Mein Vortrag am Global Azure Bootcamp 2017 in Linz.
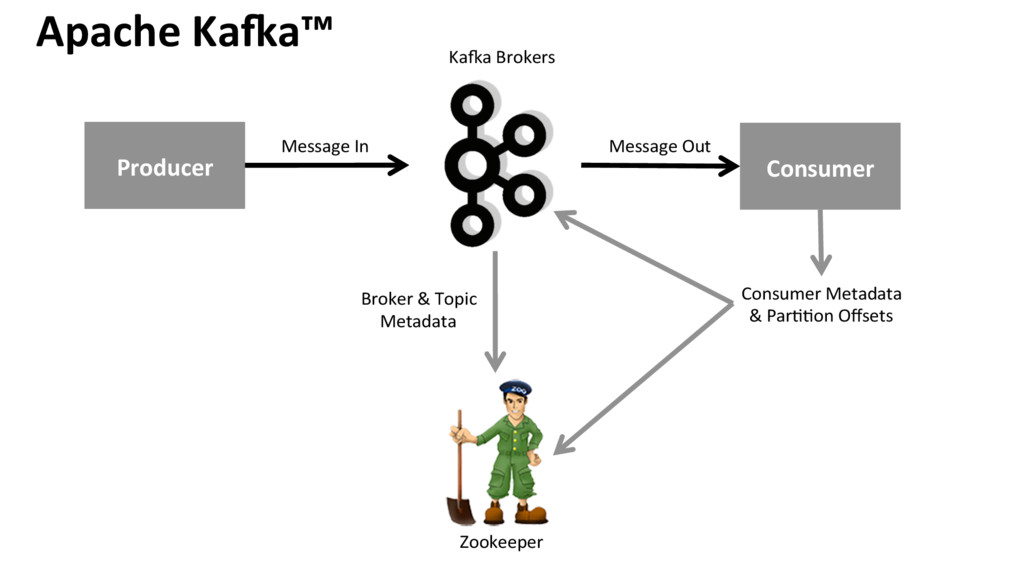
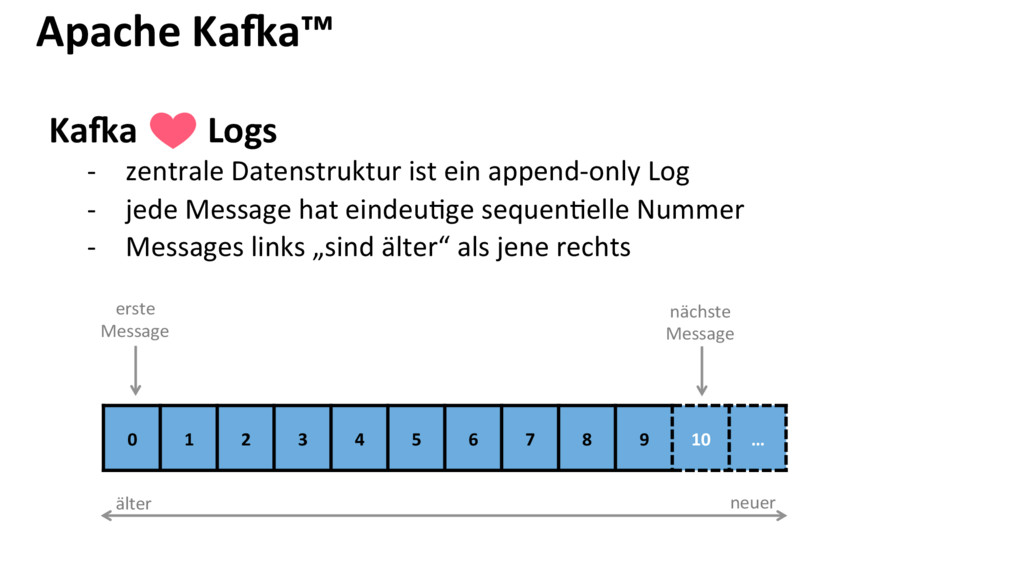
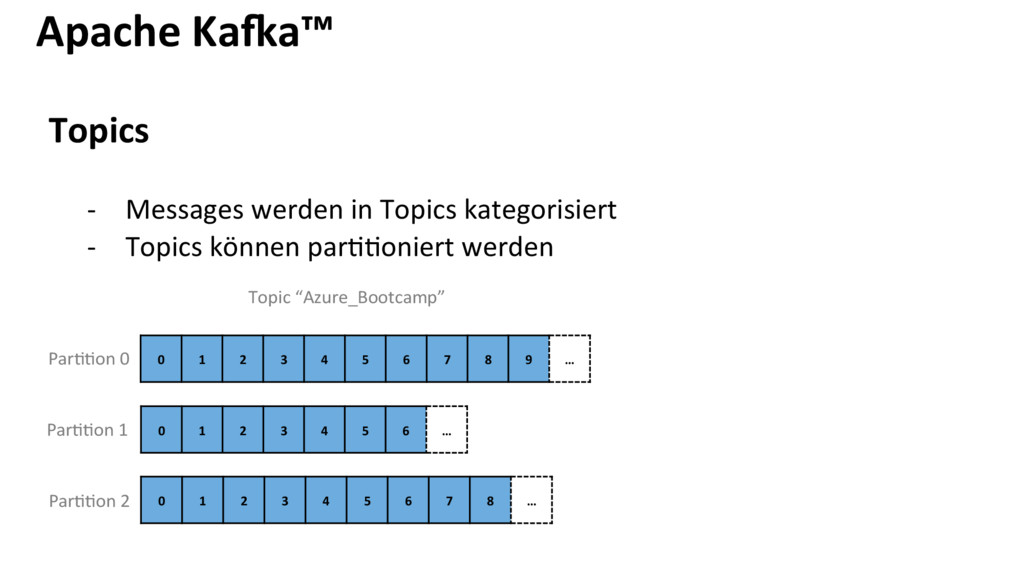
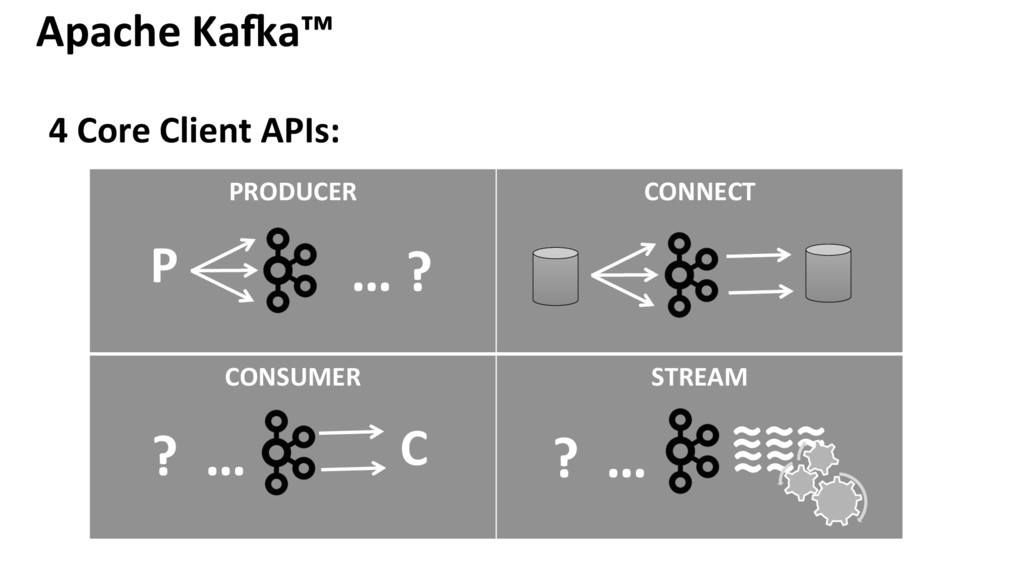
Apache Kafka ist eine verteilte, skalierbare und hochverfügbare Messaging Platform. Mit Kafka kann ein bereites Spektrum von Anwendungsfällen realisiert werden, weshalb es sich über die letzten Jahre als Herzstück vieler unternehmensweiter Datenarchitekturen etablieren konnte. Der Einsatz reicht von einfachen Message Queues bis hin zu echtzeitnahen Stream Processing Lösungen, ohne dabei auf andere schwergewichtige Frameworks od. Technologien des BigData Ökosystem-Dschungels angewiesen zu sein.
