Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIプラットフォームを運用し続けるための可観測性
Search
tanimuyk
June 04, 2026
Technology
1.4k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIプラットフォームを運用し続けるための可観測性
tanimuyk
June 04, 2026
More Decks by tanimuyk
See All by tanimuyk
4人目のSREはAgent
tanimuyk
0
430
Other Decks in Technology
See All in Technology
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
210
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
100
Claude Code 珍プレー好プレー
shinyasaita
0
320
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
220
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
620
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.4k
ADDF - ループエンジニアリングするフレームワークを作ったら/I Didn't Set Out to Build Loop Engineering, But ADDF Did
fruitriin
0
120
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
450
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.1k
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
230
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
Featured
See All Featured
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
560
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Navigating Team Friction
lara
192
16k
What's in a price? How to price your products and services
michaelherold
247
13k
We Are The Robots
honzajavorek
0
270
Ethics towards AI in product and experience design
skipperchong
2
330
The SEO identity crisis: Don't let AI make you average
varn
0
510
A Soul's Torment
seathinner
6
3.1k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
AI プラットフォームを"運用し続ける" ための可観測性 OpenTelemetry × Datadogによる実践 LayerX Ai Workforce事業部 SRE
谷村 祐樹 2026/06/05
谷村 祐樹( tanimu / @tanimuyk) © LayerX Inc. About Me
LayerX Ai Workforce事業部でSREやってます! これまでのキャリア インフラエンジニア → SRE / スクラムマスター → コンサルタント → SRE 趣味 野球観戦(Ai Workforce SREチームは全員野球好き) 育児しながらの投資エージェント作り 2
© LayerX Inc. 事業紹介 3
一緒にわいわいする仲間を募集してます!!! © LayerX Inc. We Are Hiring https://speakerdeck.com/layerx/ai-workforce-engineering-hiring-deck 4
アジェンダ © LayerX Inc. アジェンダ Ai Workforceのアーキテクチャ "運用し続ける"ための可観測性とは? OpenTelemetry ×
Datadogによる実践 まとめ 5
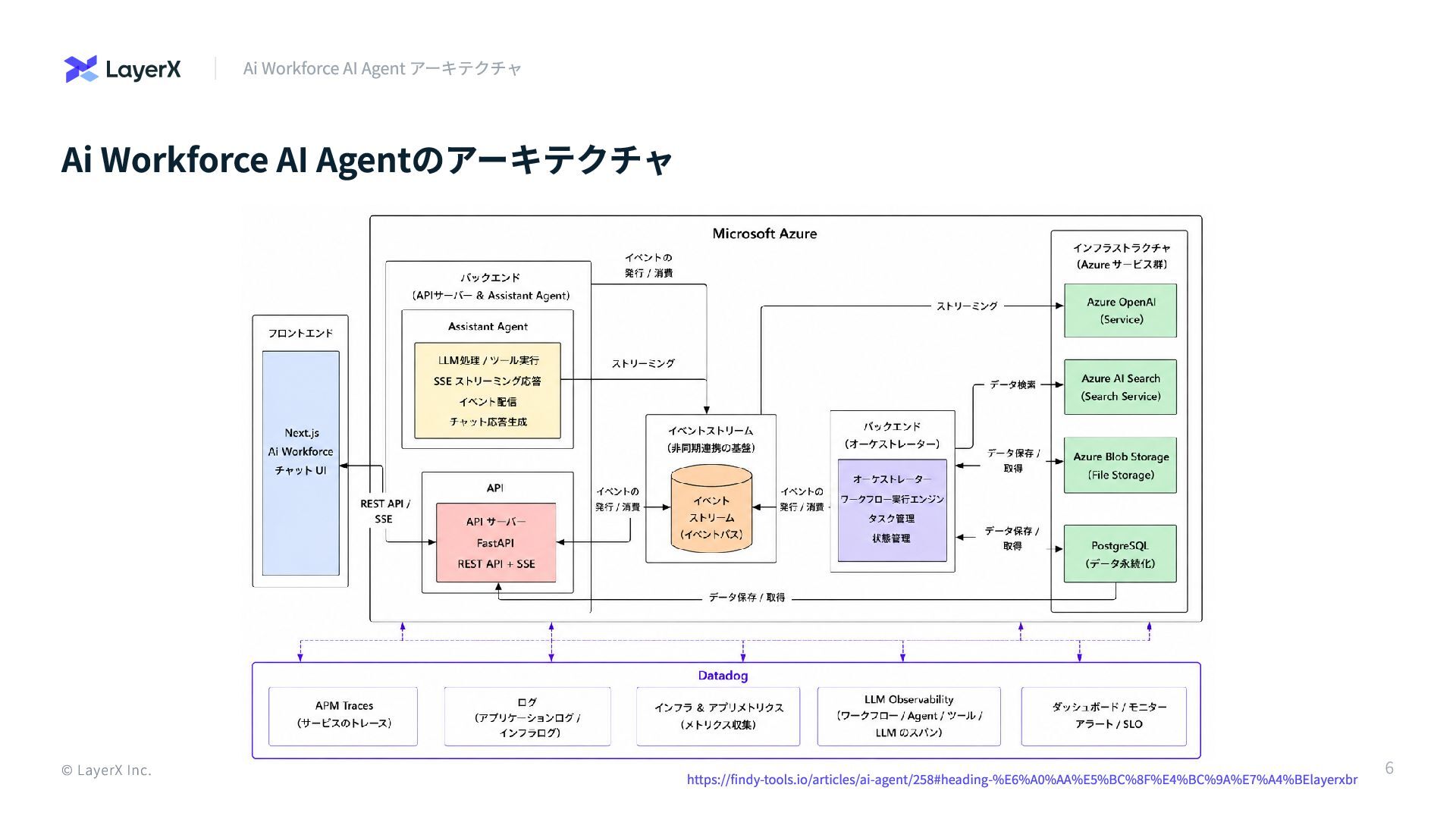
Ai Workforce AI Agentのアーキテクチャ © LayerX Inc. Ai Workforce AI
Agent アーキテクチャ https://findy-tools.io/articles/ai-agent/258#heading-%E6%A0%AA%E5%BC%8F%E4%BC%9A%E7%A4%BElayerxbr 6
"運用し続ける"ための可観測性とは?
