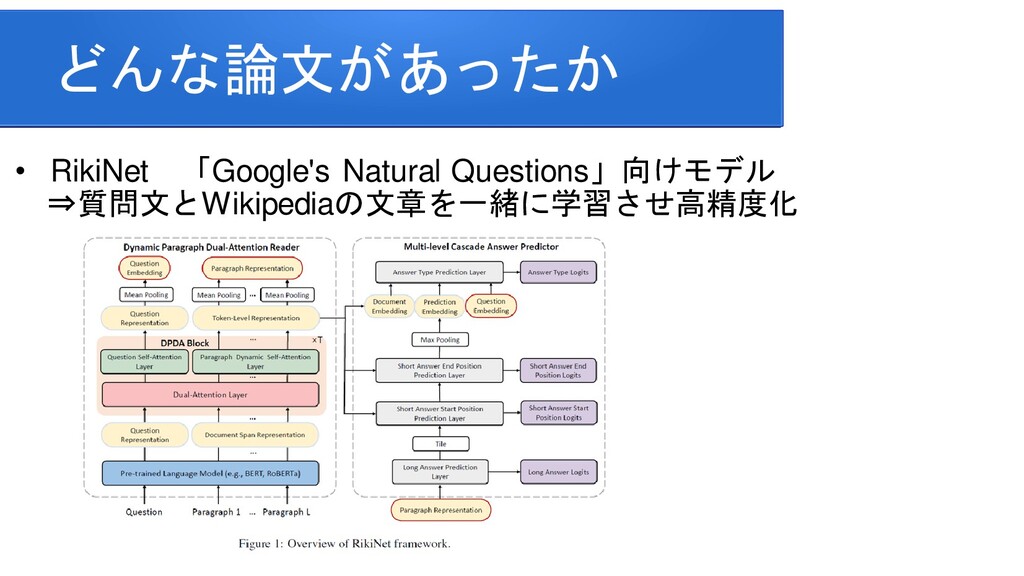
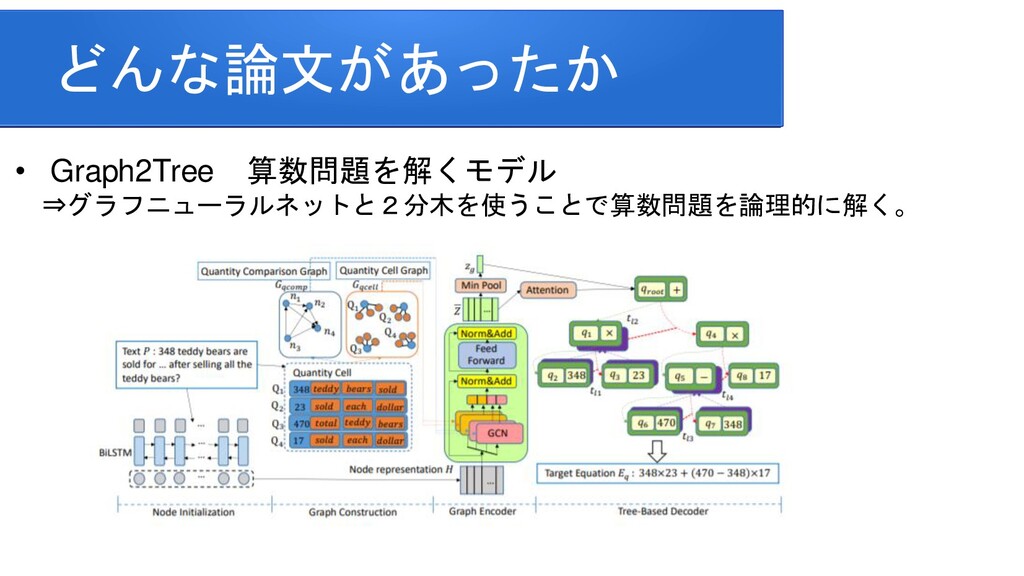
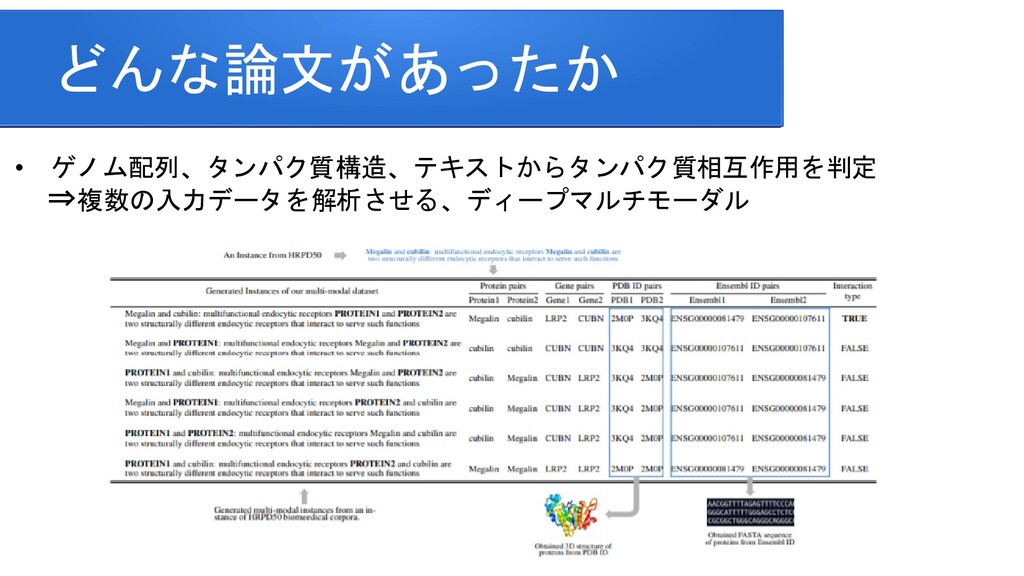
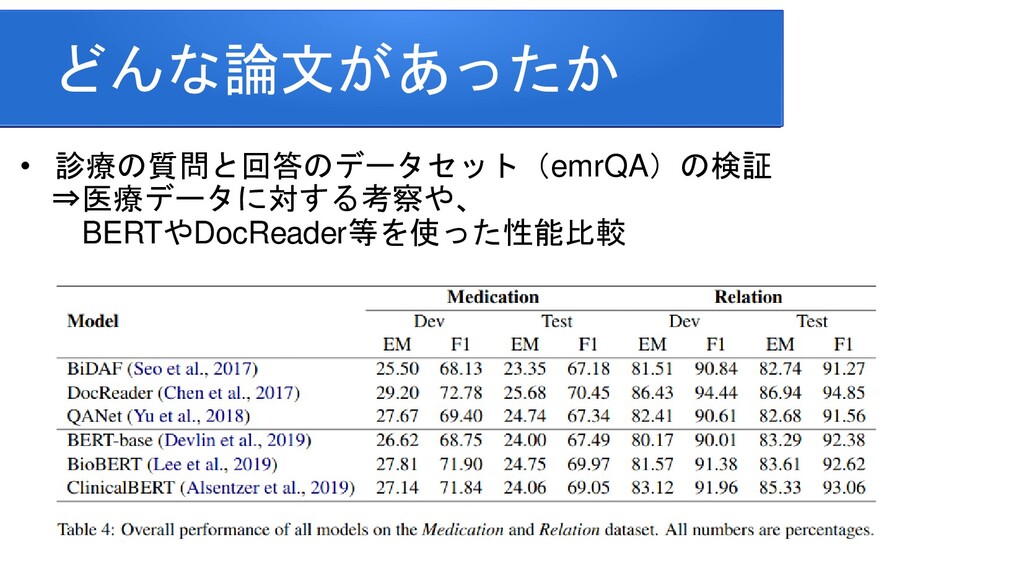
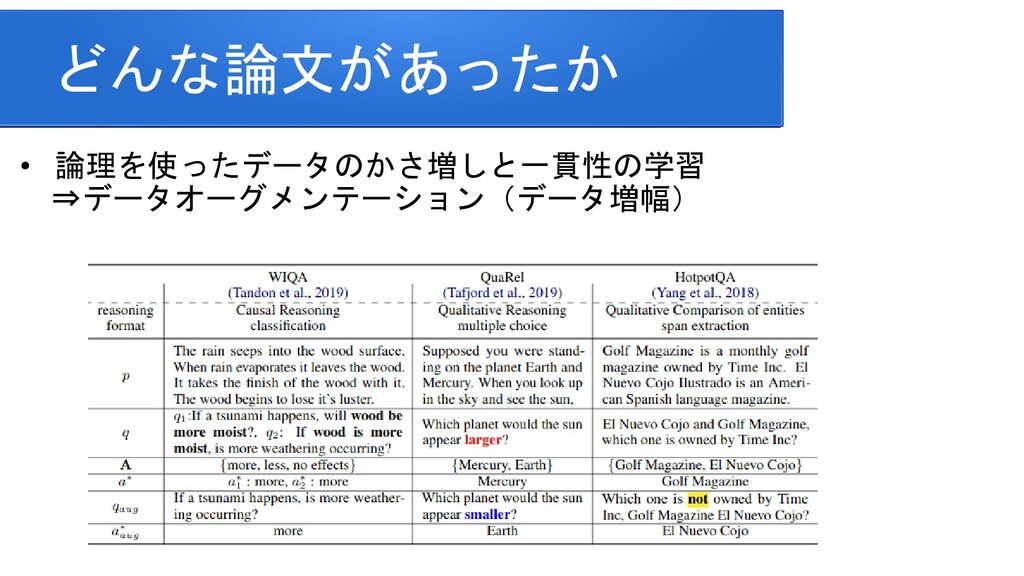
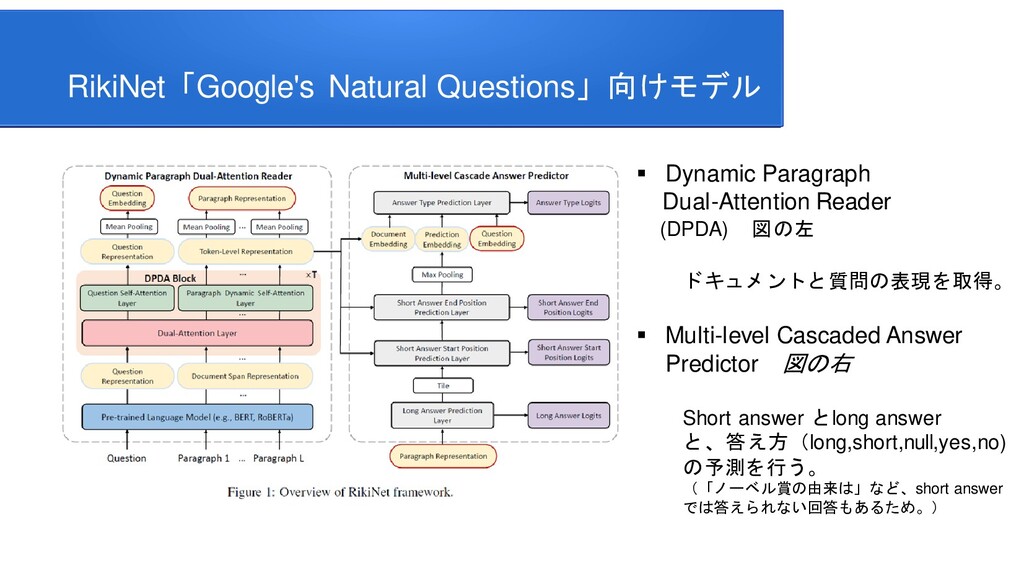
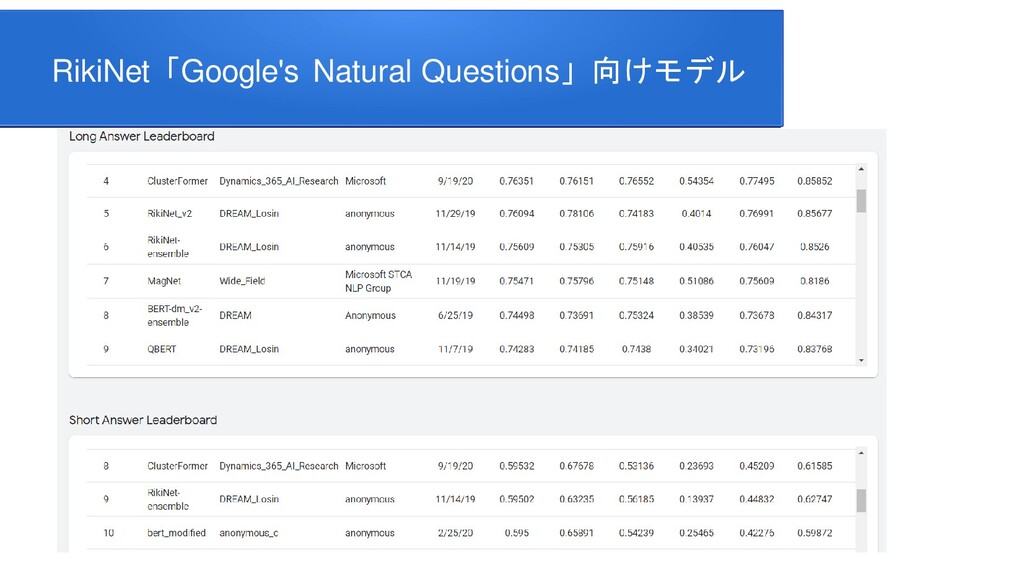
