of reasons. Financial rational is common, but it really depends on the service you’re running. You could imagine for a Tsunami alert system you’d want zero downtime.
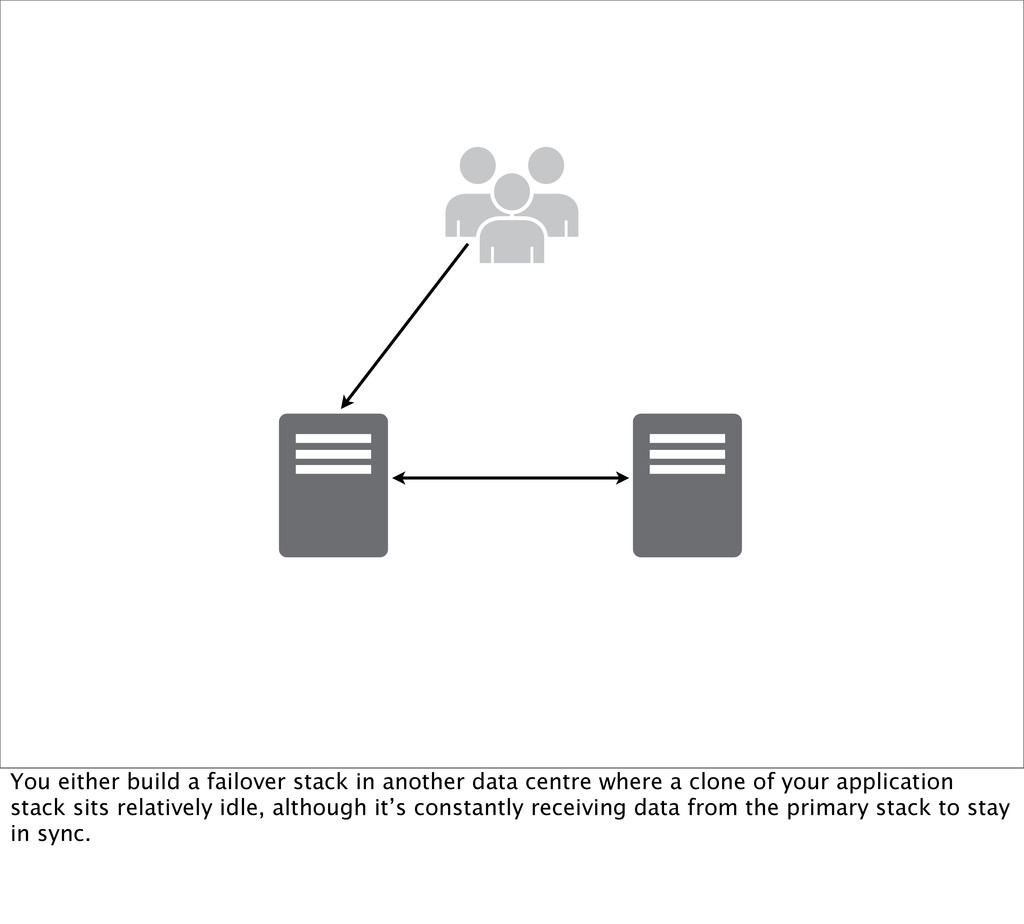
when your services go down, you do everything you can ahead of time - and within your budget - to make sure your services are as highly available as possible.
