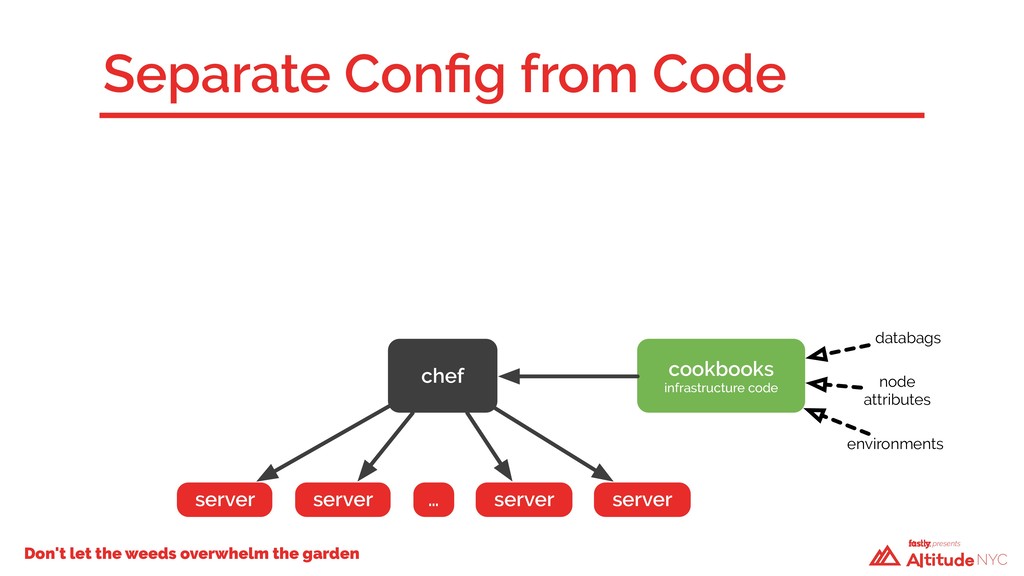
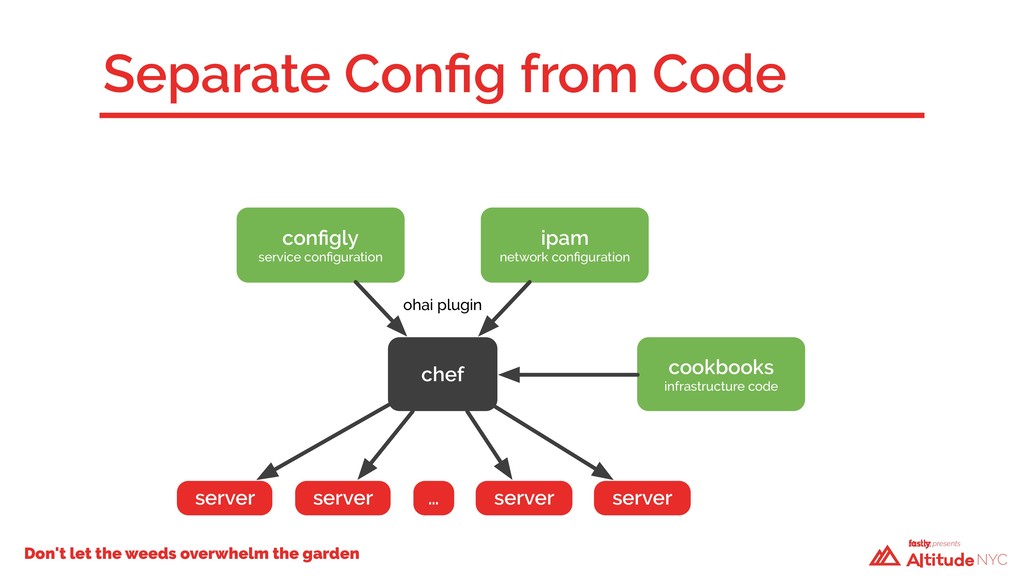
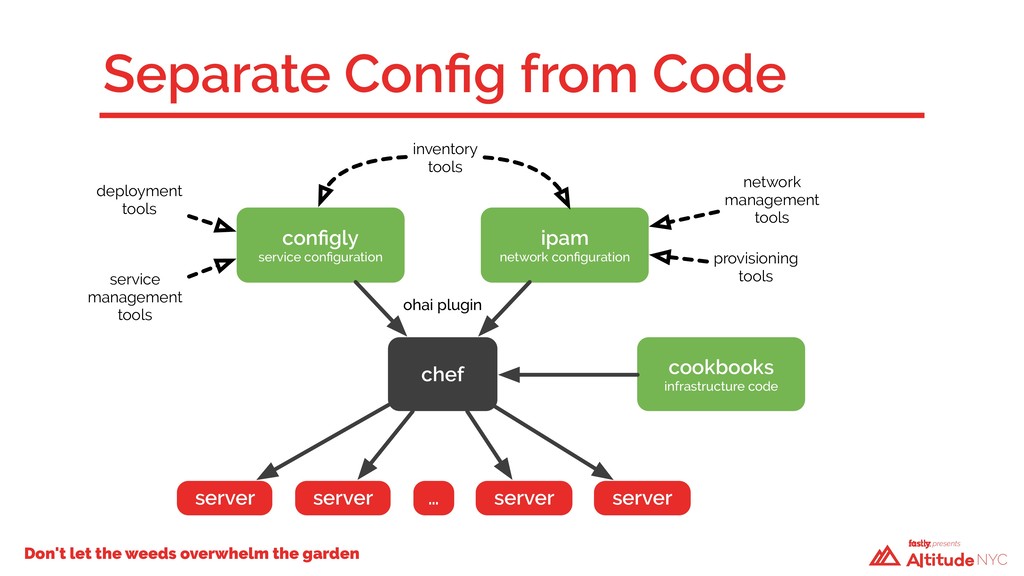
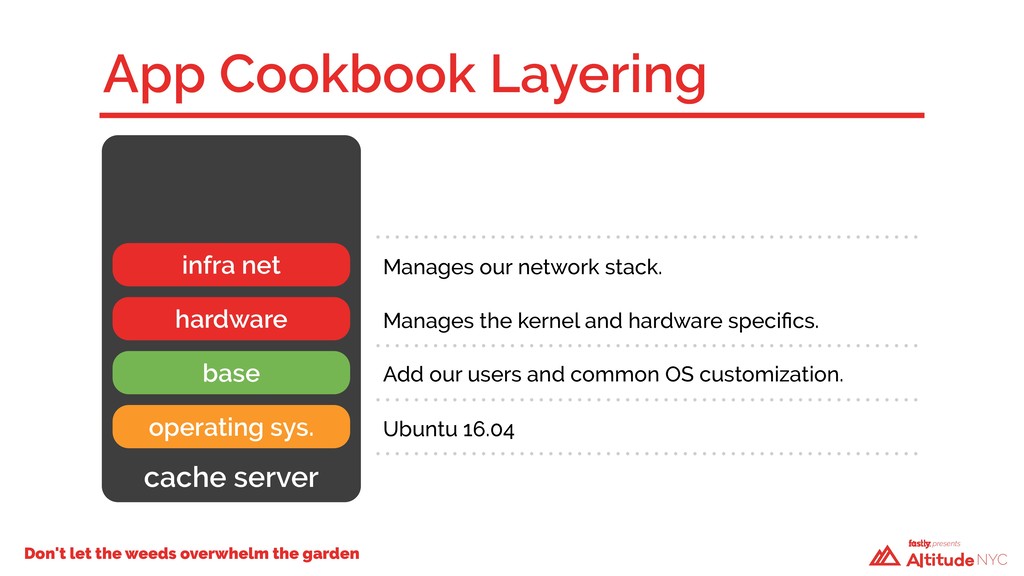
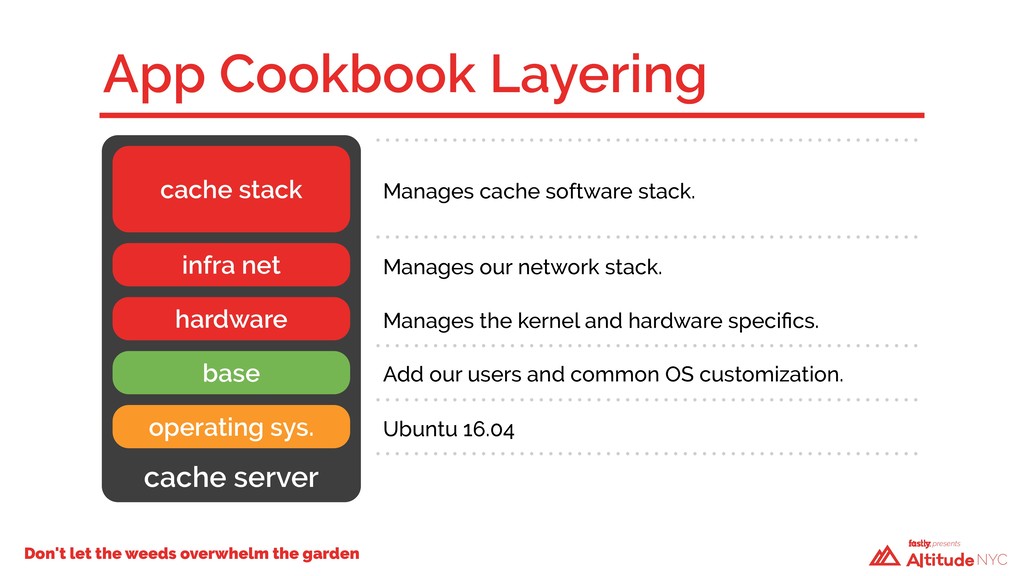