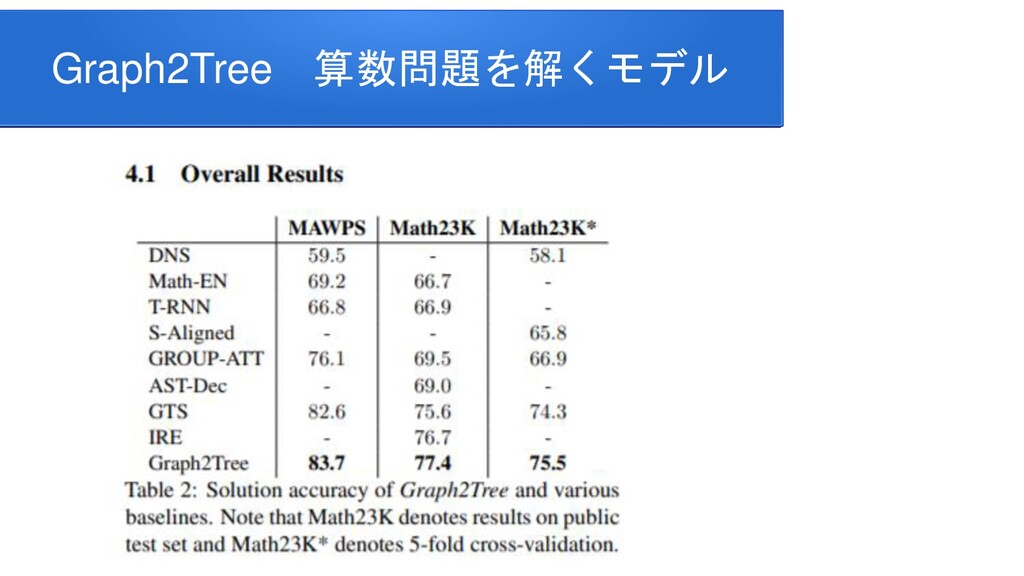
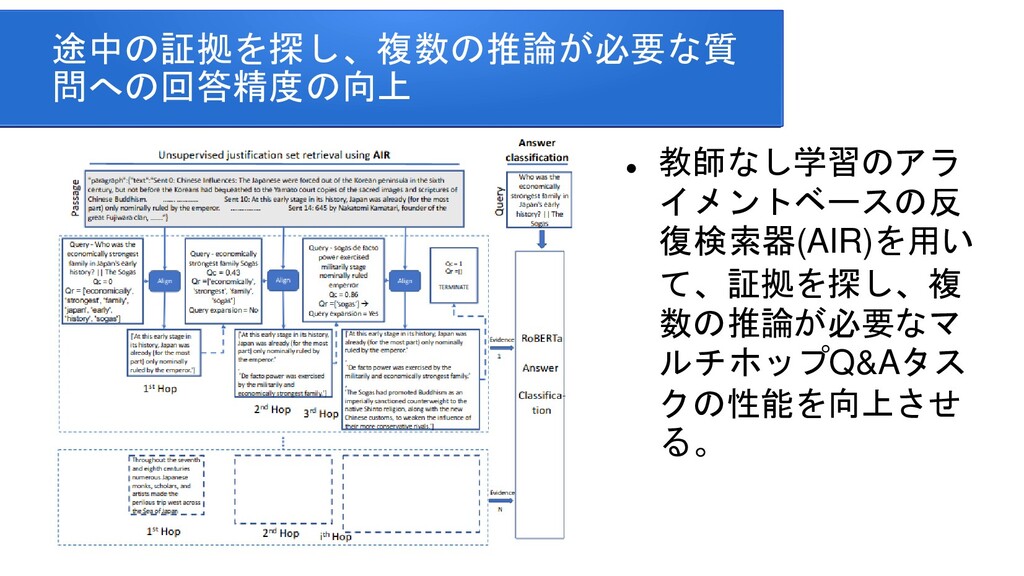
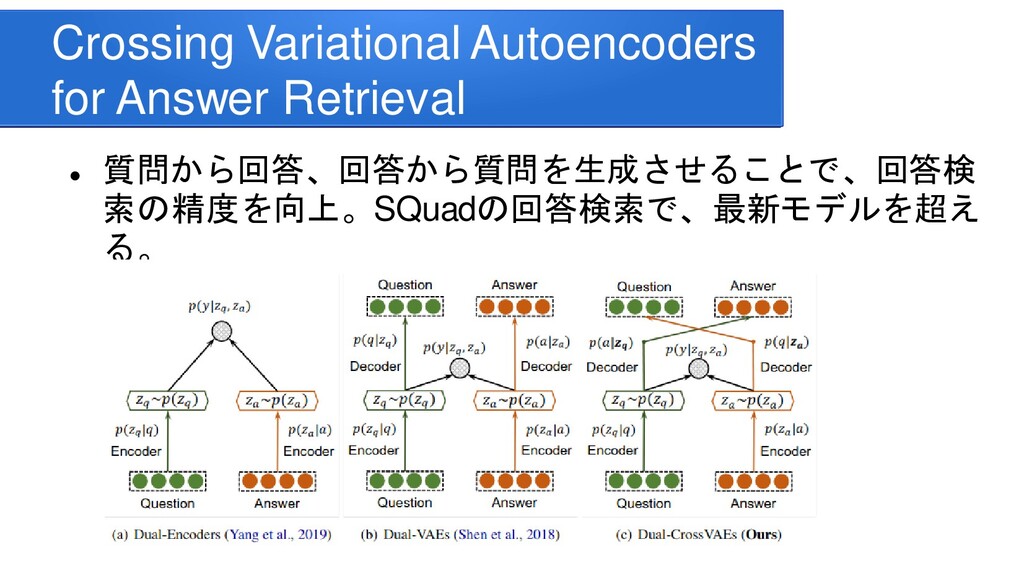
information for improving protein-protein interaction identification Pratik Dutta, Sriparna Saha Department of Computer Science & Engineering Indian Institute of Technology Patna Clinical Reading