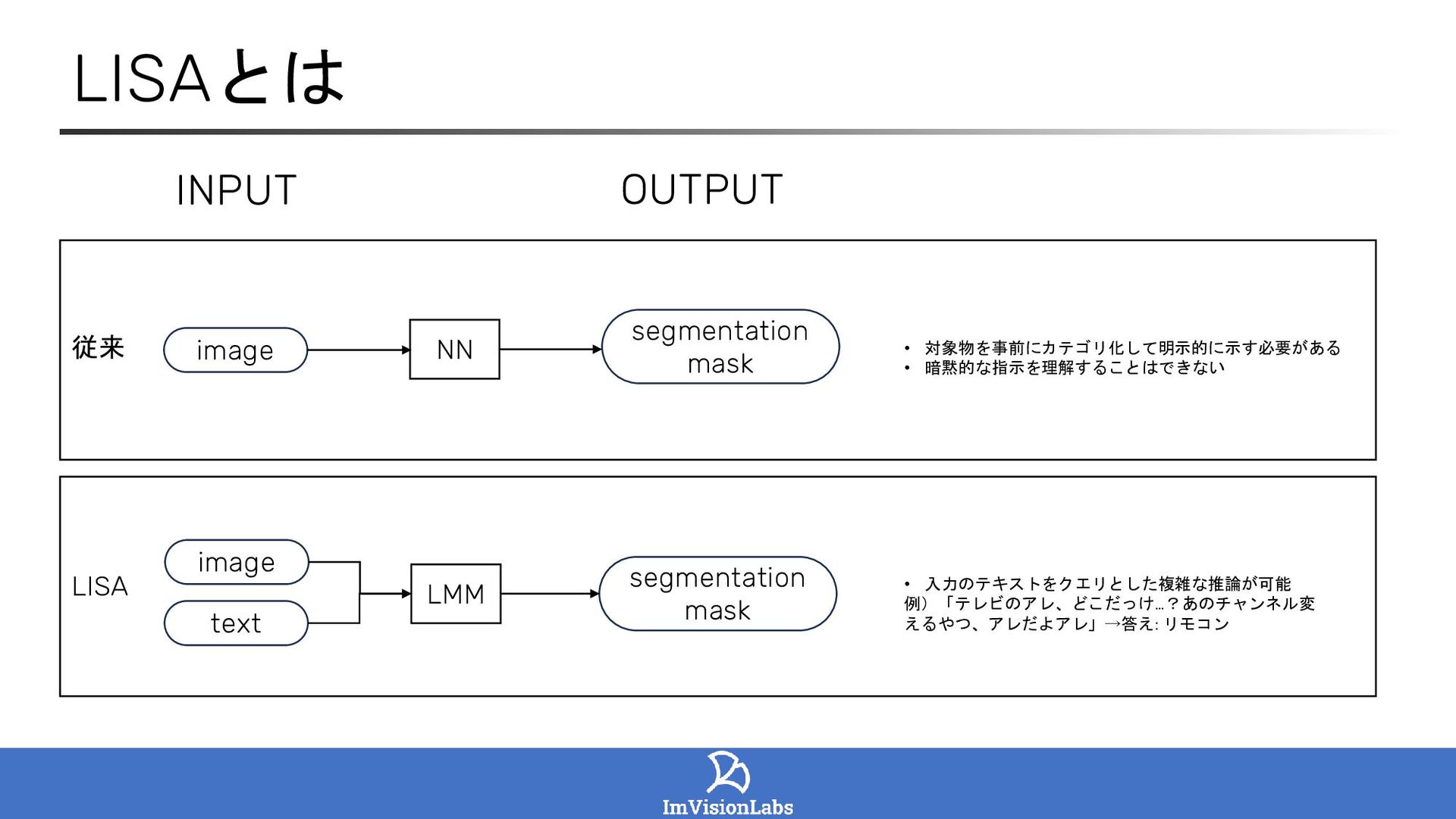
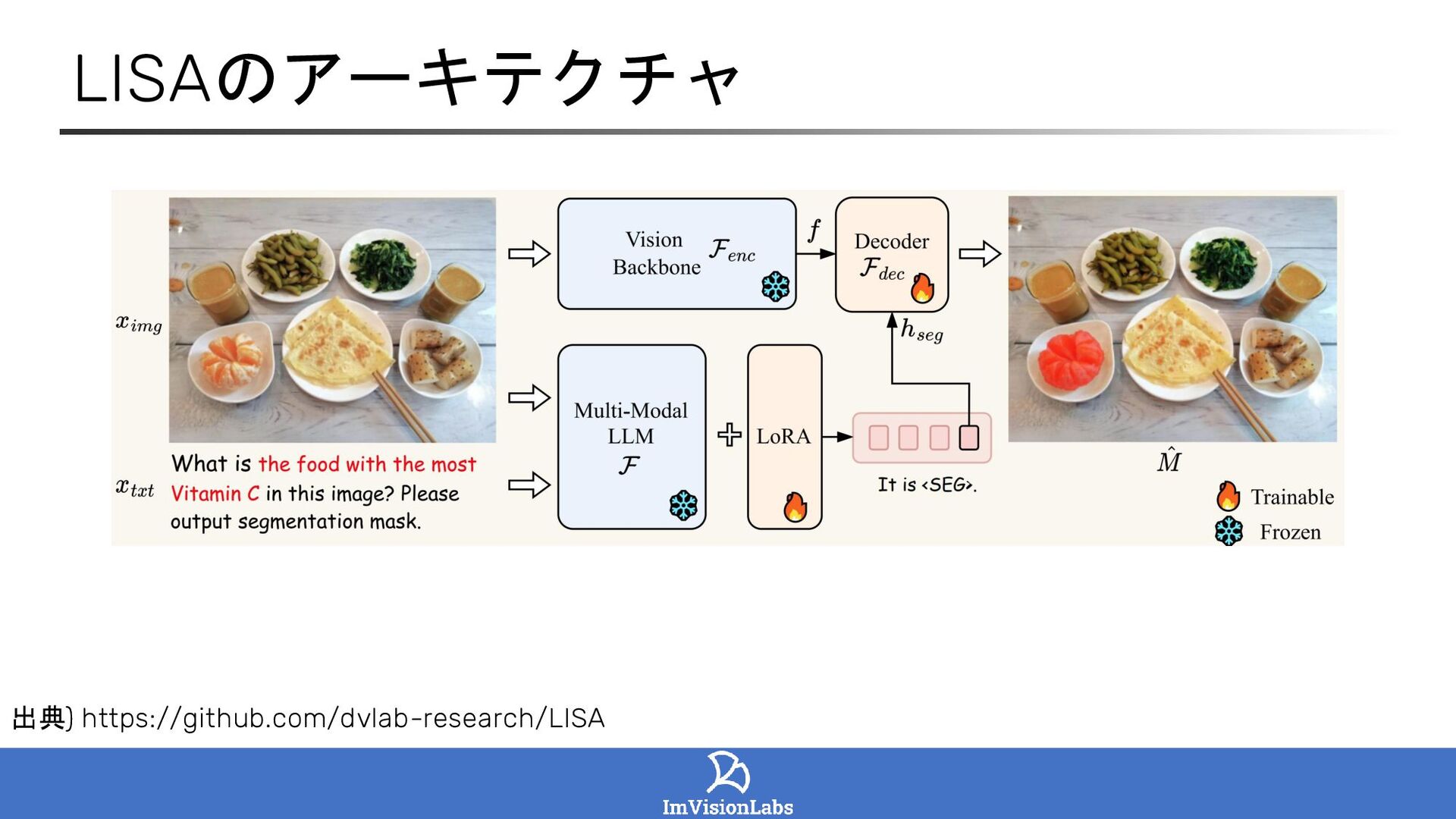
