tree_test=# WITH RECURSIVE temp(log_id) AS tree_test-# (SELECT log_id FROM log_relation1 WHERE log_id = 101 tree_test(# UNION ALL tree_test(# SELECT a.log_id FROM log_relation1 a, temp b tree_test(# WHERE a.parent_log_id = b.log_id) tree_test-# SELECT log_id FROM temp; log_id -------- 101 102 103 104 105 106 (6 rows) 【注】カラム名は英数字と記号、ID列は数値に変更
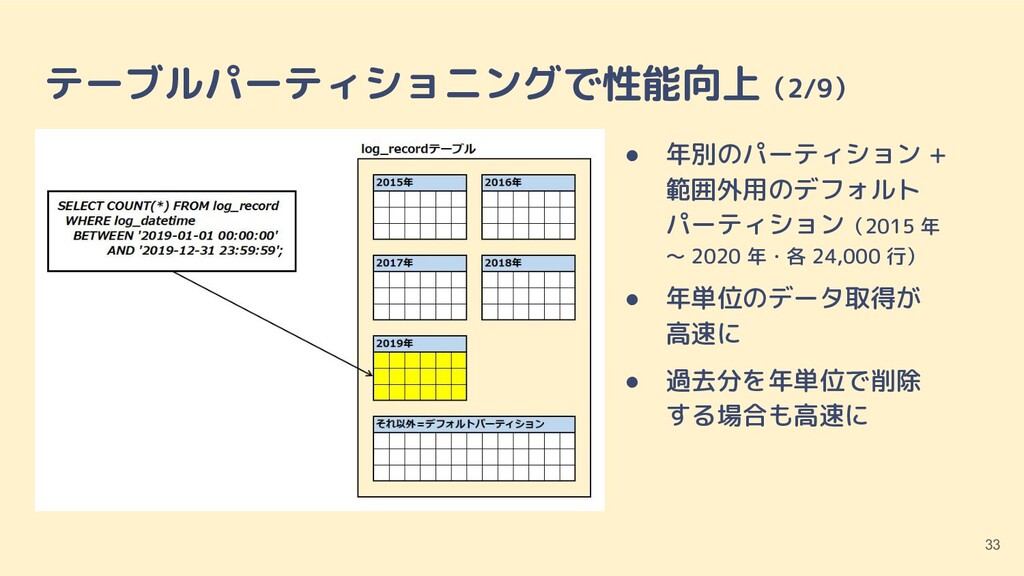
are now connected to database "partition_test" as user "postgres". partition_test=# CREATE TABLE log_record ( partition_test(# log_id SERIAL NOT NULL, partition_test(# log_datetime TIMESTAMP NOT NULL, partition_test(# log_text VARCHAR(500) NOT NULL partition_test(# ) partition_test-# PARTITION BY RANGE (log_datetime); CREATE TABLE partition_test=# CREATE TABLE log_record_default PARTITION OF log_record DEFAULT; CREATE TABLE partition_test=# CREATE TABLE log_record_2015 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2015-01-01 00:00:00') TO ('2016-01-01 00:00:00'); CREATE TABLE テーブルパーティショニングで性能向上(3/9) 34
are now connected to database "partition_test" as user "postgres". partition_test=# CREATE TABLE log_record ( partition_test(# log_id SERIAL NOT NULL, partition_test(# log_datetime TIMESTAMP NOT NULL, partition_test(# log_text VARCHAR(500) NOT NULL partition_test(# ) partition_test-# PARTITION BY RANGE (log_datetime); CREATE TABLE partition_test=# CREATE TABLE log_record_default PARTITION OF log_record DEFAULT; CREATE TABLE partition_test=# CREATE TABLE log_record_2015 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2015-01-01 00:00:00') TO ('2016-01-01 00:00:00'); CREATE TABLE テーブルパーティショニングで性能向上(3/9) 35 日時(タイムスタンプ)で パーティショニングを試す
are now connected to database "partition_test" as user "postgres". partition_test=# CREATE TABLE log_record ( partition_test(# log_id SERIAL NOT NULL, partition_test(# log_datetime TIMESTAMP NOT NULL, partition_test(# log_text VARCHAR(500) NOT NULL partition_test(# ) partition_test-# PARTITION BY RANGE (log_datetime); CREATE TABLE partition_test=# CREATE TABLE log_record_default PARTITION OF log_record DEFAULT; CREATE TABLE partition_test=# CREATE TABLE log_record_2015 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2015-01-01 00:00:00') TO ('2016-01-01 00:00:00'); CREATE TABLE テーブルパーティショニングで性能向上(3/9) 36 日時(タイムスタンプ)で パーティショニングを試す ↓範囲外はデフォルトパーティション