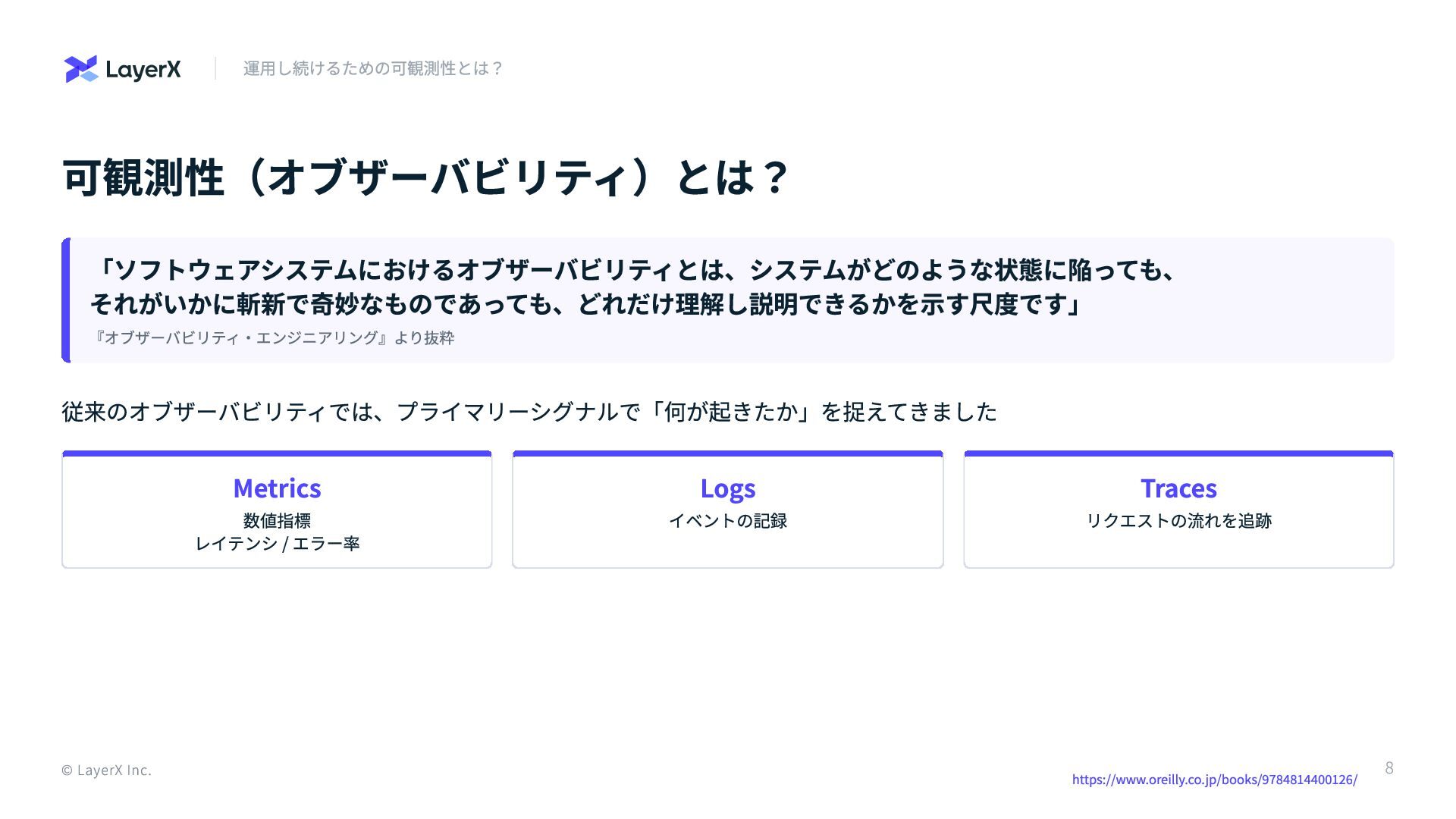
可観測性(オブザーバビリティ)とは? 「ソフトウェアシステムにおけるオブザーバビリティとは、システムがどのような状態に陥っても、 それがいかに斬新で奇妙なものであっても、どれだけ理解し説明できるかを示す尺度です」 『オブザーバビリティ・エンジニアリング』より抜粋 従来のオブザーバビリティでは、プライマリーシグナルで「何が起きたか」を捉えてきました Metrics 数値指標 レイテンシ / エラー率
Logs イベントの記録 Traces リクエストの流れを追跡 © LayerX Inc. 運用し続けるための可観測性とは? https://www.oreilly.co.jp/books/9784814400126/ 8
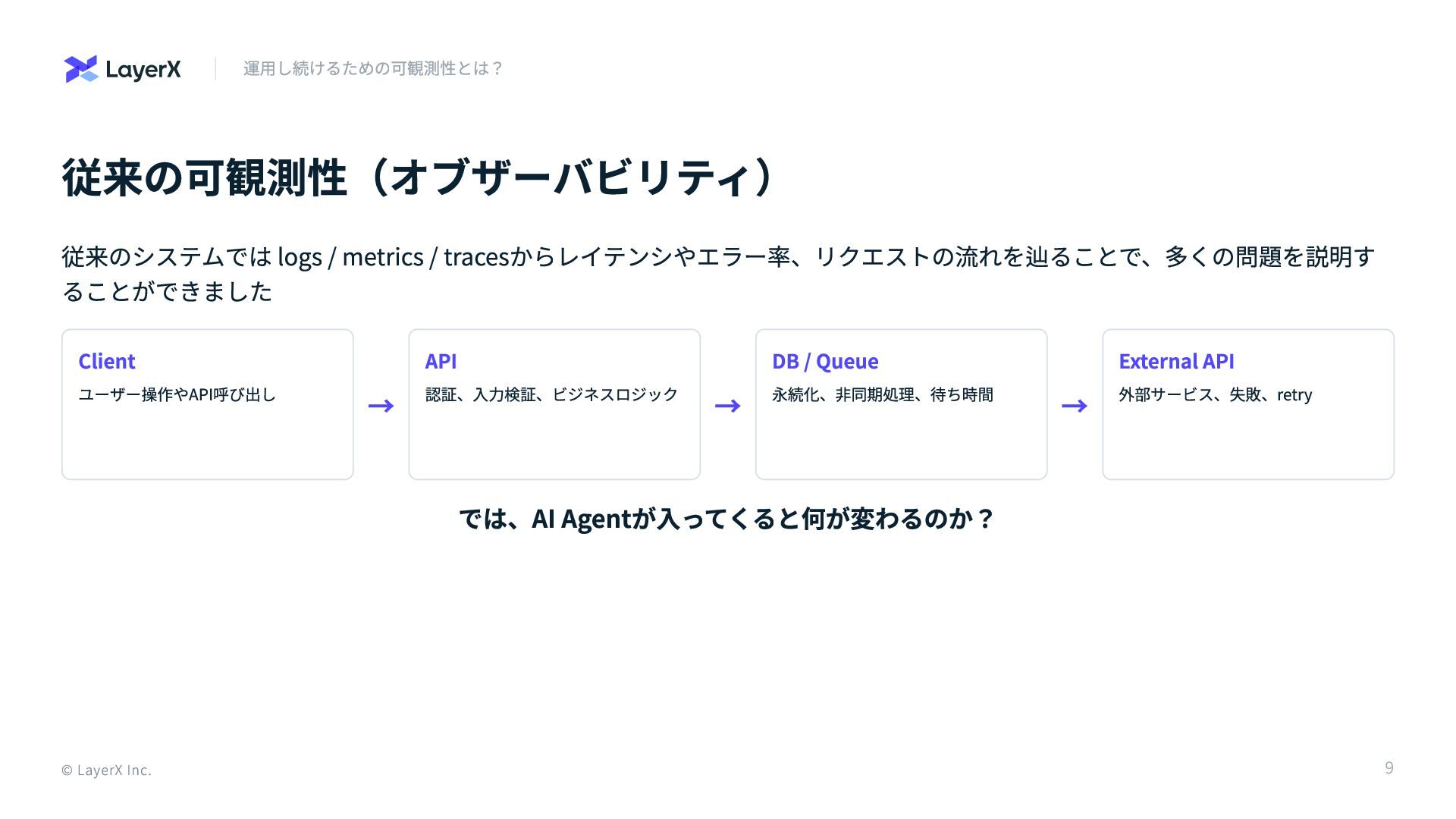
従来の可観測性(オブザーバビリティ) 従来のシステムでは logs / metrics / tracesからレイテンシやエラー率、リクエストの流れを辿ることで、多くの問題を説明す ることができました Client ユーザー操作やAPI呼び出し
→ API 認証、入力検証、ビジネスロジック → DB / Queue 永続化、非同期処理、待ち時間 → External API 外部サービス、失敗、retry では、AI Agentが入ってくると何が変わるのか? © LayerX Inc. 運用し続けるための可観測性とは? 9
AI Agentは「なぜそうなったのか?」を知る必要がある AI Agentを扱いはじめると、リクエストの中で完結しない処理が増えていきます。Agentが判断し、toolを呼び、LLMに問 い合わせ、必要に応じて非同期に後続処理へ渡っていく ↓ もともと複雑だったものがさらに複雑に... 運用はどんどん大変になっていく... © LayerX
Inc. 運用し続けるための可観測性とは? 最終的な結果だけを見ても、どこで時間がかかったのか分からない 失敗したときに、LLMなのか、toolなのか、検索なのか、queueなのかを切り分けたい さらに、 「なぜその判断をしたのか」も見る必要がある 10
"運用し続ける"ために必要な可観測性 "運用し続ける"とは、 進化し続けるプロダクト / AI Agentで何が起きているかを常に「説明できる」状態かつ、機密情報を漏らすこ となく「安全に調査」でき、属人化せずに「チームで改善し続けられる」こと。と考えています 説明できる 最終出力だけでなく、どのLLM判断・tool・検 索・非同期処理で何が起きたかを辿れる
