This session walks through a real-world system performance investigation centered on an unexpected speedup observed during a container migration. What initially appeared to be a straightforward performance improvement gradually revealed itself to be extreme CPU thrashing on the original server. Through an iterative investigation process, the root cause was traced to CPU saturation and severe resource contention introduced by noisy applications sharing the same host. The talk also introduces the observability tools used throughout the analysis, ranging from standard counters such as uptime and perf stat to BPF-based dynamic tracing.
{kind=link}
{kind=link}
{kind=link}
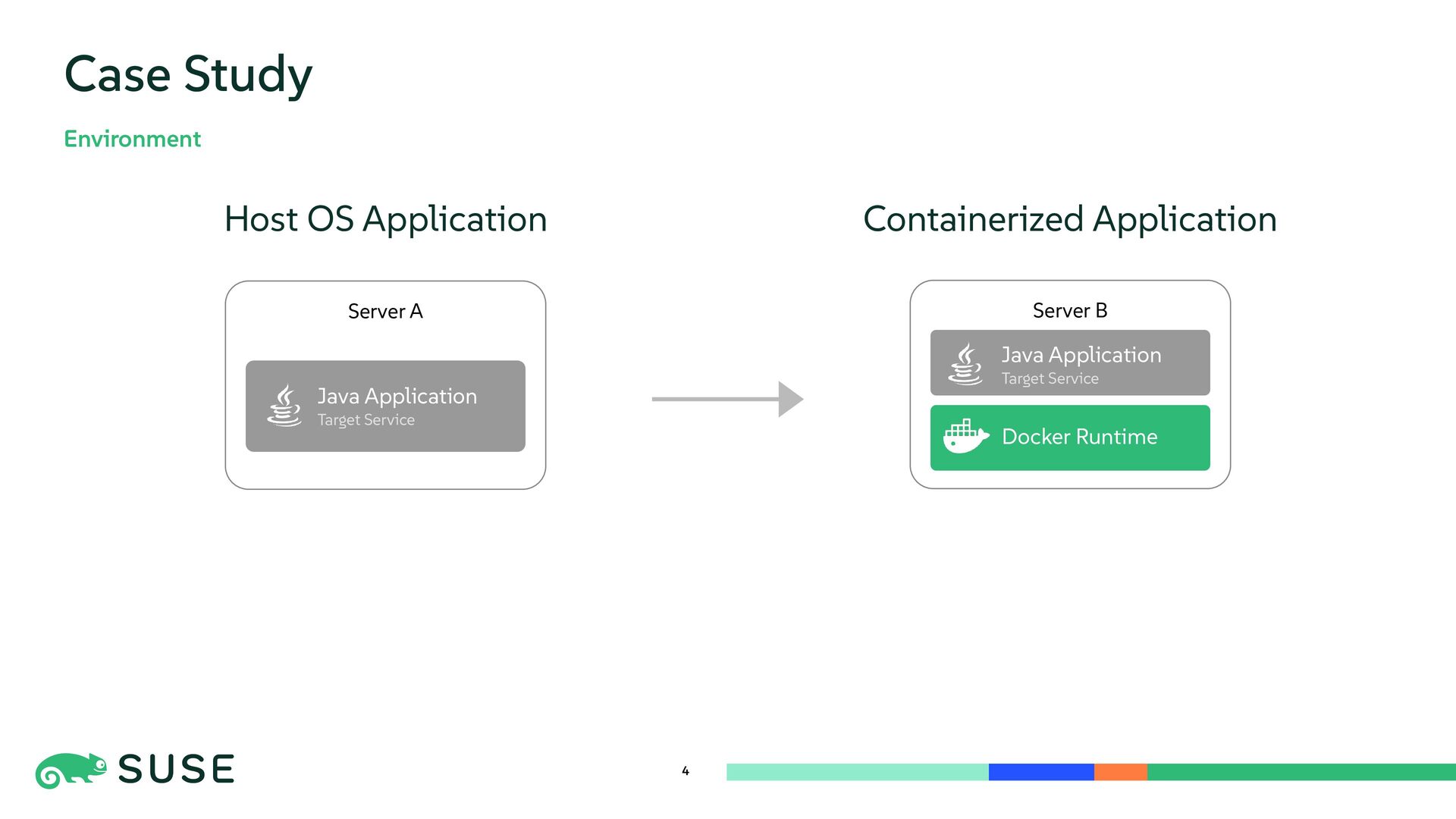{kind=link}
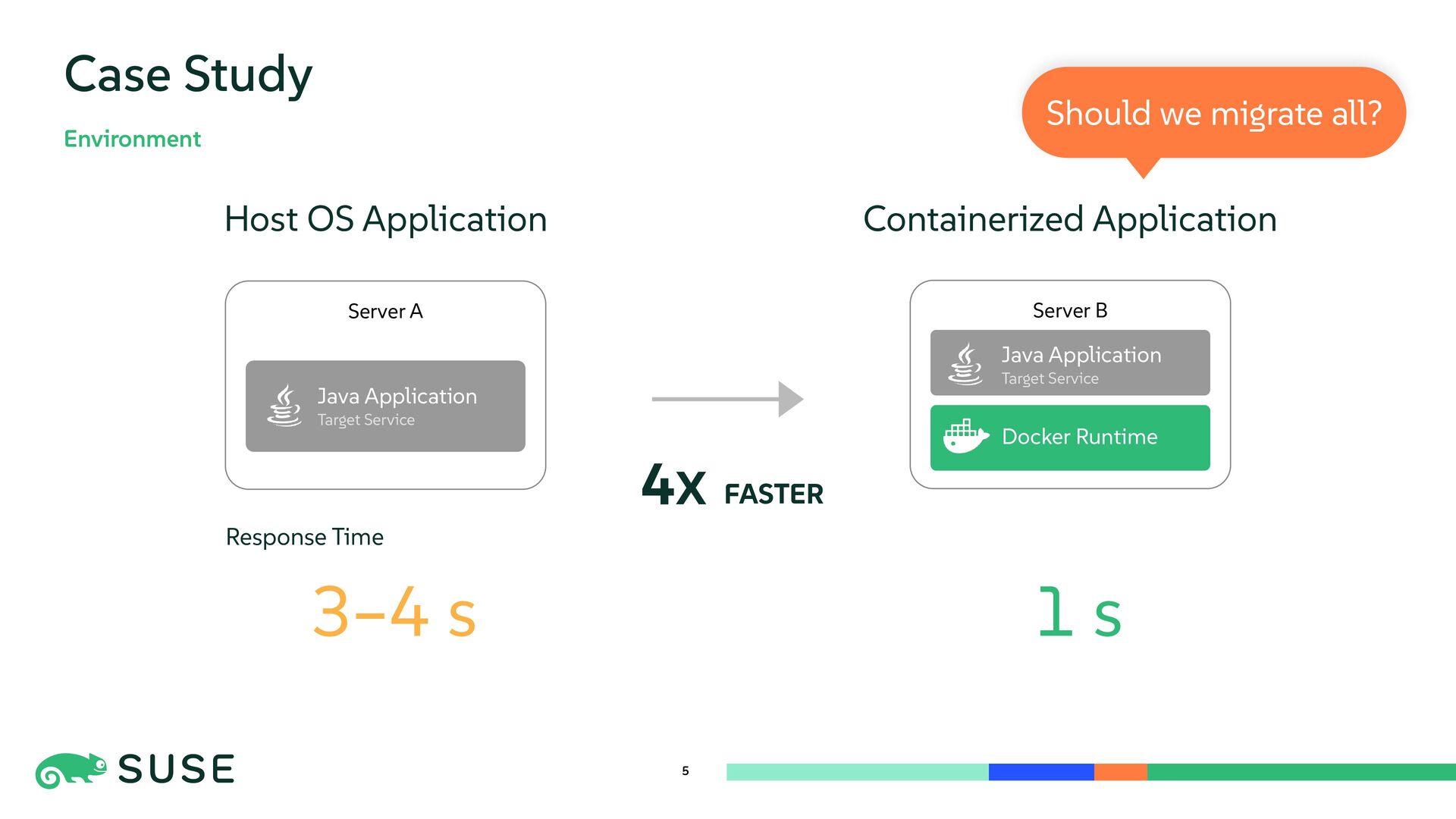{kind=link}
{kind=link}
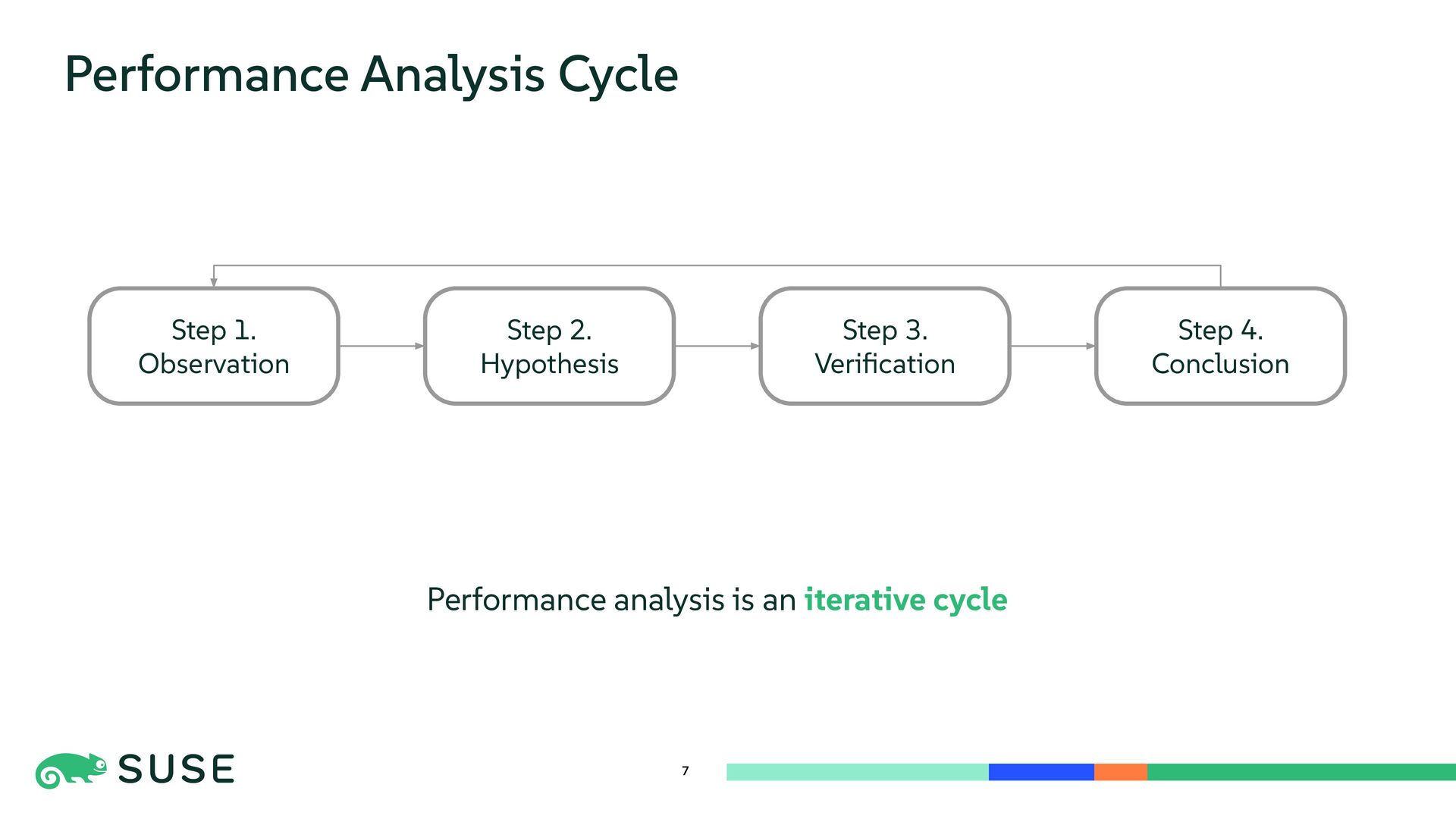{kind=link}
{kind=link}
{kind=link}