FOR VALUES FROM ('2016-01-01 00:00:00') TO ('2017-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2017 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2017-01-01 00:00:00') TO ('2018-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2018 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2018-01-01 00:00:00') TO ('2019-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2019 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2019-01-01 00:00:00') TO ('2020-01-01 00:00:00'); CREATE TABLE partition_test=# ALTER TABLE log_record ADD PRIMARY KEY (log_id, log_datetime); ALTER TABLE (データINSERT)
FOR VALUES FROM ('2016-01-01 00:00:00') TO ('2017-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2017 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2017-01-01 00:00:00') TO ('2018-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2018 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2018-01-01 00:00:00') TO ('2019-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2019 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2019-01-01 00:00:00') TO ('2020-01-01 00:00:00'); CREATE TABLE partition_test=# ALTER TABLE log_record ADD PRIMARY KEY (log_id, log_datetime); ALTER TABLE (データINSERT) ↑主キーにパーティションキーを含める
no_partition_test You are now connected to database "no_partition_test" as user "postgres". no_partition_test=# CREATE TABLE log_record ( no_partition_test(# log_id SERIAL NOT NULL, no_partition_test(# log_datetime TIMESTAMP NOT NULL, no_partition_test(# log_text VARCHAR(500) NOT NULL no_partition_test(# ); CREATE TABLE no_partition_test=# ALTER TABLE log_record ADD PRIMARY KEY (log_id); ALTER TABLE no_partition_test=# CREATE INDEX ON log_record (log_datetime); CREATE INDEX (データINSERT)
no_partition_test You are now connected to database "no_partition_test" as user "postgres". no_partition_test=# CREATE TABLE log_record ( no_partition_test(# log_id SERIAL NOT NULL, no_partition_test(# log_datetime TIMESTAMP NOT NULL, no_partition_test(# log_text VARCHAR(500) NOT NULL no_partition_test(# ); CREATE TABLE no_partition_test=# ALTER TABLE log_record ADD PRIMARY KEY (log_id); ALTER TABLE no_partition_test=# CREATE INDEX ON log_record (log_datetime); CREATE INDEX (データINSERT) 比較用に非パーティショニング のテーブルも用意する 全く同じデータをINSERTする