Nach einer kurzen Einführung zu den wichtigsten Komponenten von Kafka zeigt die Session in einem Mix aus Vortrag und Demos, wie einfach es ist, Kafka Anwendungen zu entwickeln und diese mit Kafka HDInsight in Azure bereitzustellen. Im Zuge dessen werden mögliche Anknüpfungspunkte zu anderen Azure Services diskutiert. Ebenso erfolgt eine Abgrenzung zu alternativen Umsetzungsmöglichkeiten von Datenstromanalysen in Azure.
https://coding-club-linz.github.io/global-azure-bootcamp-2017/
Sample Code => https://github.com/hpgrahsl/kafka-azure-gab2017
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
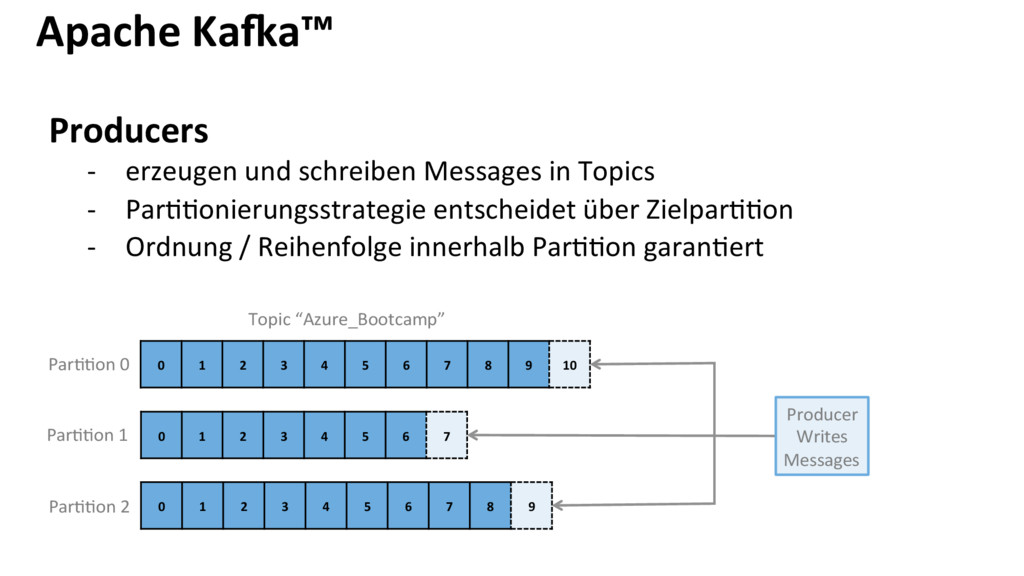{kind=link}
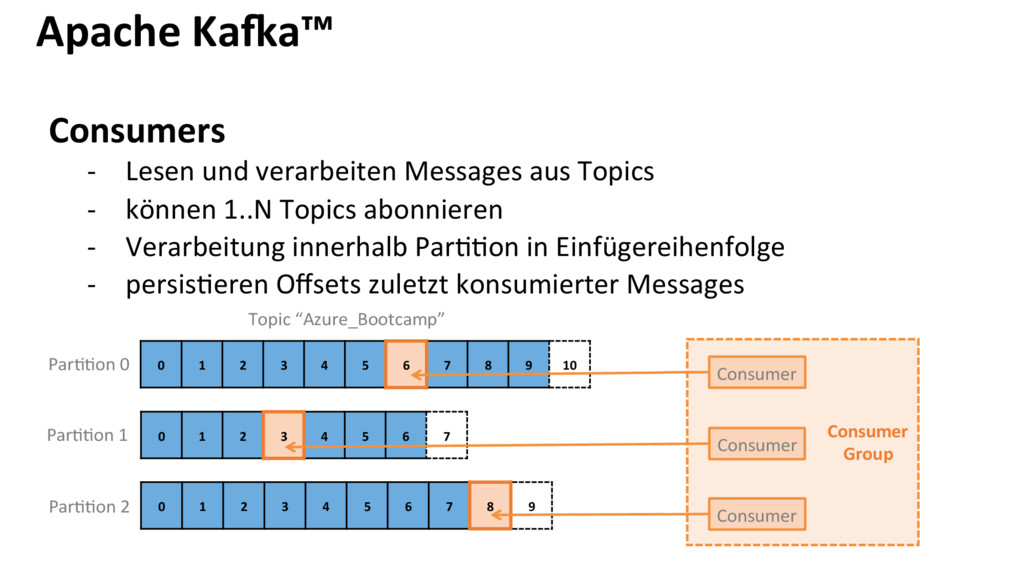{kind=link}
{kind=link}
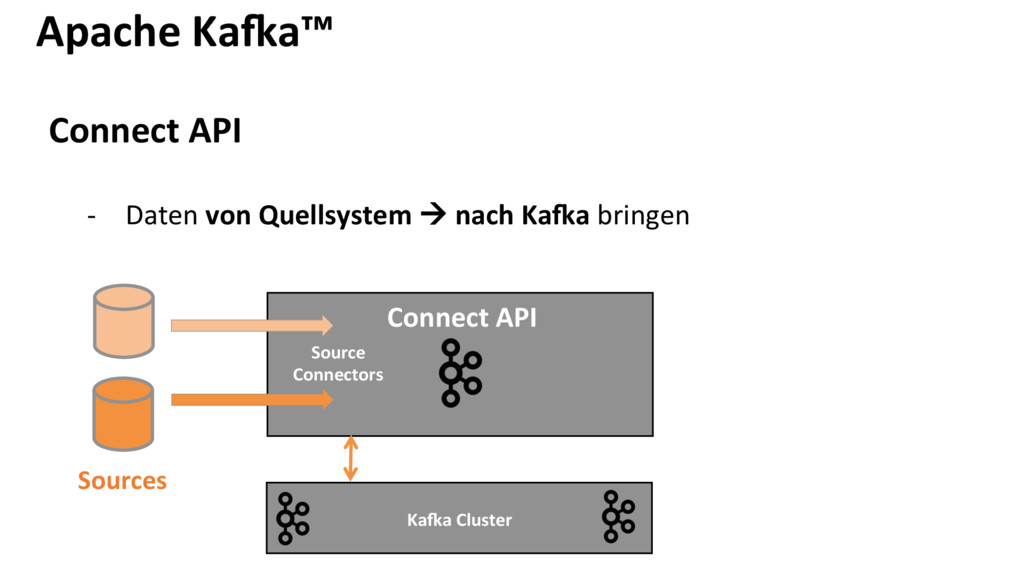{kind=link}
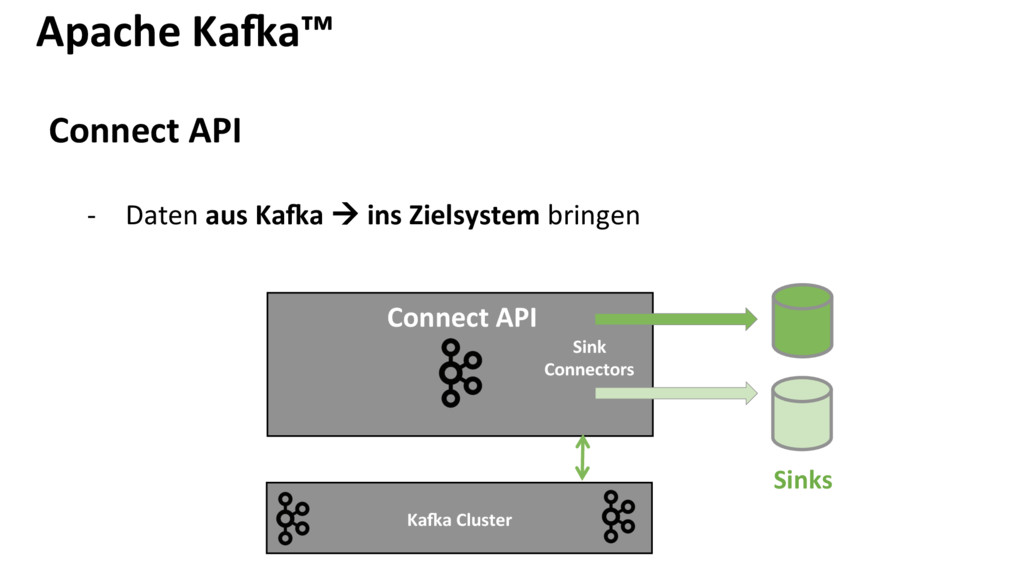{kind=link}
{kind=link}
{kind=link}
{kind=link}
