本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
紹介する論文は「SegEarth-OV: Towards Training-Free Open-Vocabulary Segmentation for Remote Sensing Images」です。この研究では、
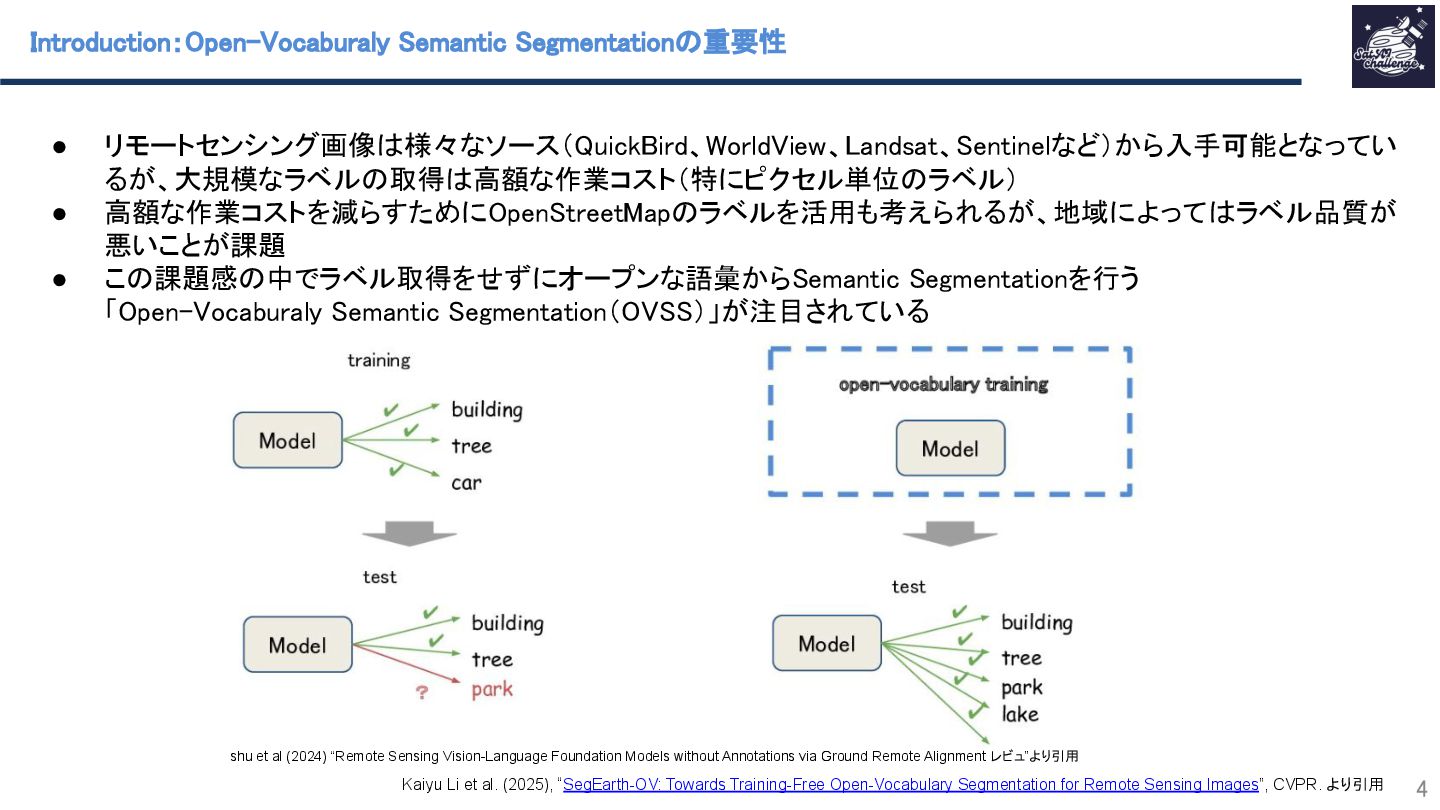
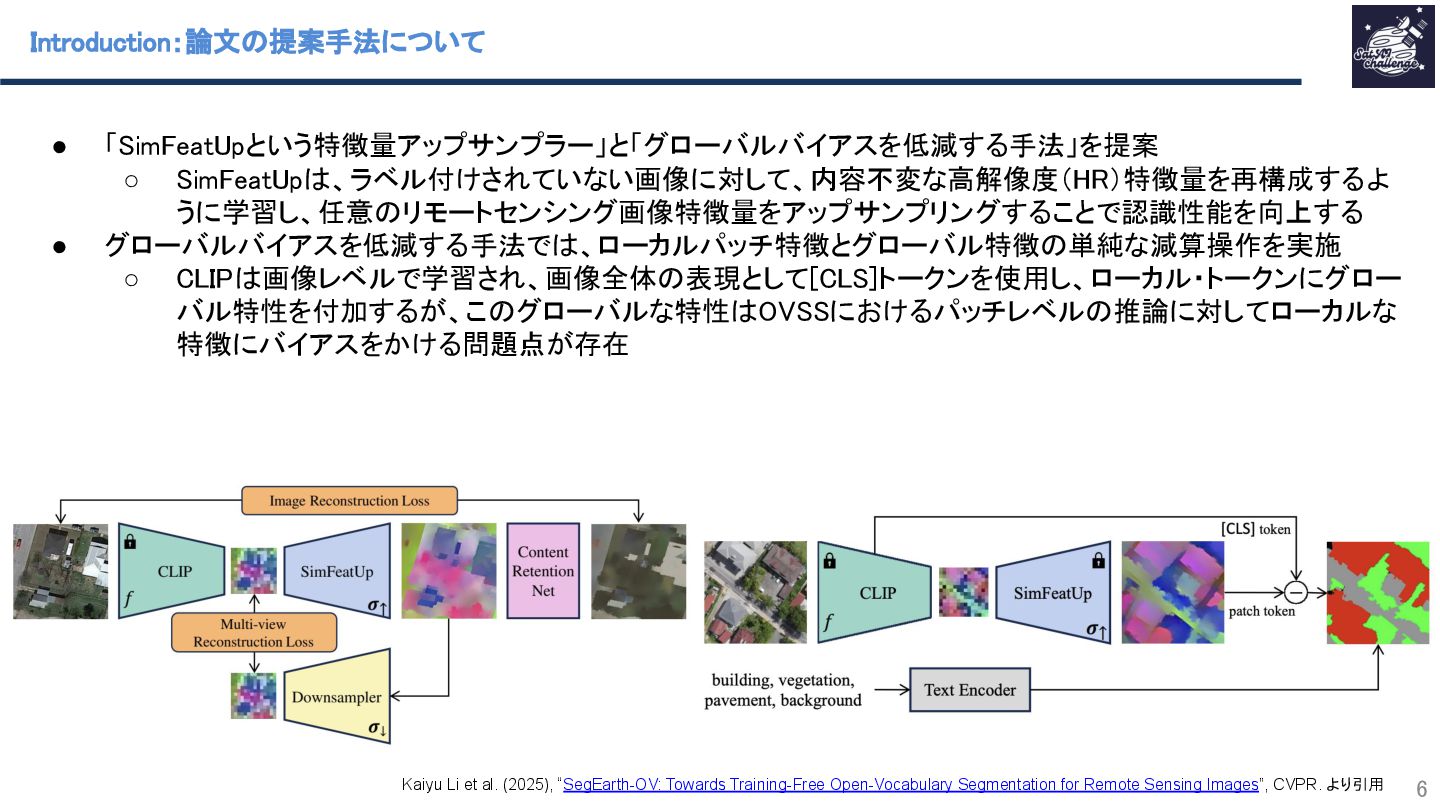
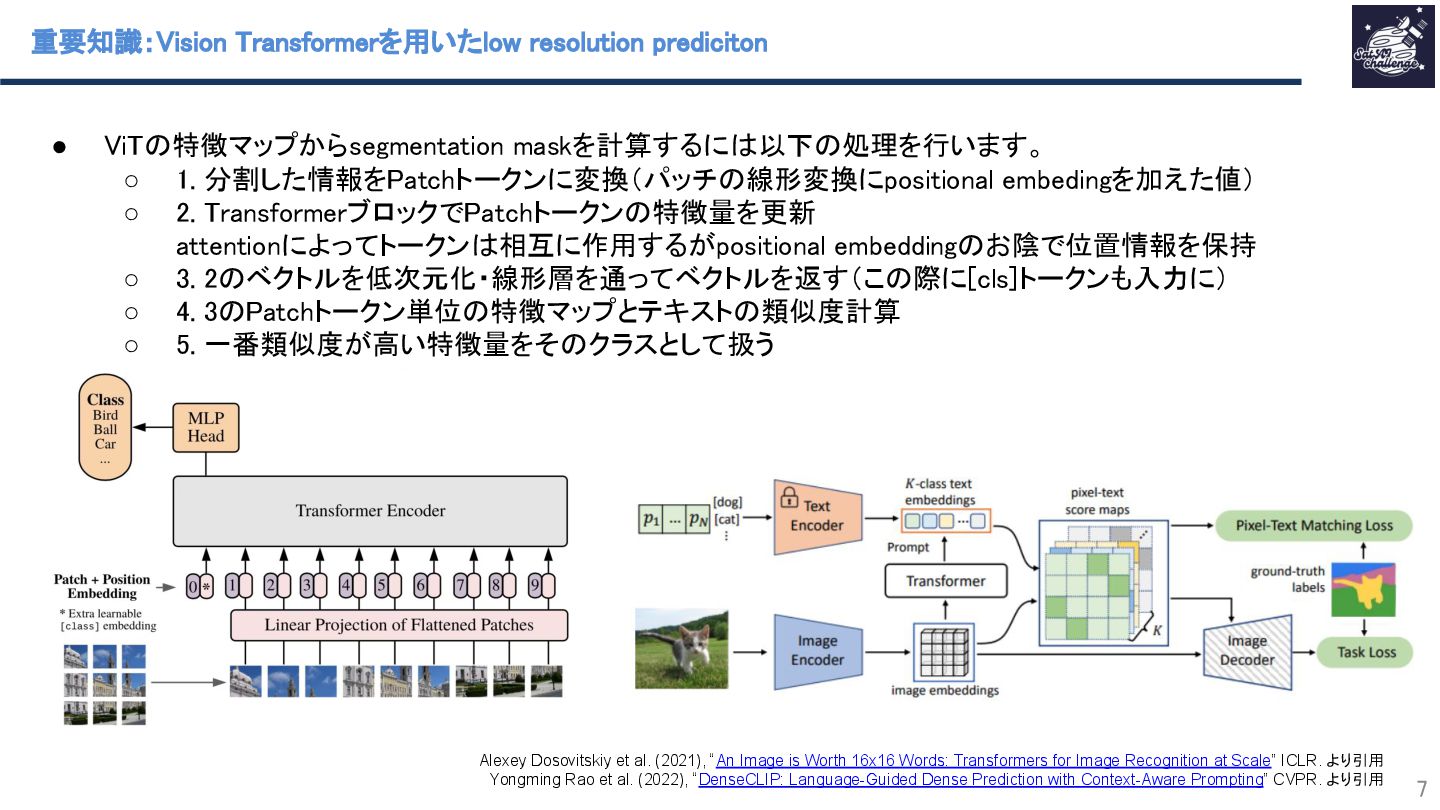
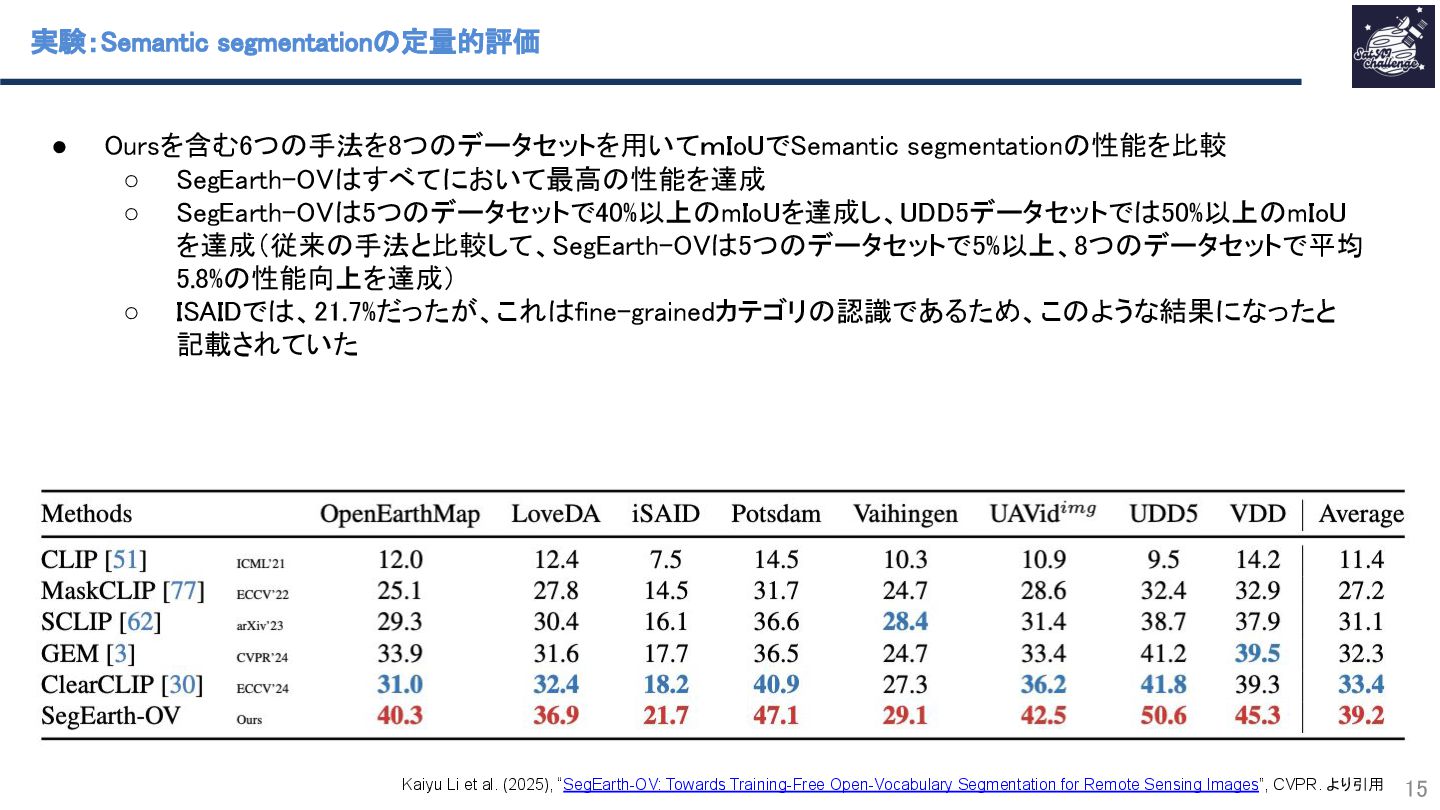