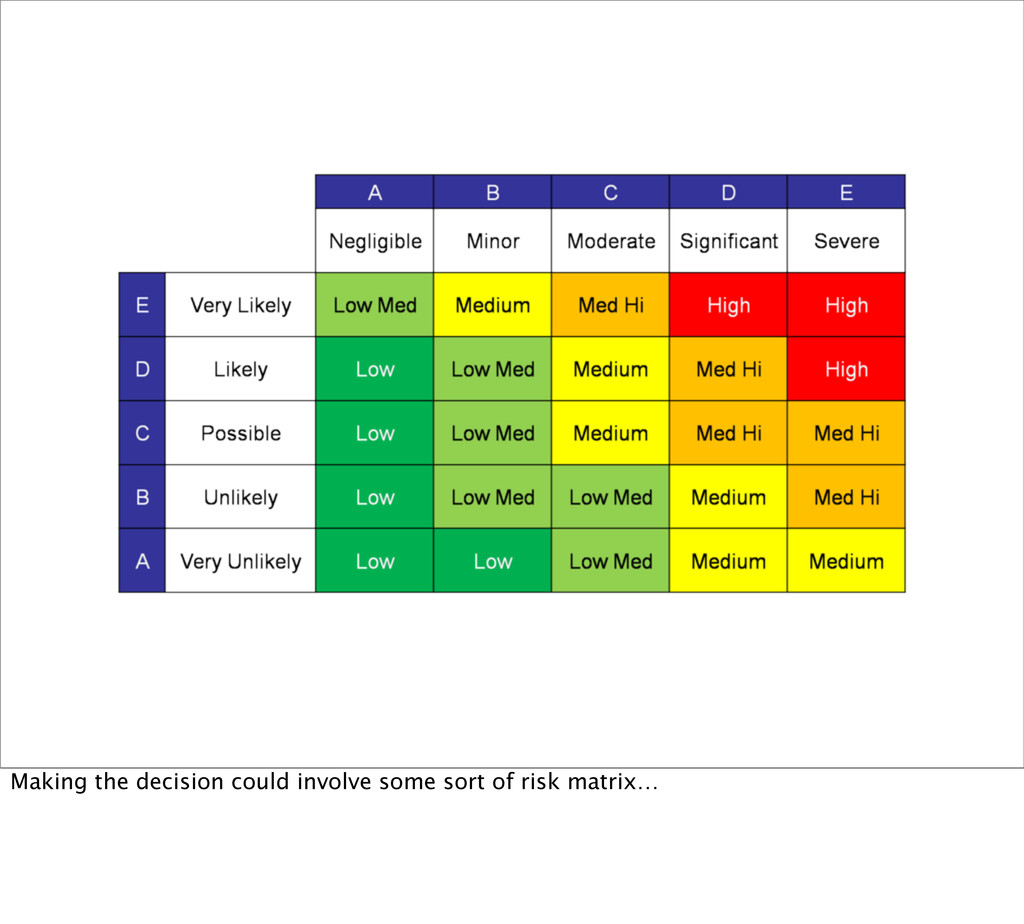
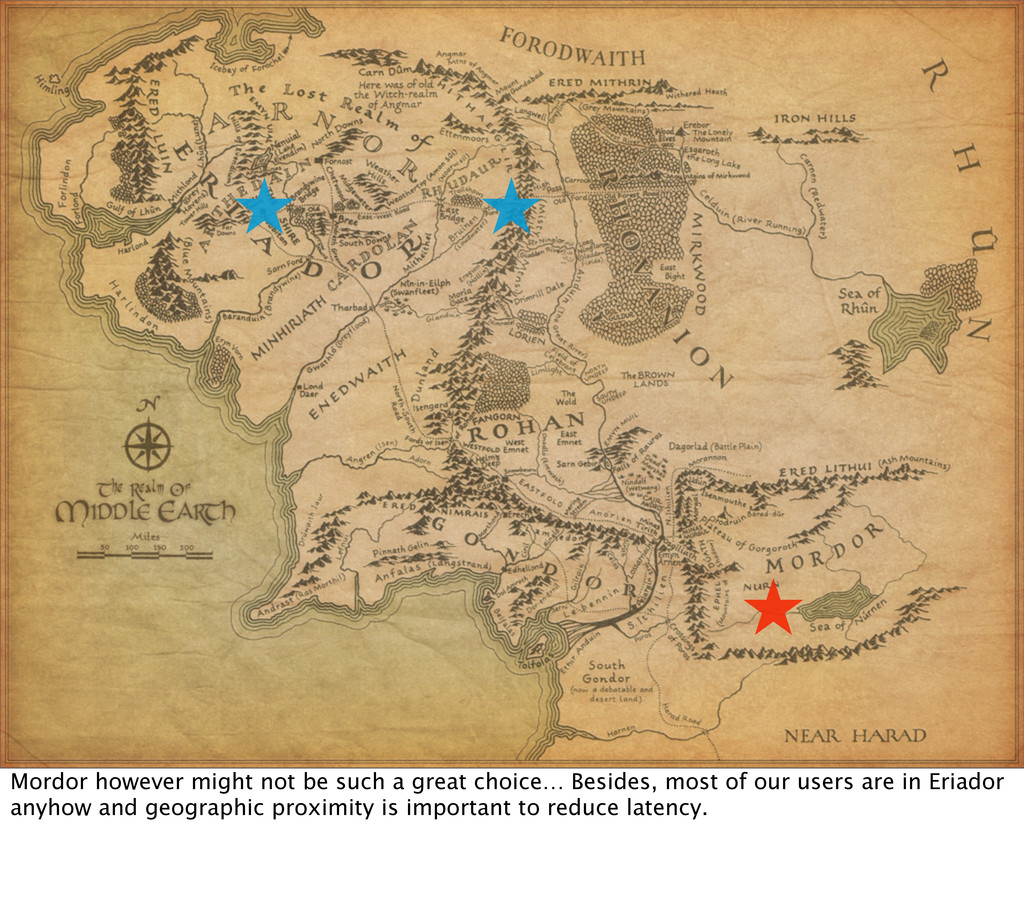
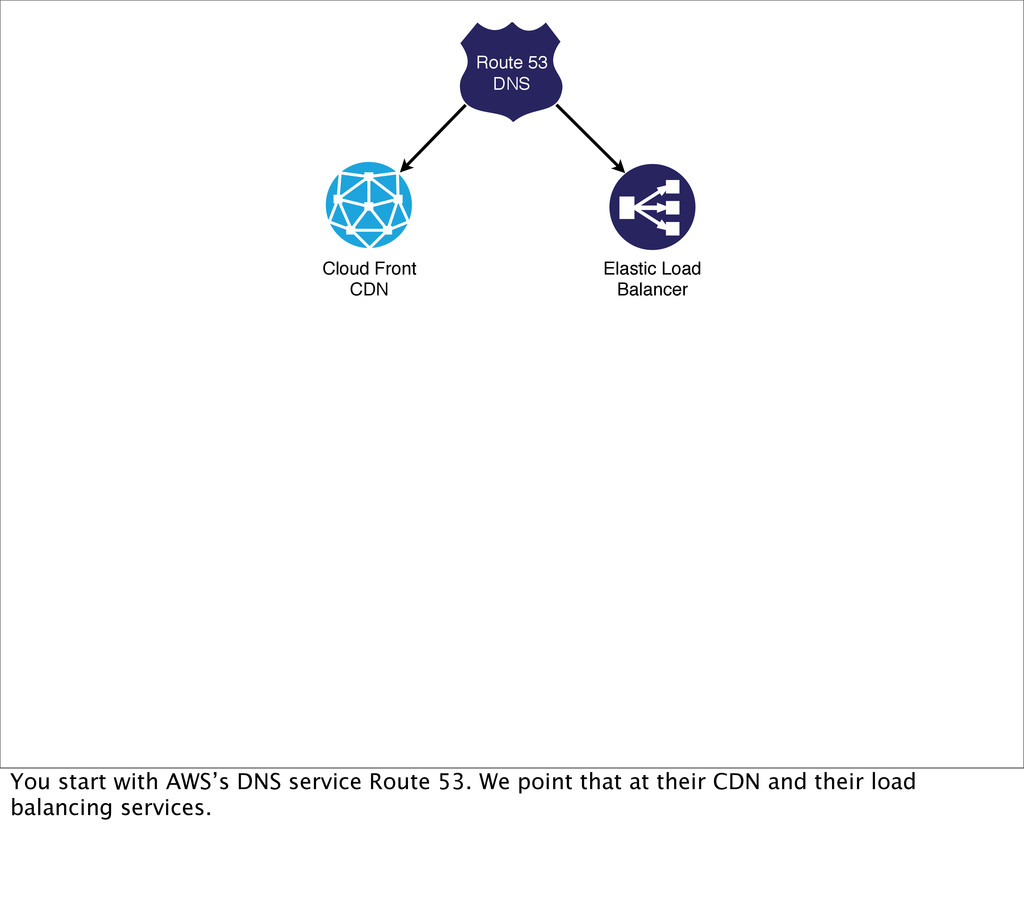
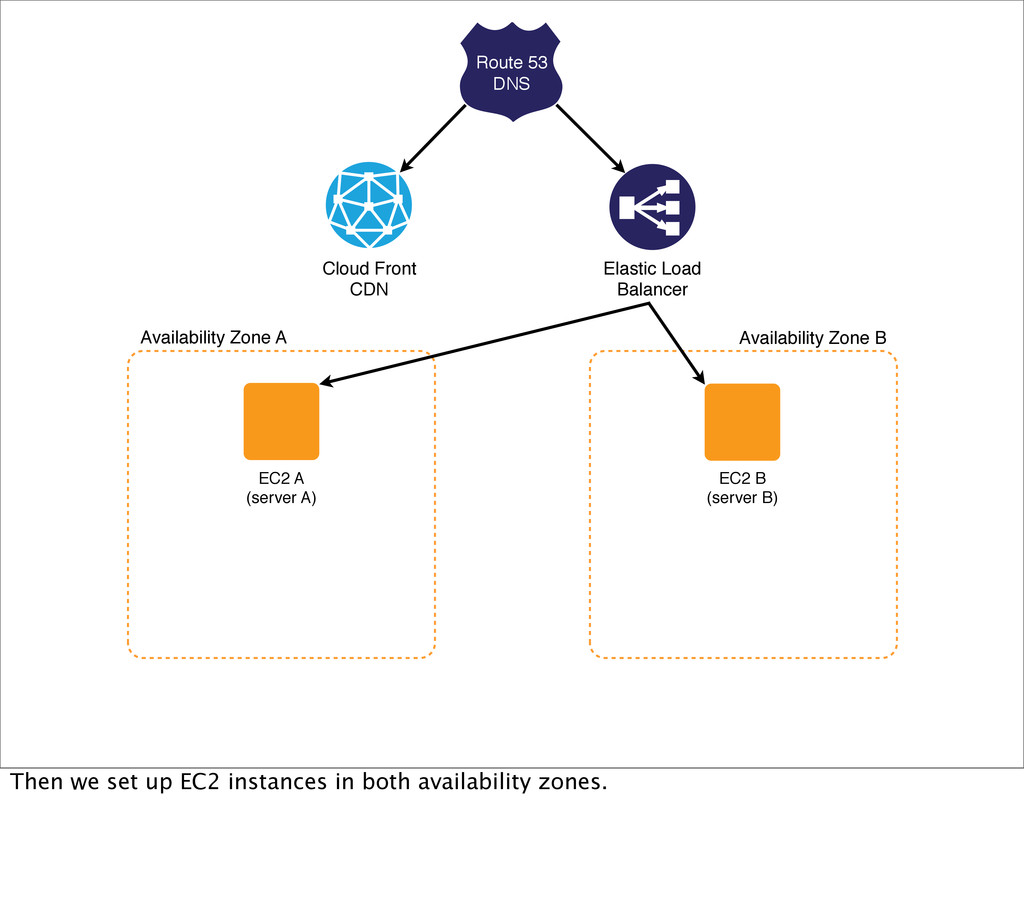
