本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、
より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。
speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
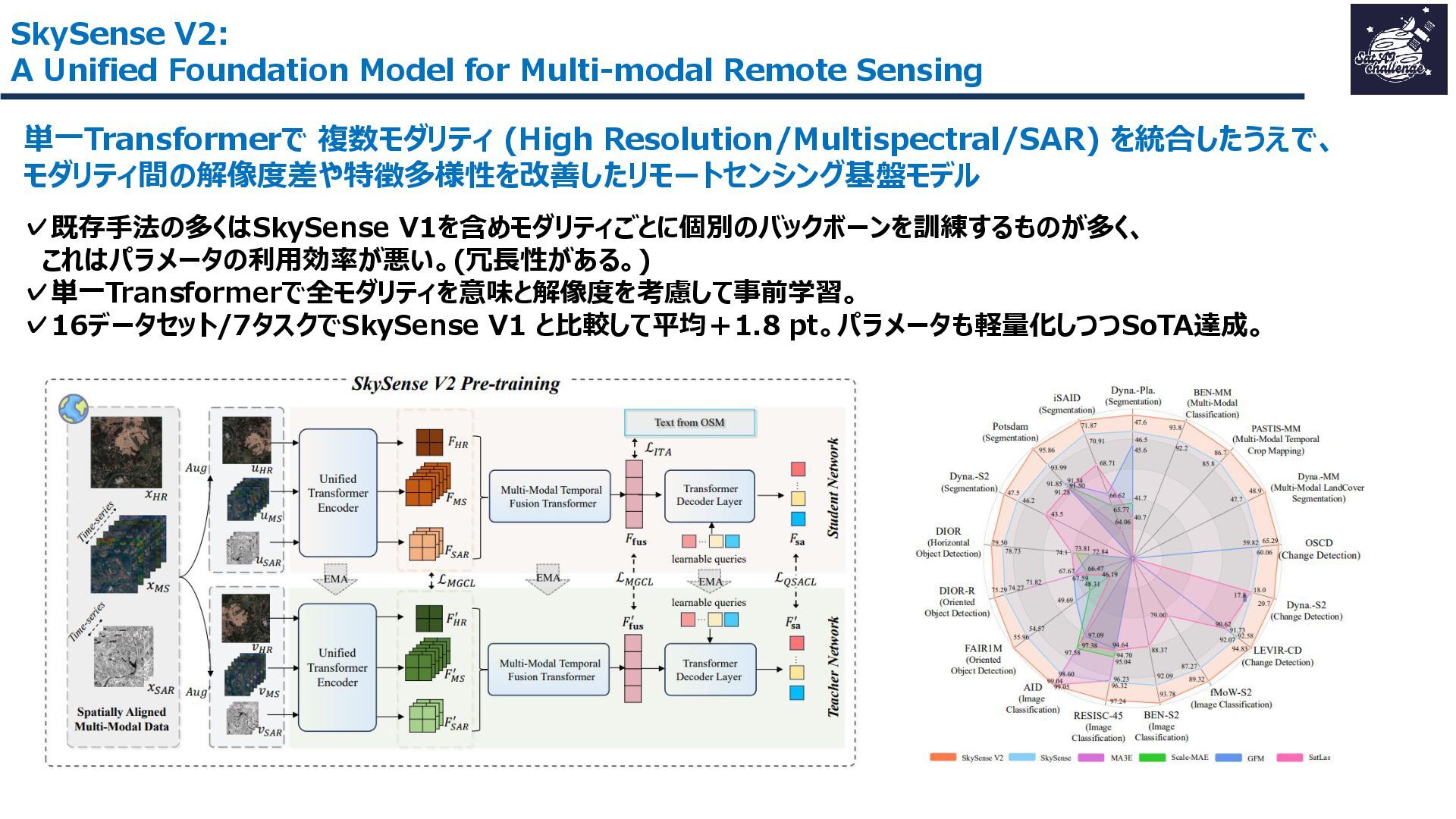
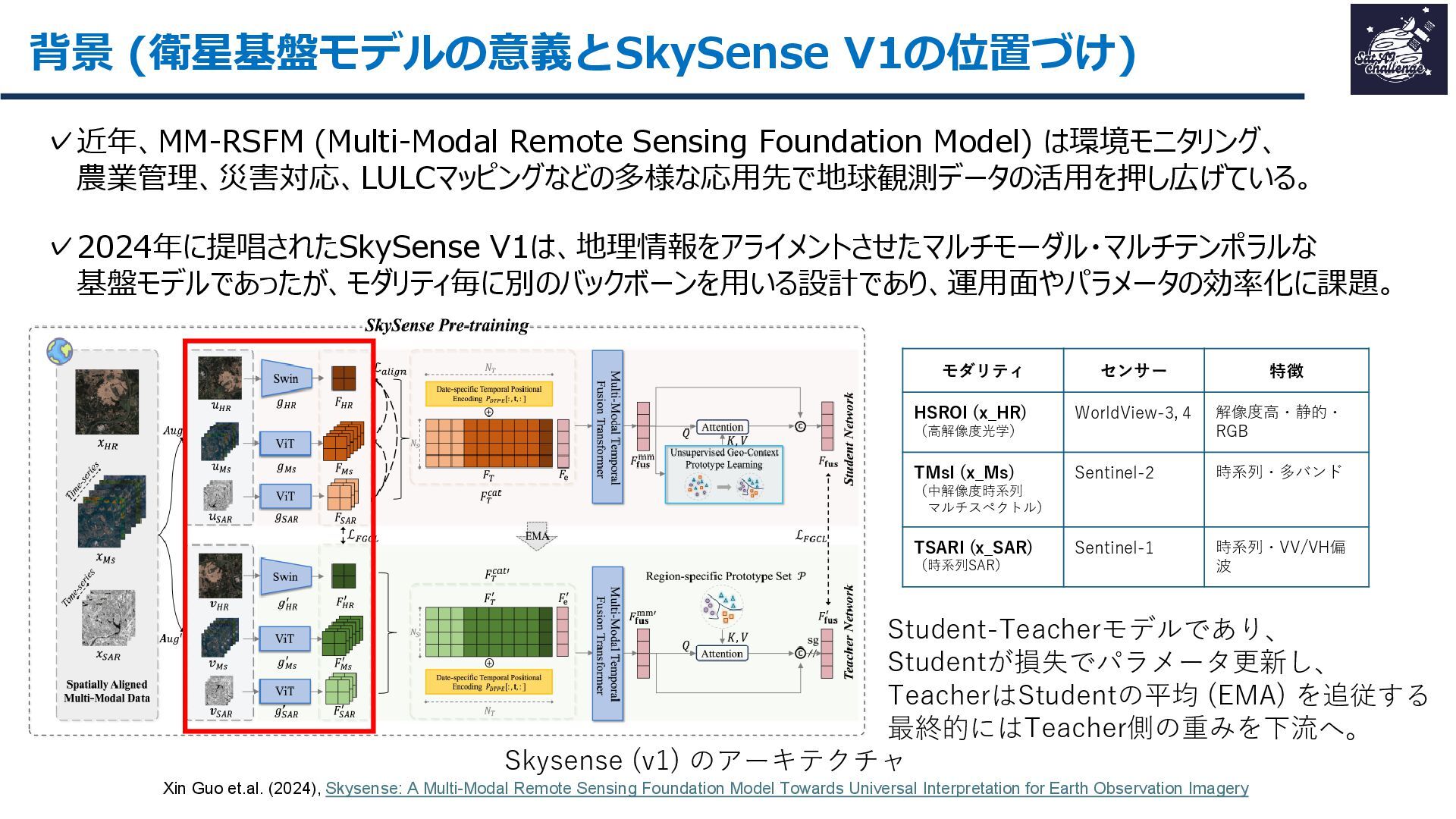
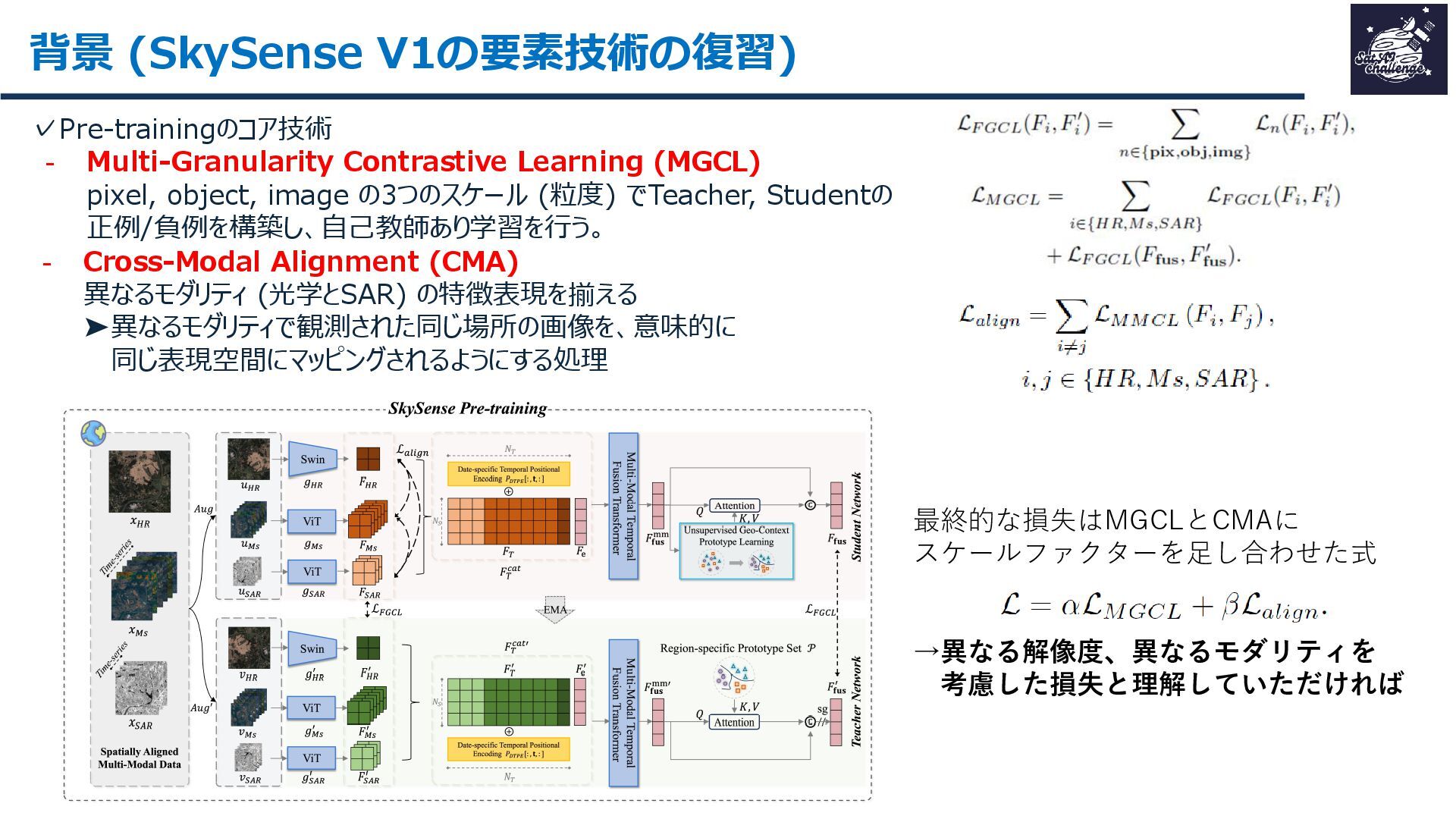
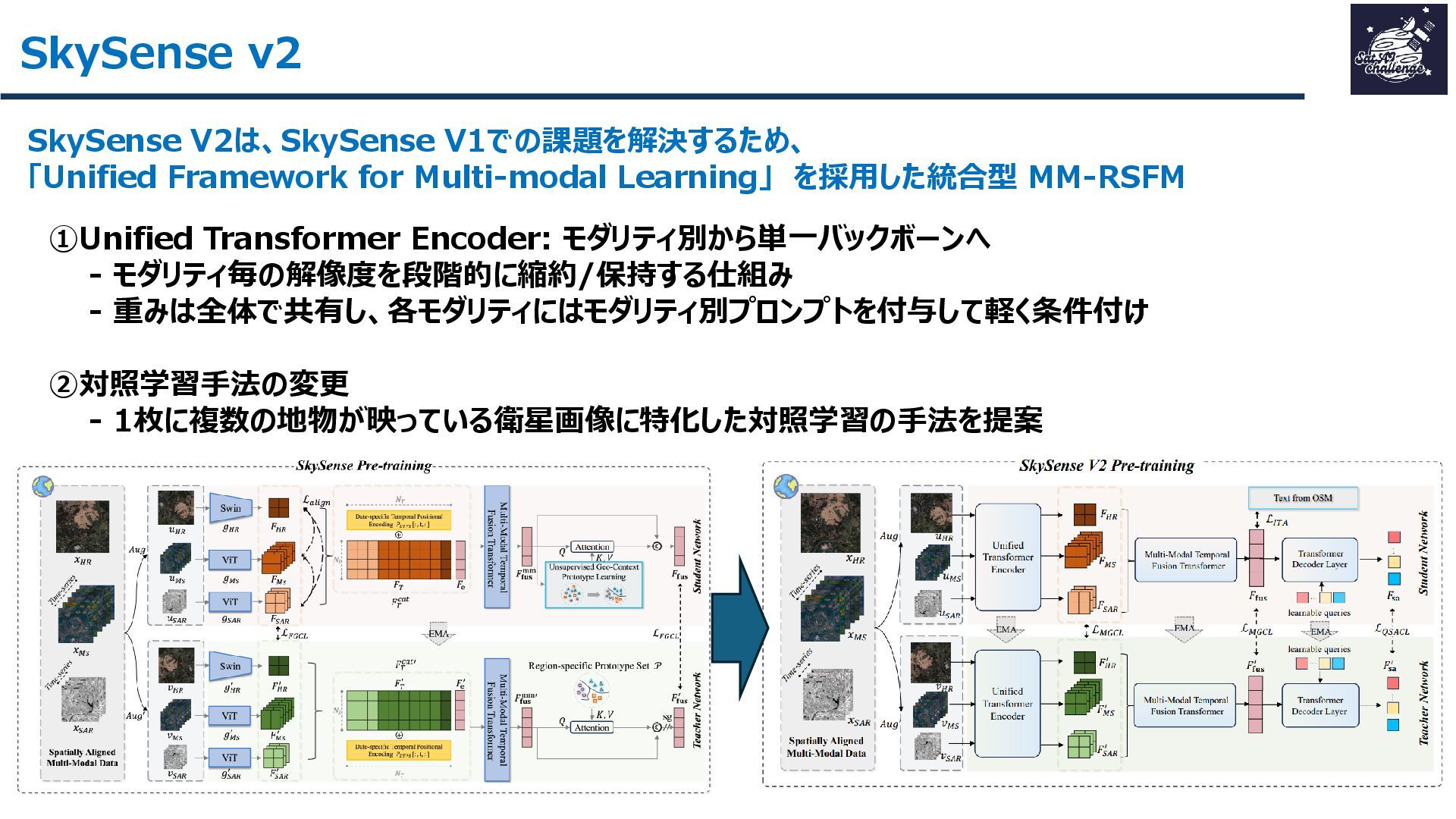
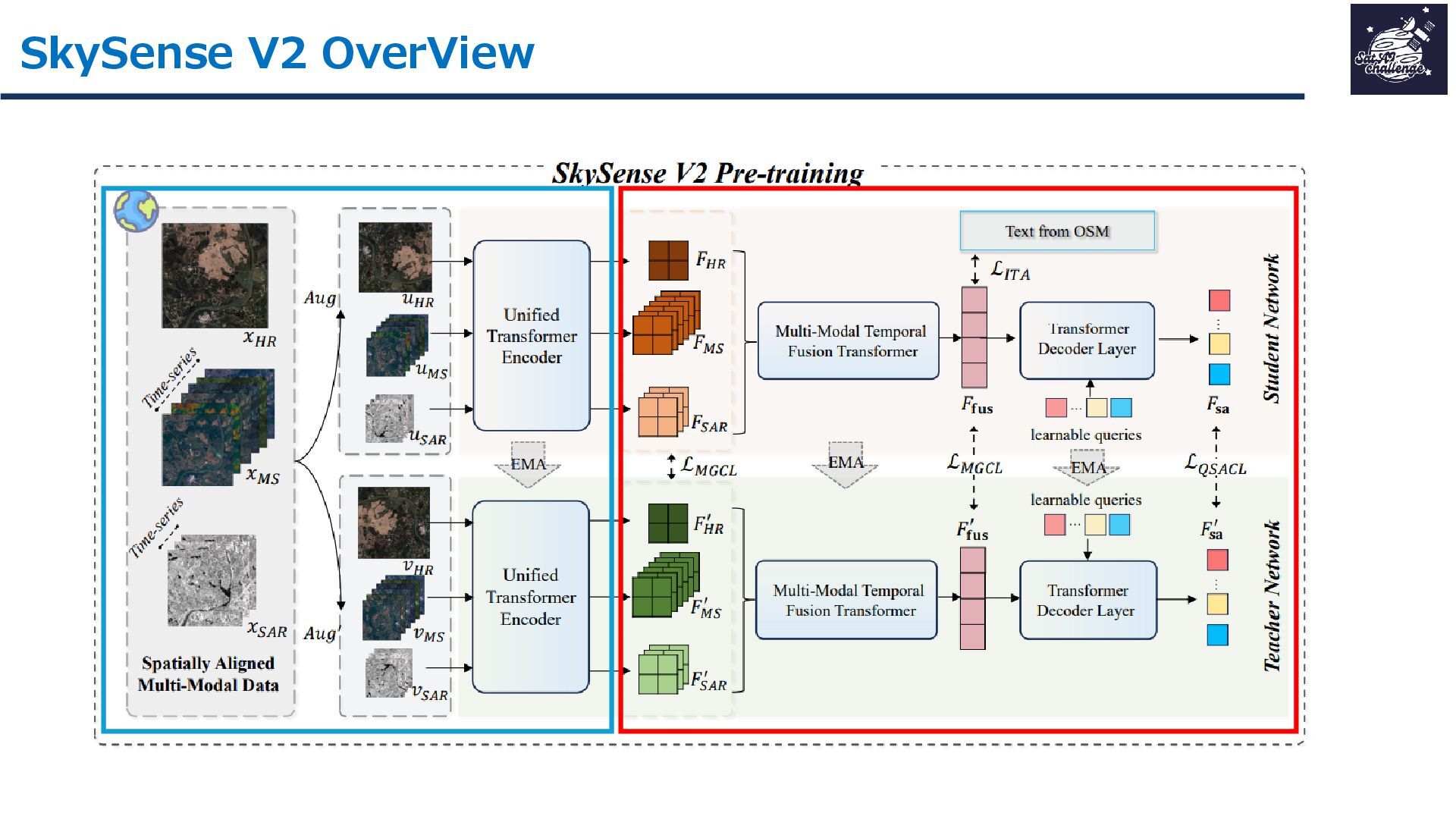