× 安全に調査できる お客様情報や文書本文を不用意に露出させず、 実行の構造と状態から調査できる × チームで扱える SREだけでなく、SWE / FDE / QAが同じtraceを 見て、同じ言葉で調査・改善できる © LayerX Inc. 運用し続けるための可観測性とは? 11
OpenTelemetry × Datadogで"運用し続ける"可観測性を実現する なぜOpenTelemetry × Datadogなのか? 計装の標準ライブラリに従いながら、Datadog APM Trace等の良さを享受するこ とで、設計・実装しやすく運用しやすい、いいとこ取りの組み合わせを採用しました
OpenTelemetry:計装の標準化 Datadog:調査・監視・改善 説明できる Agent実行をspanにする workflow / agent / task / tool / search / LLM callをspanと属性 で表し、非同期境界はSpan Linksで関連づける 同じ実行を辿る APM / Trace Explorer / LLMObsで、遅延・tool失敗・検索不足 を同じ実行から辿る 安全に調査できる 残すmetadataを決める workflow、model、duration、error、retryなど、本文以外で 切り分けに使う属性を残す ddtraceで送信前に守る LLMObs span processorでprompt / response本文、tool引 数・結果をmaskし、metadataで絞る チームで扱える 計装を開発導線に置く 共通telemetry package、docs/rules、Coding Agentの共通ル ールに計装ルールを入れる 迷わない導線にする Coding Agentには共通ルールとdev MCP、人にはDatadogと SRE Agentの調査導線を用意する © LayerX Inc. 実践の地図 12
説明できる状態をつくる
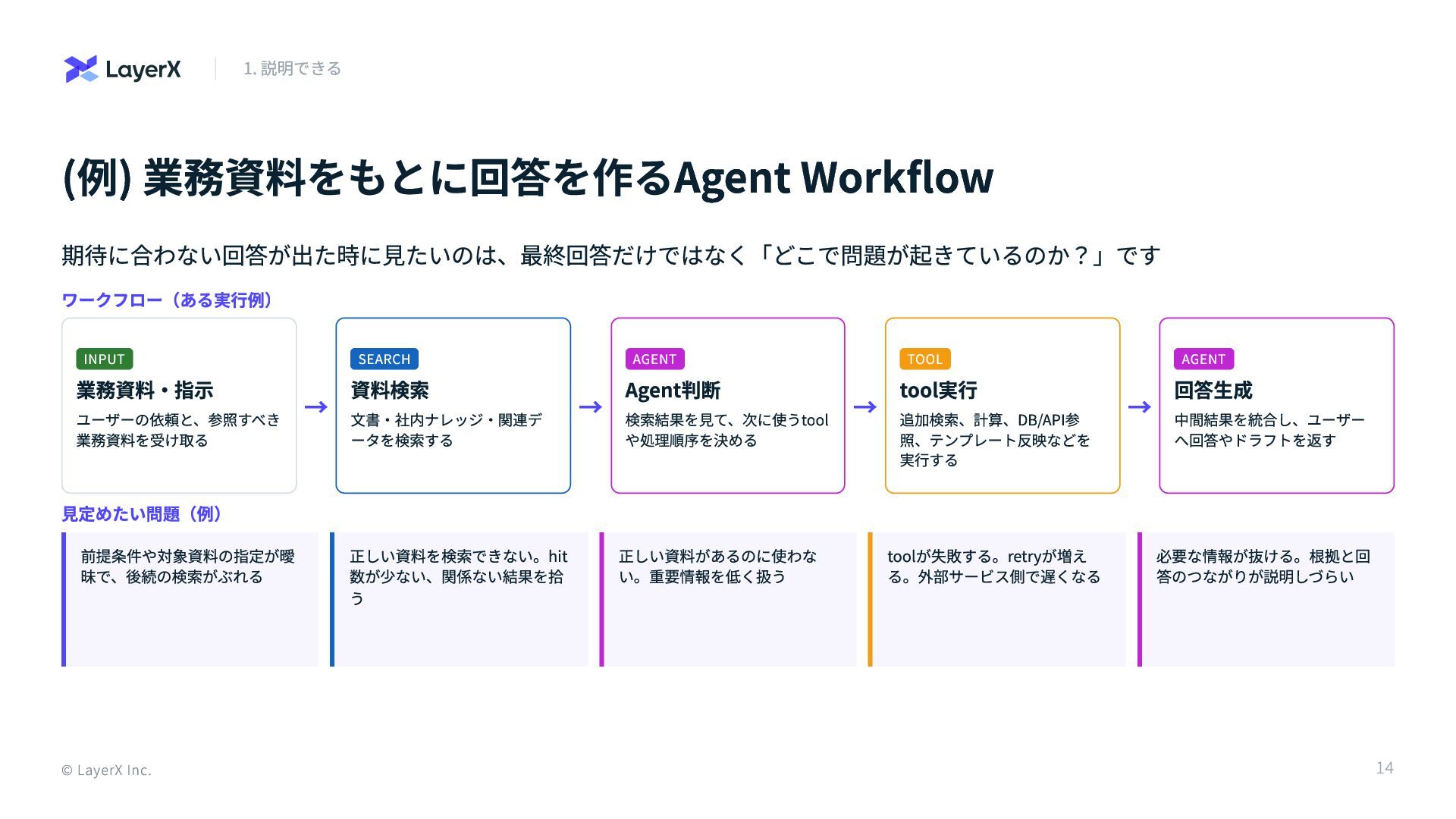
(例) 業務資料をもとに回答を作るAgent Workflow 期待に合わない回答が出た時に見たいのは、最終回答だけではなく「どこで問題が起きているのか?」です ワークフロー(ある実行例) INPUT 業務資料・指示 ユーザーの依頼と、参照すべき 業務資料を受け取る →