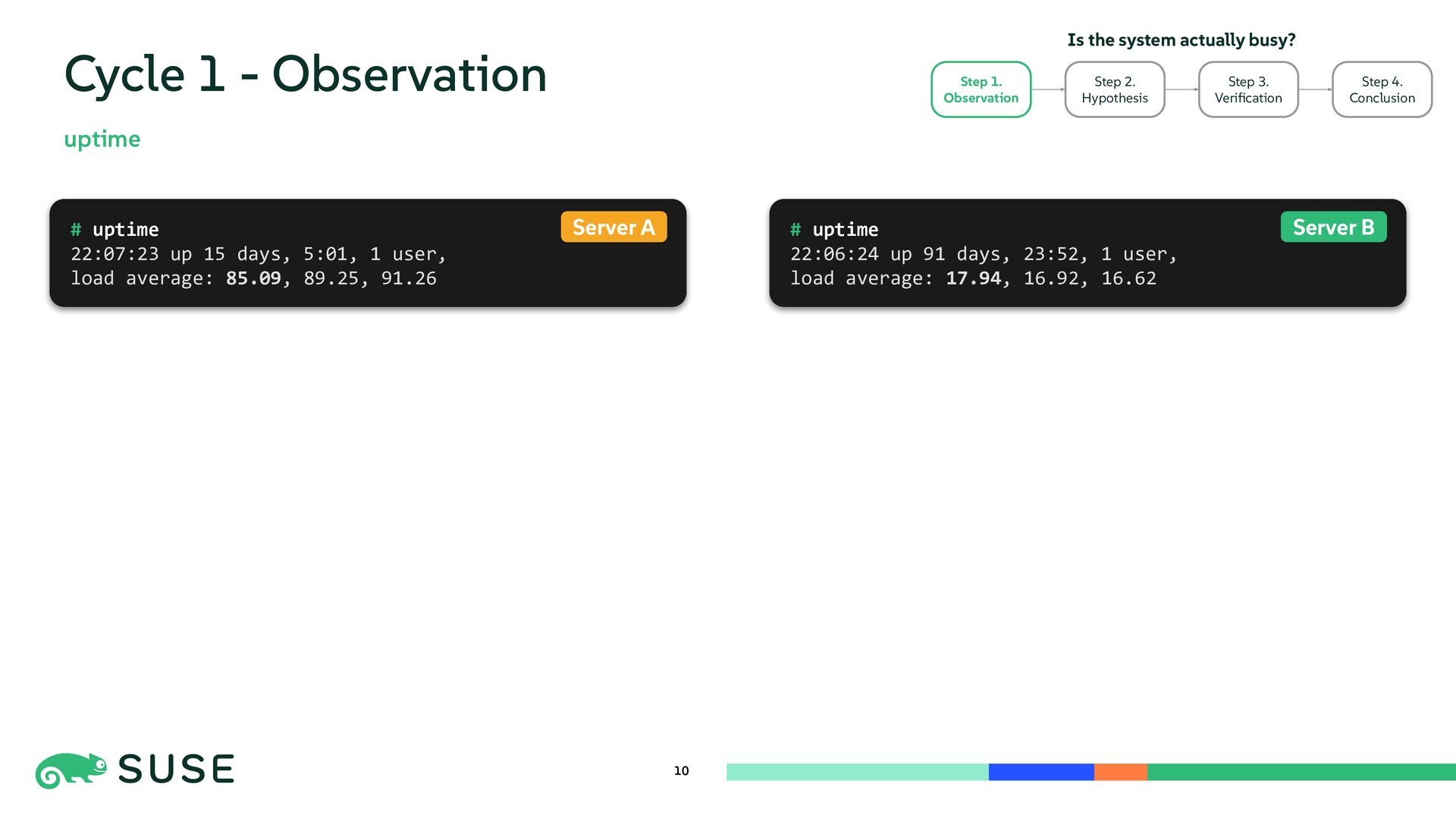{kind=link}
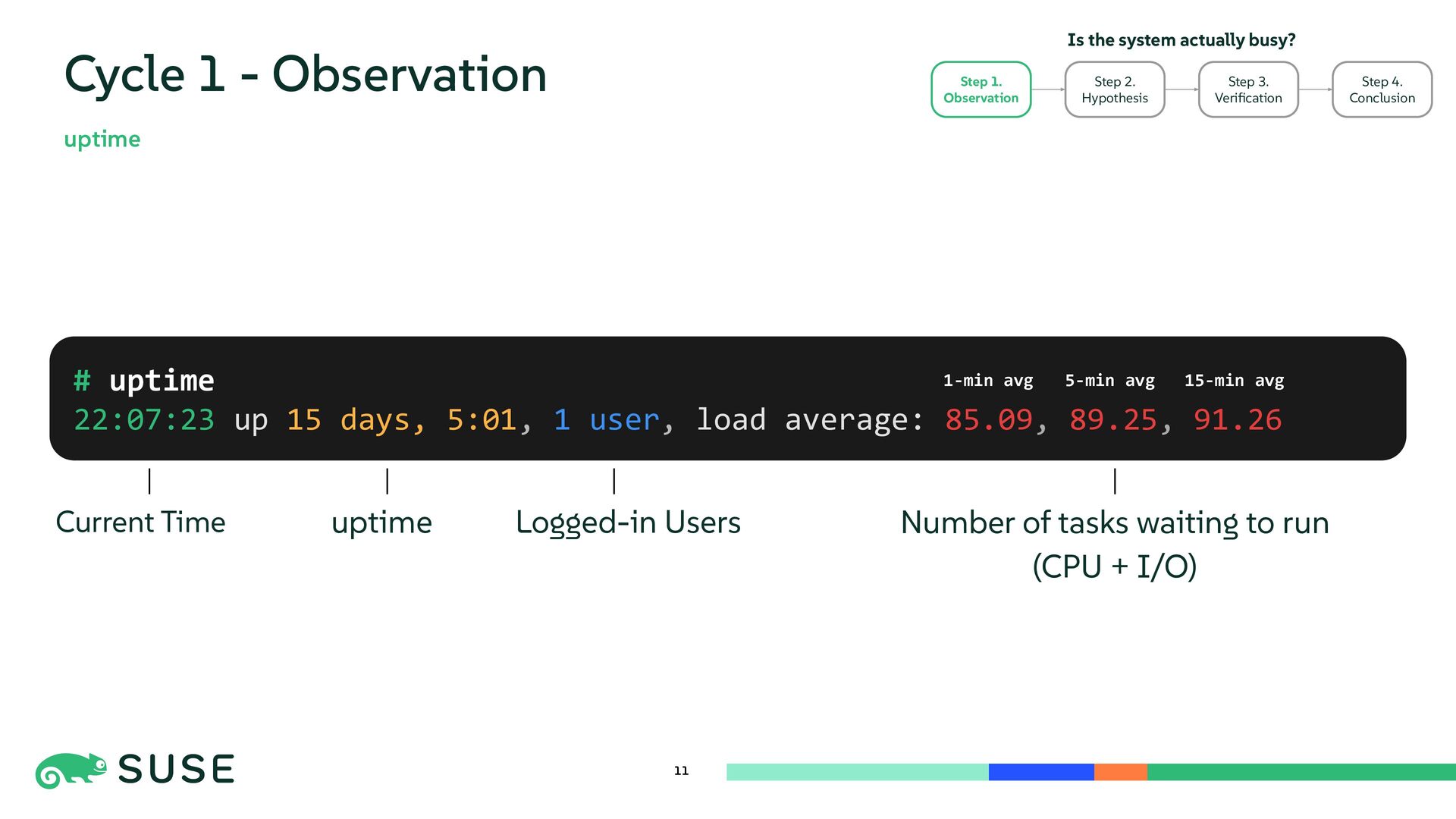{kind=link}
{kind=link}
{kind=link}
{kind=link}
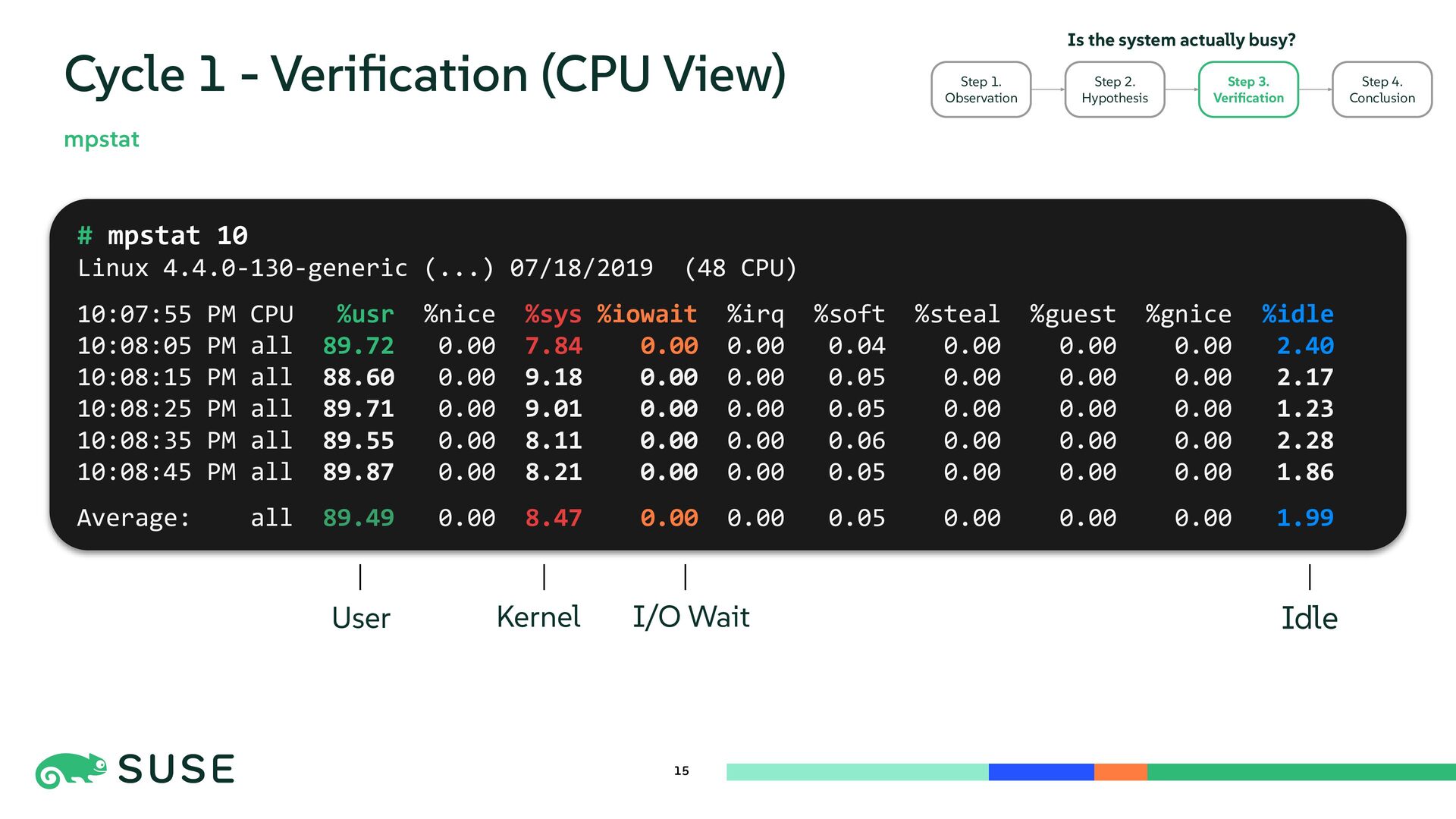{kind=link}
{kind=link}
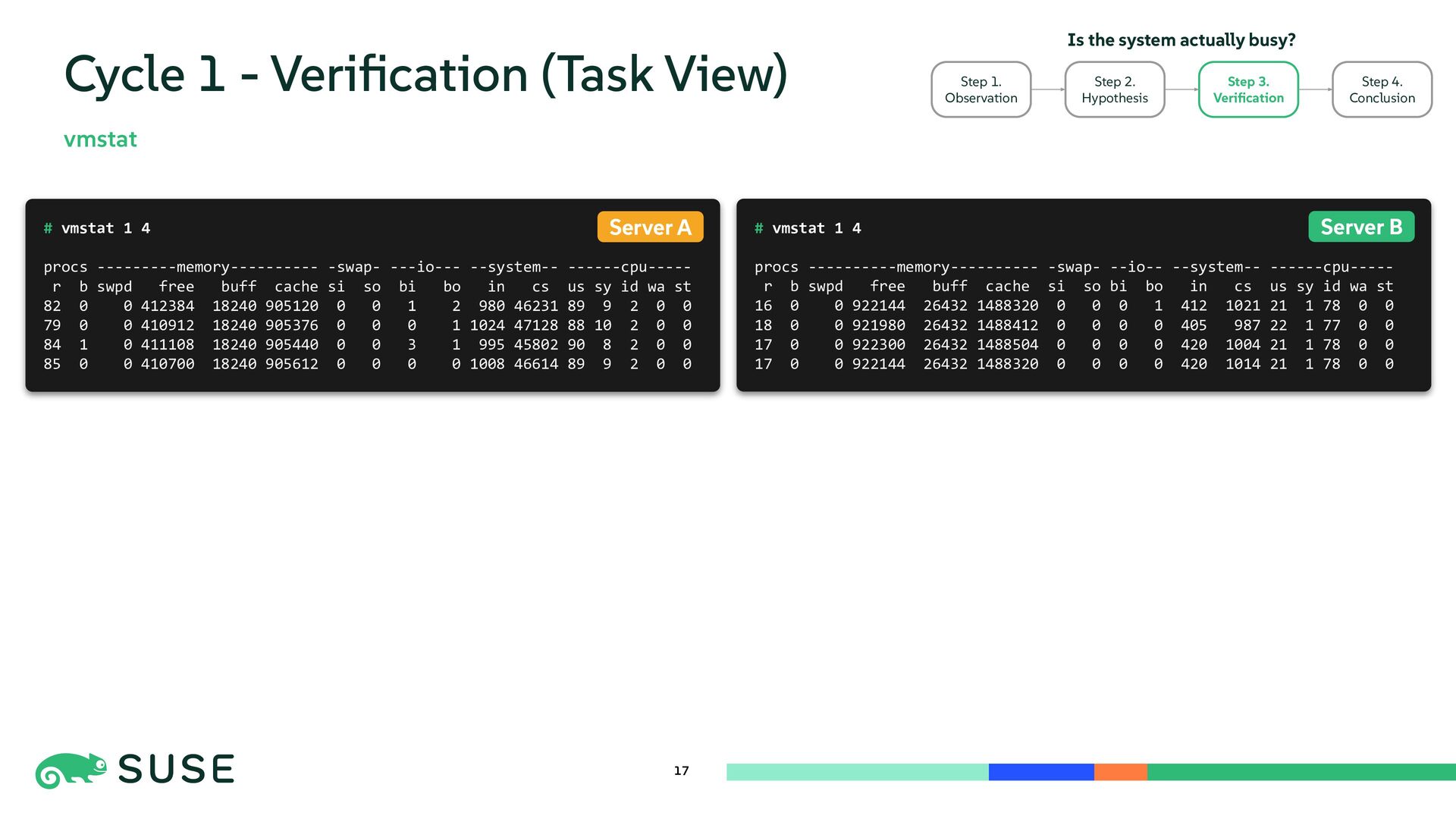{kind=link}
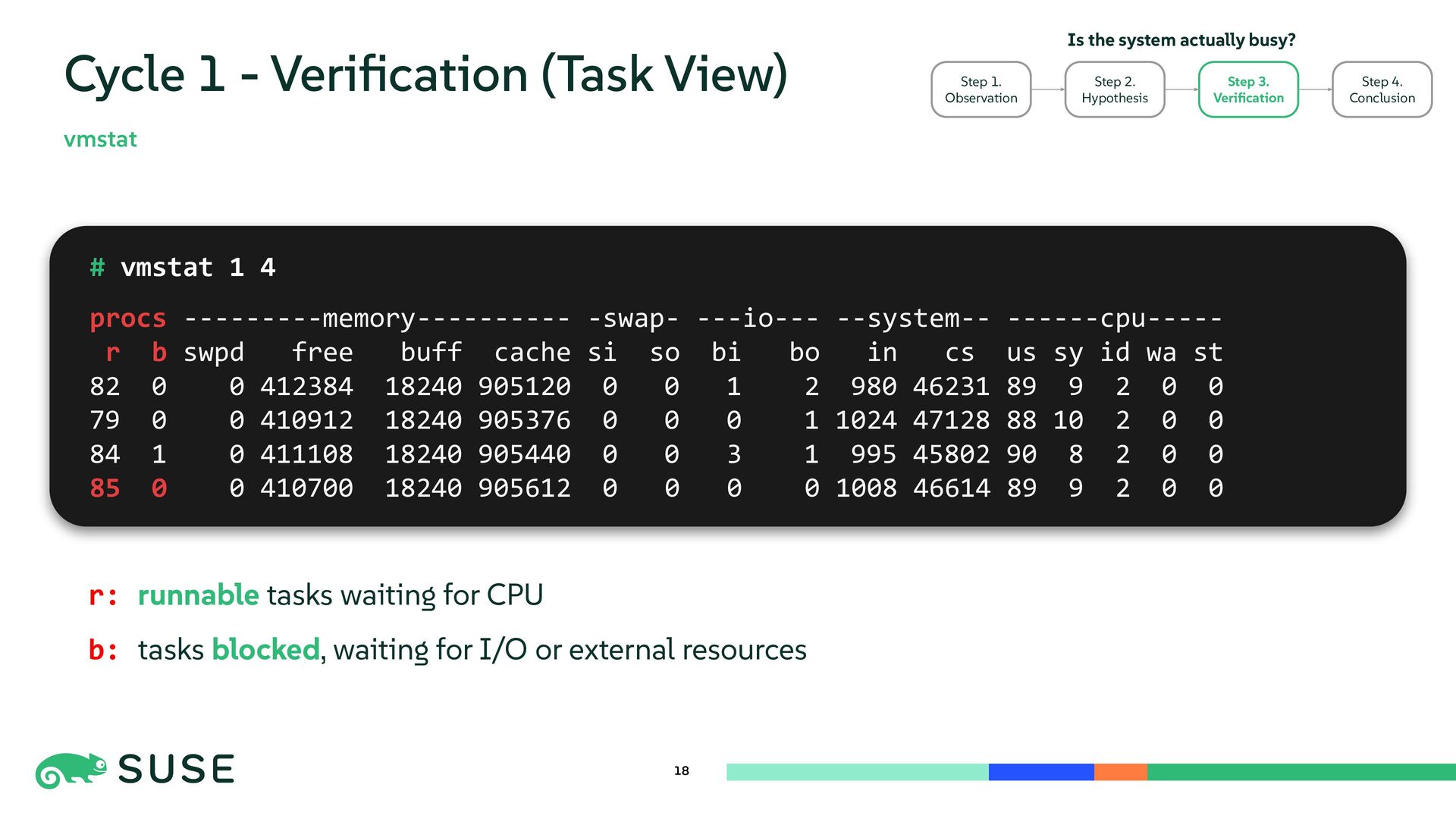{kind=link}