リモートセンシングで利用されるOpen-Vocabulary Semantic Segmentation(OVSS) のCLIPベースの手法の特徴量マップの解像度を小さくしすぎている点に着目し、その特徴マップを高解像度化するSimFeatUpという手法を提案します。その他にも、OVSSの性能を向上するために、Transformerモデルの[class]トークンに由来するグローバルバイアスの低減手法も提案しています。多くのSemantic segmentation datasetでの実験により、特徴量マップの高解像度化がOVSSの性能向上に寄与することを示します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• CLIPの学習フェーズ:画像全体のグローバル情報を含む[CLS]トークンが、対照学習によってマルチモーダル 空間へのテキスト埋め込みと最適化 • OVSS推論フェーズ:パッチトークンが使用され、推論とギャップが発生 提案手法:グローバルバイアスの緩和 12](https://files.speakerdeck.com/presentations/75c295ae704144ecb47de3bbba239cc7/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
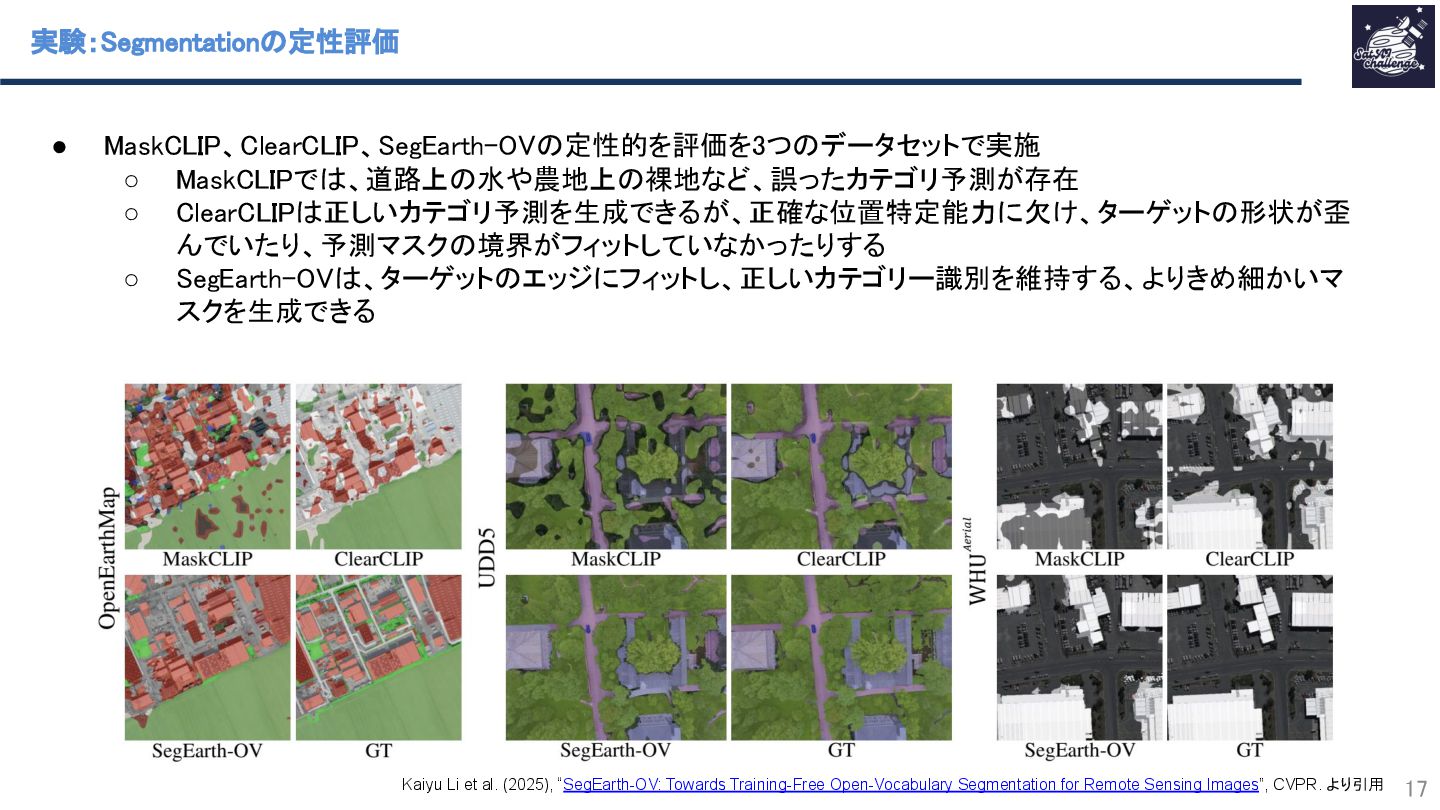{kind=link}
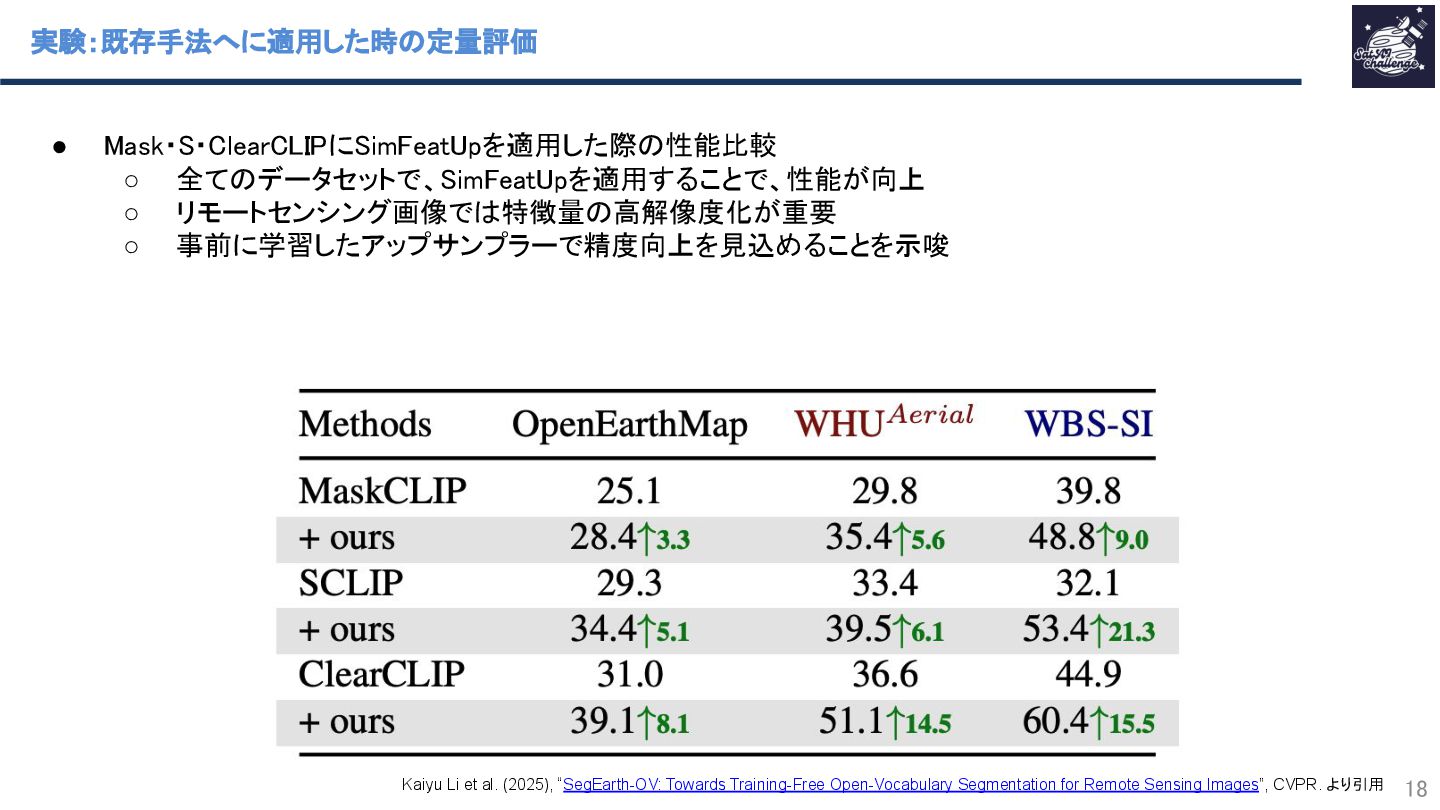{kind=link}
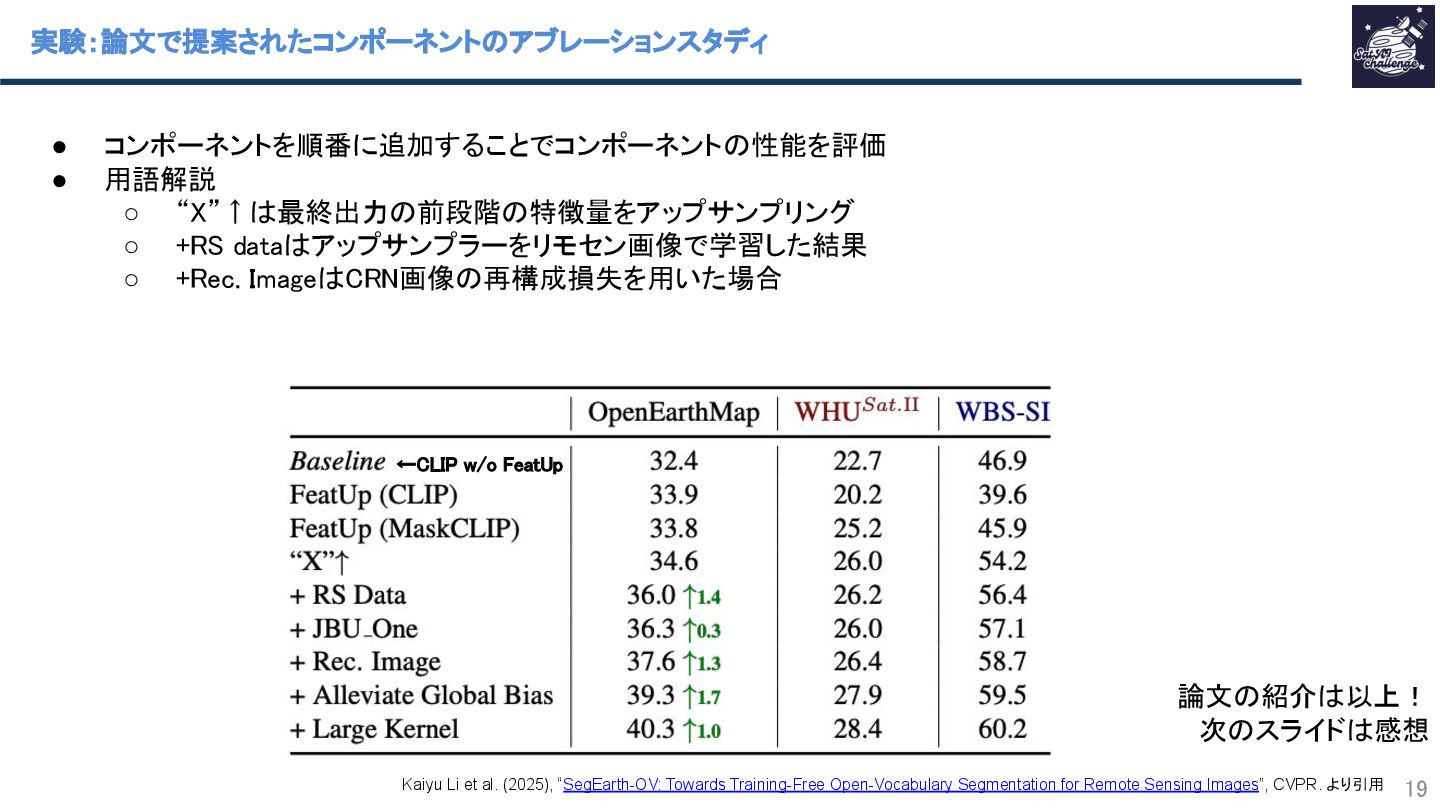{kind=link}
{kind=link}