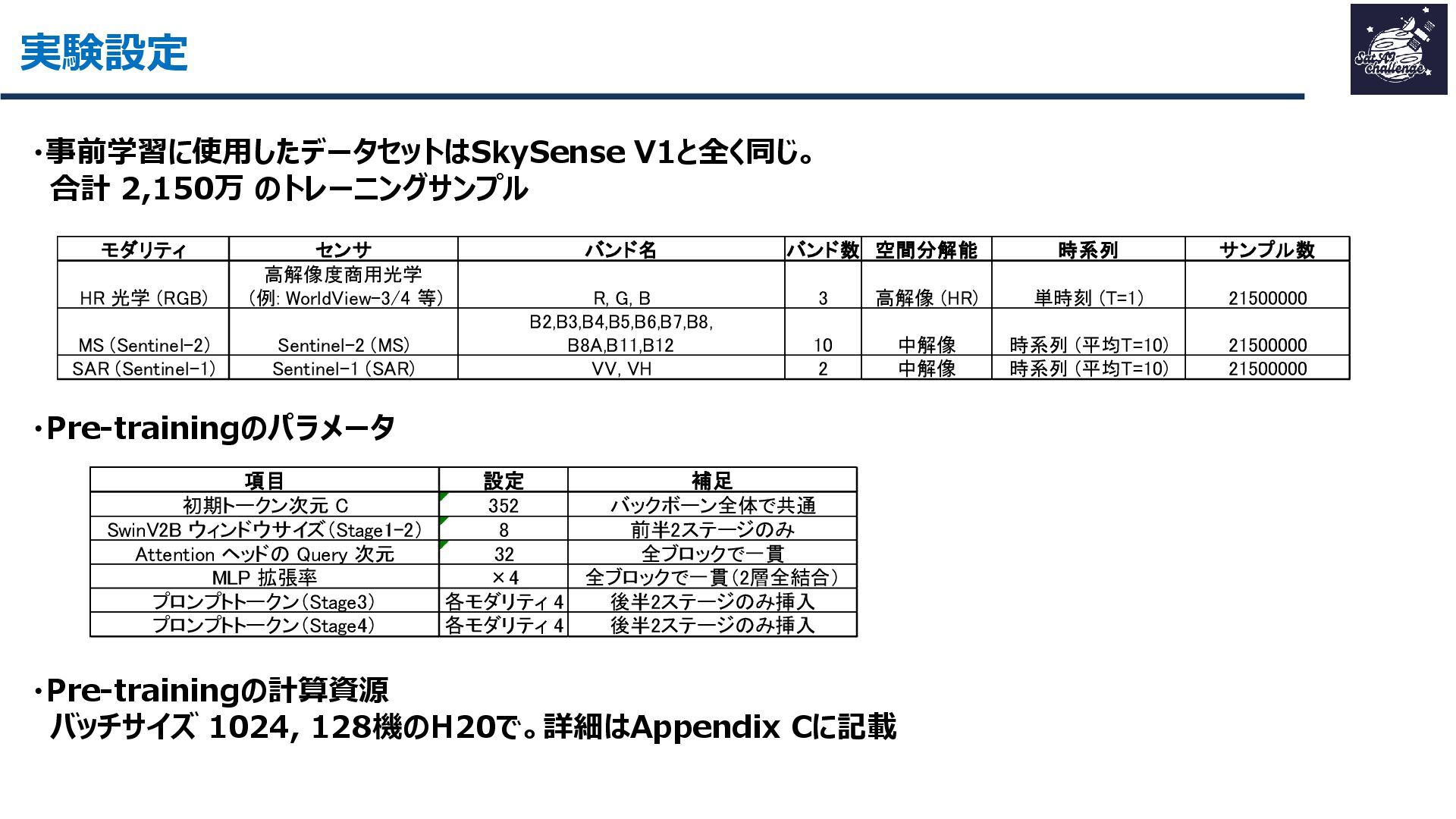
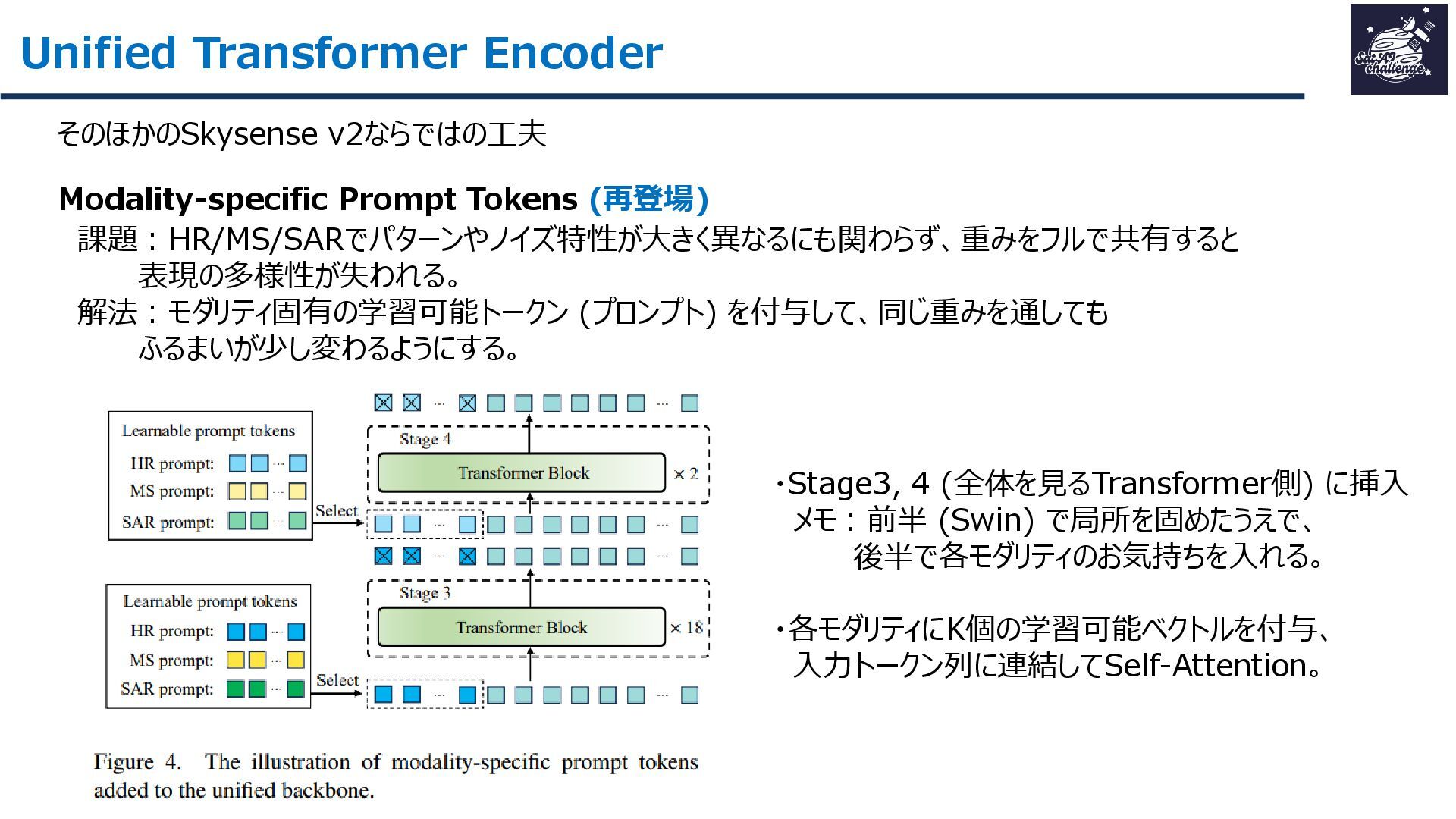
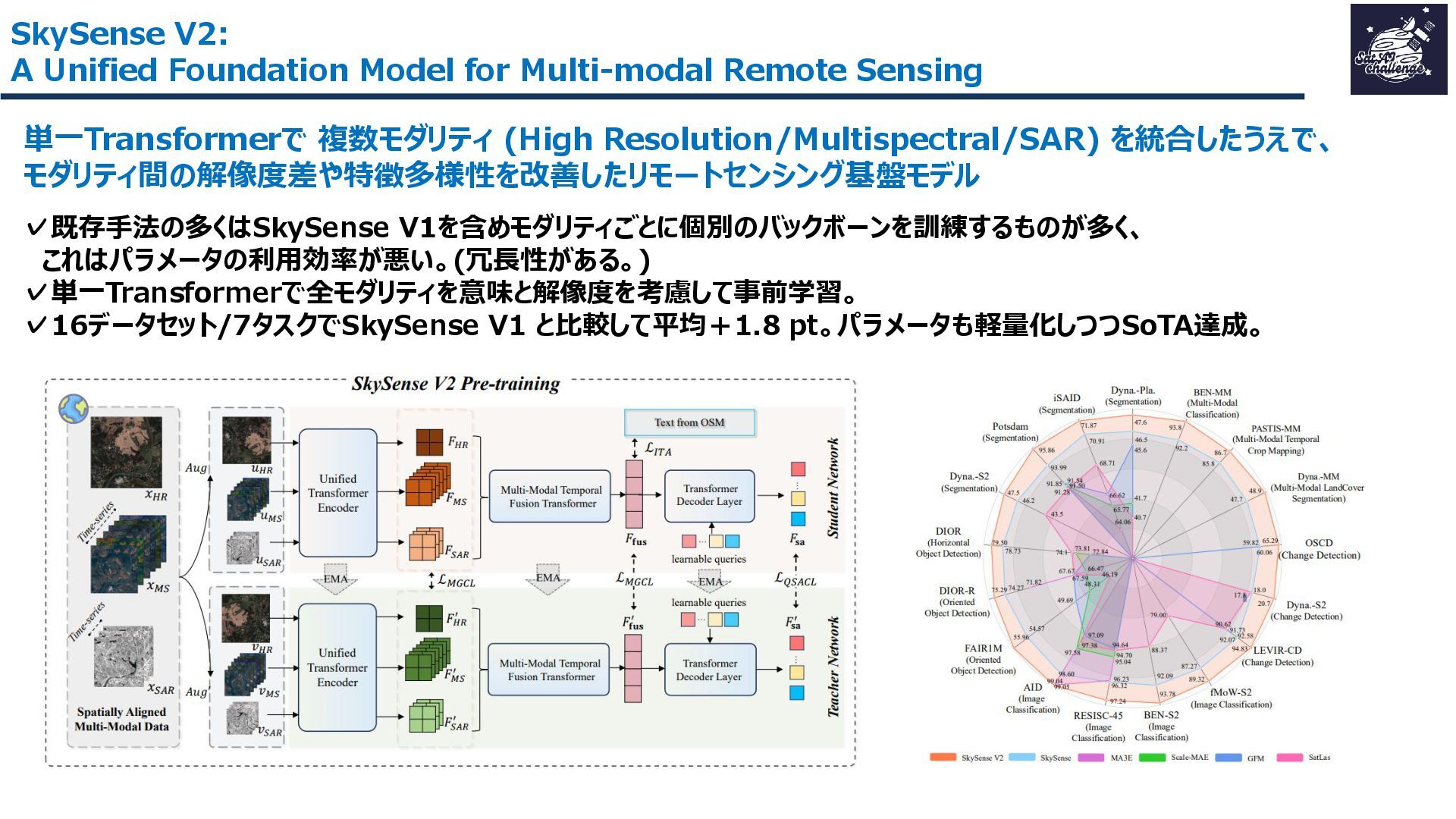
紹介する論文は、「SkySense V2: A Unified Foundation Model for Multi-modal Remote Sensing」です。