as many single points of failure as you can in your application stack. Sometimes there are external services you can do nothing about, so simply choose them wisely upfront. You take this elimination of SPOFs all the way down to the data centre and even its geographic location…
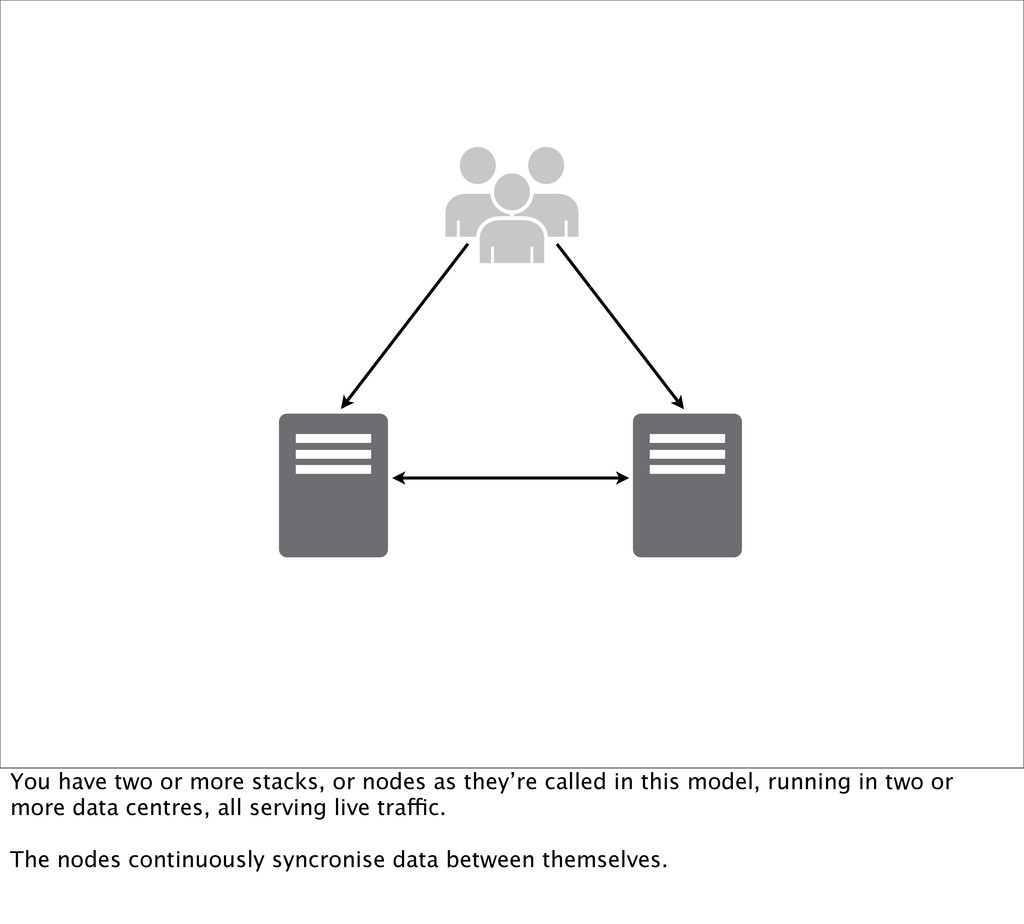
other nodes. I prefer this model as you’re getting the most out of your resources. Plus you know that your other nodes are actually operational because they’re working all of the time, unlike the failover model.