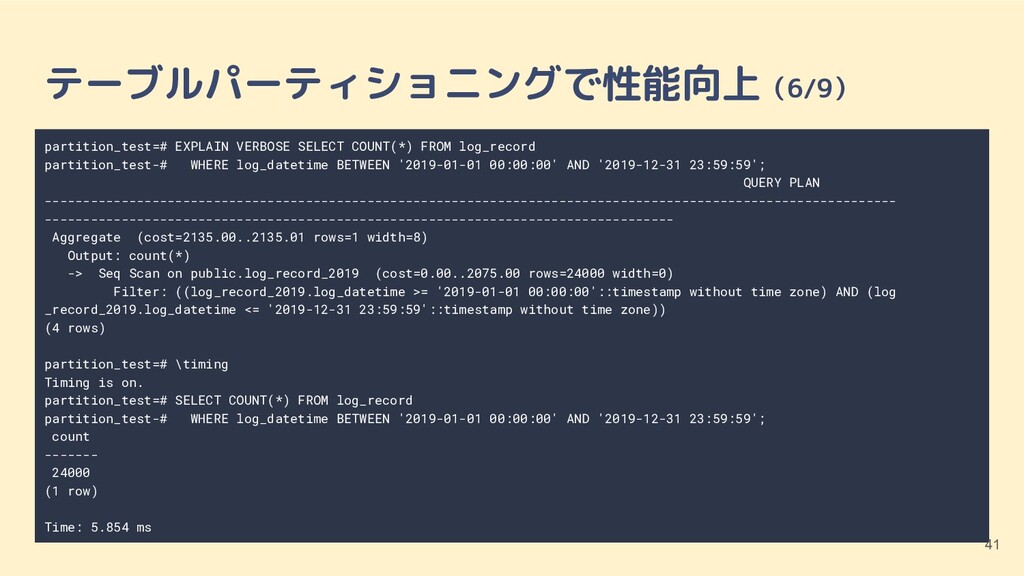
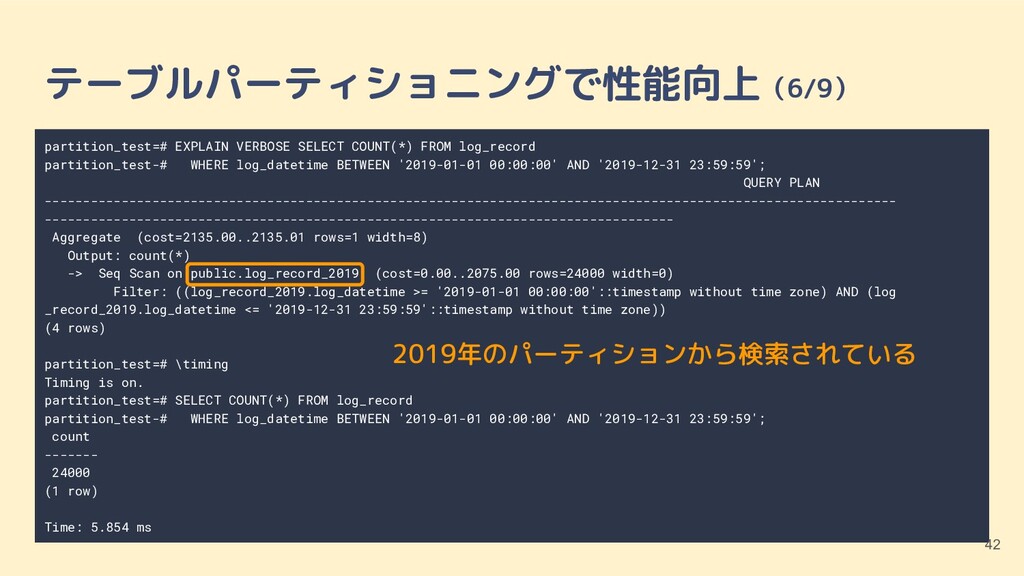
BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------- Aggregate (cost=2135.00..2135.01 rows=1 width=8) Output: count(*) -> Seq Scan on public.log_record_2019 (cost=0.00..2075.00 rows=24000 width=0) Filter: ((log_record_2019.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log _record_2019.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (4 rows) partition_test=# \timing Timing is on. partition_test=# SELECT COUNT(*) FROM log_record partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 5.854 ms テーブルパーティショニングで性能向上(6/9) 41
BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------- Aggregate (cost=2135.00..2135.01 rows=1 width=8) Output: count(*) -> Seq Scan on public.log_record_2019 (cost=0.00..2075.00 rows=24000 width=0) Filter: ((log_record_2019.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log _record_2019.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (4 rows) partition_test=# \timing Timing is on. partition_test=# SELECT COUNT(*) FROM log_record partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 5.854 ms テーブルパーティショニングで性能向上(6/9) 42 2019年のパーティションから検索されている
BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------- Aggregate (cost=2135.00..2135.01 rows=1 width=8) Output: count(*) -> Seq Scan on public.log_record_2019 (cost=0.00..2075.00 rows=24000 width=0) Filter: ((log_record_2019.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log _record_2019.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (4 rows) partition_test=# \timing Timing is on. partition_test=# SELECT COUNT(*) FROM log_record partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 5.854 ms テーブルパーティショニングで性能向上(6/9) 43 2019年のパーティションから検索されている
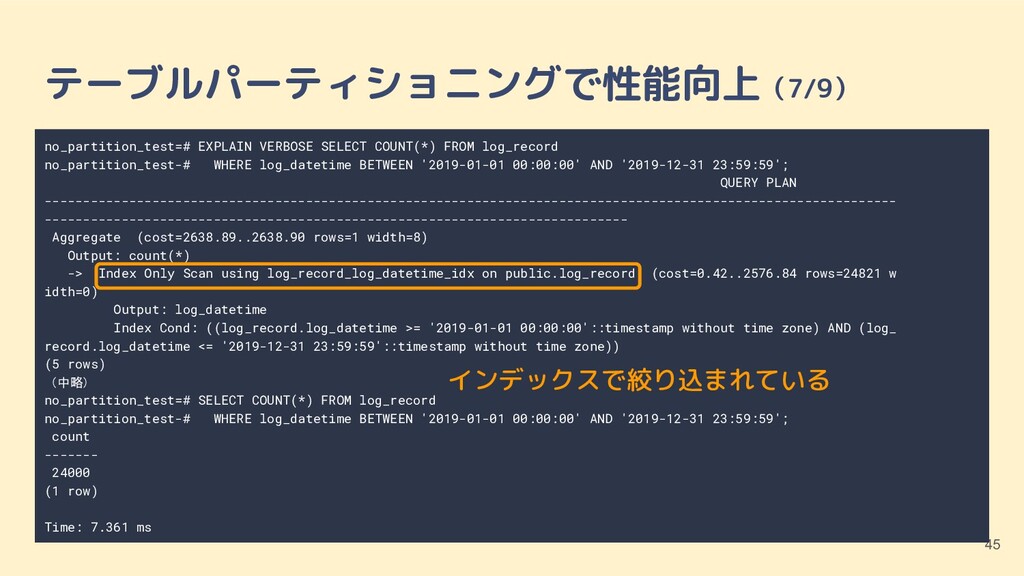
log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------- Aggregate (cost=2638.89..2638.90 rows=1 width=8) Output: count(*) -> Index Only Scan using log_record_log_datetime_idx on public.log_record (cost=0.42..2576.84 rows=24821 w idth=0) Output: log_datetime Index Cond: ((log_record.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log_ record.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (5 rows) (中略) no_partition_test=# SELECT COUNT(*) FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 7.361 ms