SEARCH 資料検索 文書・社内ナレッジ・関連デ ータを検索する → AGENT Agent判断 検索結果を見て、次に使うtool や処理順序を決める → TOOL tool実行 追加検索、計算、DB/API参 照、テンプレート反映などを 実行する → AGENT 回答生成 中間結果を統合し、ユーザー へ回答やドラフトを返す 見定めたい問題(例) 前提条件や対象資料の指定が曖 昧で、後続の検索がぶれる 正しい資料を検索できない。hit 数が少ない、関係ない結果を拾 う 正しい資料があるのに使わな い。重要情報を低く扱う toolが失敗する。retryが増え る。外部サービス側で遅くなる 必要な情報が抜ける。根拠と回 答のつながりが説明しづらい © LayerX Inc. 1. 説明できる 14
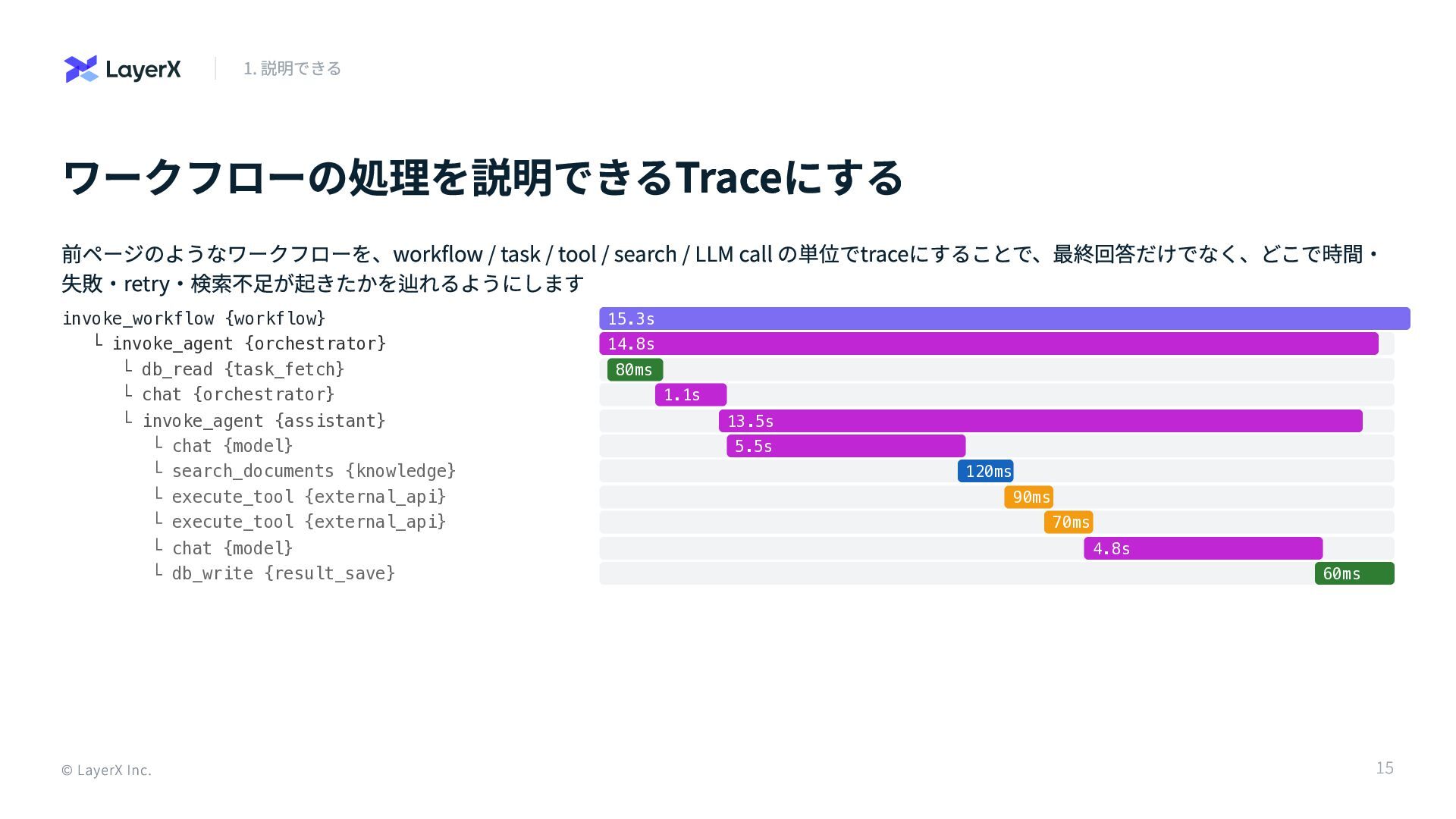
ワークフローの処理を説明できるTraceにする 前ページのようなワークフローを、workflow / task / tool / search / LLM
call の単位でtraceにすることで、最終回答だけでなく、どこで時間・ 失敗・retry・検索不足が起きたかを辿れるようにします invoke_workflow {workflow} └ invoke_agent {orchestrator} └ db_read {task_fetch} └ chat {orchestrator} └ invoke_agent {assistant} └ chat {model} └ search_documents {knowledge} └ execute_tool {external_api} └ execute_tool {external_api} └ chat {model} └ db_write {result_save} © LayerX Inc. 1. 説明できる 15.3s 14.8s 80ms 1.1s 13.5s 5.5s 120ms 90ms 70ms 4.8s 60ms 15
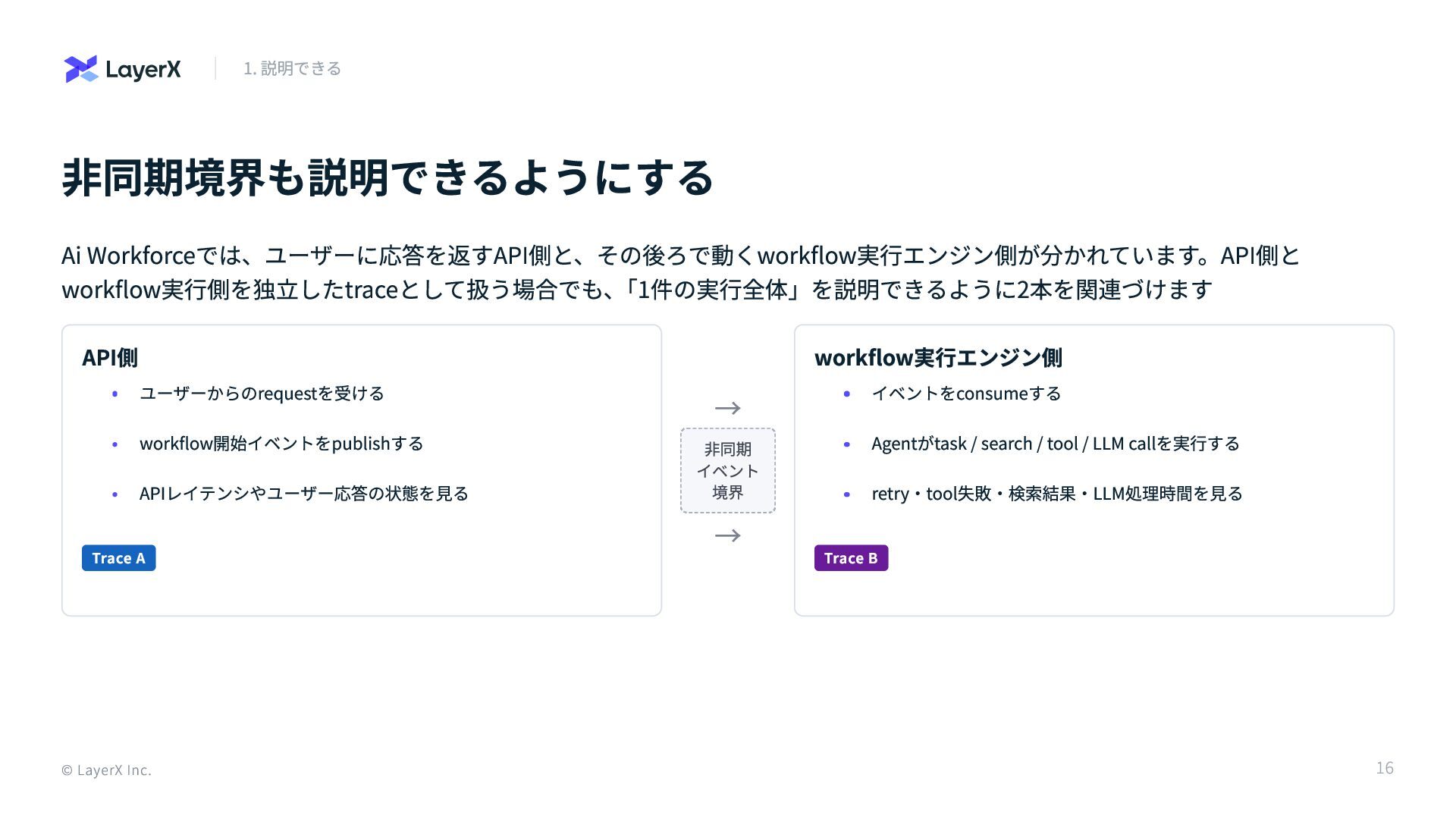
非同期境界も説明できるようにする Ai Workforceでは、ユーザーに応答を返すAPI側と、その後ろで動くworkflow実行エンジン側が分かれています。API側と workflow実行側を独立したtraceとして扱う場合でも、 「1件の実行全体」を説明できるように2本を関連づけます API側 Trace A → 非同期