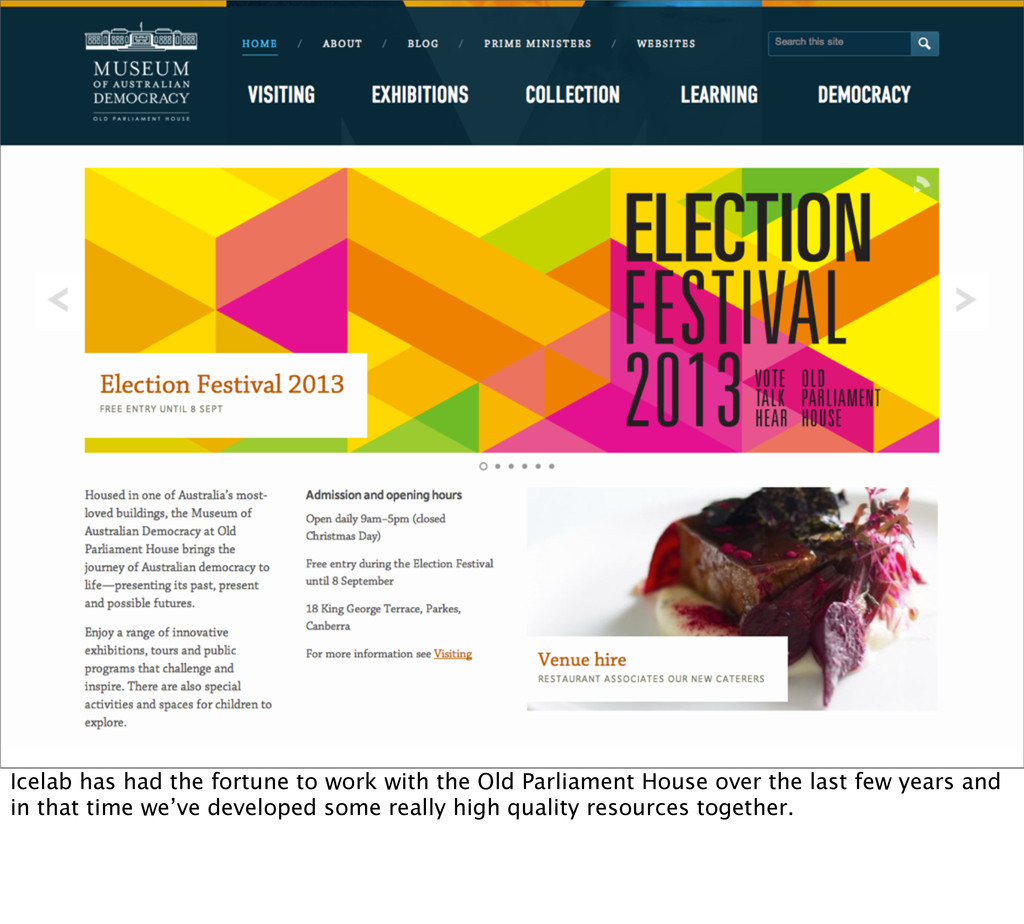
to classroom programs around the country. So having the sites available when those classes are run is very important. Having a resource unavailable could be highly disruptive to an educator’s learning plan.
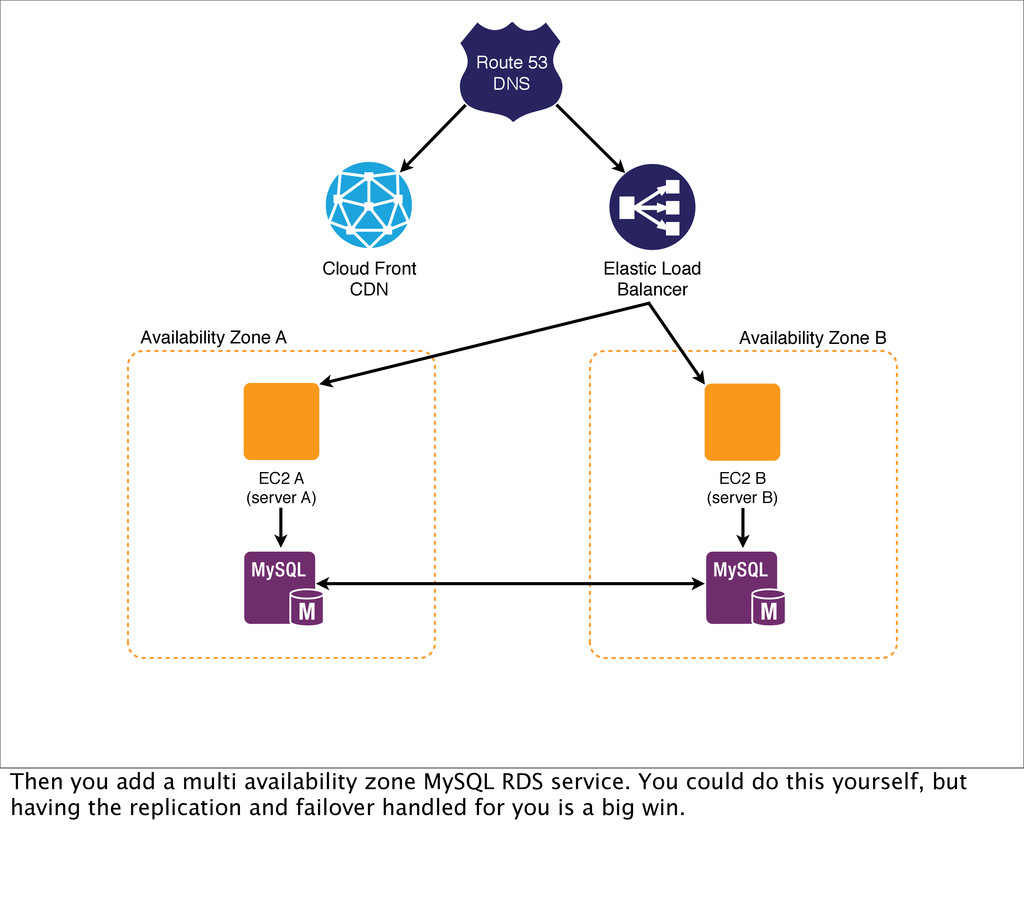