log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------- Aggregate (cost=2638.89..2638.90 rows=1 width=8) Output: count(*) -> Index Only Scan using log_record_log_datetime_idx on public.log_record (cost=0.42..2576.84 rows=24821 w idth=0) Output: log_datetime Index Cond: ((log_record.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log_ record.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (5 rows) (中略) no_partition_test=# SELECT COUNT(*) FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 7.361 ms インデックスで絞り込まれている
log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------- Aggregate (cost=2638.89..2638.90 rows=1 width=8) Output: count(*) -> Index Only Scan using log_record_log_datetime_idx on public.log_record (cost=0.42..2576.84 rows=24821 w idth=0) Output: log_datetime Index Cond: ((log_record.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log_ record.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (5 rows) (中略) no_partition_test=# SELECT COUNT(*) FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 7.361 ms インデックスで絞り込まれている パーティショニングのほうが若干速い
ms partition_test=# SELECT COUNT(*) FROM log_record partition_test-# WHERE log_datetime BETWEEN '2015-01-01 00:00:00' AND '2015-12-31 23:59:59'; count ------- 0 (1 row) no_partition_test=# DELETE FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2015-01-01 00:00:00' AND '2015-12-31 23:59:59'; DELETE 24000 Time: 123.978 ms no_partition_test=# SELECT COUNT(*) FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2015-01-01 00:00:00' AND '2015-12-31 23:59:59'; count ------- 0 (1 row) パーティショニングの場合は子テーブルを DROP パーティショニングを利用して DROP したほうが速い 非パーティショニングの場合は行を DELETE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![木構造をもつログデータを効率よく扱いたい(5/7) 案 1 問合せ [A] を PostgreSQL 12で実行してみる(再帰 CTE) 28](https://files.speakerdeck.com/presentations/bf65744a0c58475bbc2737129e54480b/slide_27.jpg){kind=link}
![木構造をもつログデータを効率よく扱いたい(6/7) 案 1 問合せ [A] を PostgreSQL 12で実行してみる(再帰 CTE) 29](https://files.speakerdeck.com/presentations/bf65744a0c58475bbc2737129e54480b/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}