Software Design Practices for Large-Scale Automation
Design practices for large-scale, high-performance, distributed system for complex algorithms such as graph, optimization, prediction, and machine learning etc.
simulation software to scale with Moore’s law • Internet Applications: systems need to be ready for next 10x user growth and feature evolution • Knowledge Base: bigger system improves cross referencing and hence quality of learning new knowledge • Deep learning: capacity of system affects quality of latent features learned and hence the prediction capability • Internet of Things: as the name suggests...
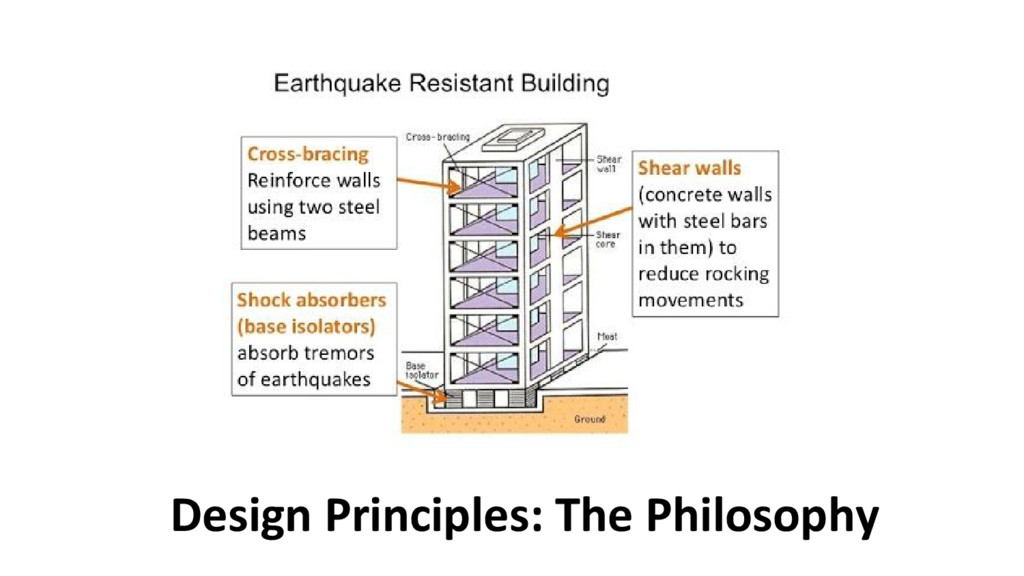