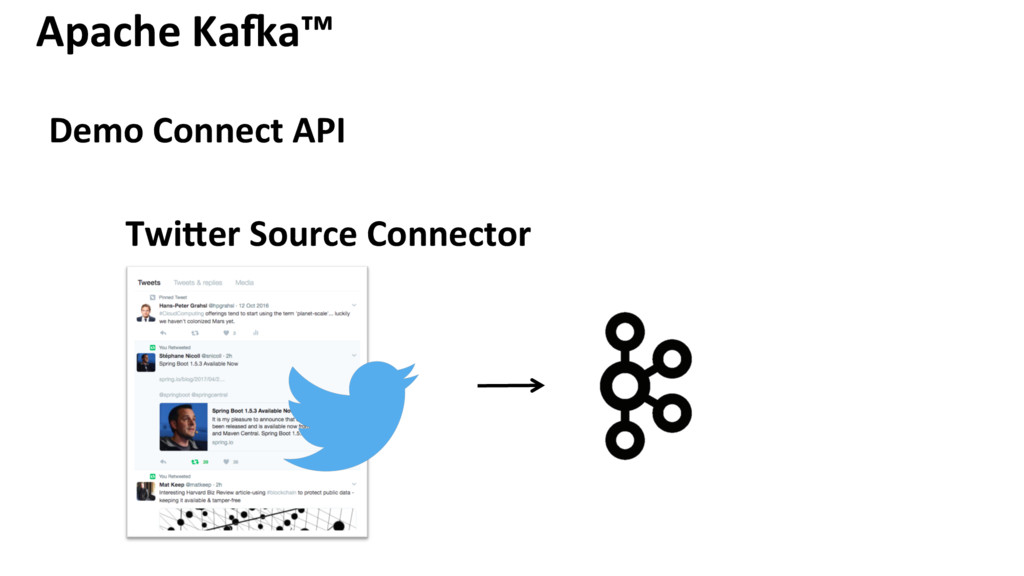{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
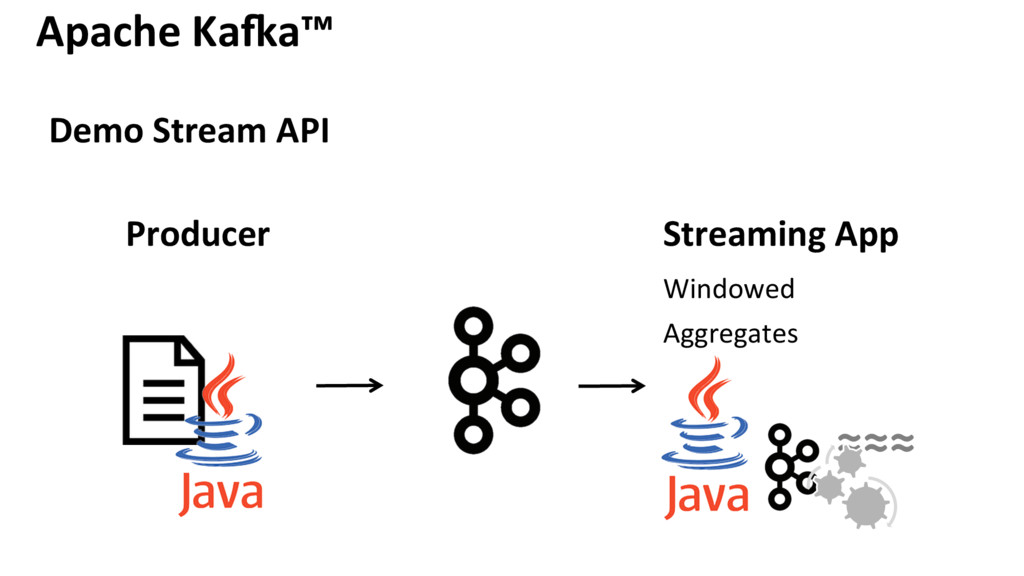{kind=link}
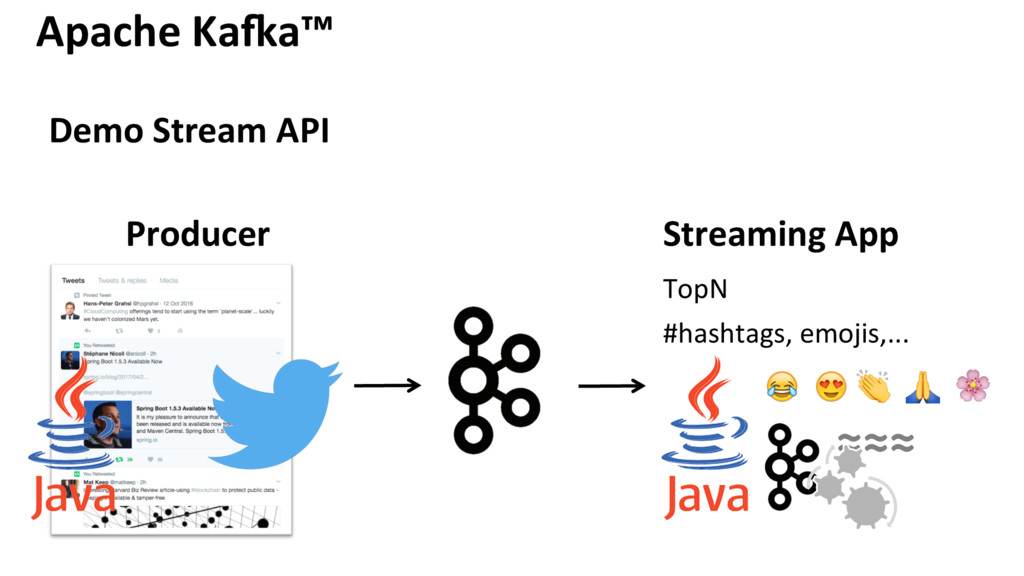{kind=link}
{kind=link}
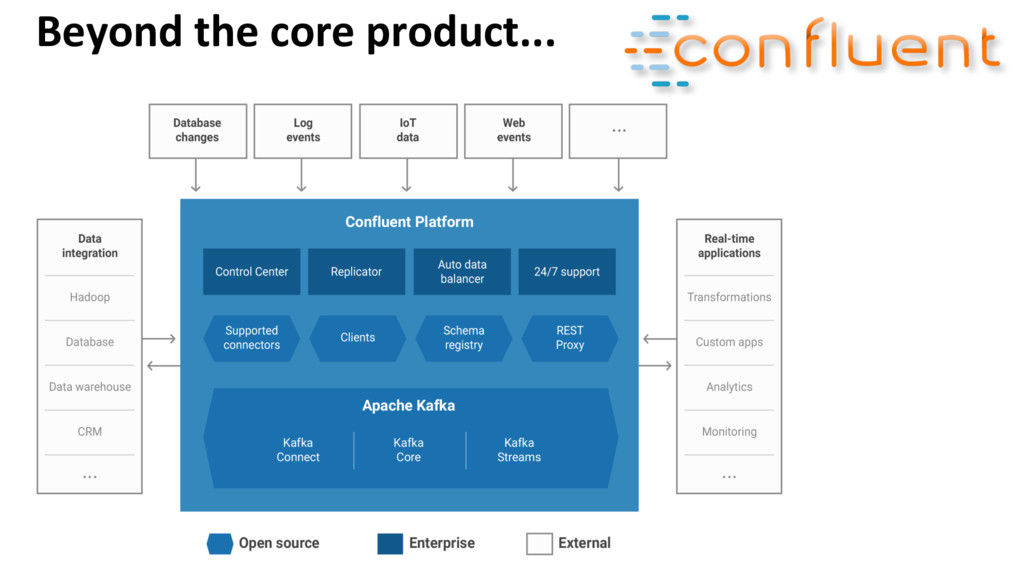{kind=link}
{kind=link}
{kind=link}
{kind=link}