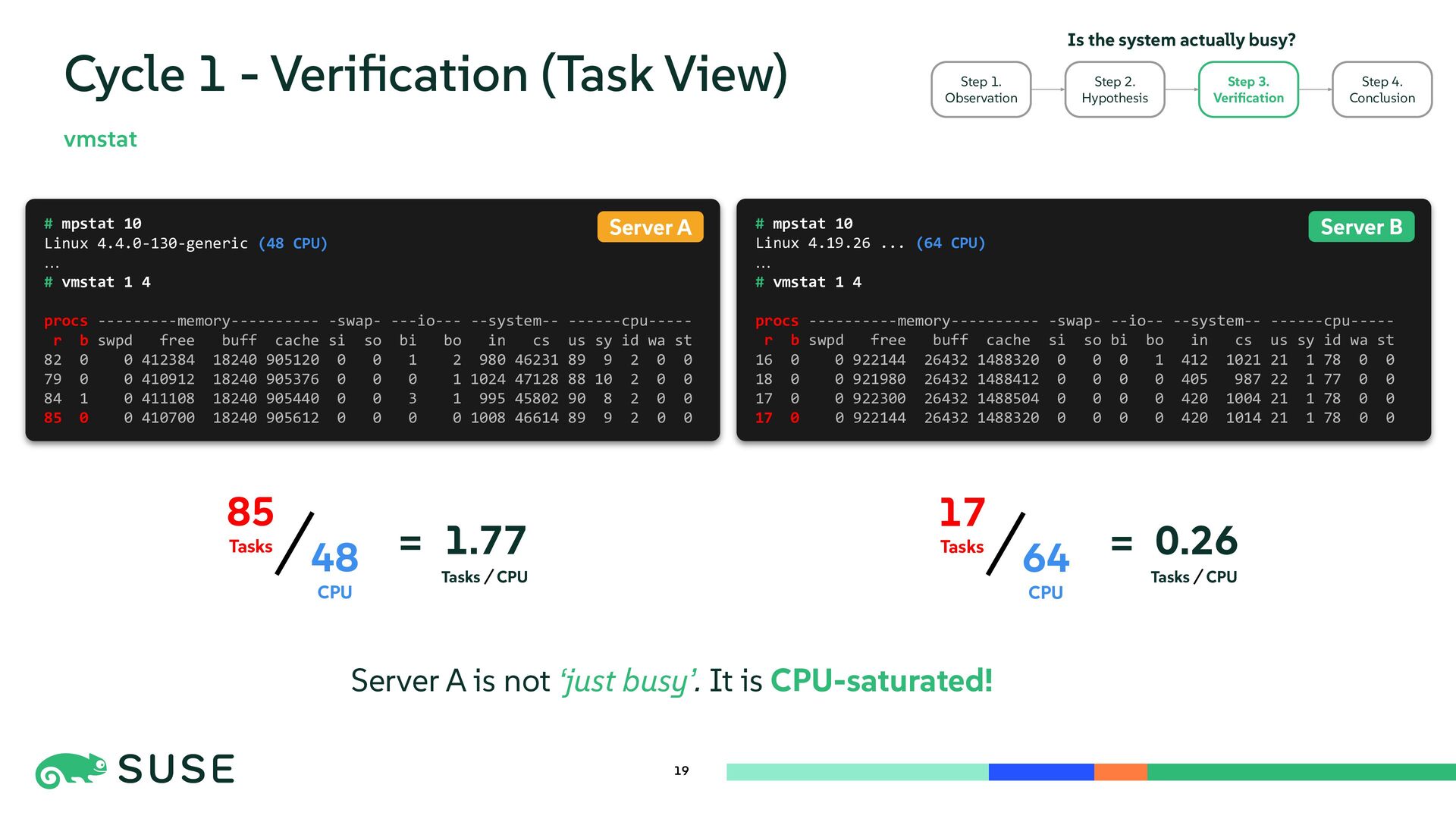{kind=link}
{kind=link}
{kind=link}
{kind=link}
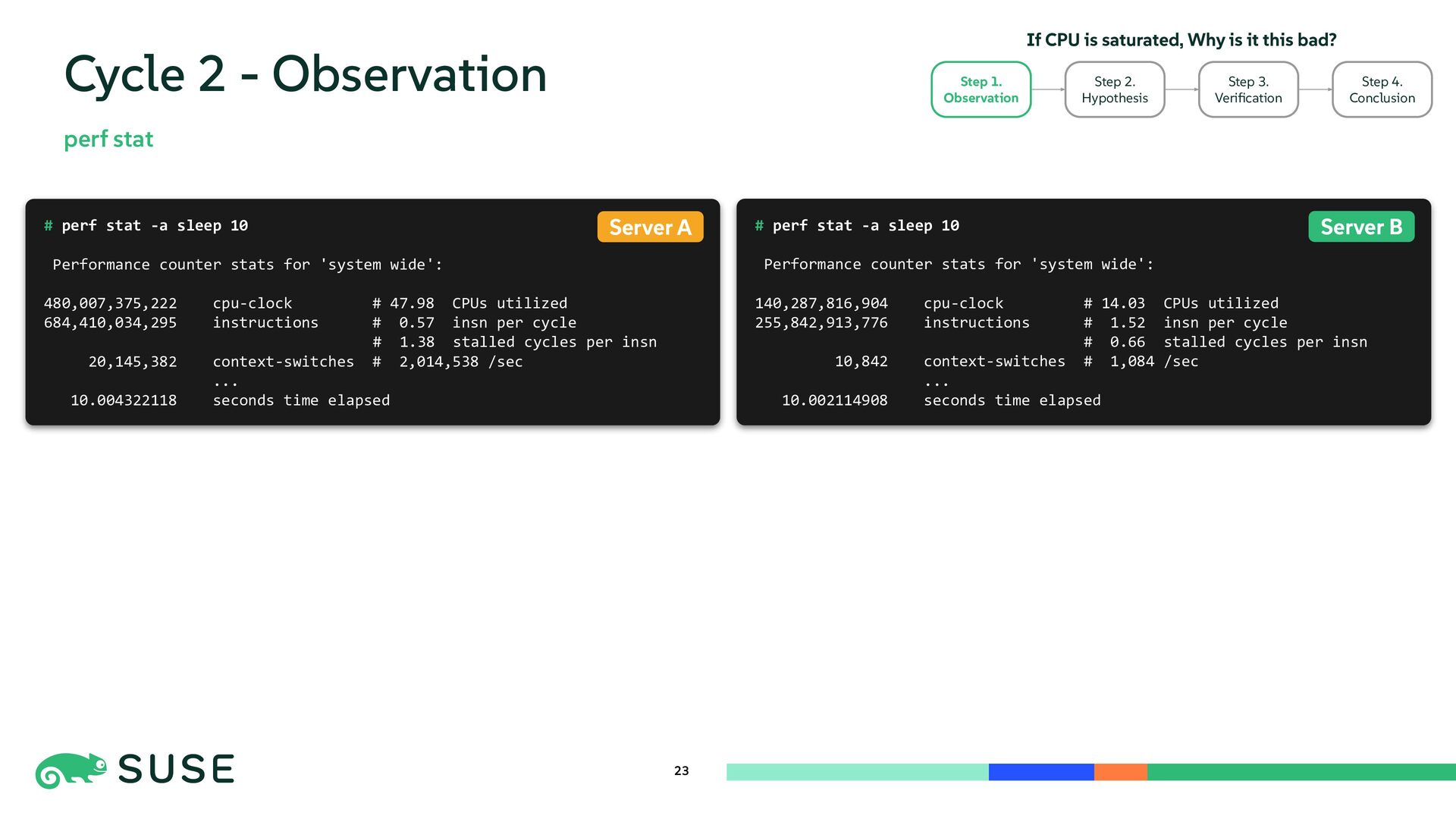{kind=link}
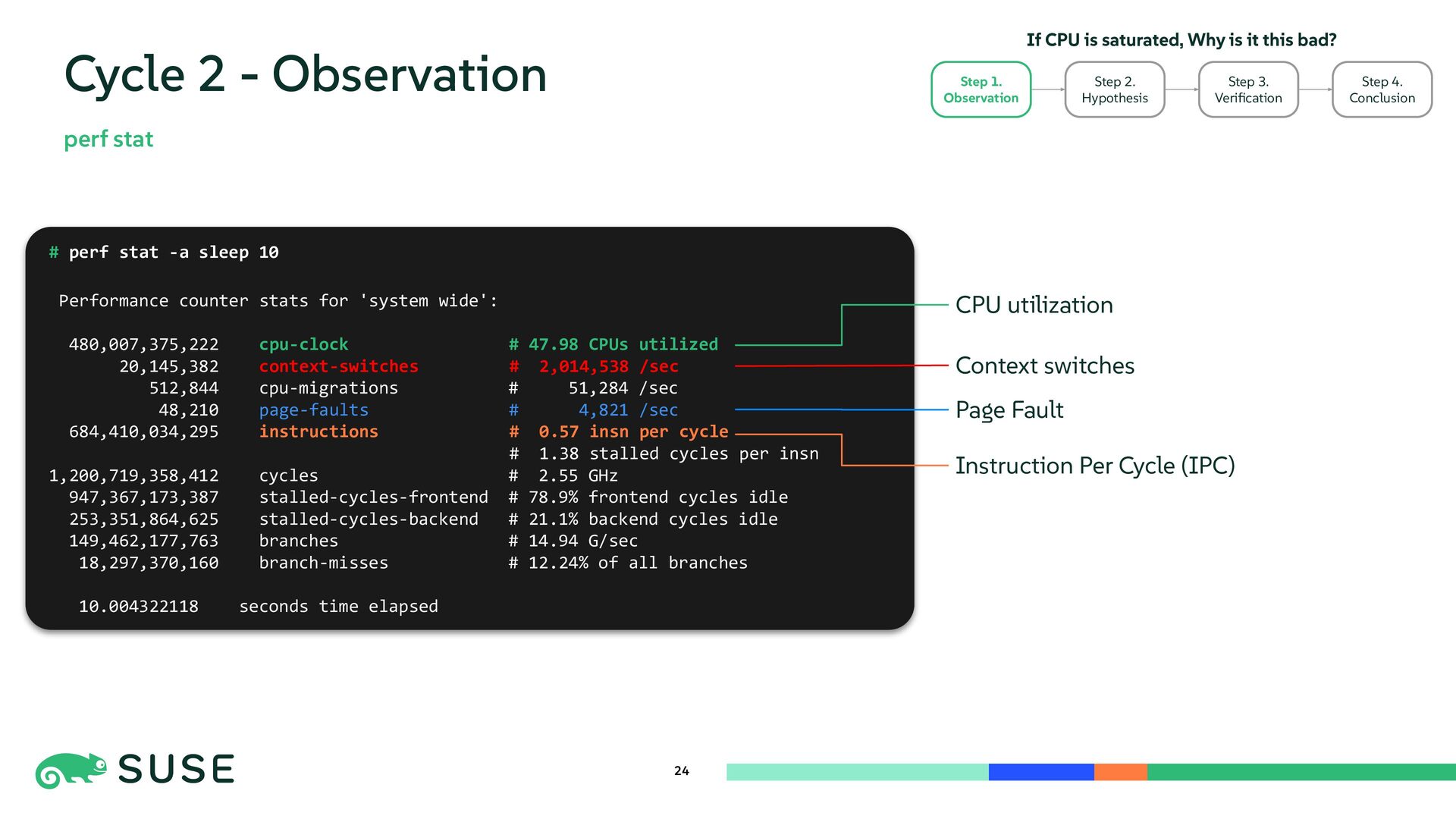{kind=link}
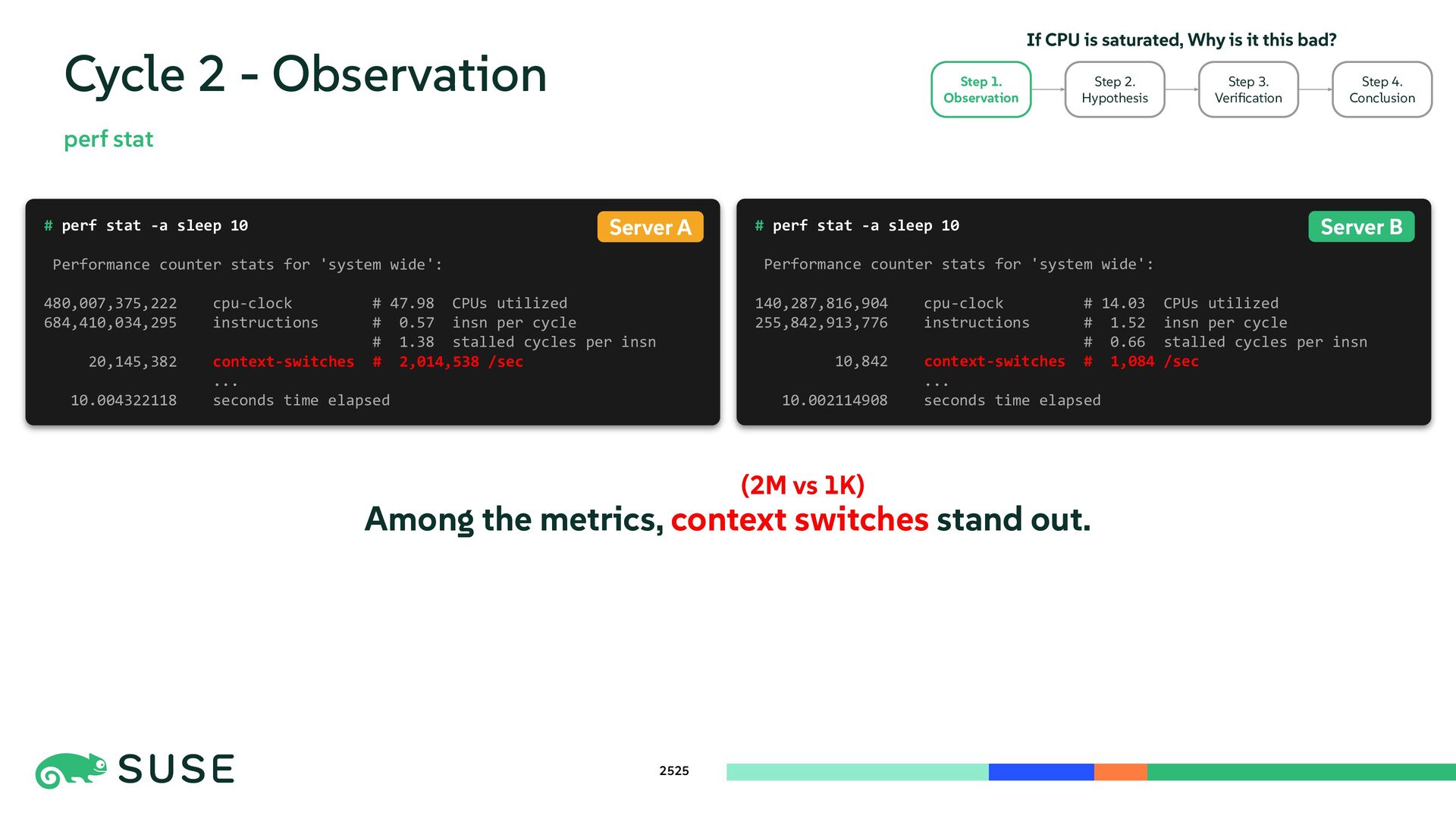{kind=link}
{kind=link}
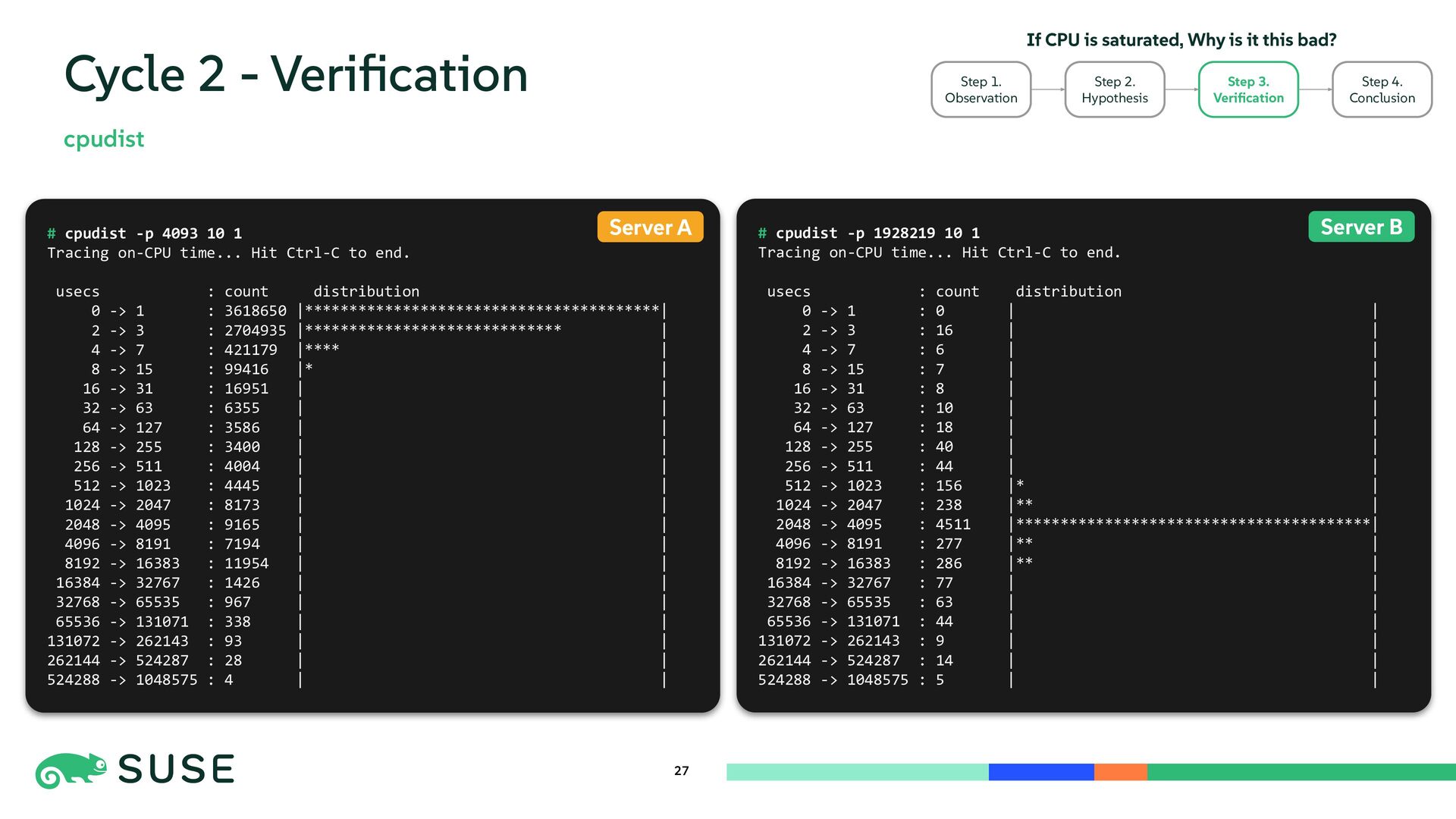{kind=link}