TOP challenge for software engineering • Usually grows with the scale of the system ◦ exhibits different patterns at different scale ◦ explodes with the number of software features • The only way to handle complexity ◦ “Divide and Conquer” ◦ realized by various Design Principles
just like human ◦ Results are stored in physical memory (RAM/ROM/Disk) ◦ Computation is done in physical processing units (CPU/GPU/FPGA) • Not feasible to build one gigantic machine that solves everything ◦ System should live on machine farms ◦ Data / Computation should be distributed • Physicality complicates the design of systems ◦ Data partition ◦ Computation partition
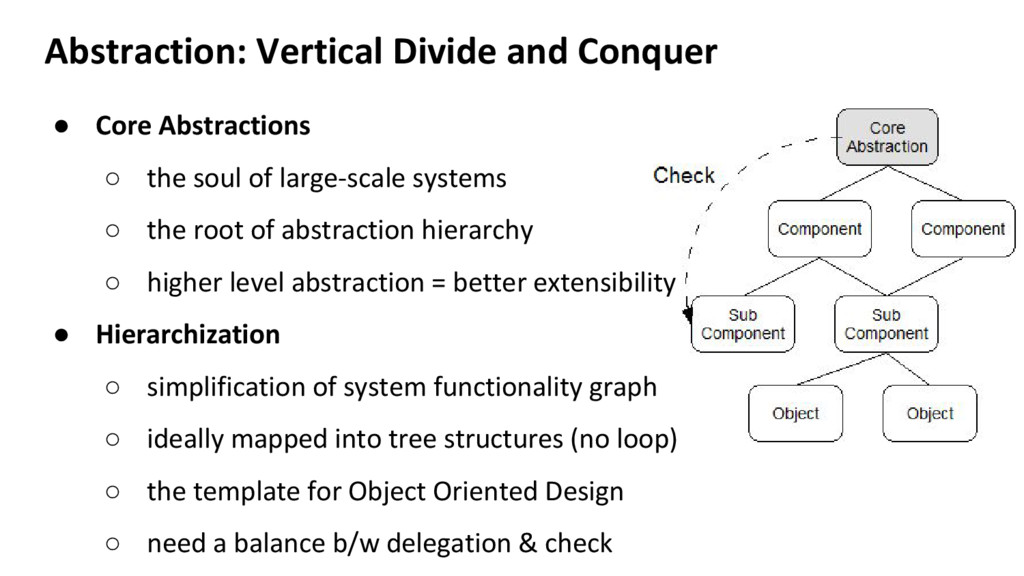