イベント 境界 → workflow実行エンジン側 Trace B © LayerX Inc. 1. 説明できる ユーザーからのrequestを受ける workflow開始イベントをpublishする APIレイテンシやユーザー応答の状態を見る イベントをconsumeする Agentがtask / search / tool / LLM callを実行する retry・tool失敗・検索結果・LLM処理時間を見る 16
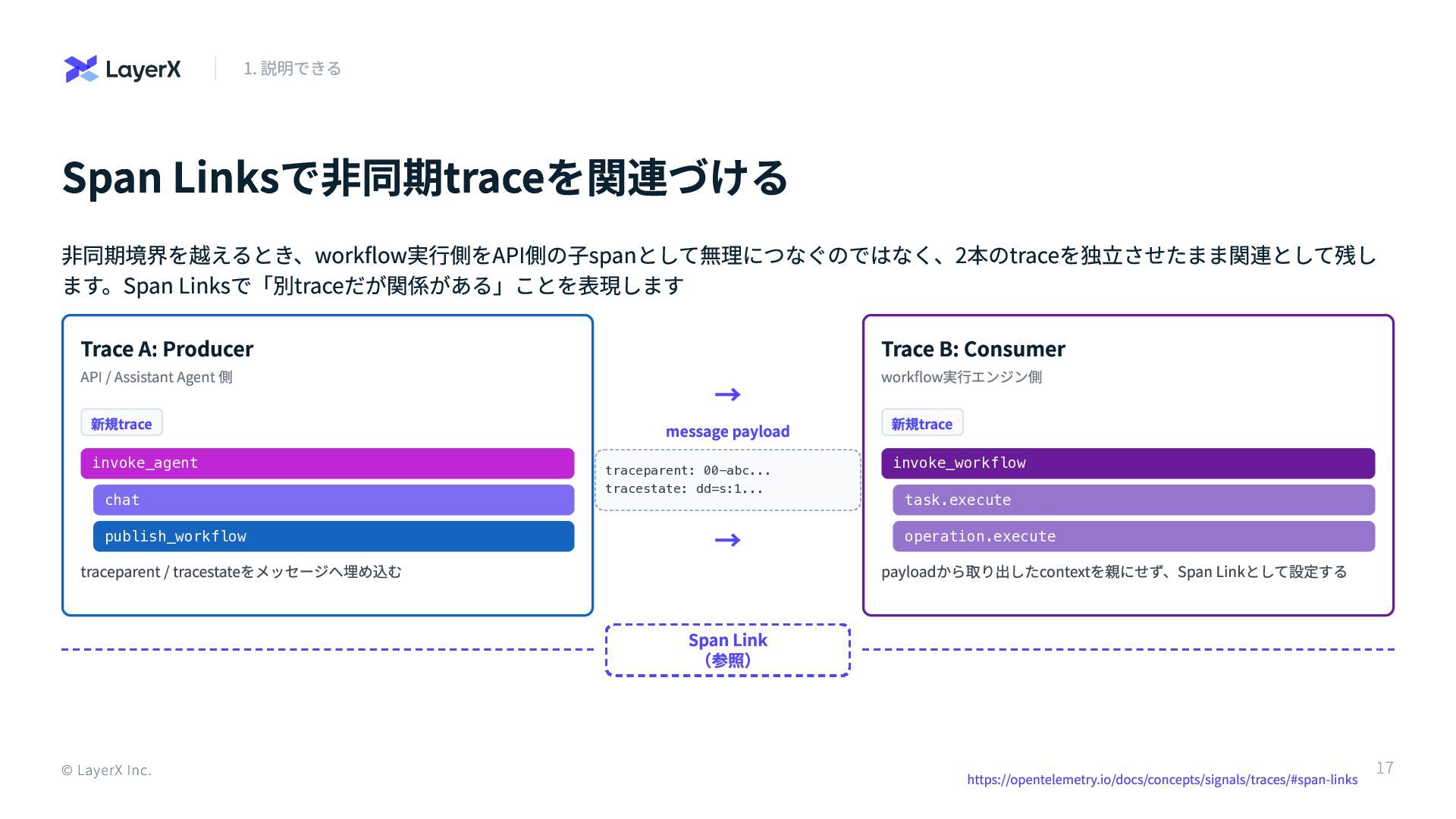
Span Linksで非同期traceを関連づける 非同期境界を越えるとき、workflow実行側をAPI側の子spanとして無理につなぐのではなく、2本のtraceを独立させたまま関連として残し ます。Span Linksで「別traceだが関係がある」ことを表現します Trace A: Producer API /
Assistant Agent 側 新規trace invoke_agent chat publish_workflow traceparent / tracestateをメッセージへ埋め込む → message payload traceparent: 00-abc... tracestate: dd=s:1... → Trace B: Consumer workflow実行エンジン側 新規trace invoke_workflow task.execute operation.execute payloadから取り出したcontextを親にせず、Span Linkとして設定する Span Link (参照) © LayerX Inc. 1. 説明できる https://opentelemetry.io/docs/concepts/signals/traces/#span-links 17
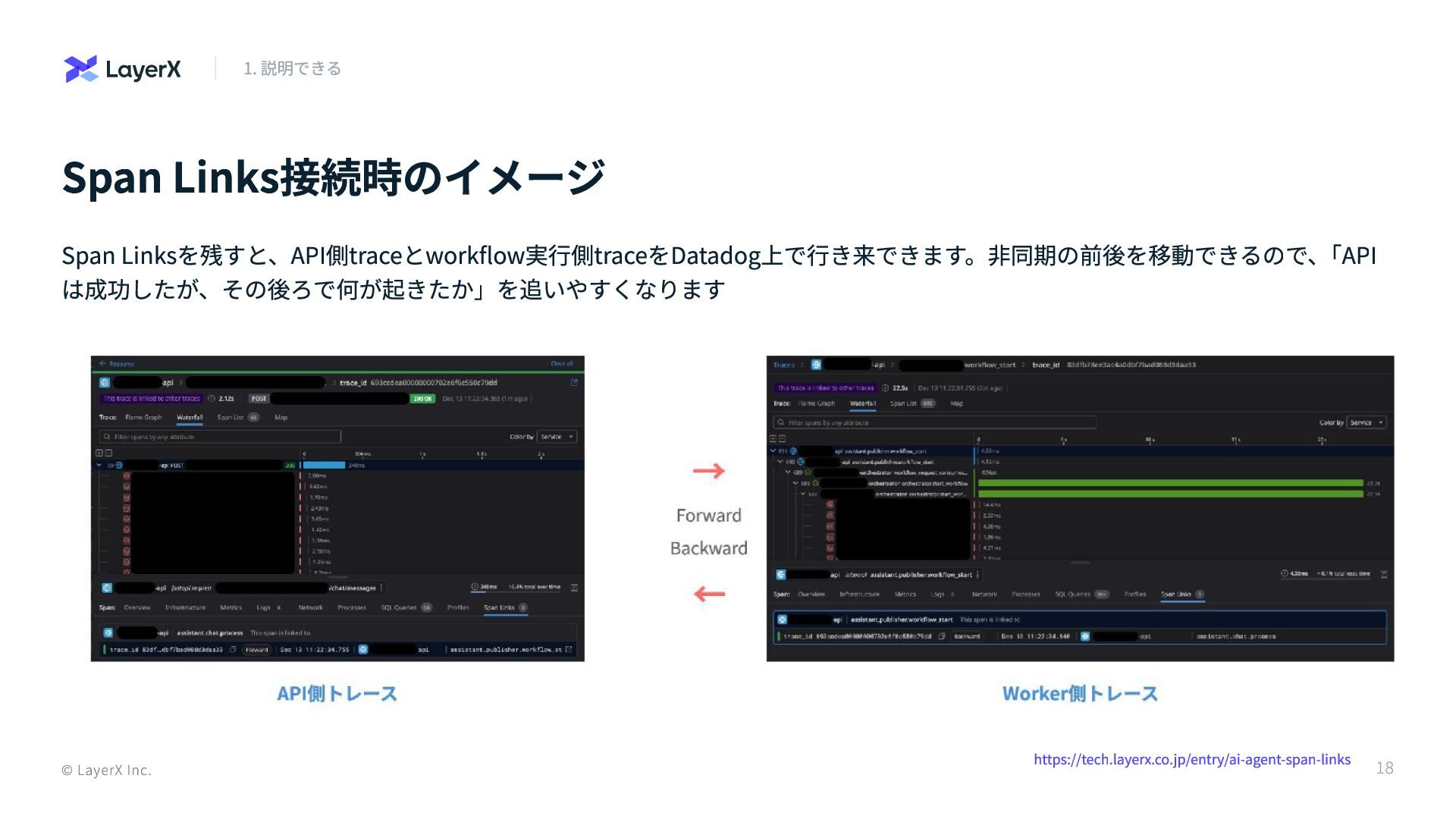
Span Links接続時のイメージ Span Linksを残すと、API側traceとworkflow実行側traceをDatadog上で行き来できます。非同期の前後を移動できるので、 「API は成功したが、その後ろで何が起きたか」を追いやすくなります https://tech.layerx.co.jp/entry/ai-agent-span-links © LayerX Inc.