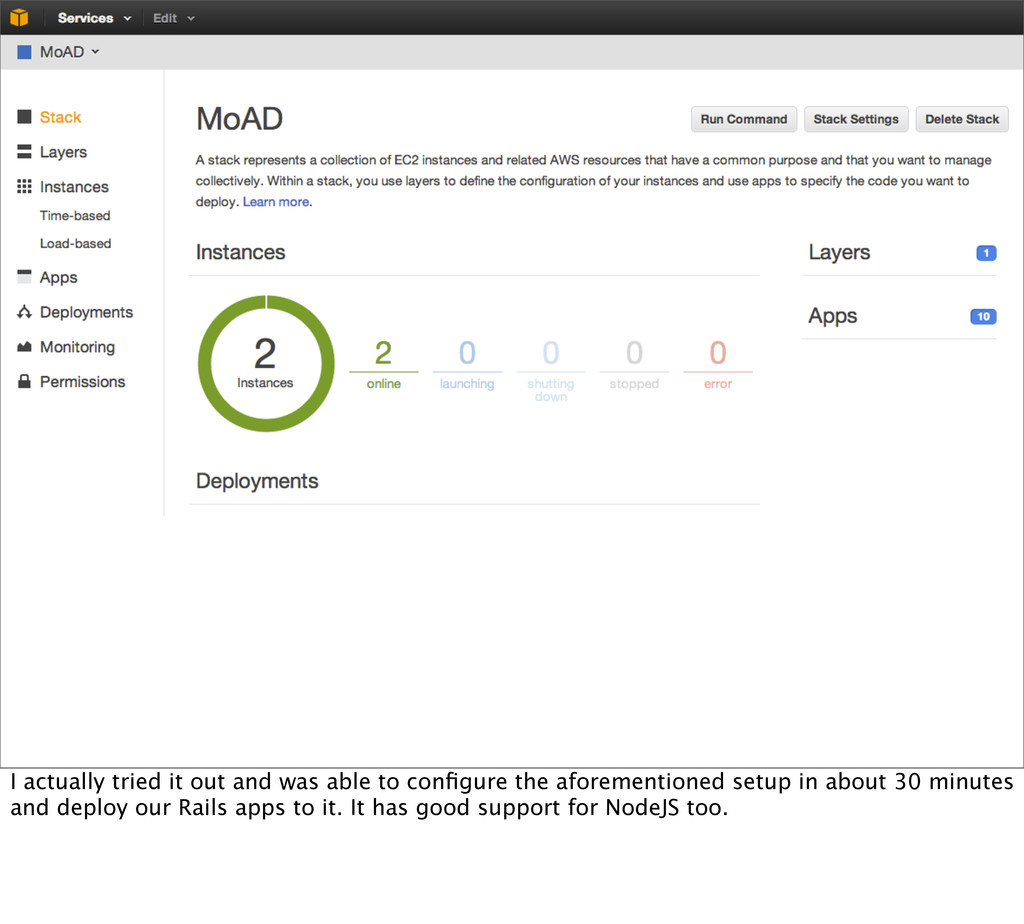
A (server A) Availability Zone A Availability Zone B EC2 B (server B) Then you add a multi availability zone MySQL RDS service. You could do this yourself, but having the replication and failover handled for you is a big win.