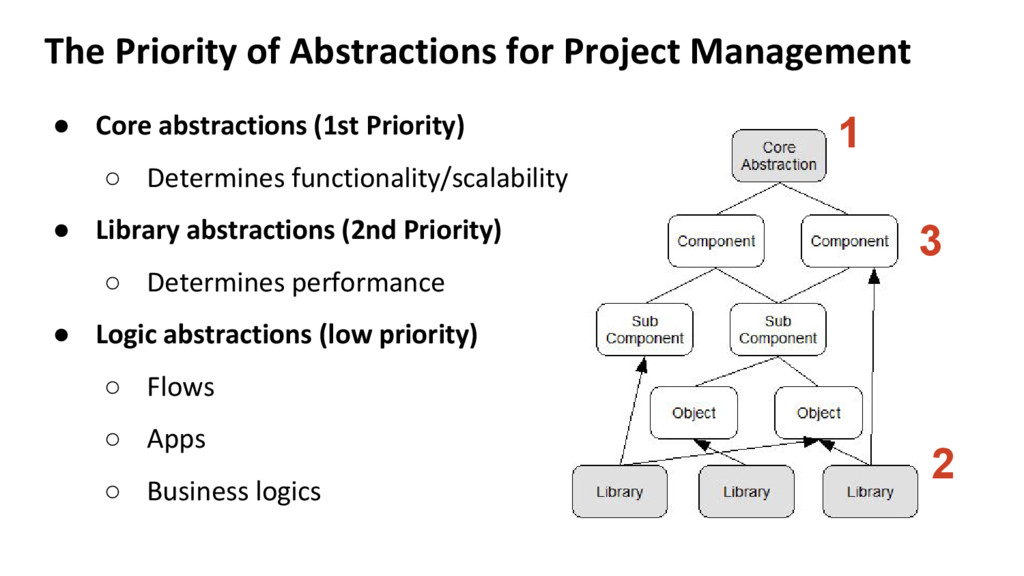
soul of large-scale systems ◦ the root of abstraction hierarchy ◦ higher level abstraction = better extensibility • Hierarchization ◦ simplification of system functionality graph ◦ ideally mapped into tree structures (no loop) ◦ the template for Object Oriented Design ◦ need a balance b/w delegation & check
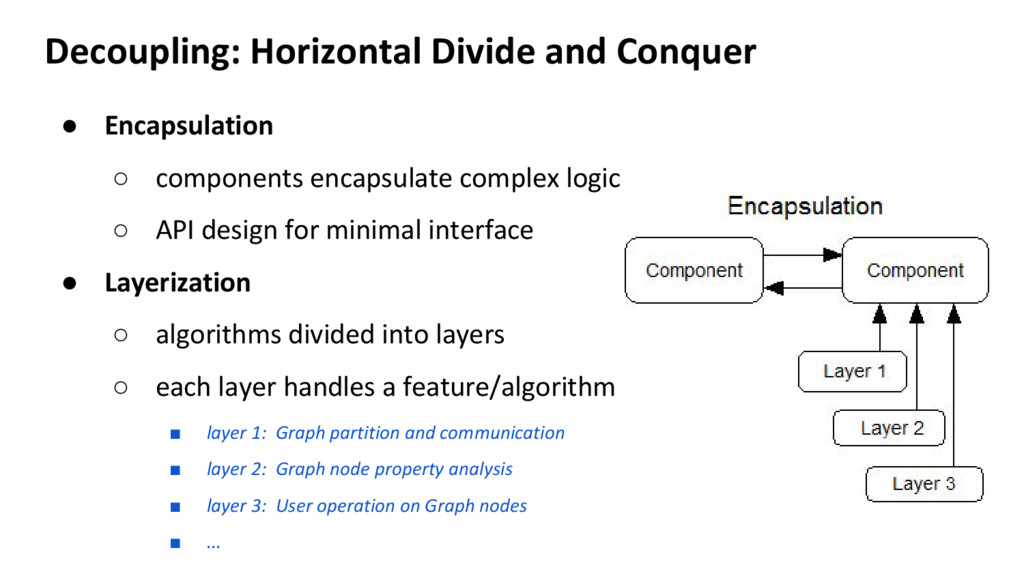
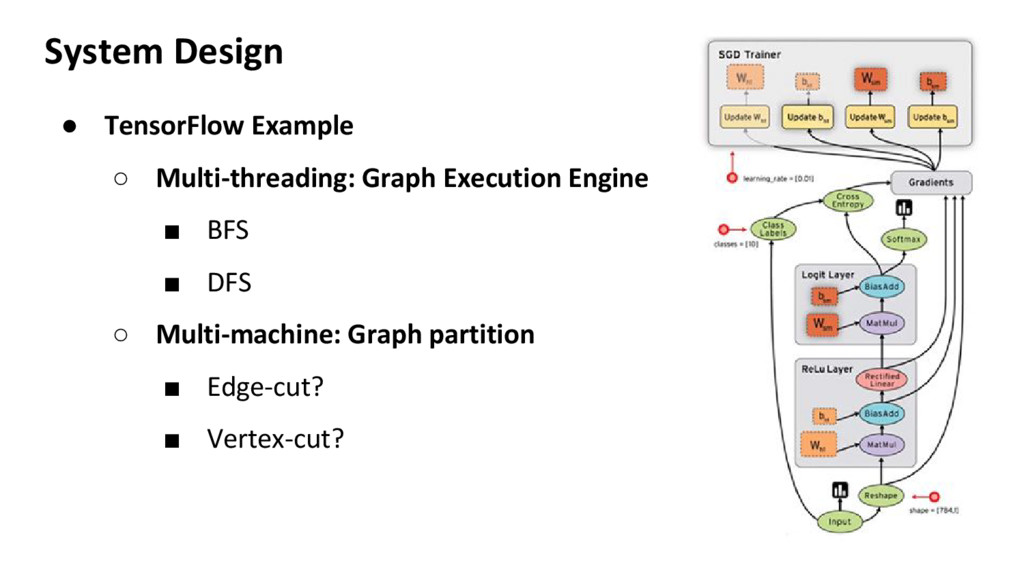
complex logic ◦ API design for minimal interface • Layerization ◦ algorithms divided into layers ◦ each layer handles a feature/algorithm ▪ layer 1: Graph partition and communication ▪ layer 2: Graph node property analysis ▪ layer 3: User operation on Graph nodes ▪ ...