1. 説明できる 18
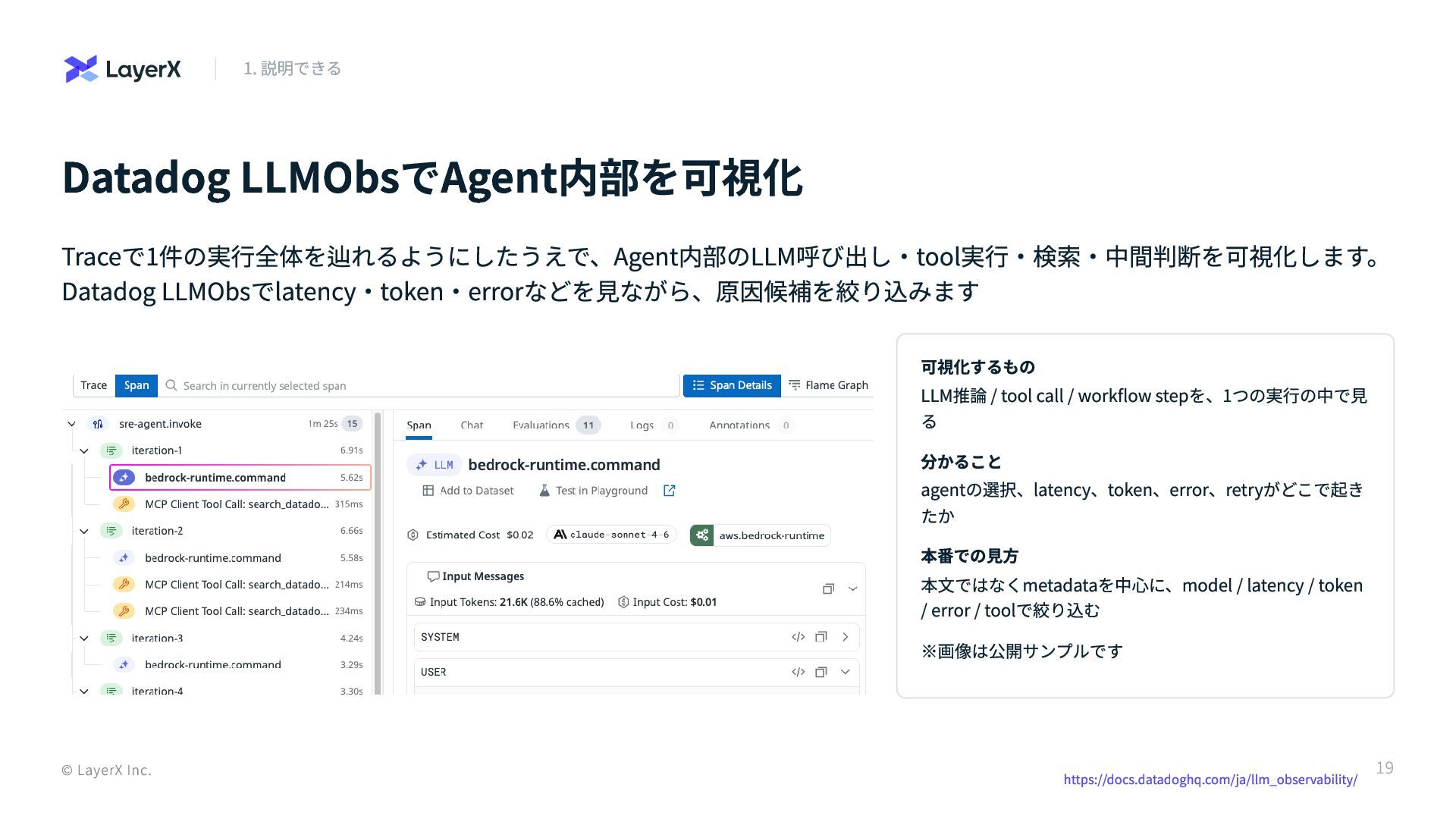
Datadog LLMObsでAgent内部を可視化 Traceで1件の実行全体を辿れるようにしたうえで、Agent内部のLLM呼び出し・tool実行・検索・中間判断を可視化します。 Datadog LLMObsでlatency・token・errorなどを見ながら、原因候補を絞り込みます 可視化するもの LLM推論 / tool call
/ workflow stepを、1つの実行の中で見 る 分かること agentの選択、latency、token、error、retryがどこで起き たか 本番での見方 本文ではなくmetadataを中心に、model / latency / token / error / toolで絞り込む ※画像は公開サンプルです © LayerX Inc. 1. 説明できる https://docs.datadoghq.com/ja/llm_observability/ 19
安全に調査できる状態をつくる
安全に見るために、残す情報を選ぶ Ai Workforceでは、お客様の文書・指示・検索結果など、機密性の高い情報を扱っています。そのため本番で安全に調査できるよ う、原因切り分けに必要な属性と、原則として残さない生データを分けています。本文が必要な深い調査は、承認済みデータや再 現環境で確認します 残す属性 残さない生データ 切り分ける問題 © LayerX
Inc. 2. 安全に調査できる workflow / agent / tool / model / version duration / token / error / retry回数 検索hit数、tool種別、status prompt template / toolset の version prompt / response本文 お客様の文書・検索結果本文 tool引数・tool結果の生データ 個人情報や機密情報を含むpayload 検索不足、関係ない検索結果 tool失敗、retry増加 LLM遅延、token増加 外部provider側のerror 21
送信前に守るところまで実装に入れる 「残す情報 / 残さない情報」の方針は、spanのmetadata・名前・status・durationを維持しつつ、機密情報を含み得る本文を Datadogへ送る前にmaskする形で実装しています 実装イメージ metadataは残し、本文は外に出さない LLM spanを作る name