{kind=link}
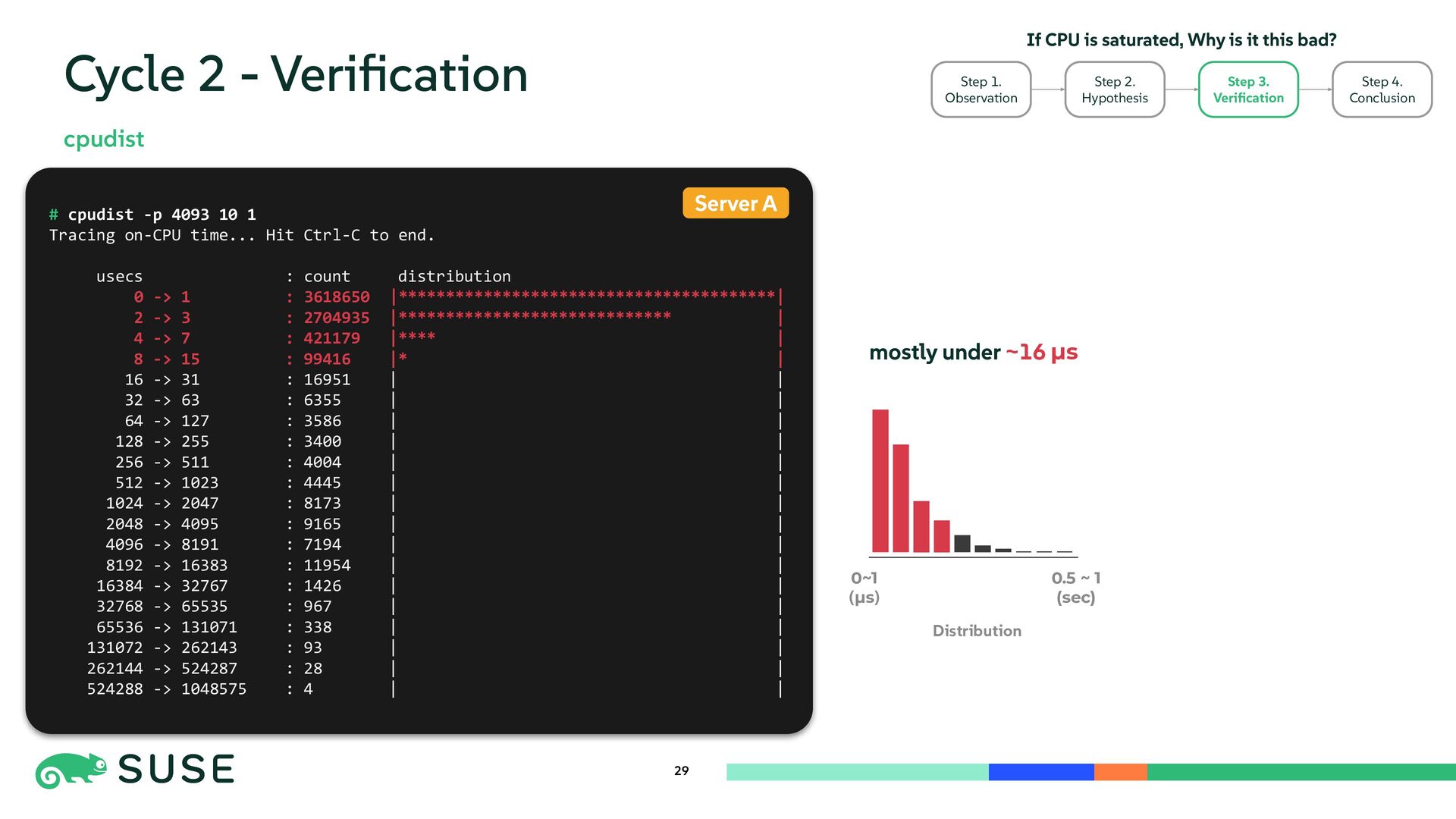{kind=link}
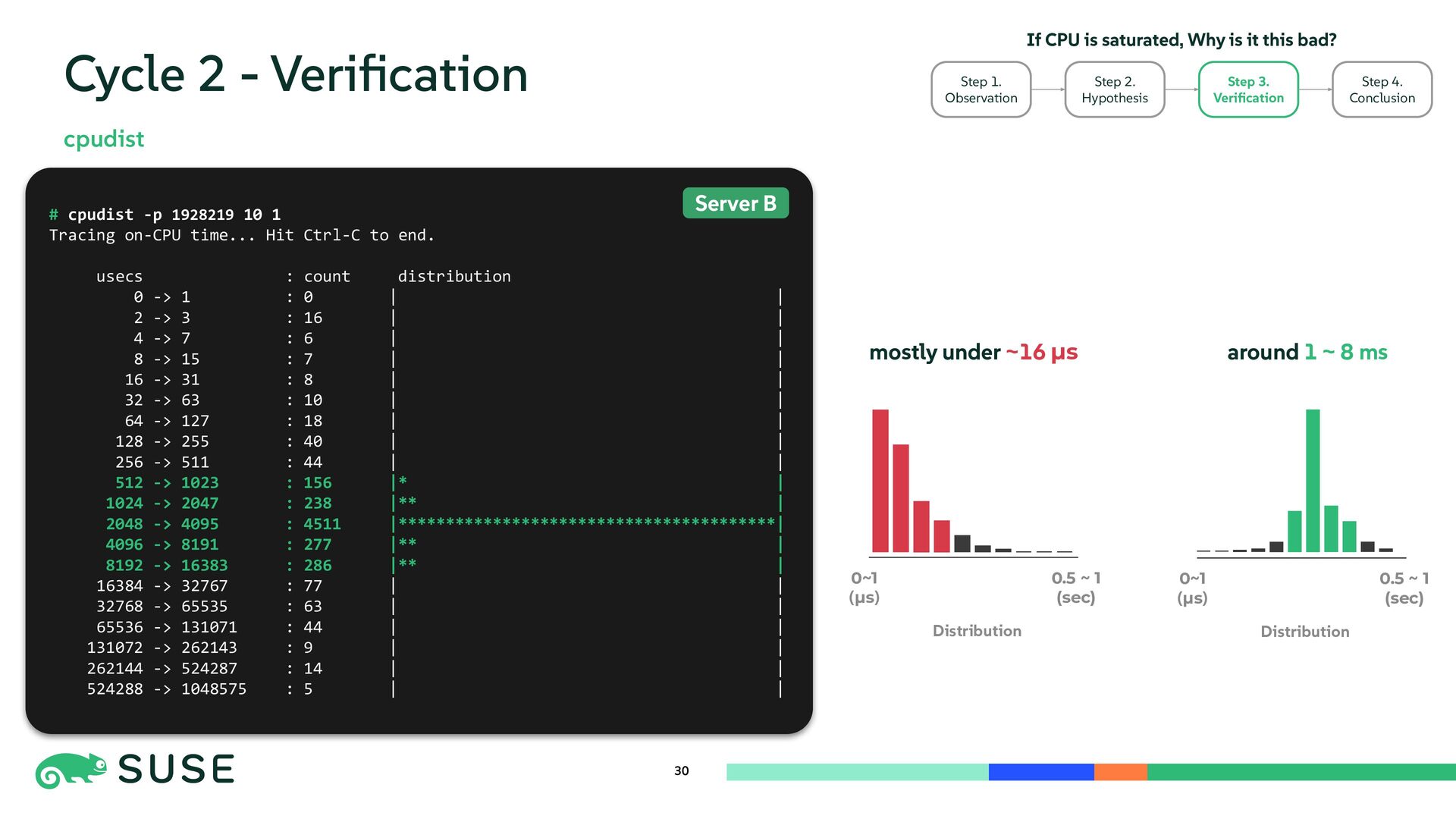{kind=link}
{kind=link}
{kind=link}
{kind=link}
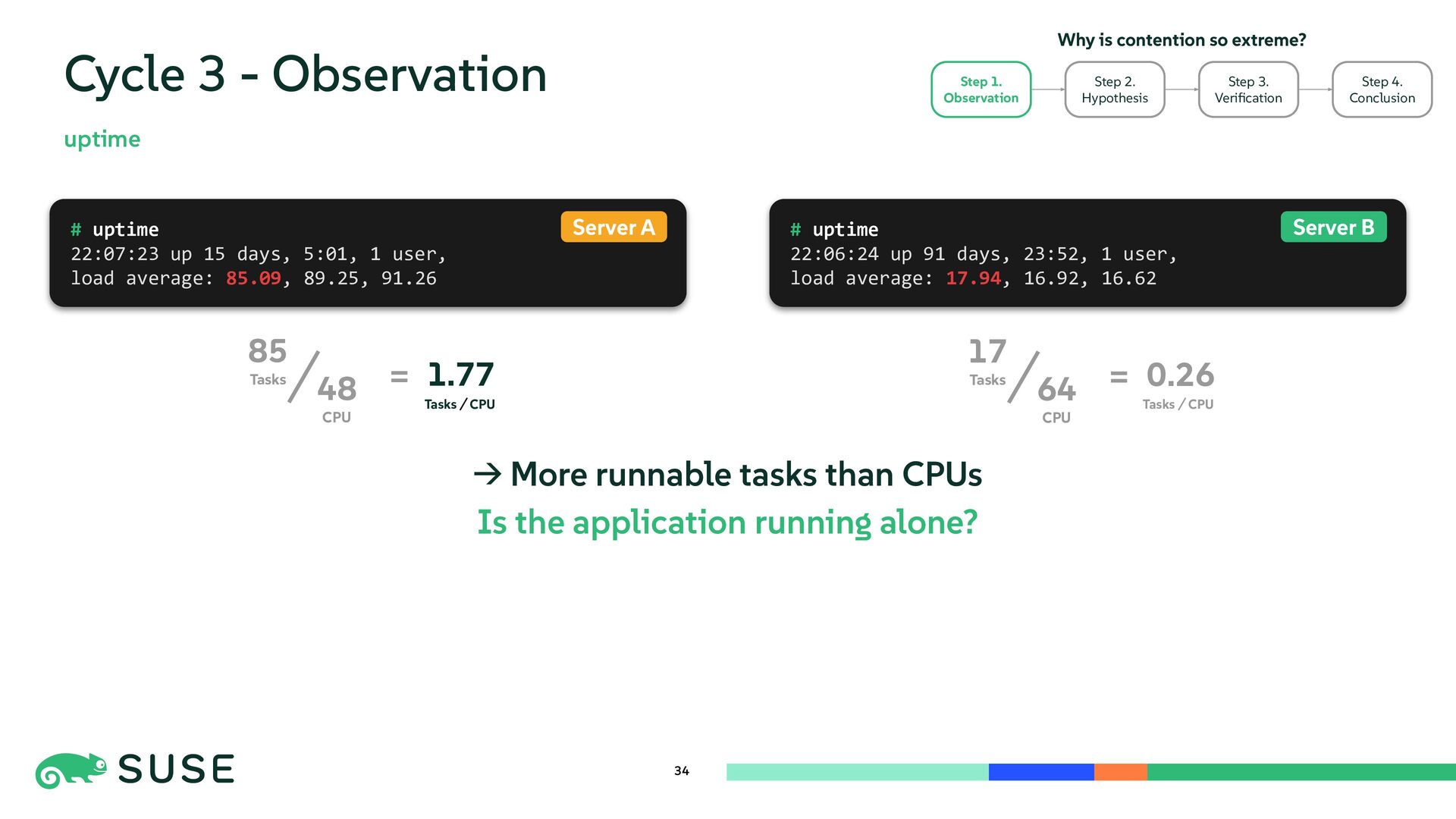{kind=link}
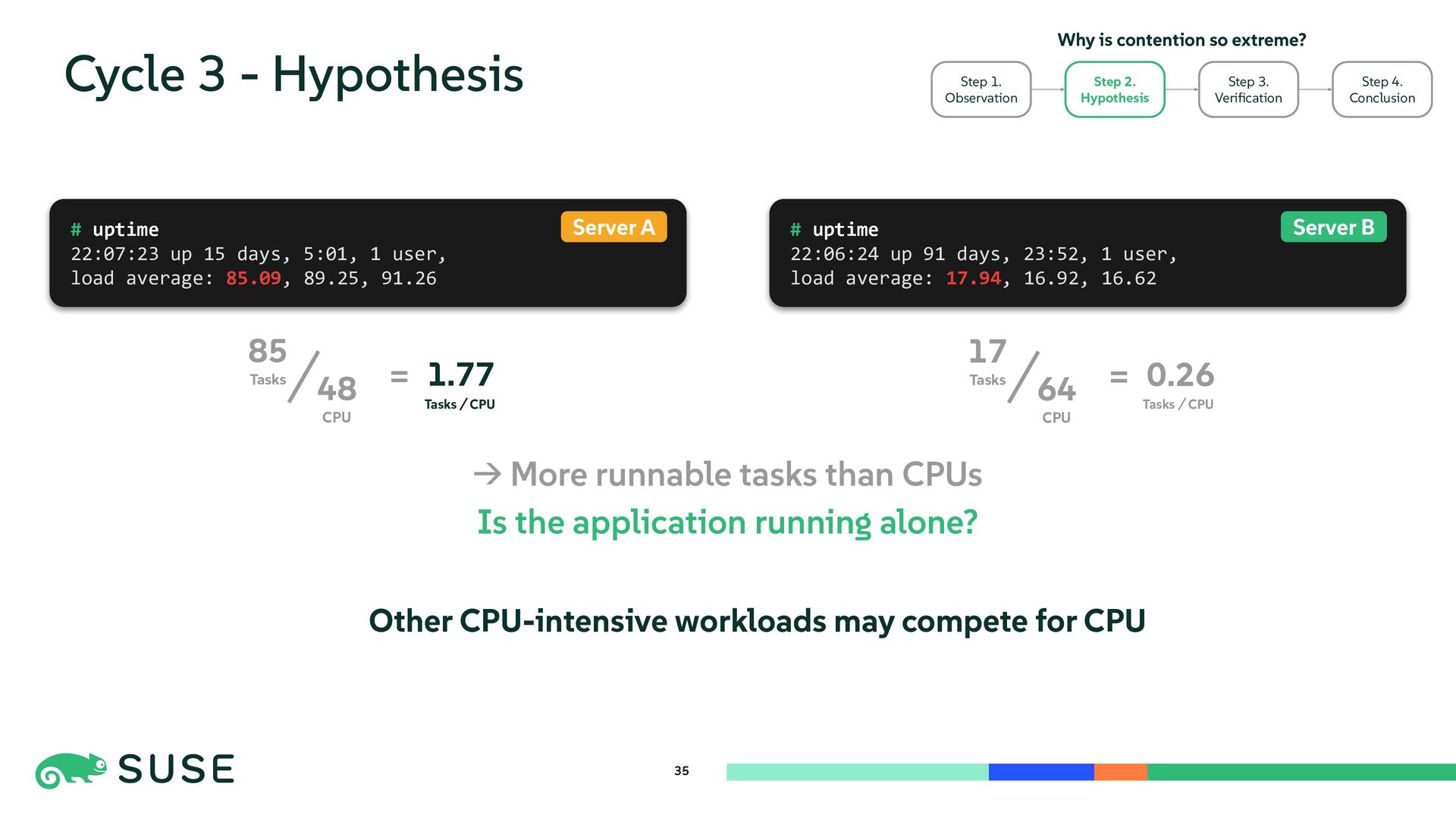{kind=link}
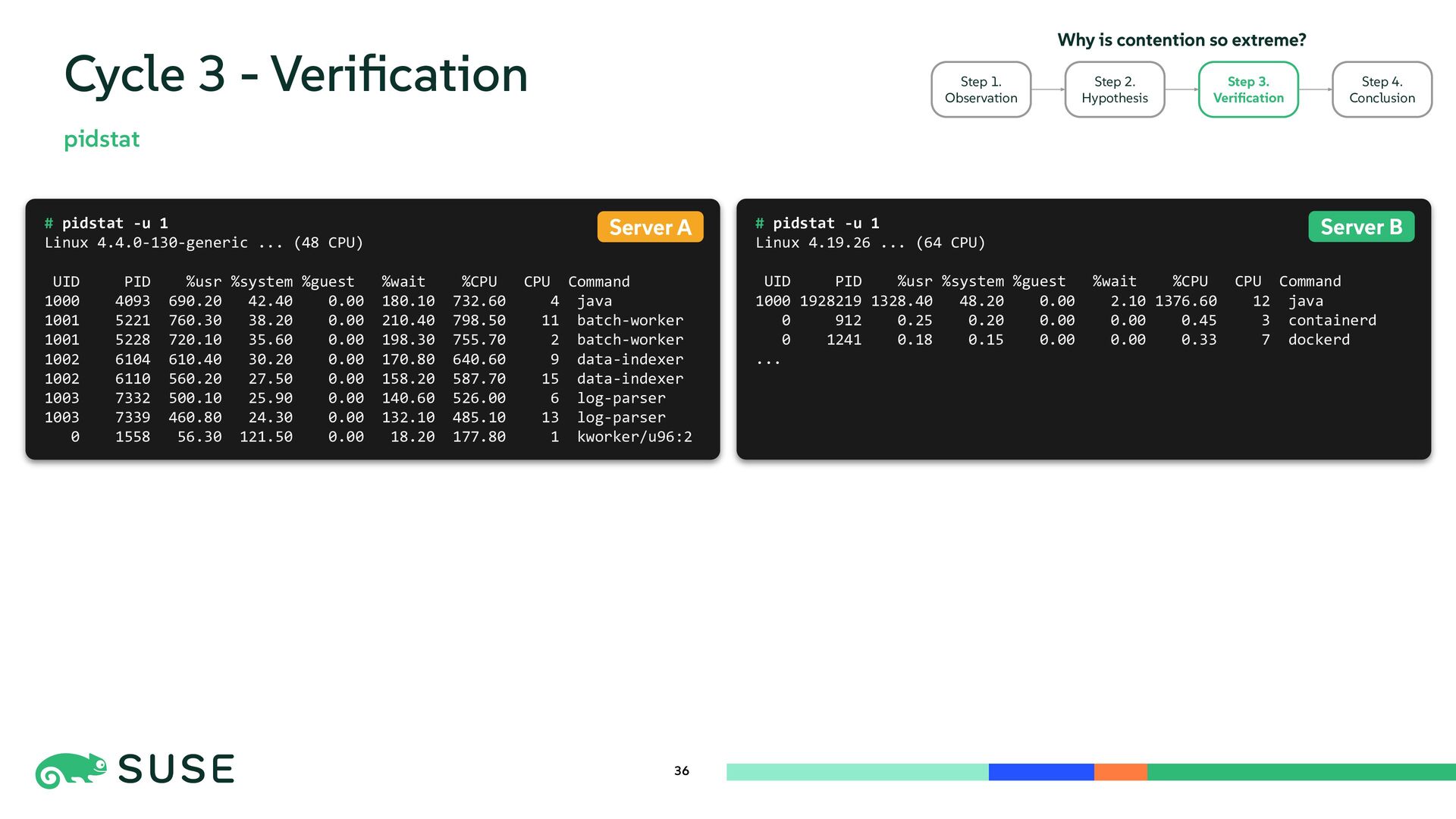{kind=link}