本研究では、高・中空間分解能の光学衛星画像およびSAR衛星画像を、単一のTransformerバックボーンで統合的に処理する基盤モデルを提案しました。従来はモダリティごとに別バックボーンを用いる設計が主流で、パラメータ冗長性やモデル肥大化が課題でした。SkySense V2では、Adaptive Patch Mergingやモダリティプロンプトなどの工夫により、複数解像度・複数モダリティを一体的に扱うことを可能にしています。
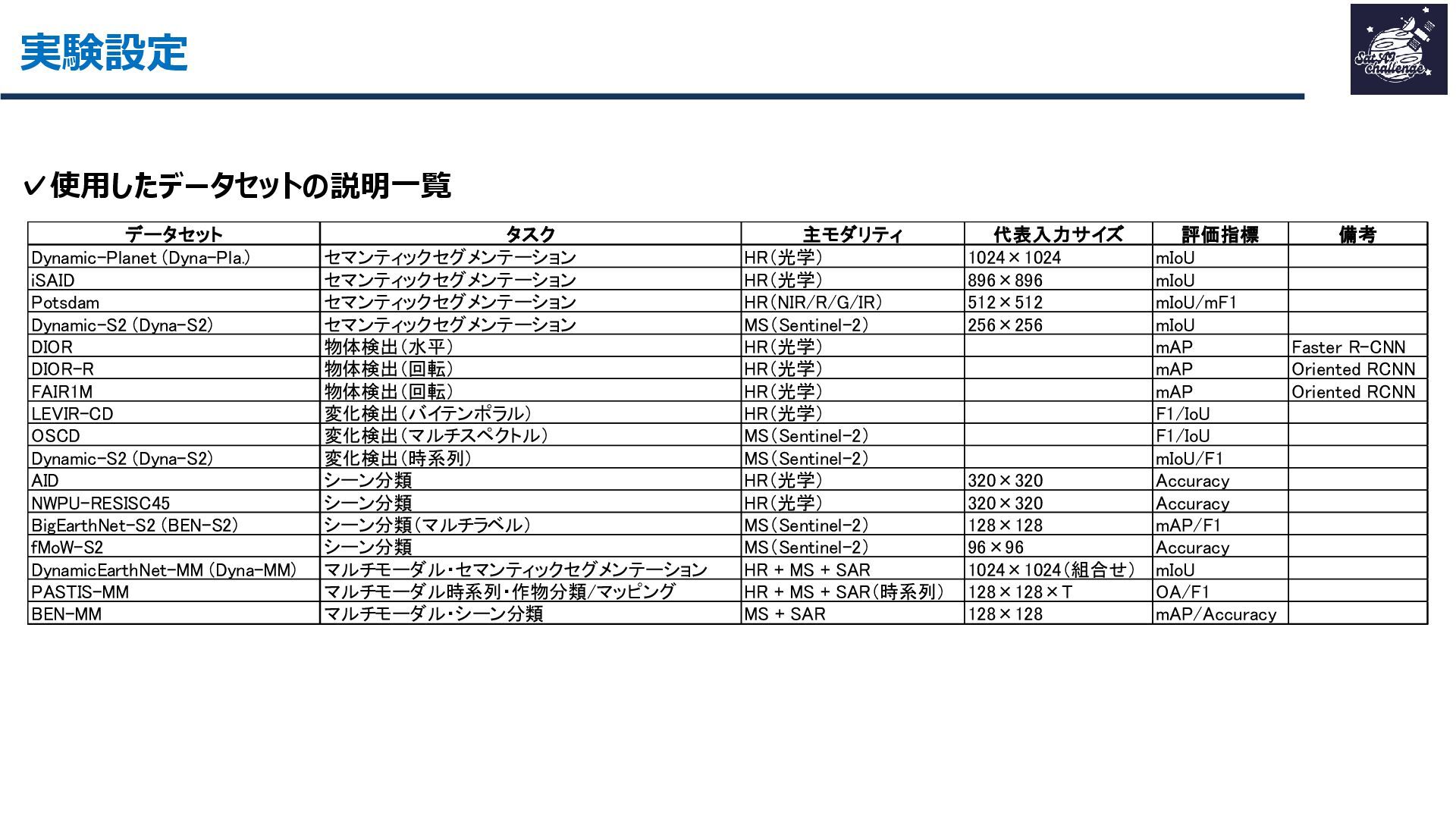
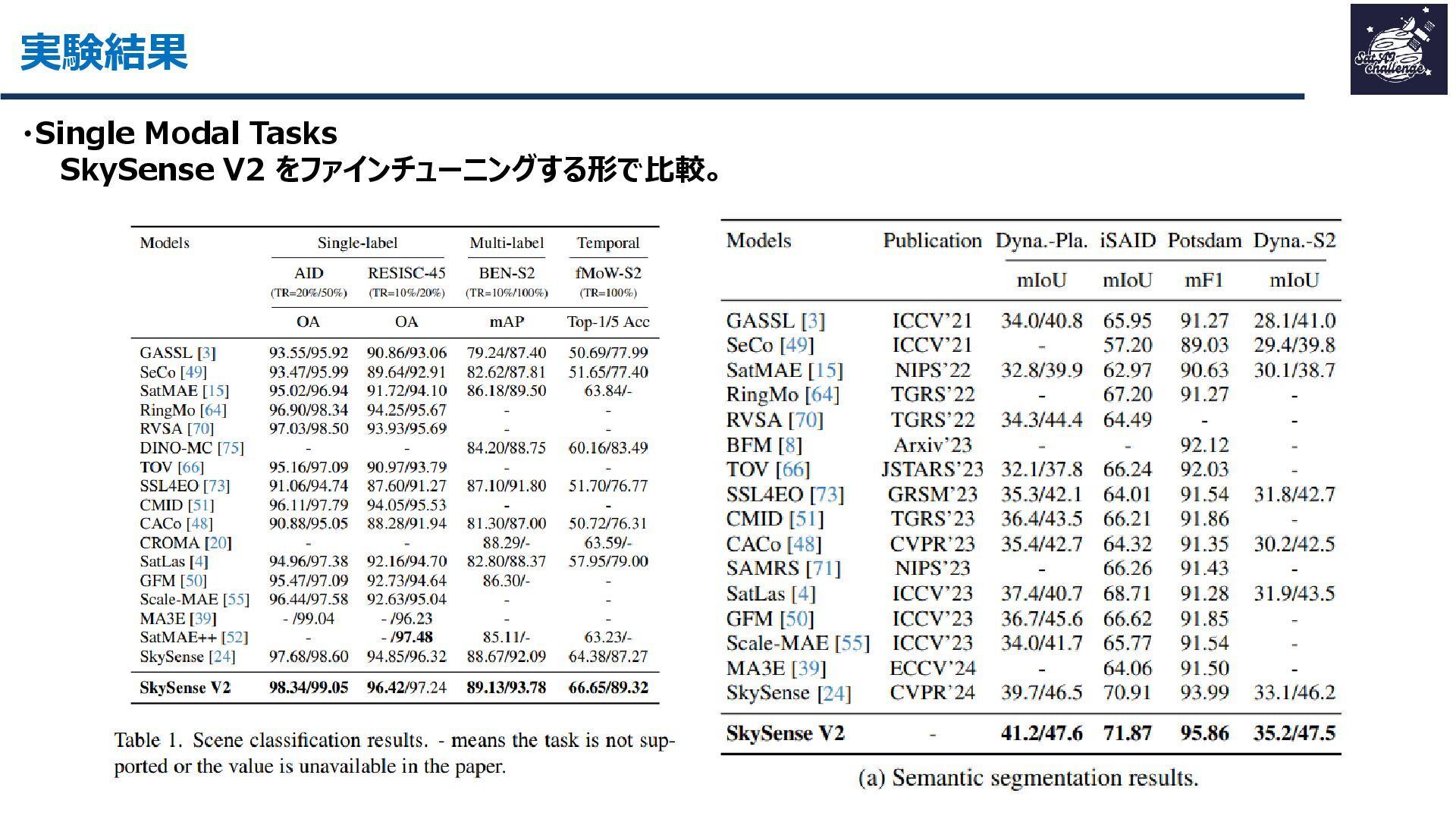
その結果、16データセット・7タスクで平均+1.8ptの性能向上を達成し、軽量かつ汎用的なリモートセンシング基盤モデルとして有効性を示しました