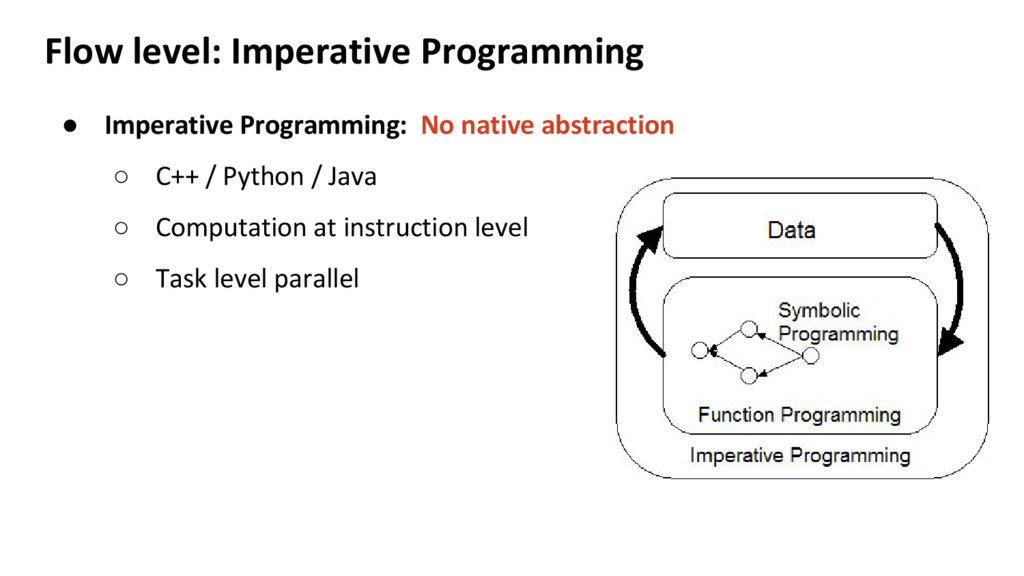
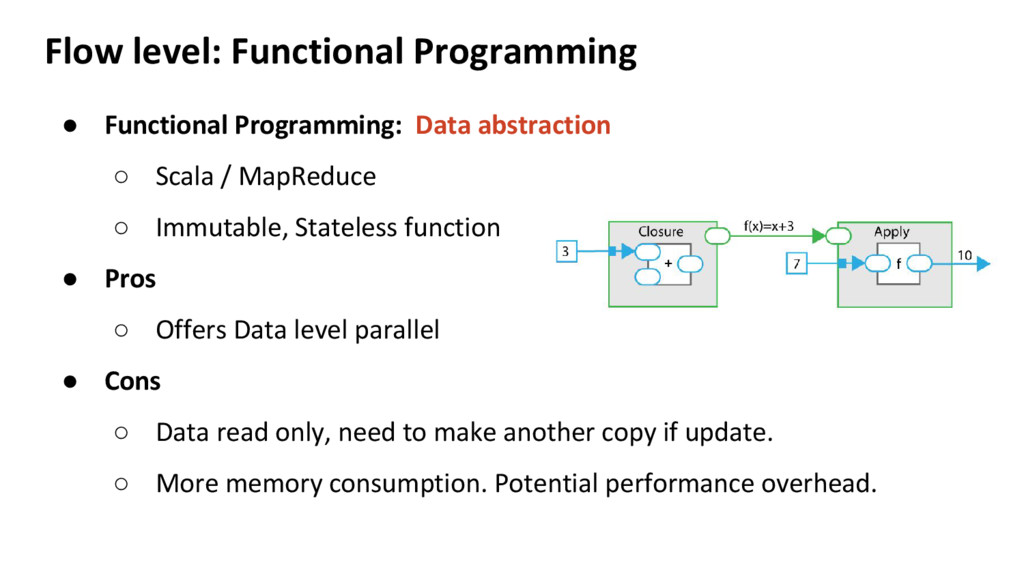
at different levels ◦ Offers encapsulation and parallelism at different levels ◦ Crucial to choose the right computation paradigm • Computation Paradigm at different levels ◦ Language level: Python, C, Scala ◦ Flow level: Imperative, Symbolic, Functional programming ◦ System level: Computation-centric (HPC) or Data-centric (e.g. Spark)
Scala / MapReduce ◦ Immutable, Stateless function • Pros ◦ Offers Data level parallel • Cons ◦ Data read only, need to make another copy if update. ◦ More memory consumption. Potential performance overhead.