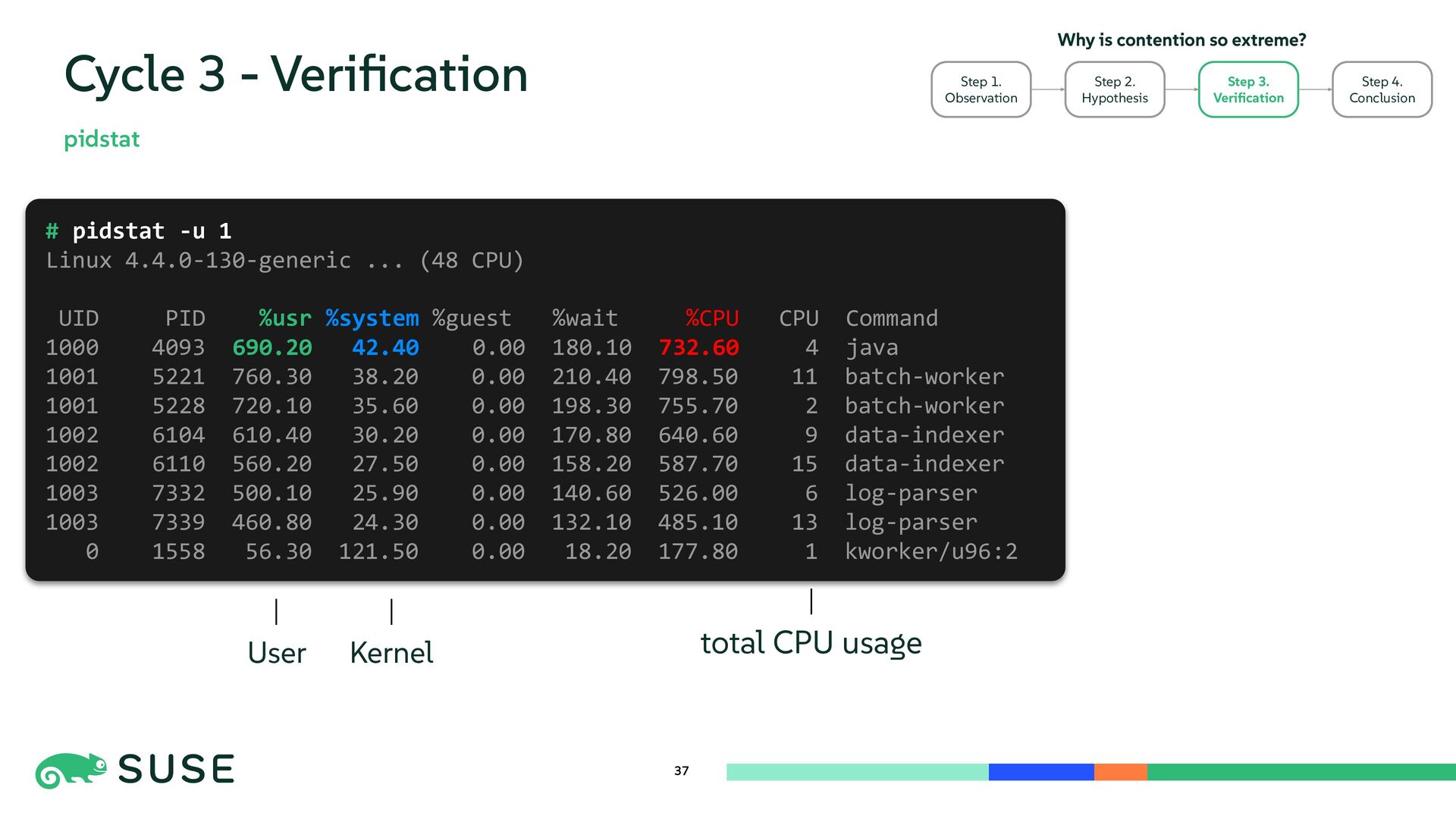{kind=link}
{kind=link}
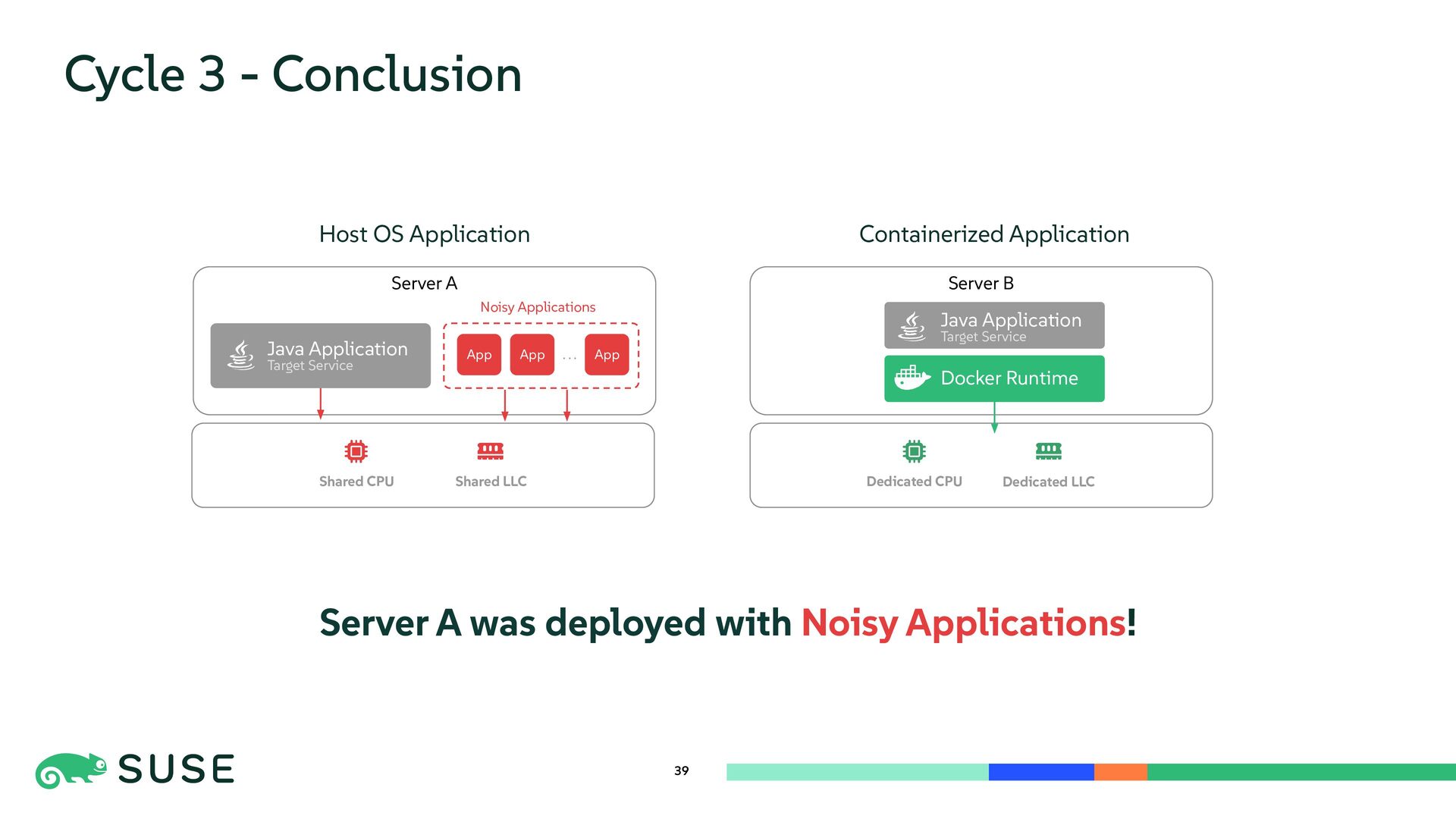{kind=link}
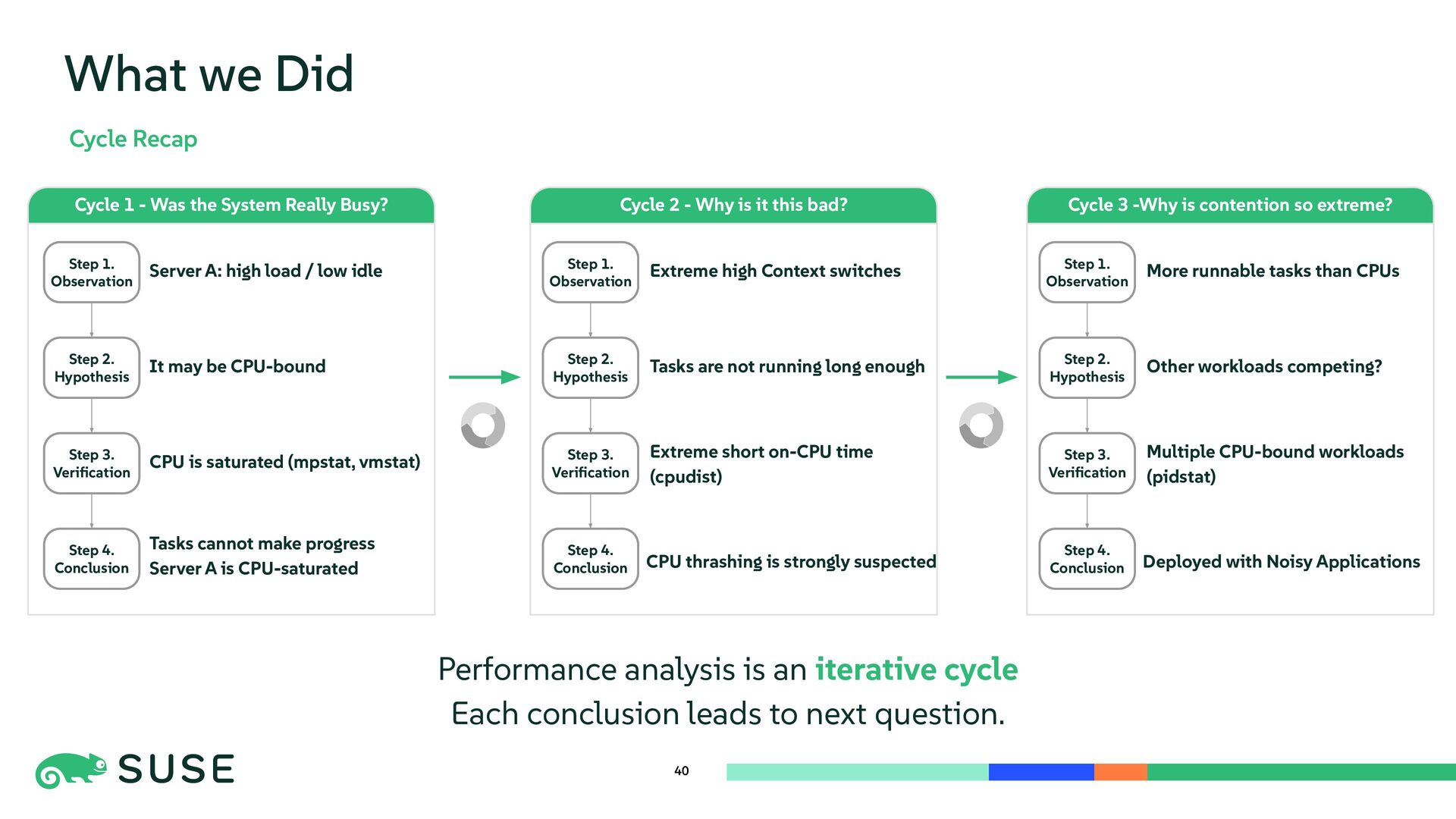{kind=link}
{kind=link}
{kind=link}
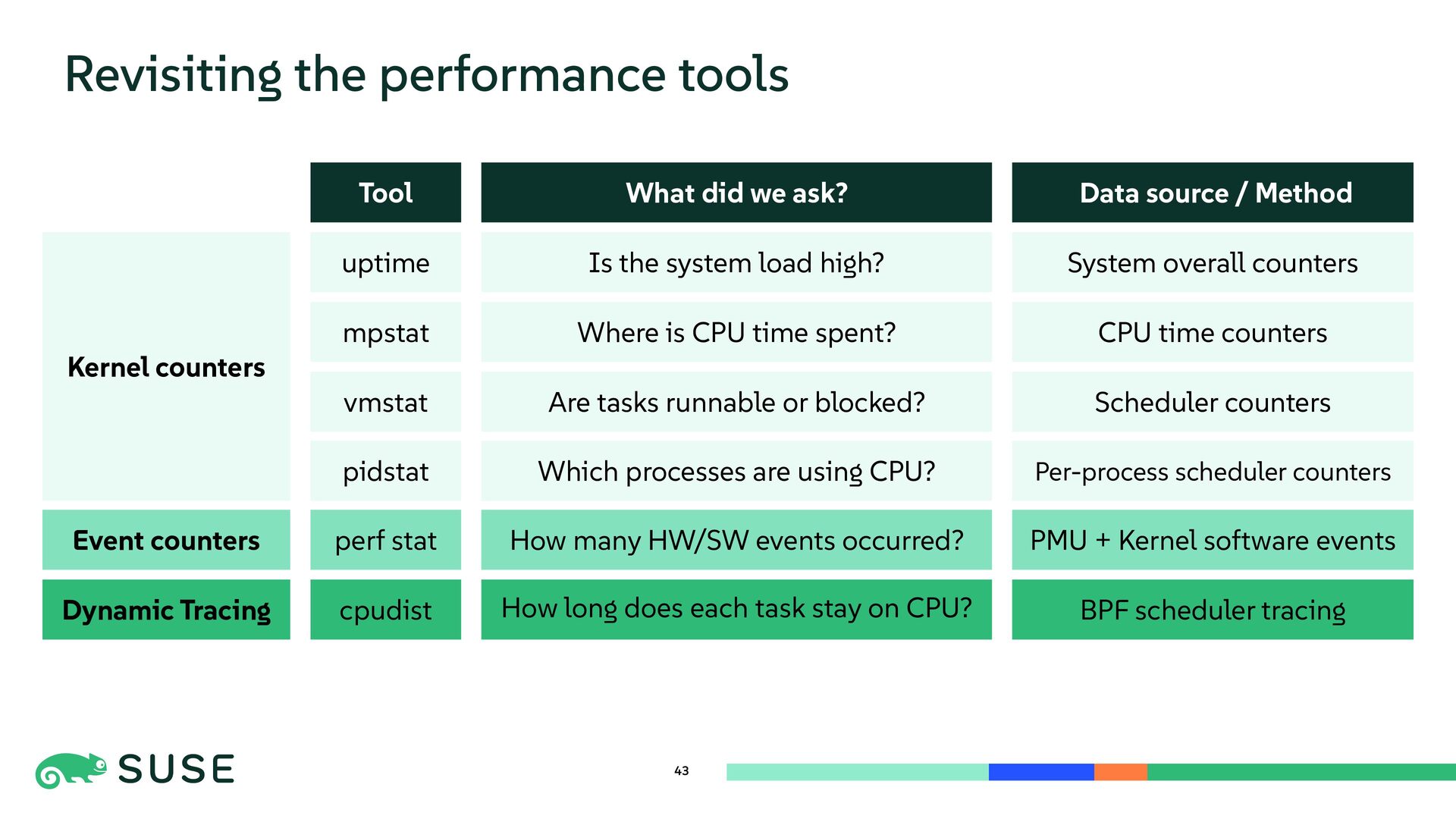{kind=link}
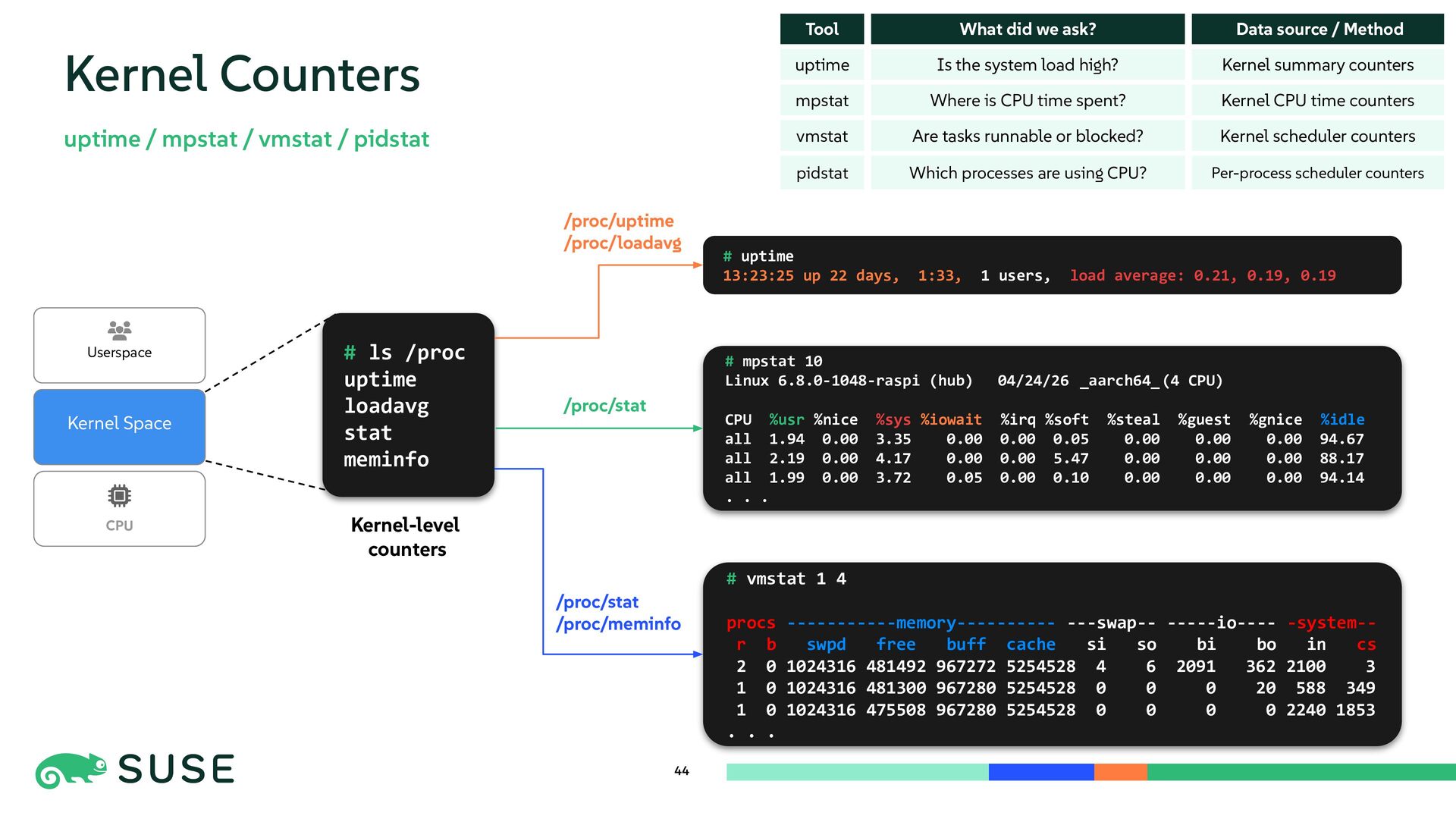{kind=link}