Comprehension: A Thorough Analysis of the emrQA Dataset Xiang Yue Bernal Jimenez Gutierrez The Ohio State University Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings Vikas Yadav, Steven Bethard, Mihai Surdeanu University of Arizona, Tucson, AZ, USA Graph-to-Tree Learning for Solving Math Word Problems Jipeng Zhang1,2,∗ , Lei Wang2,∗ , Roy Ka-Wei Lee3 , Yi Bin1 , Yan Wang4 , Jie Shao1,5,#, Ee-Peng Lim2 1Center for Future Media, University of Electronic Science and Technology of China 2School of Information Systems, Singapore Management University 3Department of Computer Science, University of Saskatchewan 4Tencent AI Lab 5Sichuan Artificial Intelligence Research Institute Contextualized Sparse Representations for Real-Time Open-Domain Question Answering Jinhyuk Lee1 Minjoon Seo2,3 Hannaneh Hajishirzi2,4 Jaewoo Kang Korea University1 University of Washington2 Clova AI, NAVER3 Allen Institute for AI4 RikiNet: Reading Wikipedia Pages for Natural Question Answering Dayiheng Liu♠† Yeyun Gong† Jie Fu♦ Yu Yan† Jiusheng Chen♥Daxin Jiang‡ Jiancheng Lv♠ Nan Duan† College of Computer Science, Sichuan University †Microsoft Research Asia ♦ Mila ‡Microsoft Search Technology Center Asia ♥Microsoft AI and Research
