One-Class SVM (OCSVM) とは?
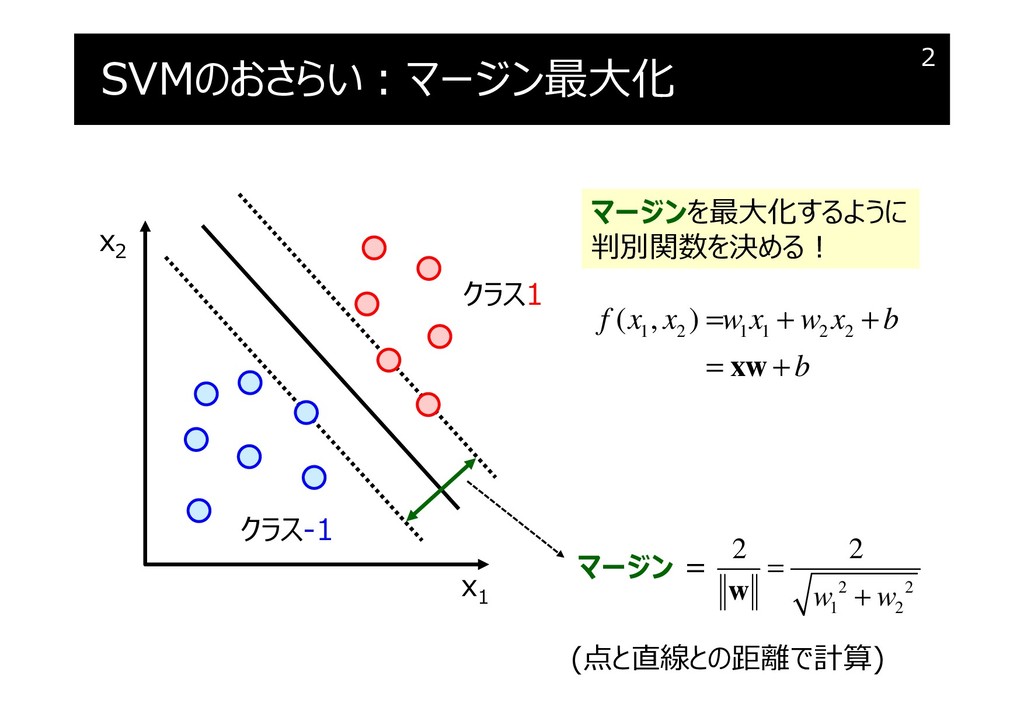
SVMのおさらい:マージン最大化
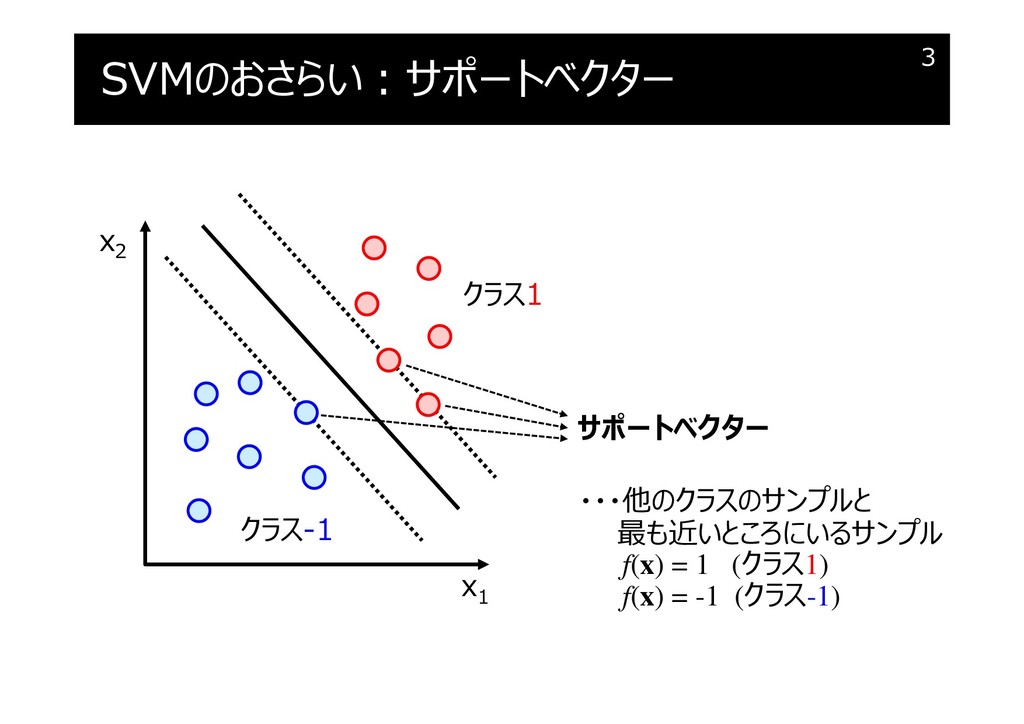
SVMのおさらい:サポートベクター