Theano / TensorFlow ◦ Operator level parallel ◦ Graph model as base engine • Pros ◦ Offers high operator parallelism through graph propagation • Cons ◦ Not flexible for all programming tasks ◦ May incur overhead handling with fine-grained operators
different levels ◦ Multi-threading ◦ Multi-process ◦ Distributed cluster ◦ Mainstream communication: MPI • Partition based on needs of communication ◦ Minimize communication ◦ Algorithm partition ◦ Data partition
Components ◦ GPU acceleration (many small cores) ▪ Model is too small; too much overhead; stays on CPU ▪ Model is too large; exceeds GPU memory; do partial acceleration ▪ Exchange memory with CPU through memory copy ◦ FPGA (millions of gates) ◦ SSD, RAID 0/1,5/10 • Disk IO ◦ HDF5 parallel read/write
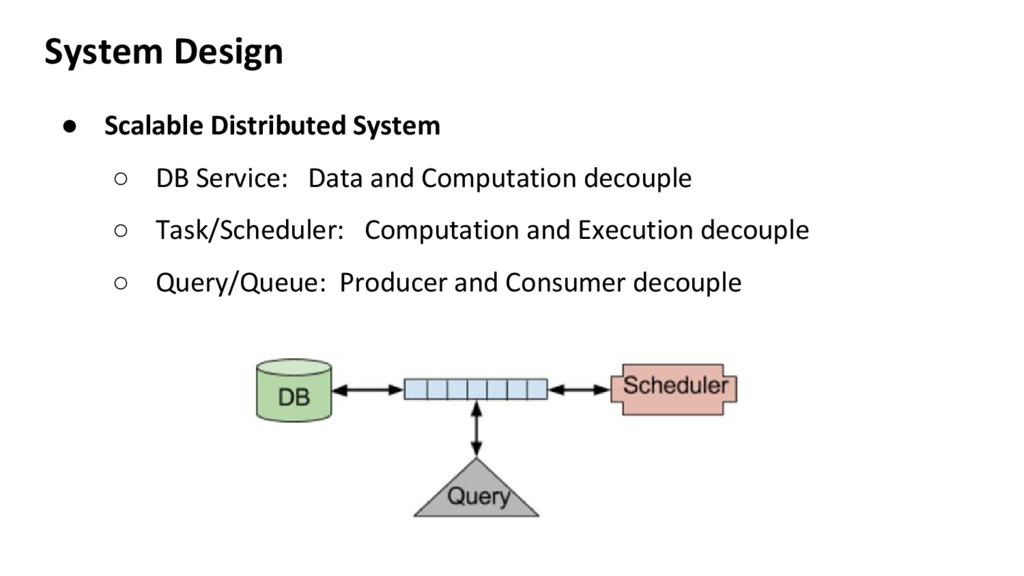
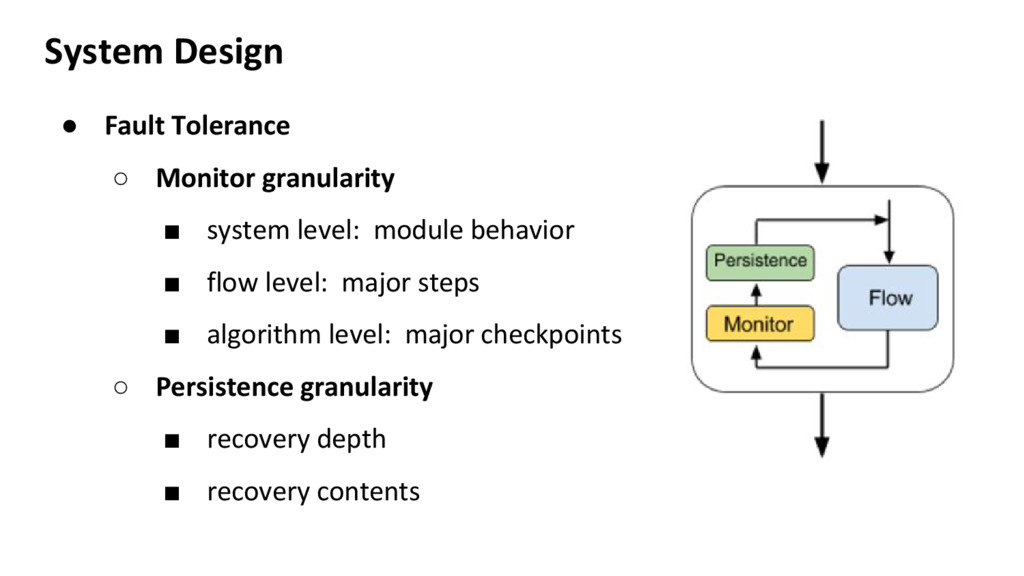
central DB ◦ Serialization: boost:serialization(c++), pickling(Python) • Scalable computation ◦ Usually has a scheduler ◦ Explicit scheduling: user defines computation graph nodes ◦ Implicit scheduling: engine analyzes the computation graph • Stateless ◦ Good for debug, easy recover from failure
Stochastic algorithms → use Data-centric model ▪ E.g. Back propagation: Parameter Server ◦ Deterministic algorithms → use Computation-centric (HPC) model ▪ E.g. Common data sync among model partitions: Bulk Synchronous Parallel
task = function(data, parameters, executor_id) ◦ schema (base class) for task ◦ scheme for any data ◦ schema for any function ◦ schema for any parameter • Benefits ◦ higher level automation ◦ potentially more intelligent system
setter / getter ◦ encapsulate atomic or repeated functionality ◦ #define any hard number ◦ factorize long function or class ◦ build shared libraries from bottom-up ▪ communication lib ▪ parallel computing lib ▪ debug / reporting lib
by folder ◦ module level decouple by file ◦ variable space decouple by namespace • Code change ◦ physical change (files/folders touched) should reflect logical change ◦ change scope should narrow down as development goes ◦ diff mangement
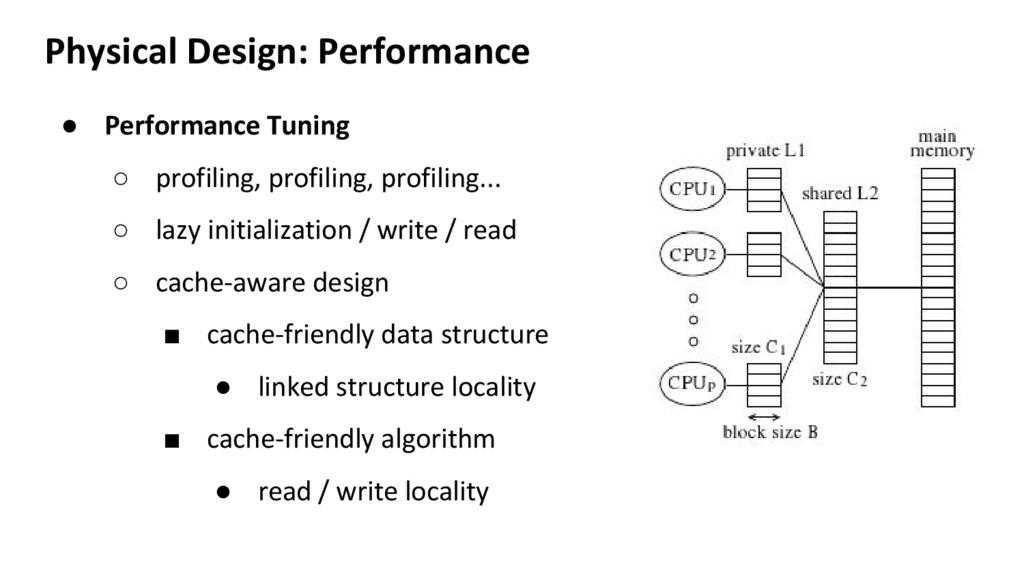
for performance ◦ Code runs in memory, not in the air • OS Memory Handling ◦ Memory allocation, fragmentation, release etc ◦ Tcmalloc VS jemalloc ▪ Improves allocation/fragmentation ▪ Still has issue on release