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
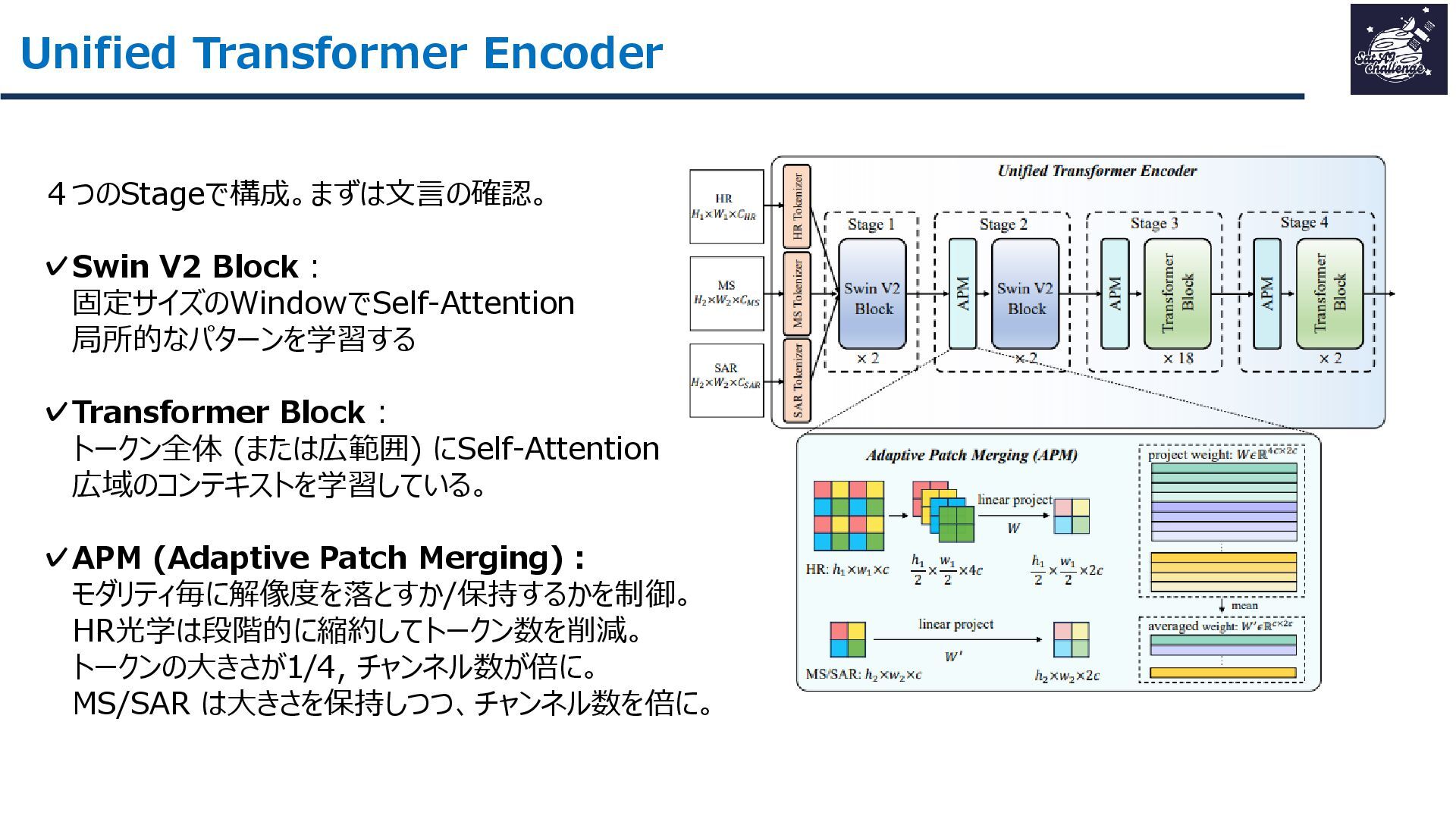{kind=link}
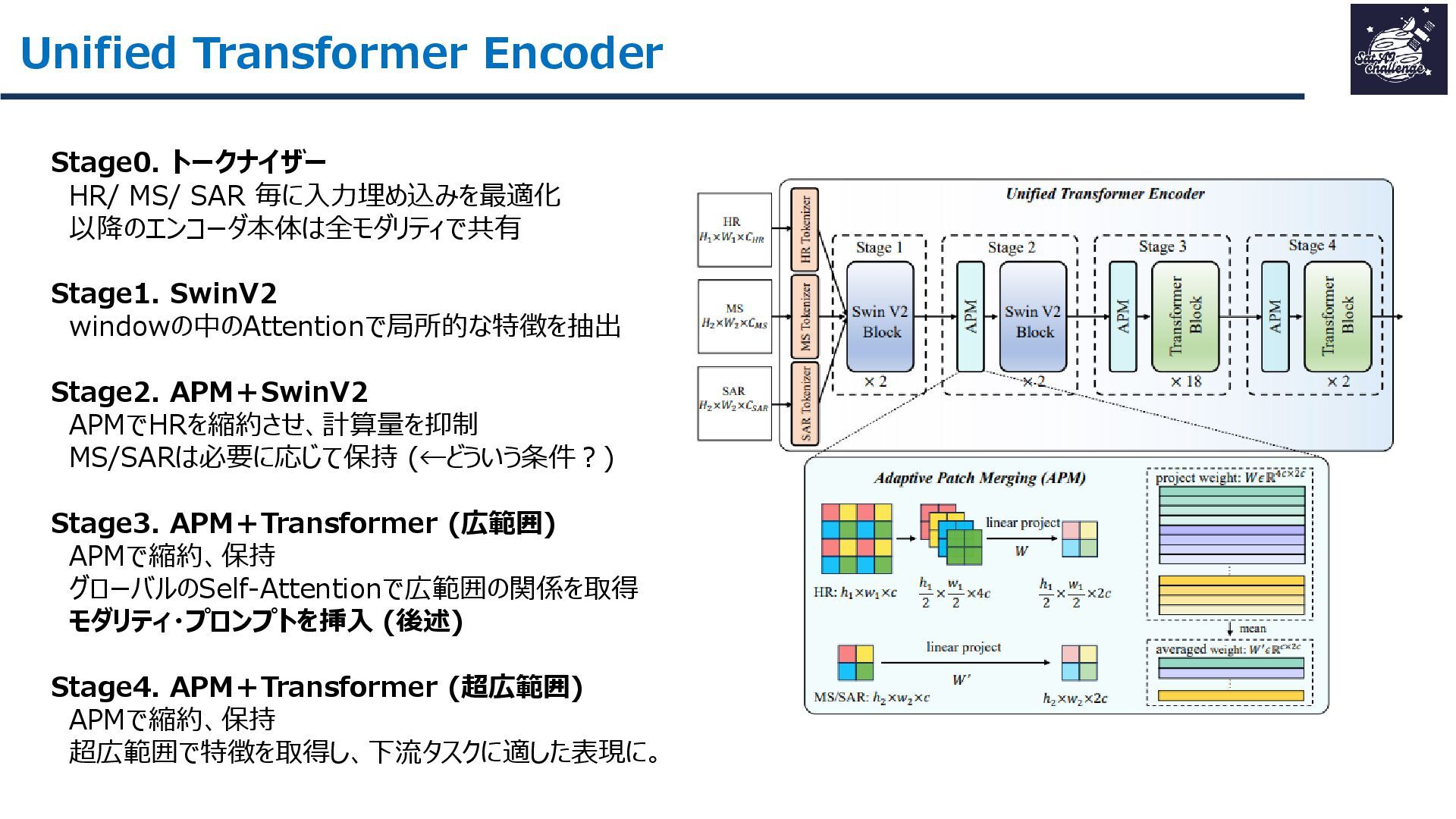{kind=link}
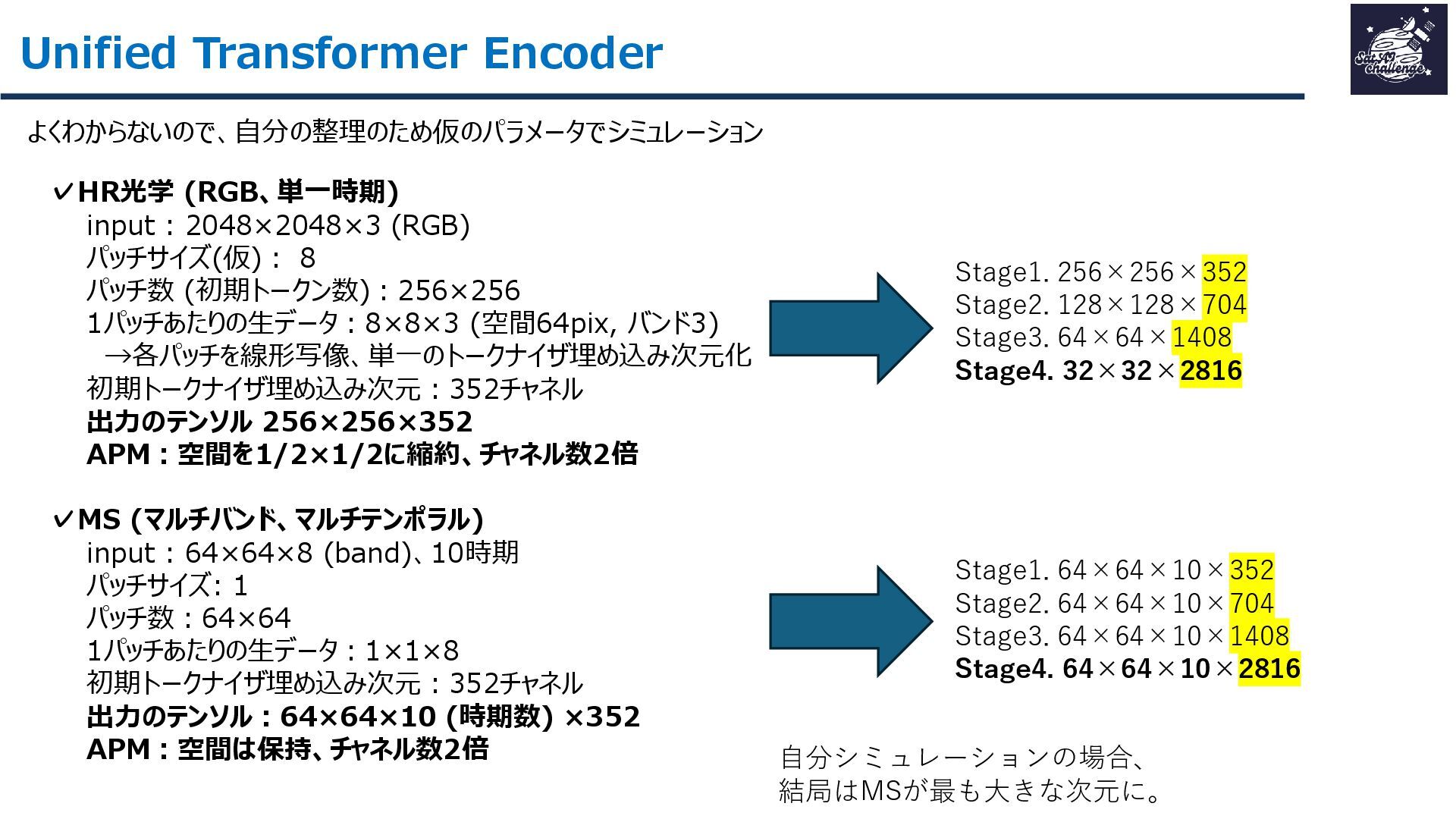{kind=link}