/ tag / status / duration / model / token など、調査に必要な情報を持 たせる ↓ 送信前にmaskする prompt / response本文、tool arguments、tool resultsをprocessorで伏せ る ↓ Datadogで調査する 本文ではなく、実行の構造と状態から原因候補を絞る © LayerX Inc. 2. 安全に調査できる 22
チームで扱える状態をつくる
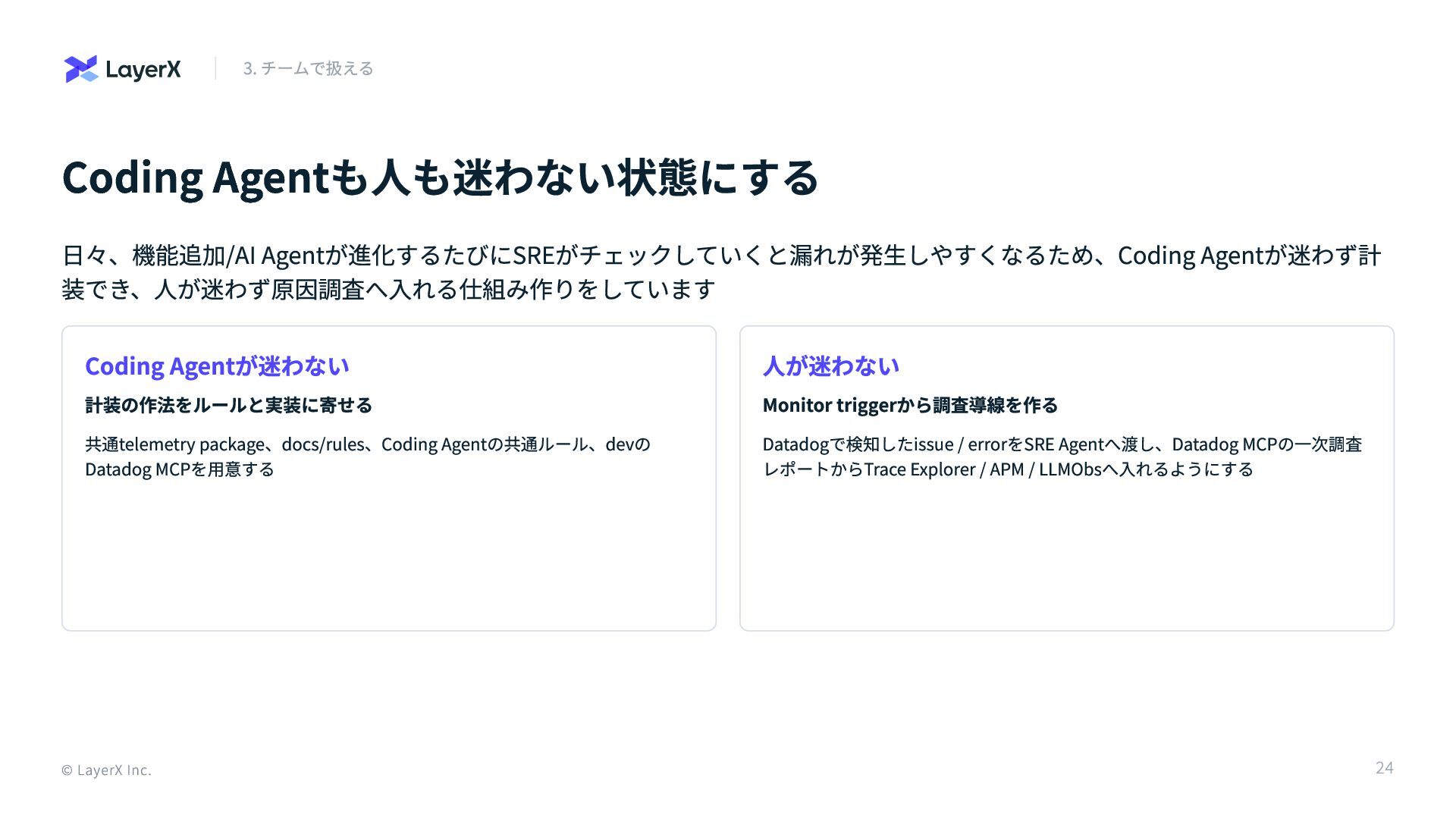
Coding Agentも人も迷わない状態にする 日々、機能追加/AI Agentが進化するたびにSREがチェックしていくと漏れが発生しやすくなるため、Coding Agentが迷わず計 装でき、人が迷わず原因調査へ入れる仕組み作りをしています Coding Agentが迷わない 計装の作法をルールと実装に寄せる 共通telemetry
package、docs/rules、Coding Agentの共通ルール、devの Datadog MCPを用意する 人が迷わない Monitor triggerから調査導線を作る Datadogで検知したissue / errorをSRE Agentへ渡し、Datadog MCPの一次調査 レポートからTrace Explorer / APM / LLMObsへ入れるようにする © LayerX Inc. 3. チームで扱える 24
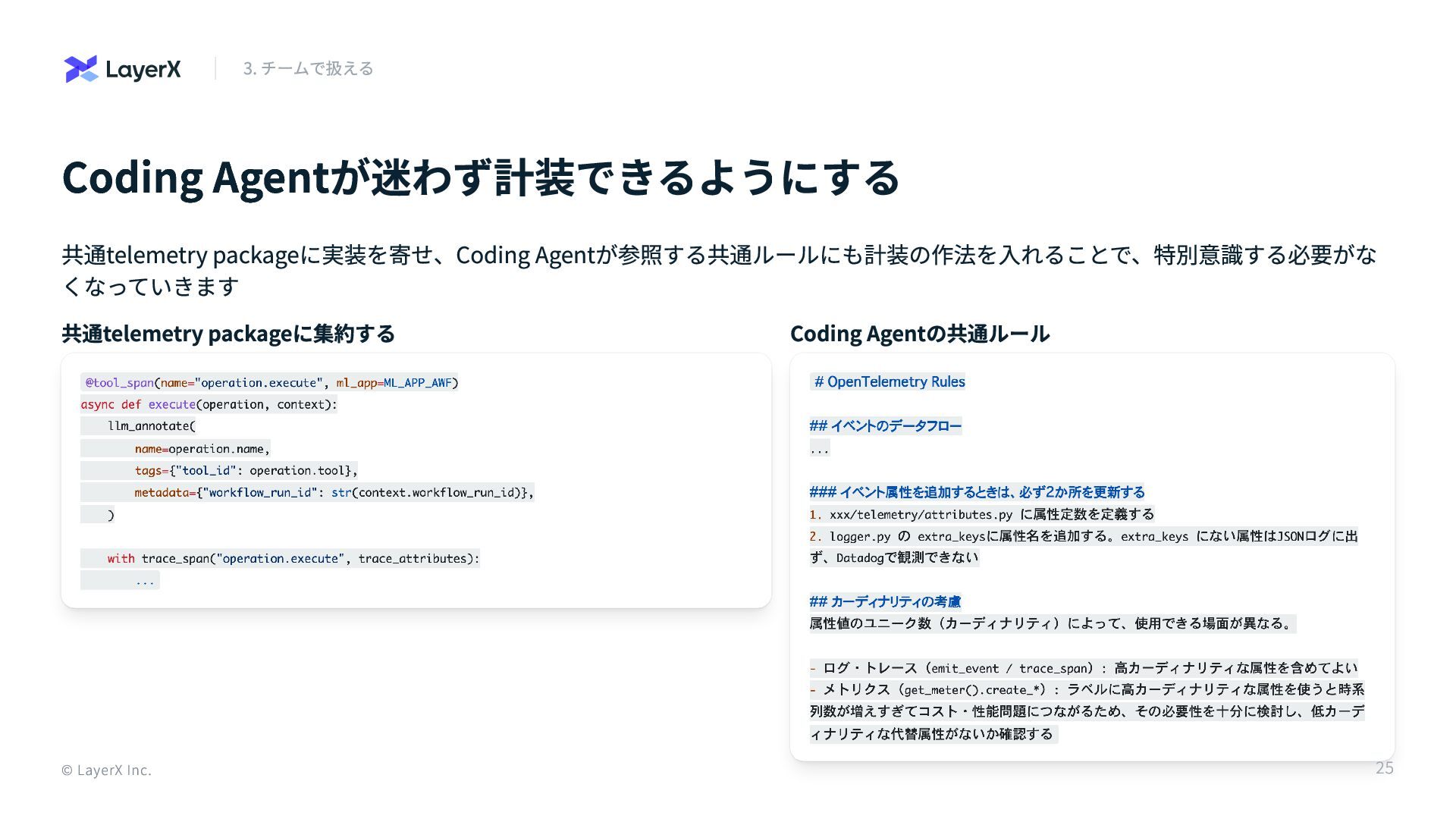
Coding Agentが迷わず計装できるようにする 共通telemetry packageに実装を寄せ、Coding Agentが参照する共通ルールにも計装の作法を入れることで、特別意識する必要がな くなっていきます 共通telemetry packageに集約する Coding Agentの共通ルール
© LayerX Inc. 3. チームで扱える 25
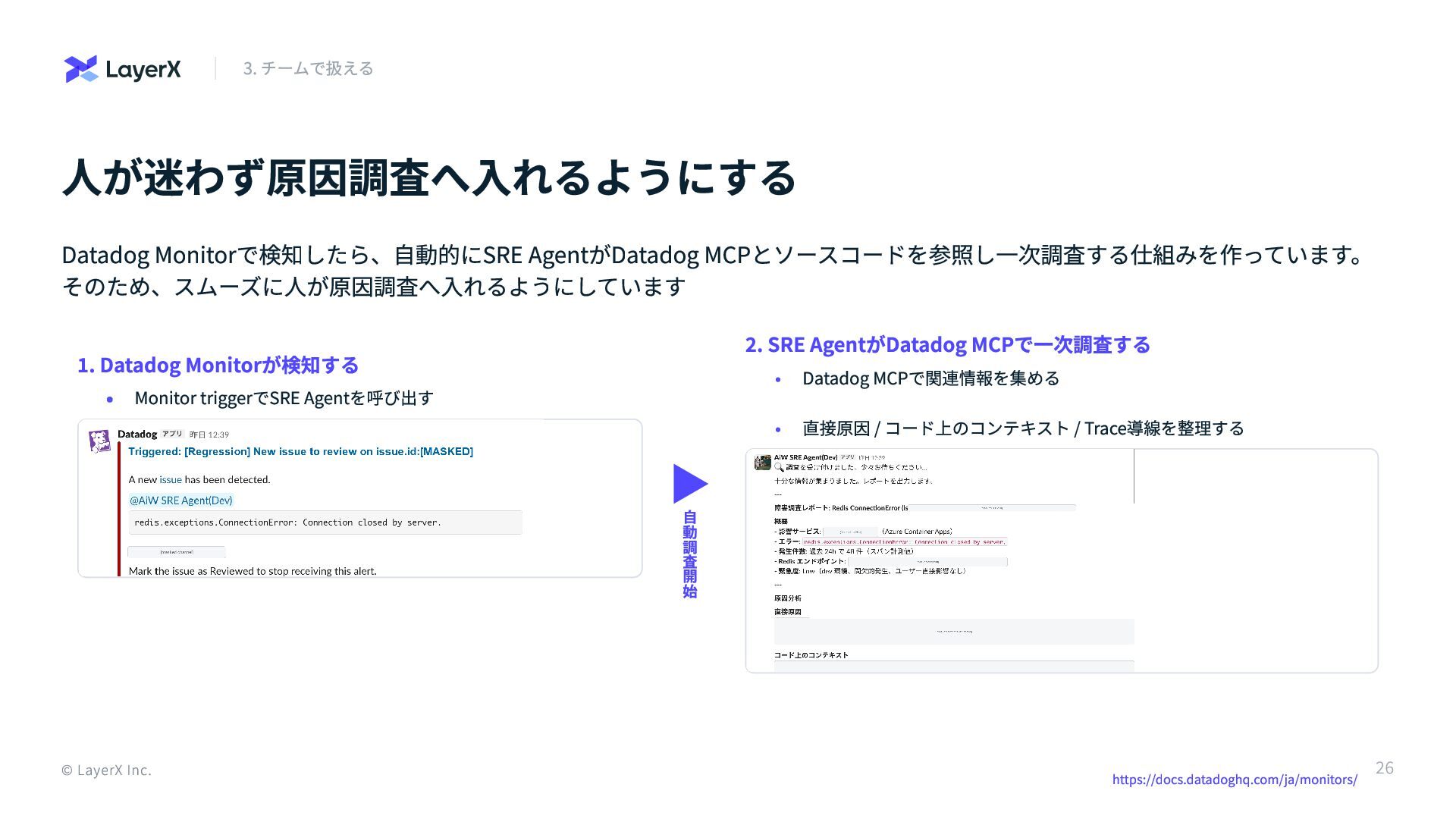
人が迷わず原因調査へ入れるようにする Datadog Monitorで検知したら、自動的にSRE AgentがDatadog MCPとソースコードを参照し一次調査する仕組みを作っています。 そのため、スムーズに人が原因調査へ入れるようにしています 1. Datadog Monitorが検知する ▶
自 動 調 査 開 始 2. SRE AgentがDatadog MCPで一次調査する © LayerX Inc. 3. チームで扱える Monitor triggerでSRE Agentを呼び出す Datadog MCPで関連情報を集める 直接原因 / コード上のコンテキスト / Trace導線を整理する https://docs.datadoghq.com/ja/monitors/ 26
余談:SRE Agent オテスキー © LayerX Inc. 3. チームで扱える 選手紹介 Ai