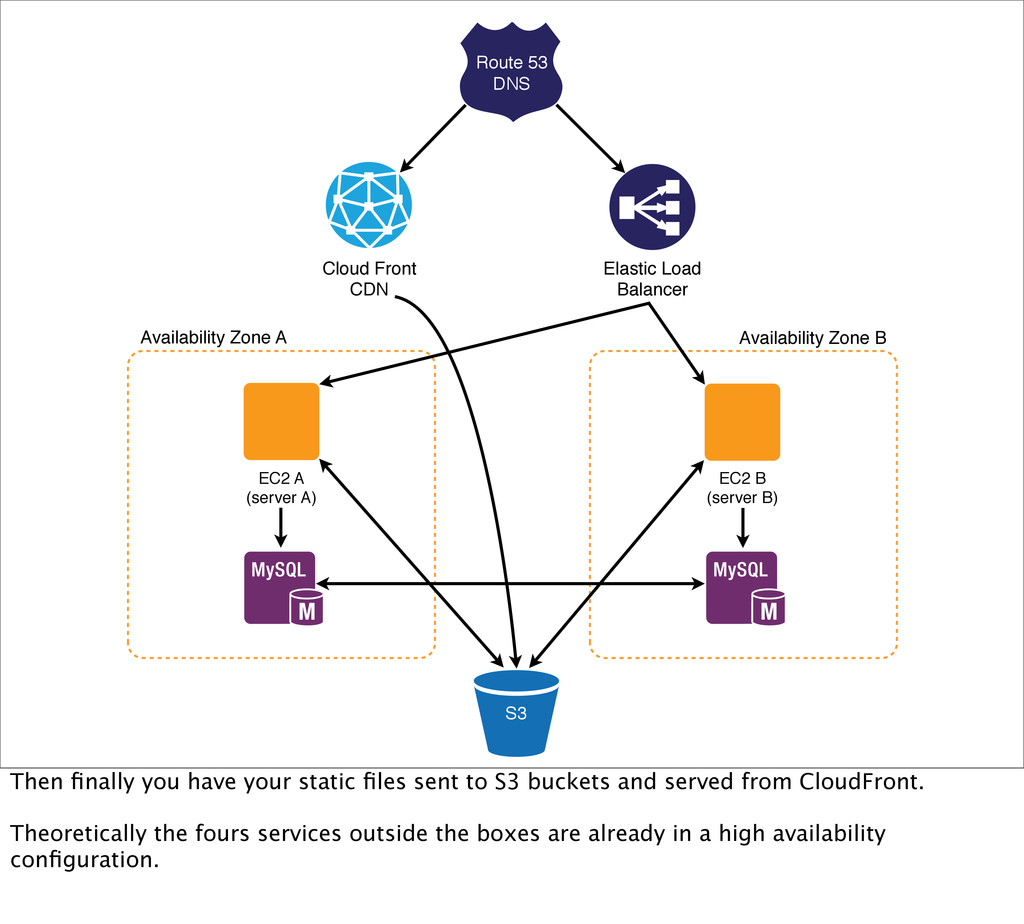
A (server A) Availability Zone A Availability Zone B EC2 B (server B) S3 Then finally you have your static files sent to S3 buckets and served from CloudFront. Theoretically the fours services outside the boxes are already in a high availability configuration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] Or on my NSA hotline.](https://files.speakerdeck.com/presentations/915ea8e0f8b901308c562a3a9ff60ec9/slide_53.jpg){kind=link}
{kind=link}