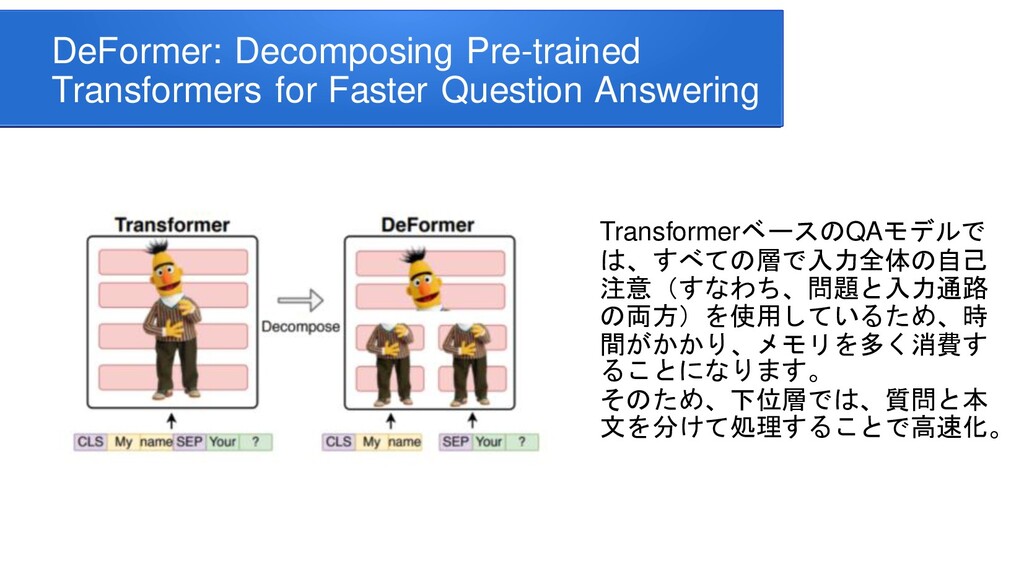
[email protected] DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering Qingqing Cao, Harsh Trivedi, Aruna Balasubramanian, Niranjan Balasubramanian Department of Computer Science Stony Brook University Stony Brook, NY 11794, USA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