▪ Memory critical: TC/JEmalloc ▪ Memory and Performance critical: MMU ◦ HPC is memory and performance critical ▪ Parallel does not solve all the problem. Single machine performance is still dominant factor ▪ You should know the code very well to design manual MMU ◦ Spark replacing JVM memory management with Tungsten project
▪ shared memory, data exchange OK ◦ multi-process ▪ heavy overhead ▪ separated memory space, more difficult data exchange ◦ distributed multiple machine ▪ balance between computation VS. communication
is the key information to stitch each pieces together ◦ sync data to resemble single machine algorithm (rare but can be useful) ◦ keep data local, sync results (map/reduce) • When to sync? ◦ lazy sync (e.g. Bulk Synchronous Parallel) ◦ async (e.g. Parameter Server) • Where to sync? ◦ refactor algorithm by optimal sync point
◦ for many algorithms, lack of global sync leads to QoR loss ◦ full global sync is very expensive in communication cost ◦ carefully choose sync points to maximize Performance / QoR Loss • Self-healing Algorithms ◦ some algorithms have less dependency on global sync ◦ e.g. in Stochastic Optimization ▪ global sync may be postponed to allow local optimum explored ▪ however this nice feature is data / model dependant
on QoR? ▪ approximation is inevitable, so what can be approximated? ▪ not just an engineering problem ▪ usually needs assessment on business impact ◦ Solutions ▪ for each approximation candidates, detail profiling on QoR loss VS. Performance Gain VS. Business impact
to maintain? ▪ Stochastic Algorithms: find deterministic in probability values ▪ Graph algorithms: hard to trace in large-scale graph ◦ Solutions ▪ develop single machine algorithm first as golden ▪ detailed testing and correlation for each parallelization step ▪ detailed testing to understand result/error pattern on small data
of complexity ◦ iterations need to be tuned, or completely re-designed ◦ may become harder to converge • Tuning iterations ◦ Again, where to iterate? ▪ spend runtime on key gainer ▪ profiling of iterations VS. QoR gain ◦ Tuning knots for convergence ▪ iteration knots have very high impact on convergence ▪ profiling of convergence parameters VS runtime VS QoR