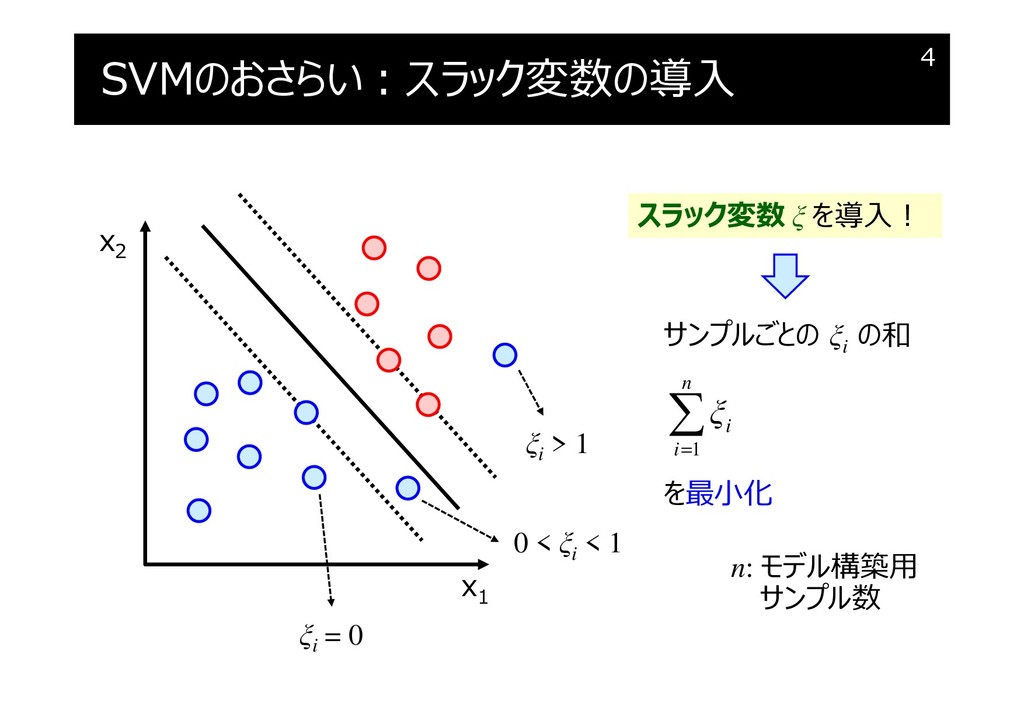
SVMのおさらい:スラック変数の導入
SVMのおさらい:最小化する関数
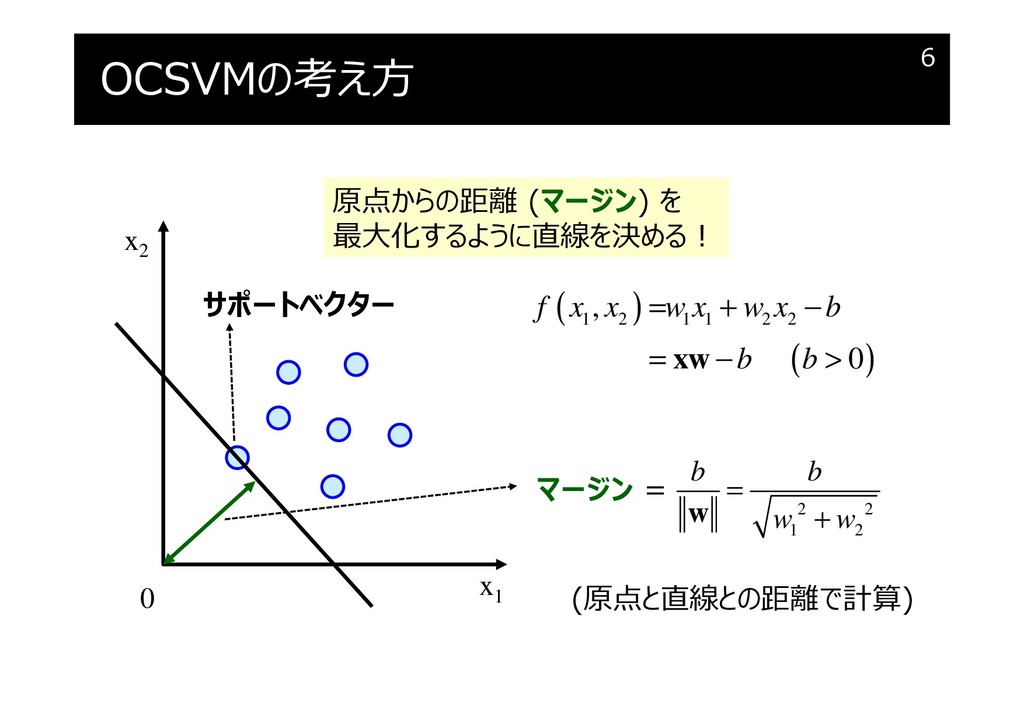
OCSVMの考え方
原点からの距離で大丈夫?