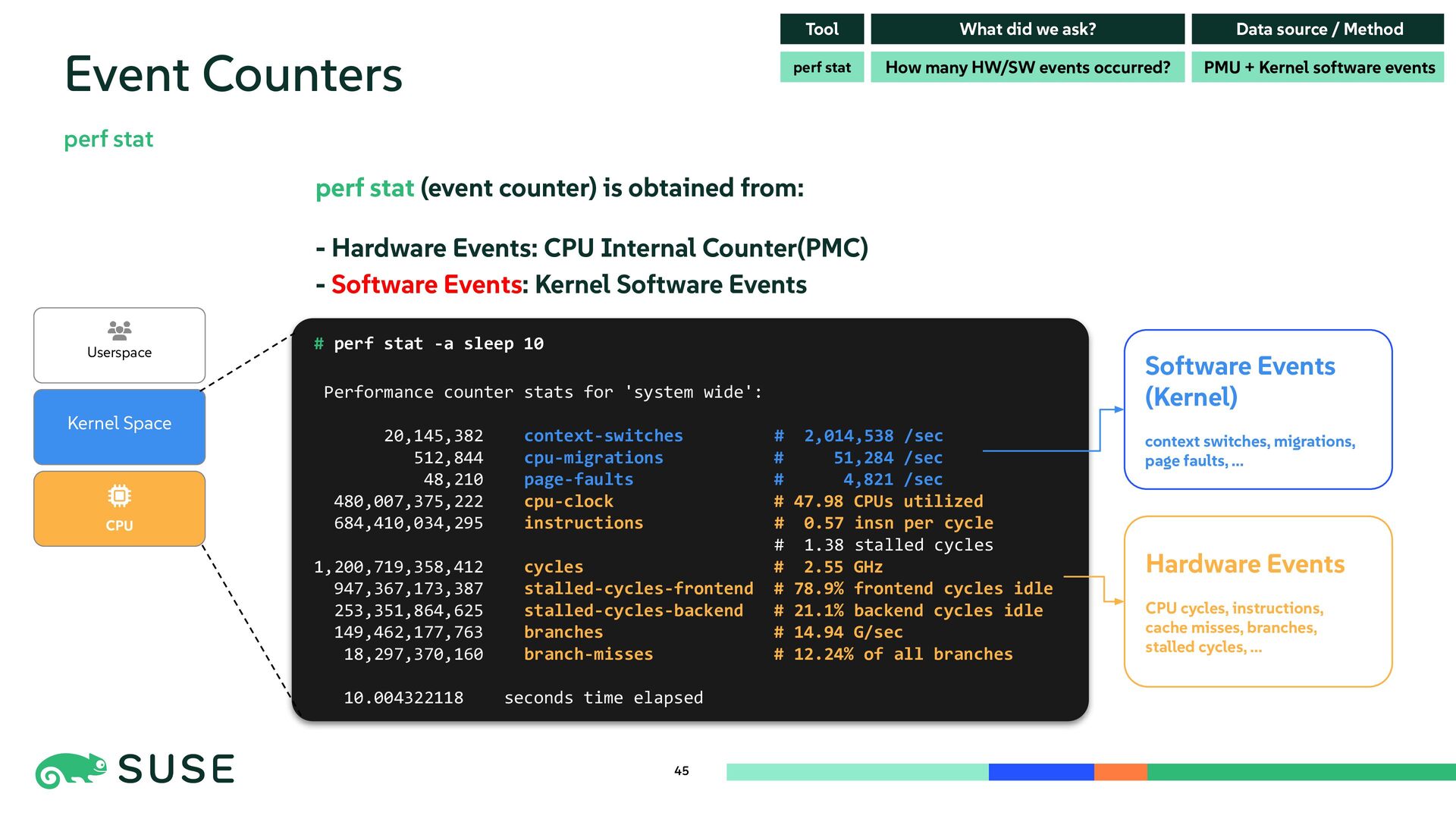{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
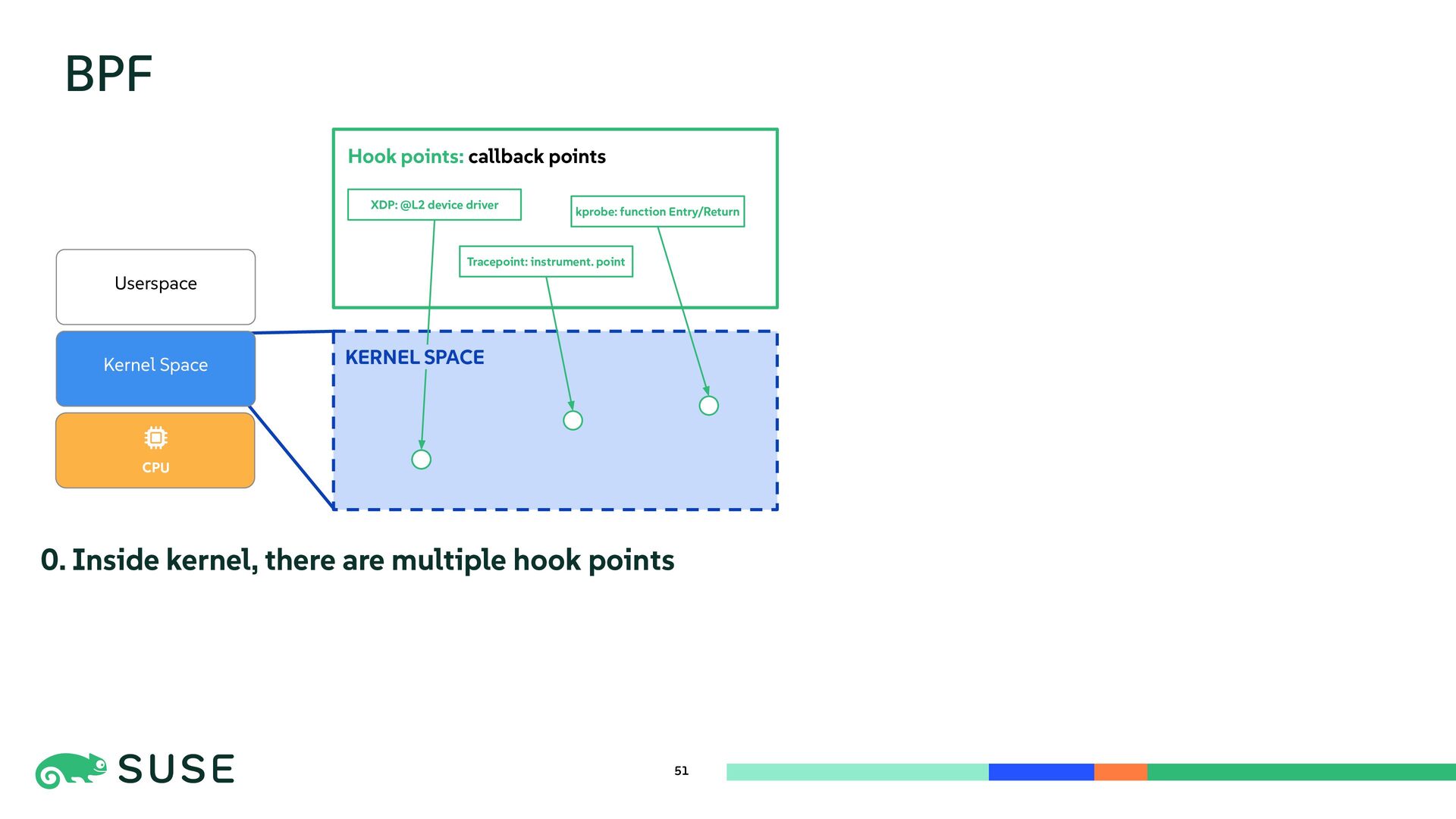{kind=link}
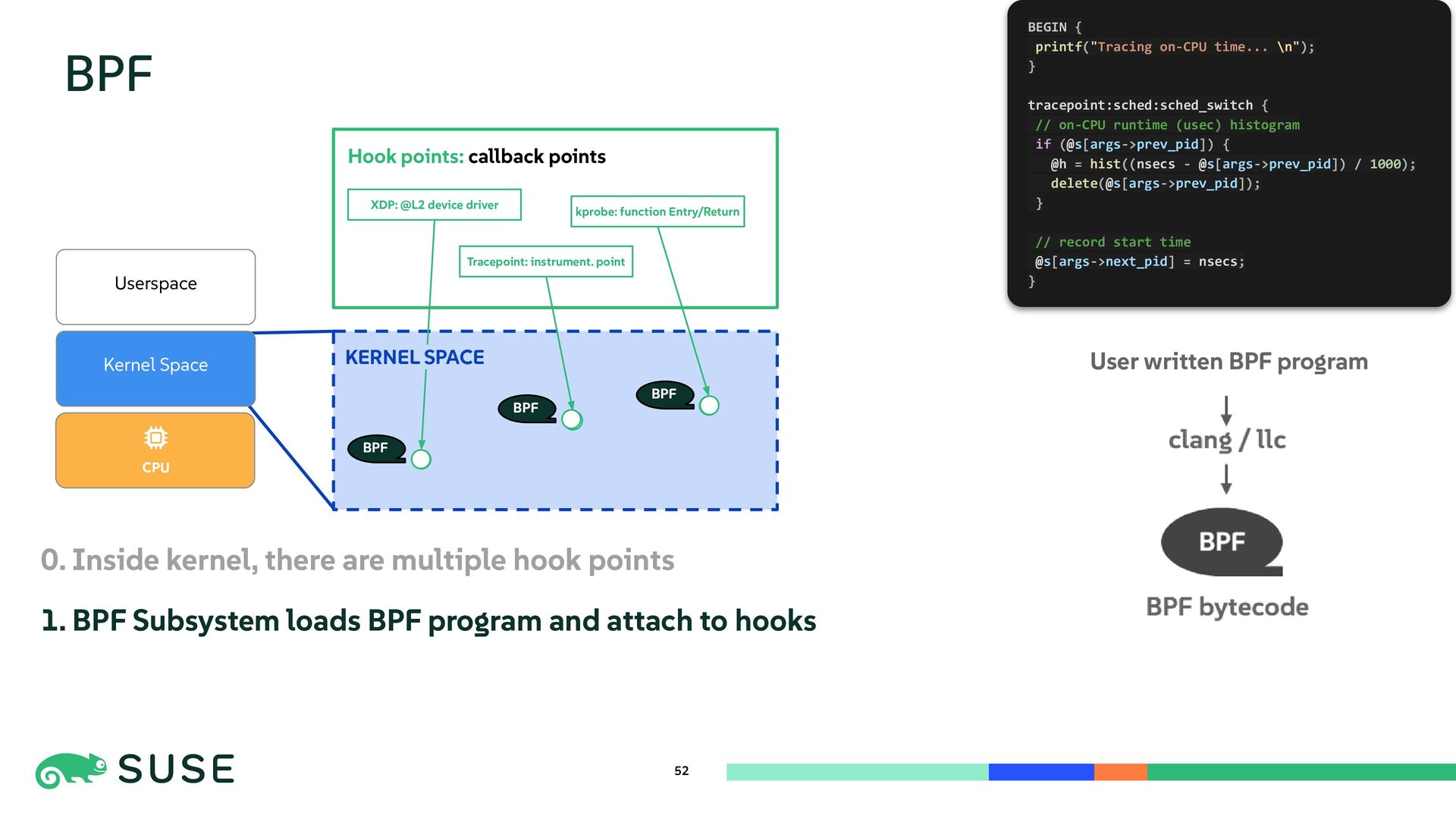{kind=link}
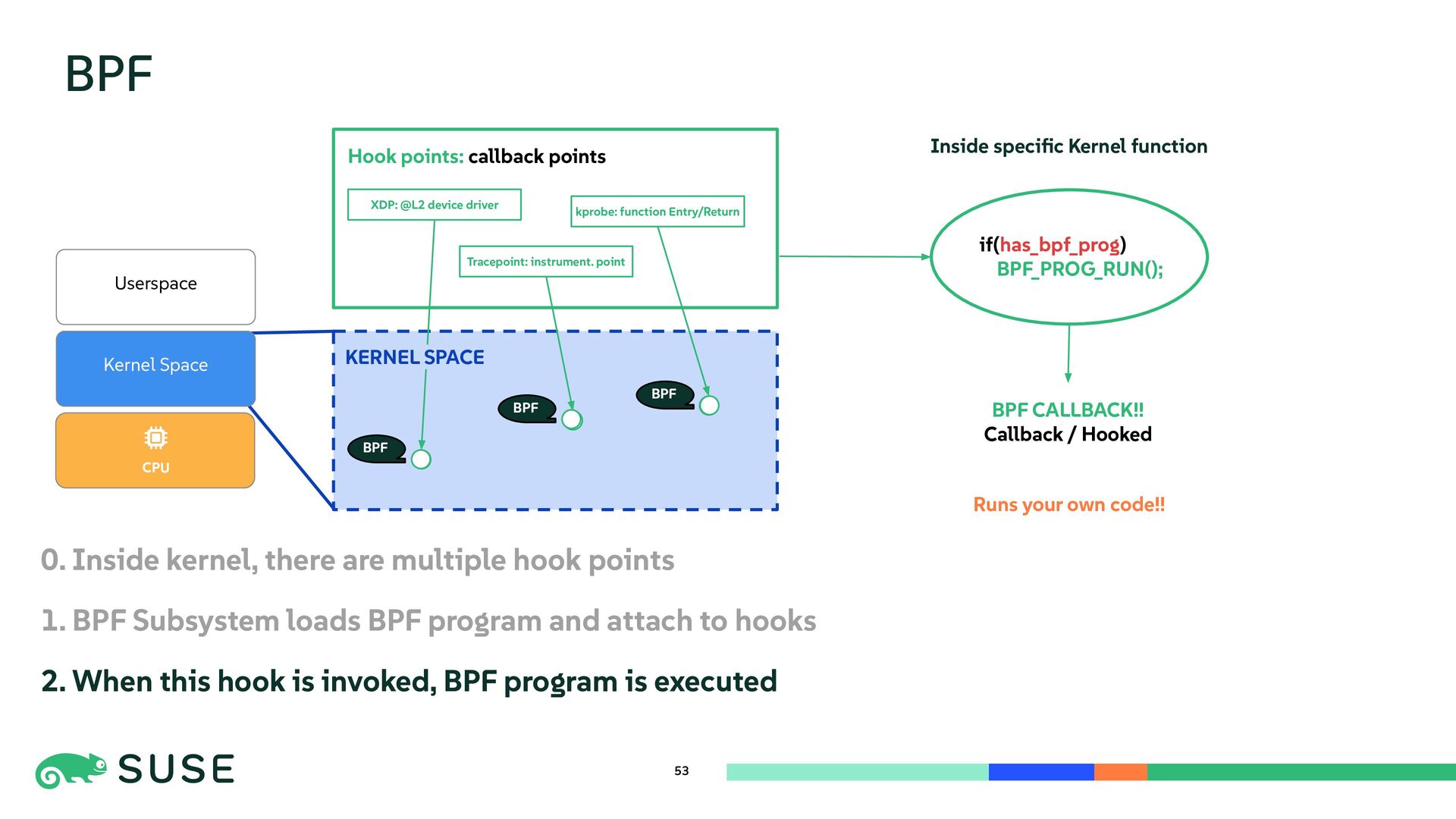{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}