Language) “In these distributed computation engines, the shuffle refers to the repartitioning and aggregation of data during an all-to-all operation. Understandably, most performance, scalability, and reliability issues that we observe in production Spark deployments occur within the shuffle.” http://blog.cloudera.com/blog/2015/01/improving-sort-performance-in-apache-spark- its-a-double
Spark Language) ◦ unified partition VS. per-stage partition ▪ per-stage partition fits algorithm better, but requires data migration ◦ global partition VS. stream partition ▪ global partition fits algorithm better, but requires single machine to hold all data for partition ▪ stream partition + post-partition adjustment
Spark Language) ◦ QoR numerical dependence on the number of partitions ▪ direct partitioning has numerical stability problem ▪ fine-grained partition + post-partition coarsening is better • Solutions ◦ Hard to use standard library for high performance system ◦ Best performance system is customized on: ▪ Data volume ▪ Computation intensity ▪ (Multiple-stage) Algorithm parallelism ◦ Always, keep a golden of single machine run, even for small input data!
◦ A high level model of the system ◦ Save time in debug ◦ Save business in crisis • Throughout Software Lifecycle ◦ Development: test-driven development ◦ Deployment: handles discrepancy b/w user env and dev env ◦ Maintenance: predicts error, learns from failures, improves system
Good to have: ◦ Cases run through ◦ Information on internal data, sometimes • Too much of it? ◦ hurts performance • Need a balance ◦ Input of external data → sanity check ◦ Internal data → no check on high performance engine. System design and code should ensure that
based ▪ Simply adds up the numbers to see if match ▪ Use another algorithm, simpler, but does rough check ◦ Data driven ▪ Samples intermediate data from normal runs, issues alert when runtime data distribution is different
more) • Essentially a high level abstraction on code OUTPUT ◦ Not just debug ◦ A reversed tree structure, with samples on key nodes ◦ Grows intelligently with field practice • Maintenance effort should decrease over time ◦ Error handling/messaging system should mature through time ◦ Bugs should be fixed in the right direction, not just workaround
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}