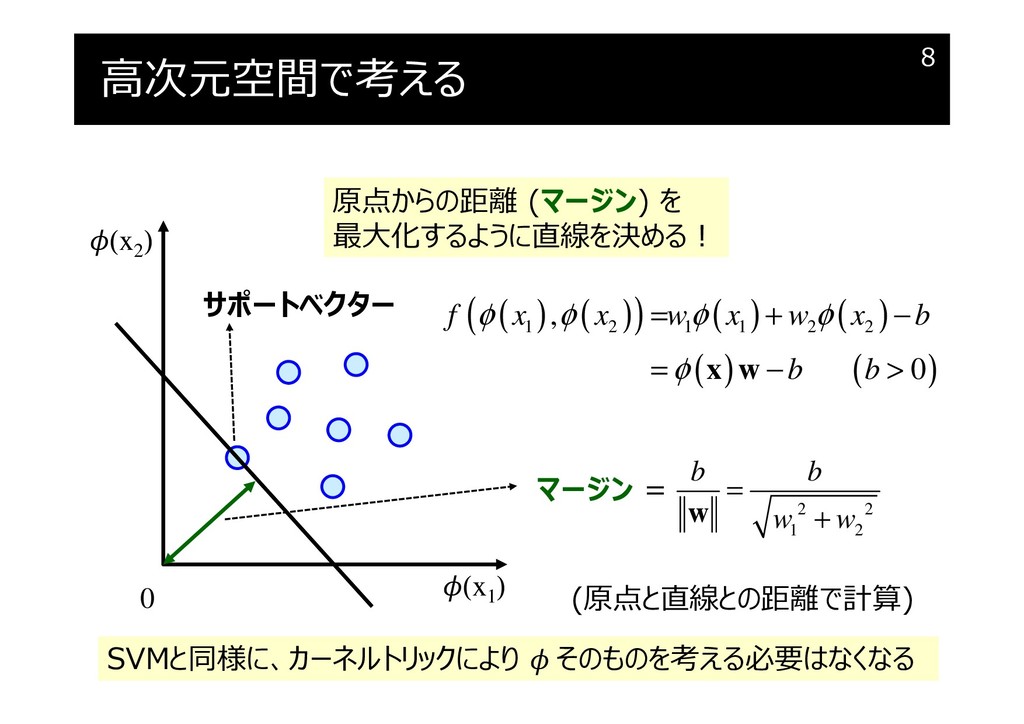
高次元空間で考える
マージンの最大化
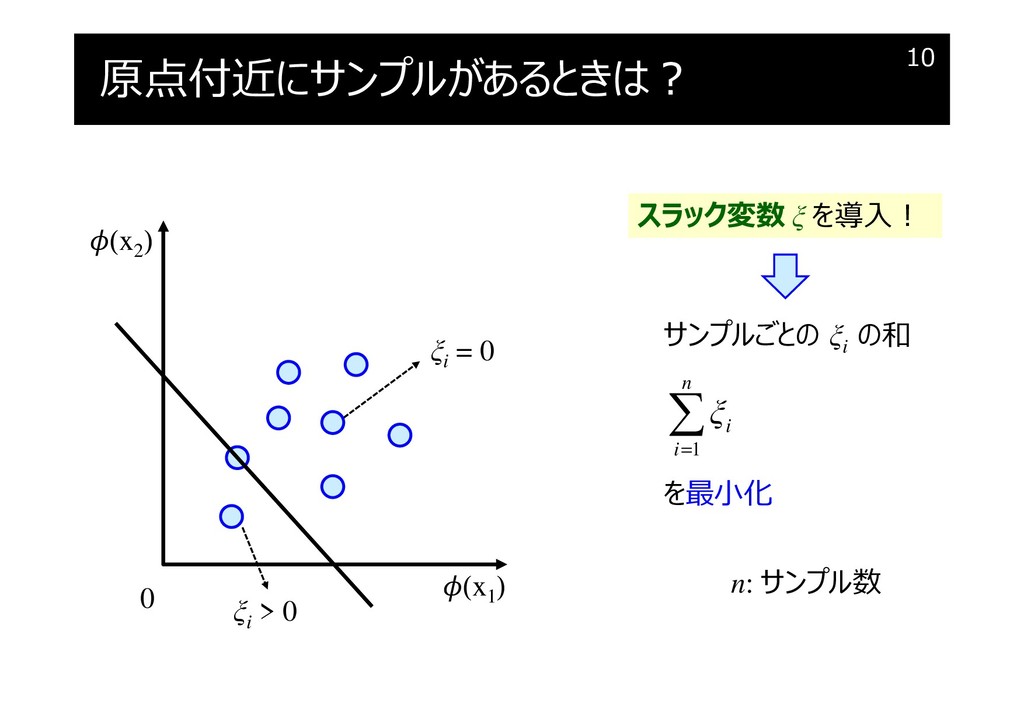
原点付近にサンプルがあるときは?
一緒に最小化
重み w と b を求める
偏微分して0
二次計画問題
直線の式を求める
G の変形
カーネル関数の例
OCSVMのまとめ
OCSVMの使い方
ν, γ の決め方
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![OCSVMのまとめ Support Vector Machine (SVM) [1] を領域推定問題に応用 18 0 写像](https://files.speakerdeck.com/presentations/06d1252538ce4613810ce1320788fa55/slide_18.jpg){kind=link}
{kind=link}
{kind=link}