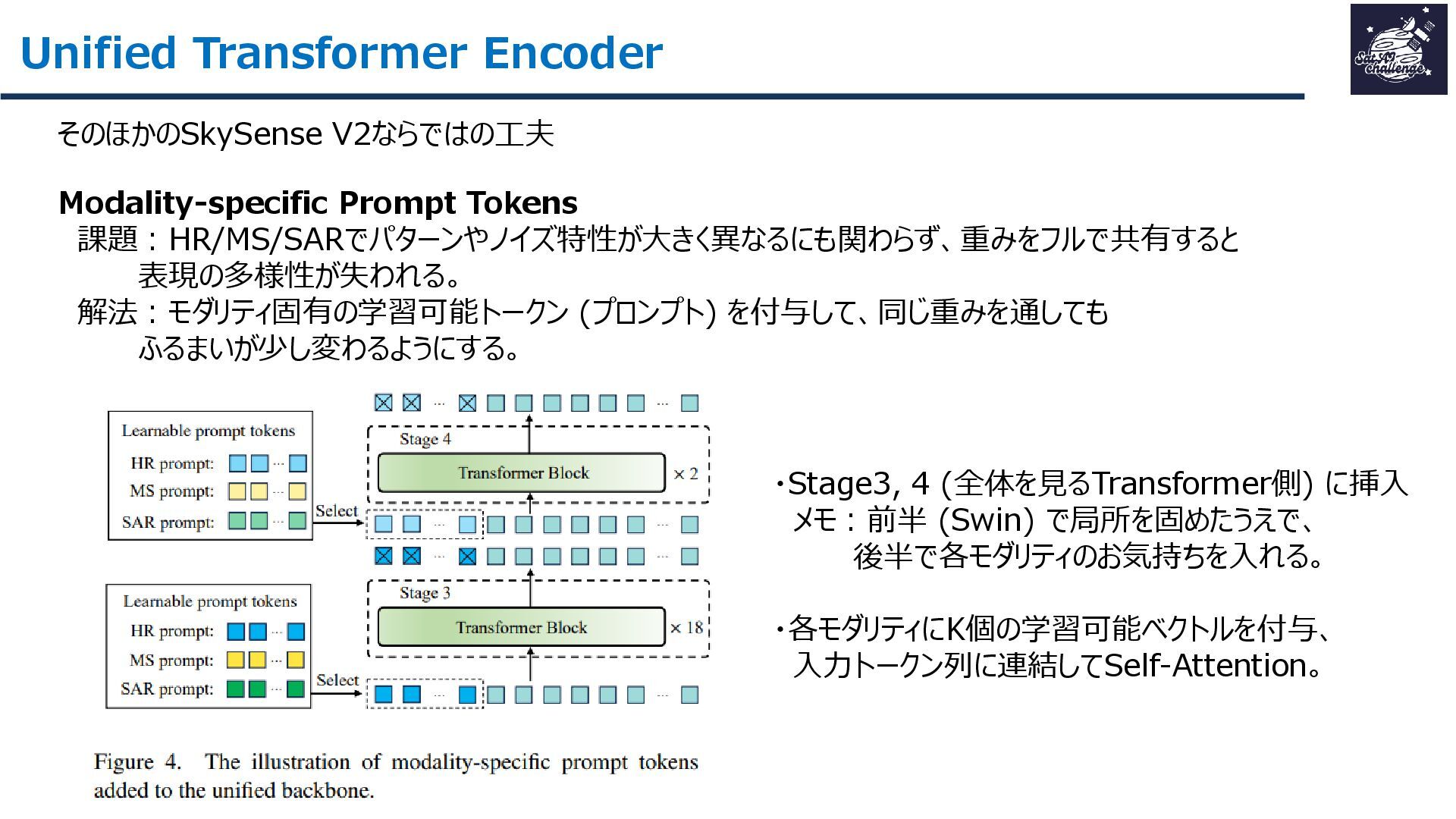{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
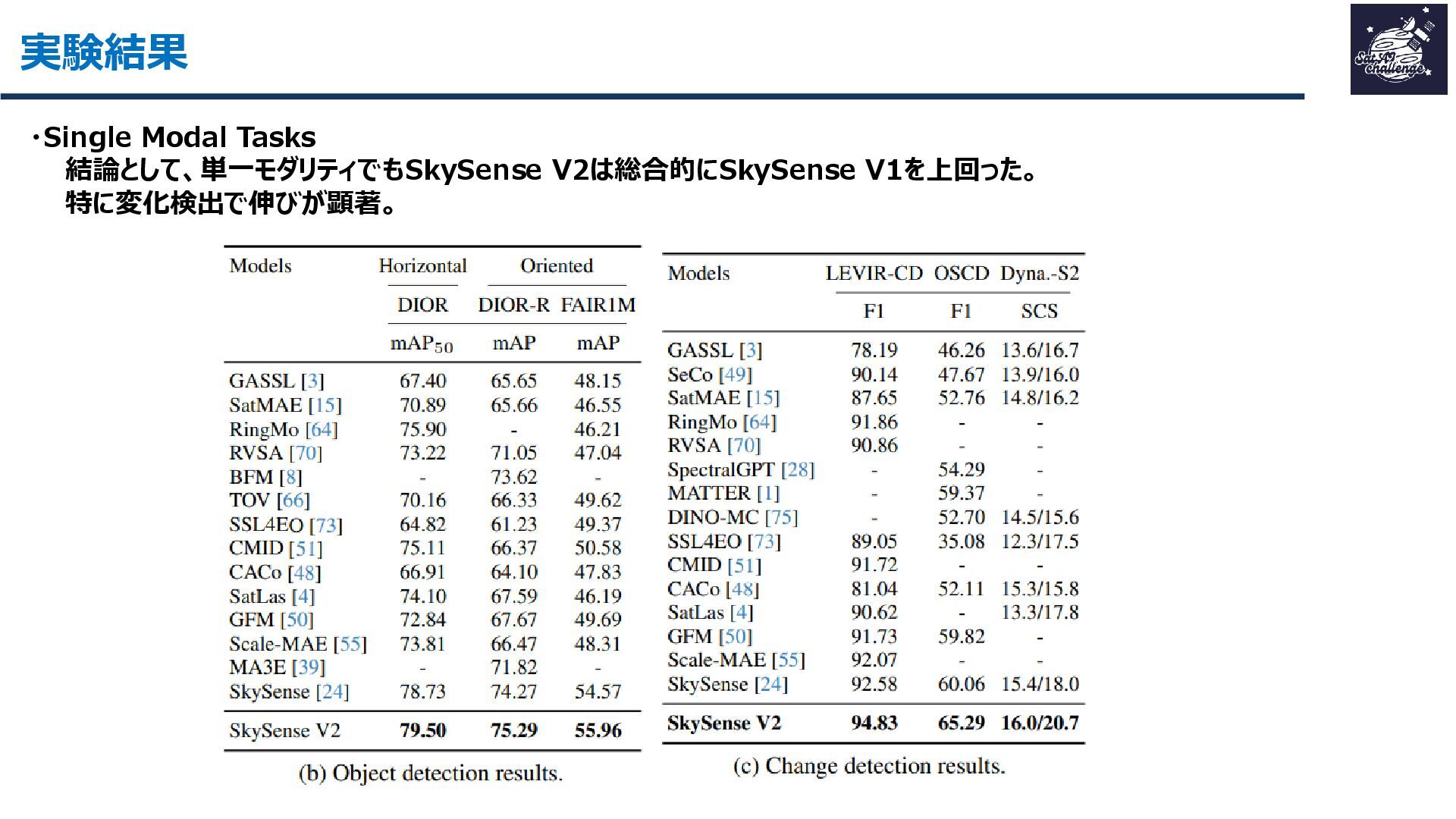{kind=link}