Workforce SREチームに現れた助っ人 (リアルな姿とピュアな姿の2つの側面を持つ) Ai Workforceの運用に必要な情報 (Datadog MCP / ソースコード等)を武器に、 日々ノックを受け続けている 最近、ソフトウェアエンジニアが育てている猫 エージェントとタッグを組み、3A Play Ground (k8s)で必要な環境を即座に提供する役割も担う 27
"運用し続ける"ために行っている工夫 変化し続けるプロダクトを"運用し続ける"ために、OpenTelemetry・Datadog・AI Agentを組み合わせ、説明できる・安全に調査 できる・チームで扱える状態を作っています 説明できる 業務ワークフローからAgent内部まで、1件 の実行として辿れる状態にする OpenTelemetry workflow /
task / tool / search / LLM callを span化し、Span Linksで非同期境界を関連 づける Datadog Trace Explorer / APM / LLMObsで、実行全 体からAgent内部まで辿る × 安全に調査できる 本文を見すぎず、実行の構造と状態から原因 候補を絞る 残す duration / error / retry / token / 検索hit数 などのmetadata 守る prompt / response / tool payloadは送信前 maskで外に出さない × チームで扱える Coding Agentも人も迷わない導線にして、 SREだけの運用にしない 開発 共通telemetry packageとルールで、 Coding Agentが迷わず計装できる 運用 Monitor → SRE Agent → Trace導線で、人 が原因調査へ入れる © LayerX Inc. まとめ 28
Datadog DASH 2026 (6/10)に同じチームの 石田 健太(ishiken)が登壇します!!! 登壇タイトル:The AI Engineering Playbook:
How to Evaluate & Iterate at Every Phase of Development オンラインは無料なので、ぜひ見てください! © LayerX Inc. Datadog DASH 2026 https://dash.datadoghq.com/sessions/the-ai-engineering-playbook-how-to-evaluate-iterate-at-every-phase-of-development/ 29
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}