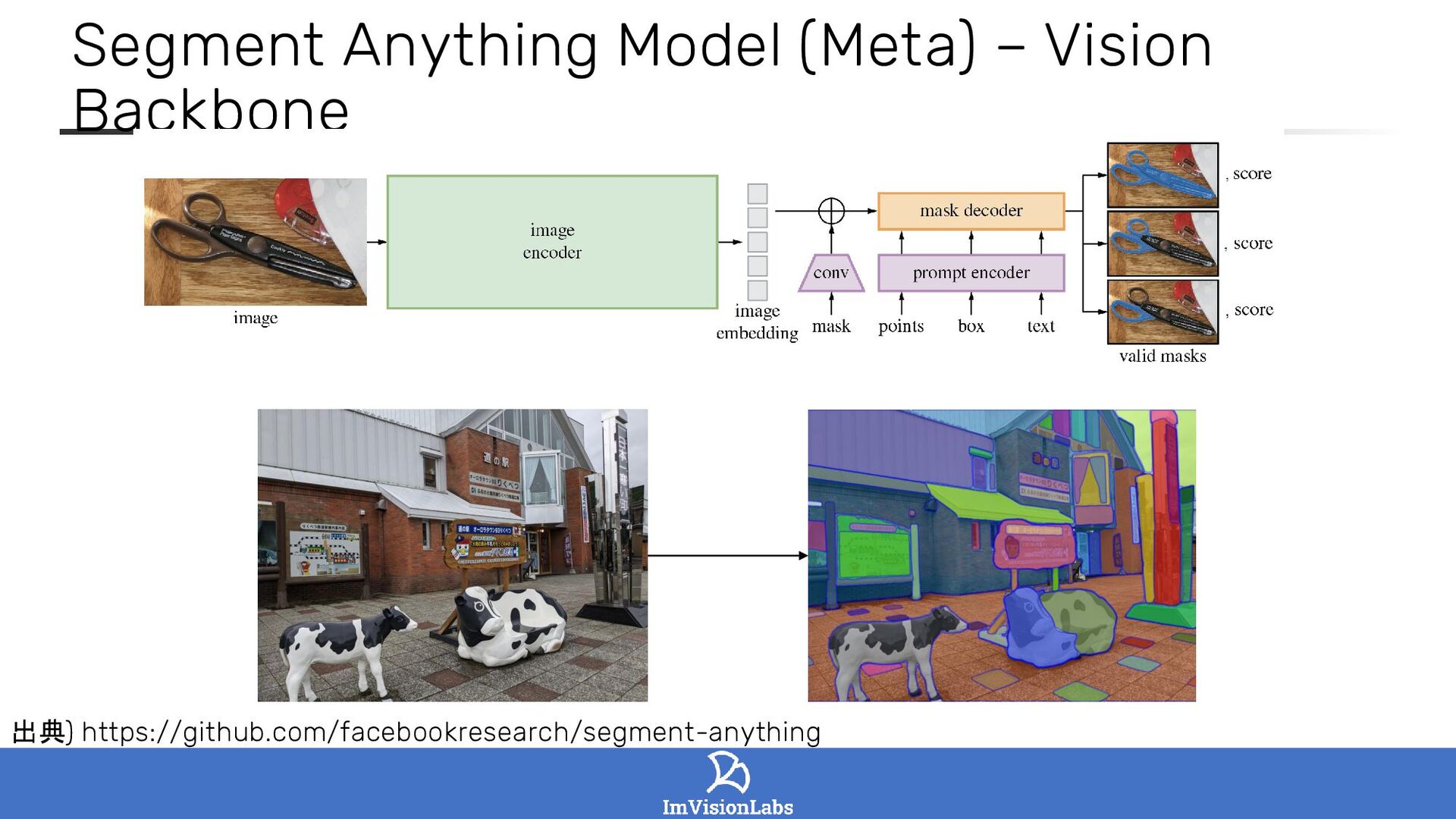
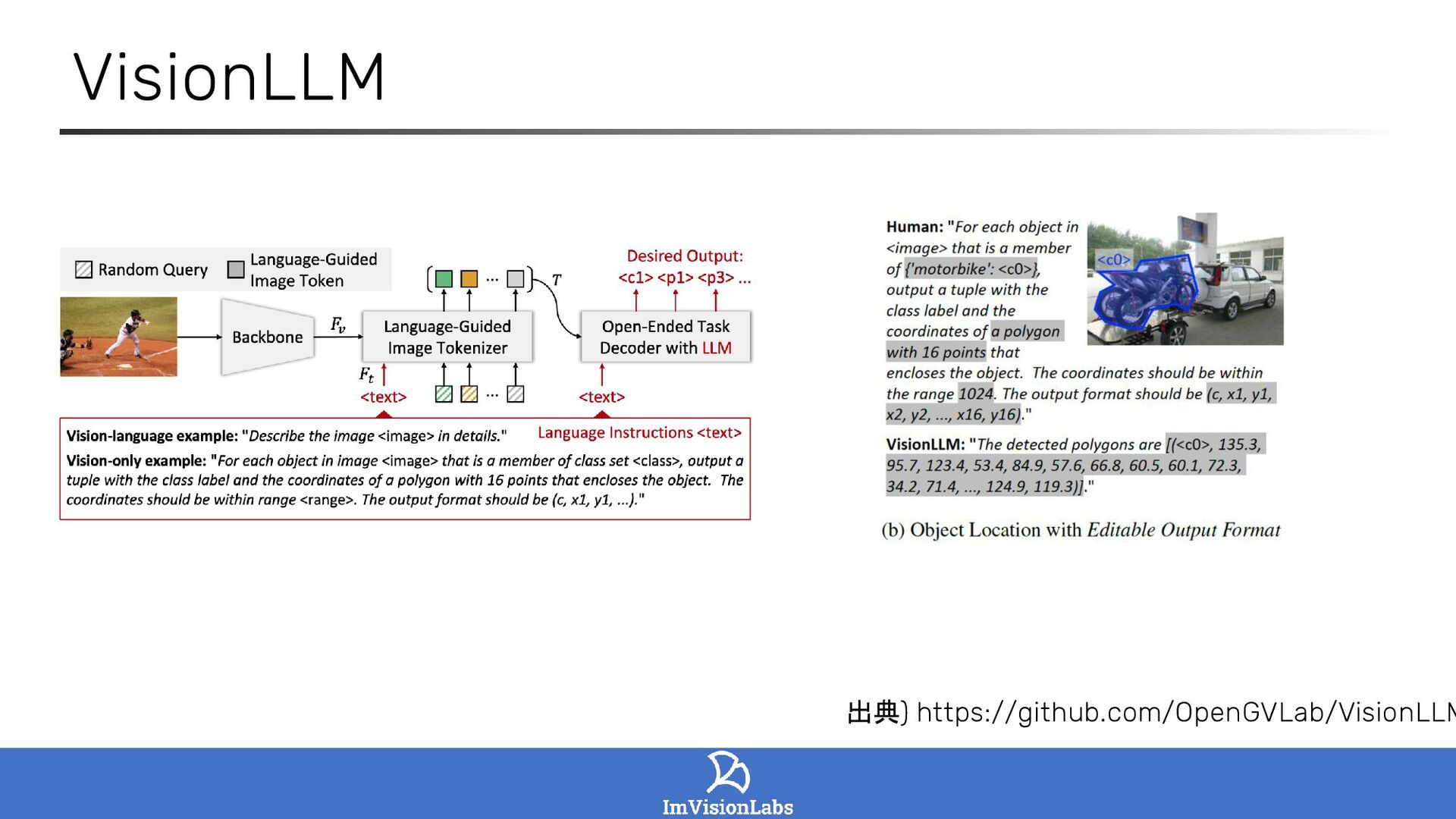
LISA: Reasoning Segmentation via Large Language Model (Lai et al., 2023)
github: https://github.com/dvlab-research/LISA
arXiv: https://arxiv.org/abs/2308.00692
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}