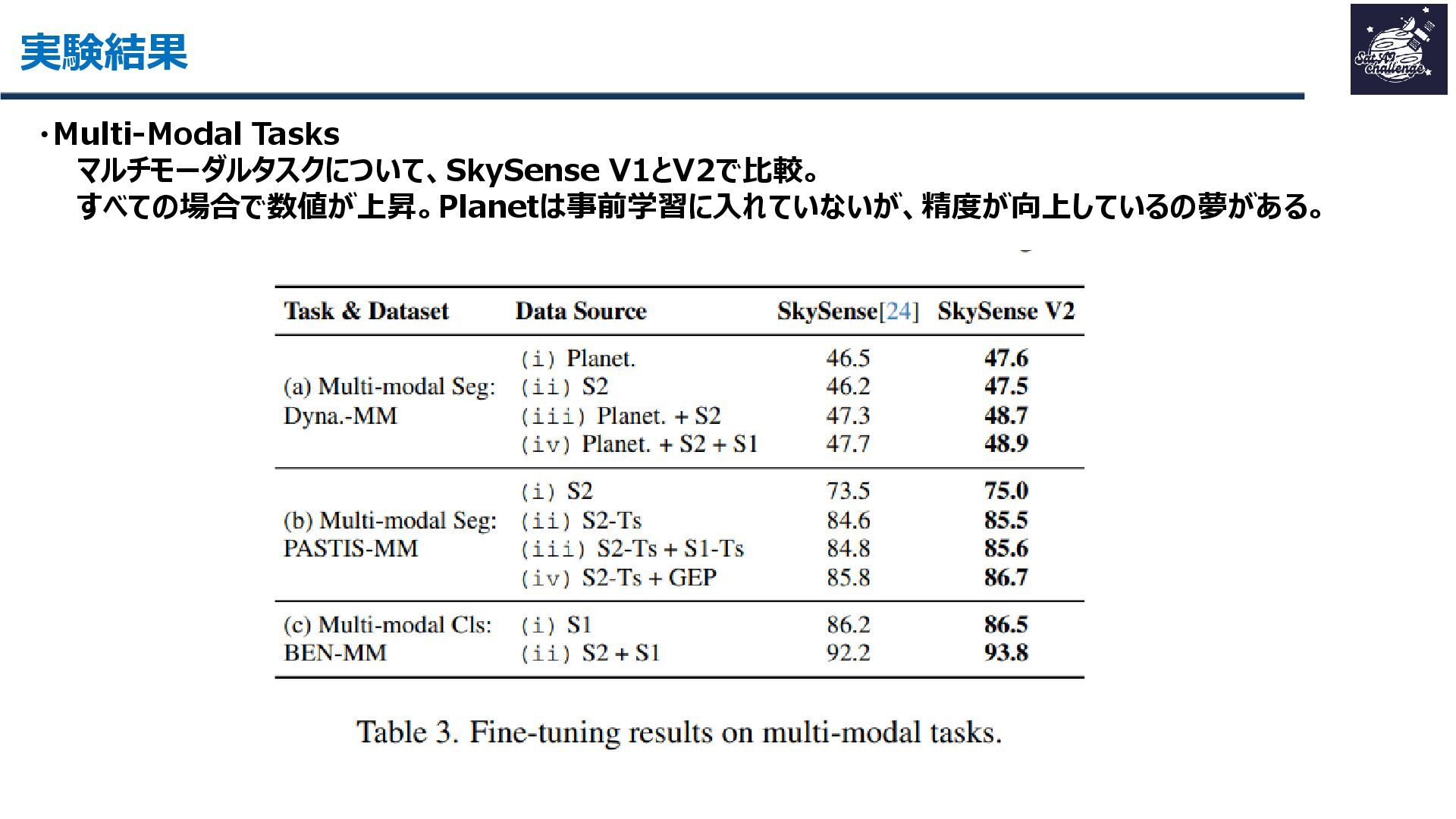{kind=link}
{kind=link}
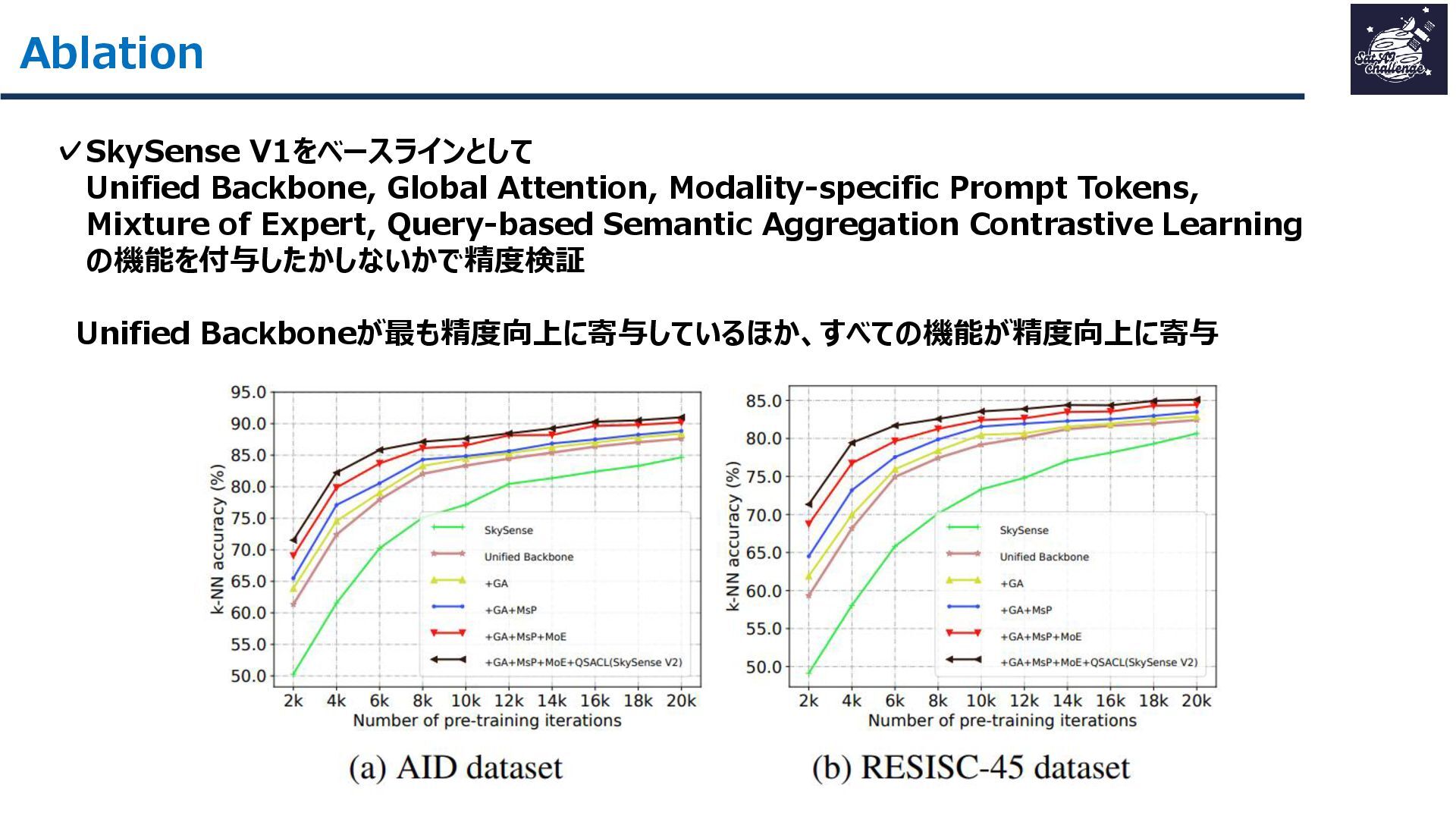{kind=link}
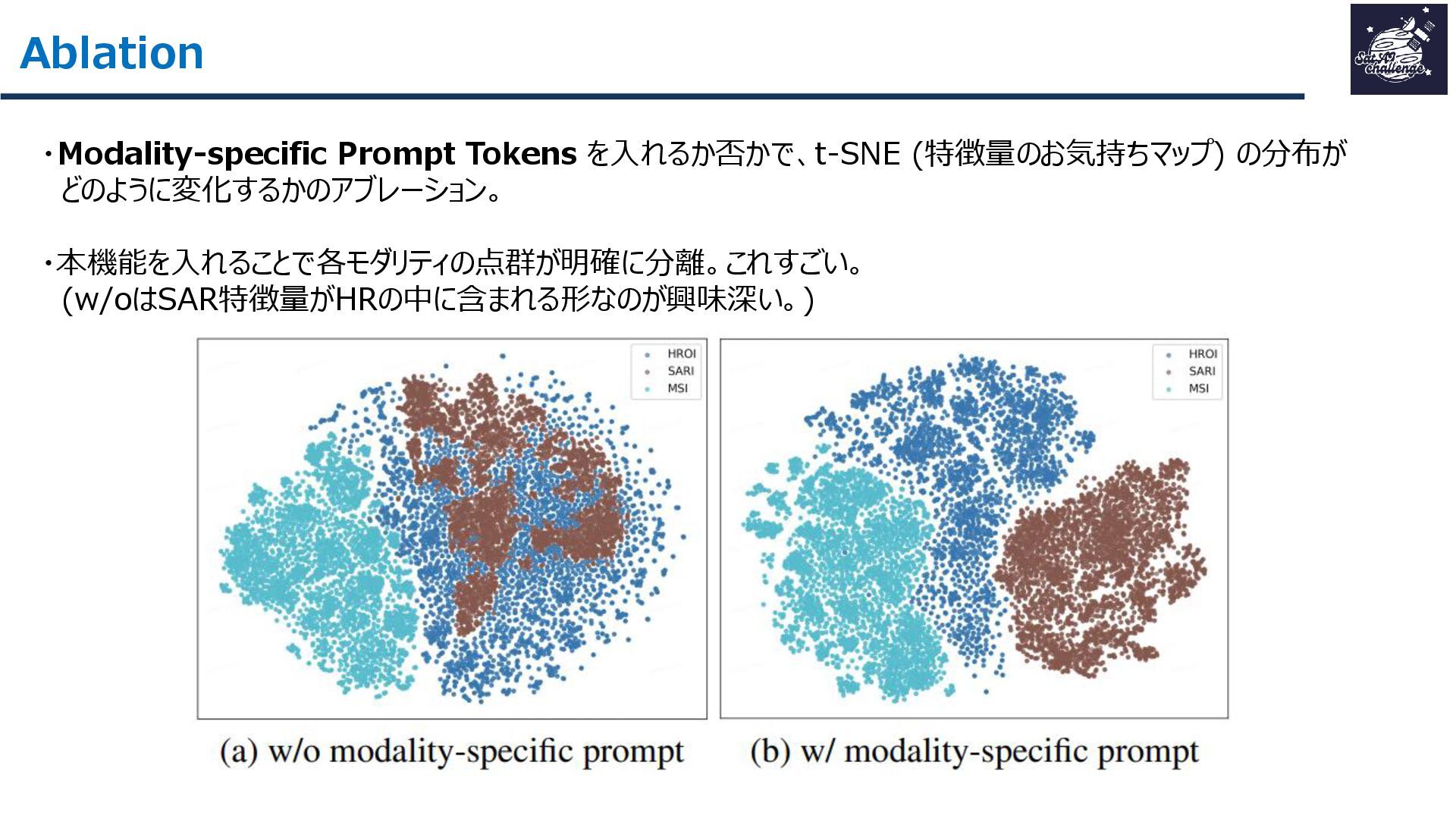{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}