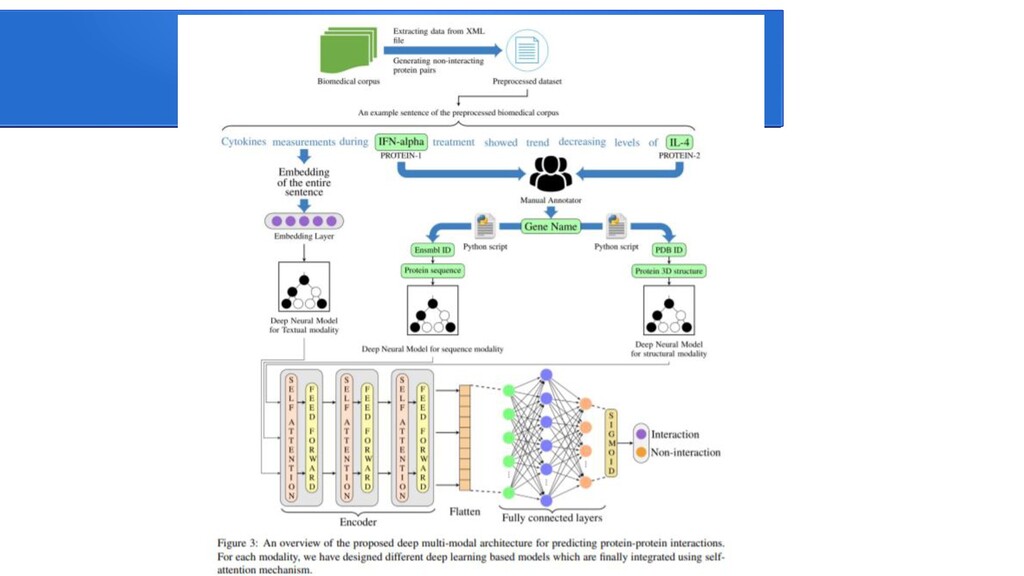{kind=link}
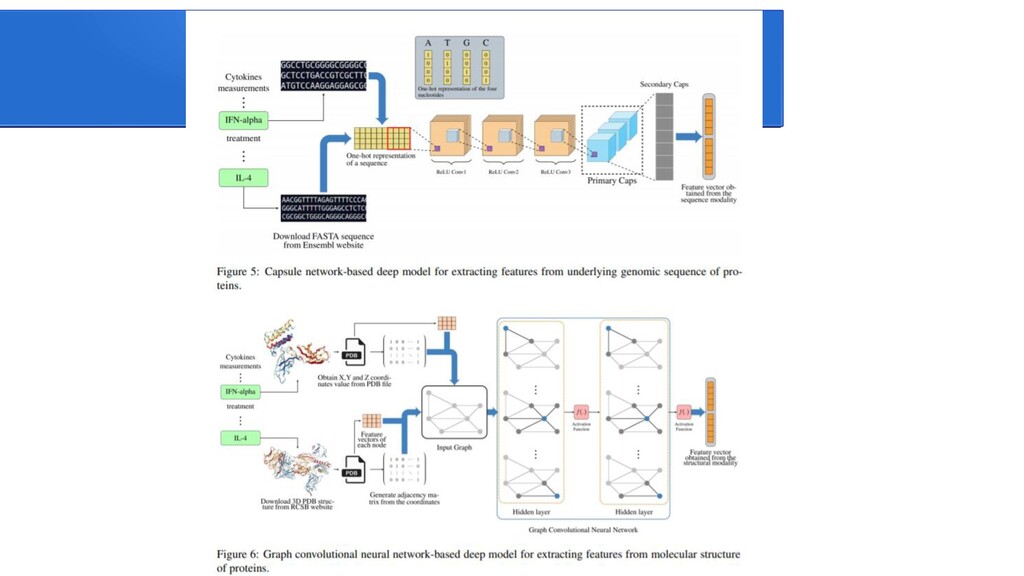{kind=link}
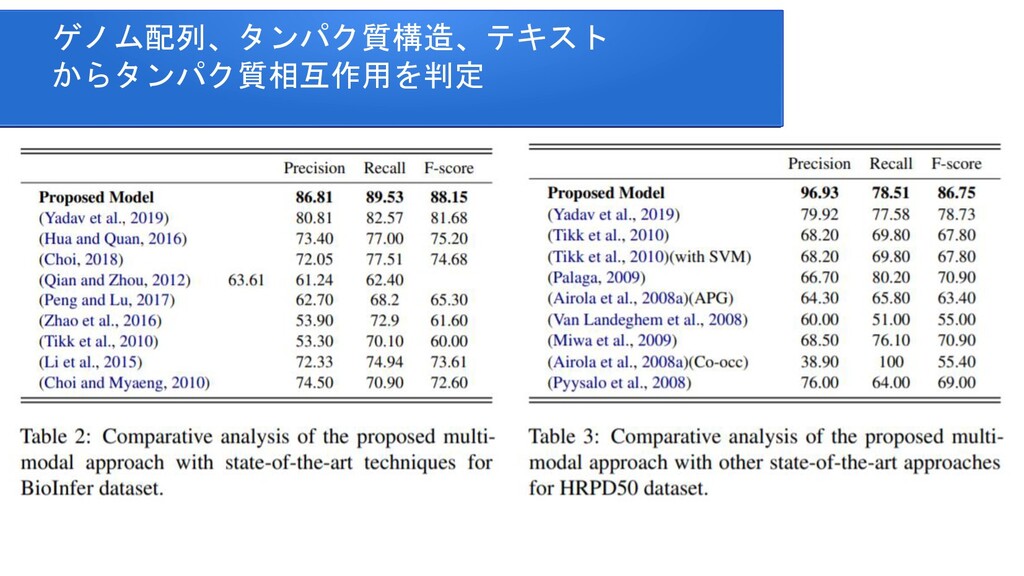{kind=link}
{kind=link}
{kind=link}
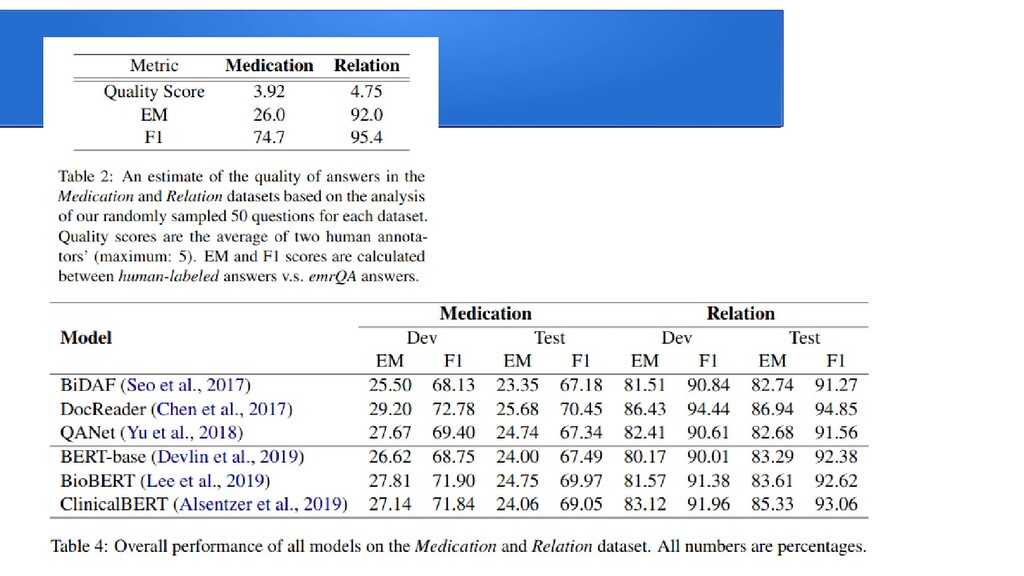{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}