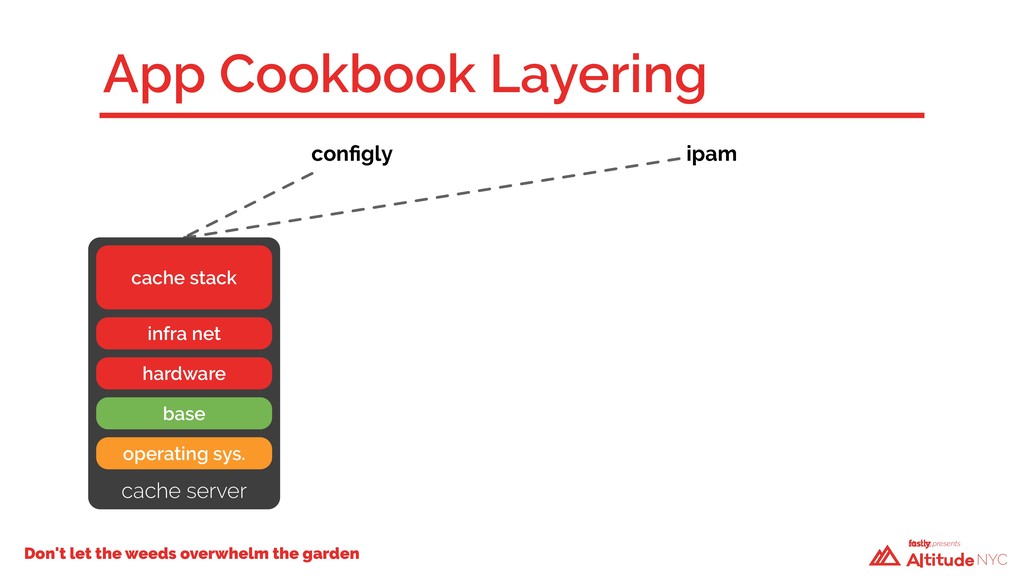
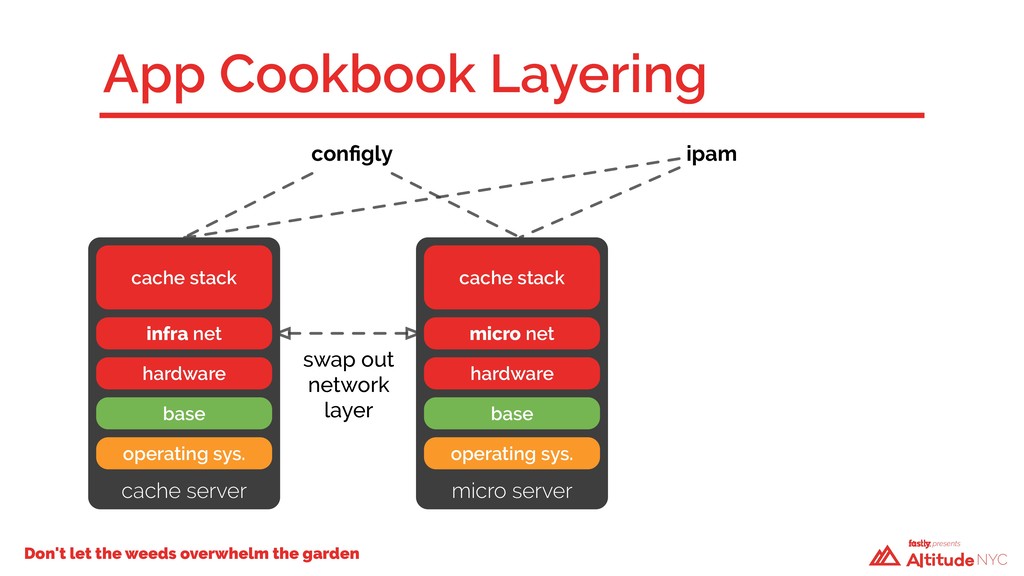
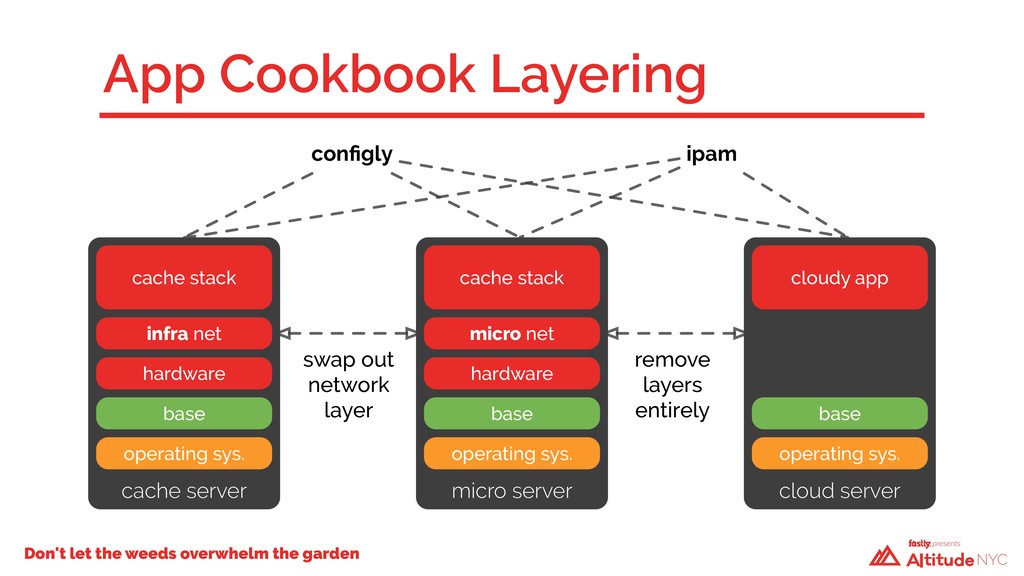
A year ago, our technical debt was incurring compound interest and we weren’t going to be able to keep making the minimum payments. We had to take a hard look at how we built our infrastructure—we had a code base that had evolved over time, with no design patterns and little structure. Changes in one Chef cookbook would have cascading failures in seemingly unrelated places elsewhere. We had dependencies upon dependencies. We faced a critical decision: fix what we have in place or start over again using what we’d had before as a guide. We chose the latter.
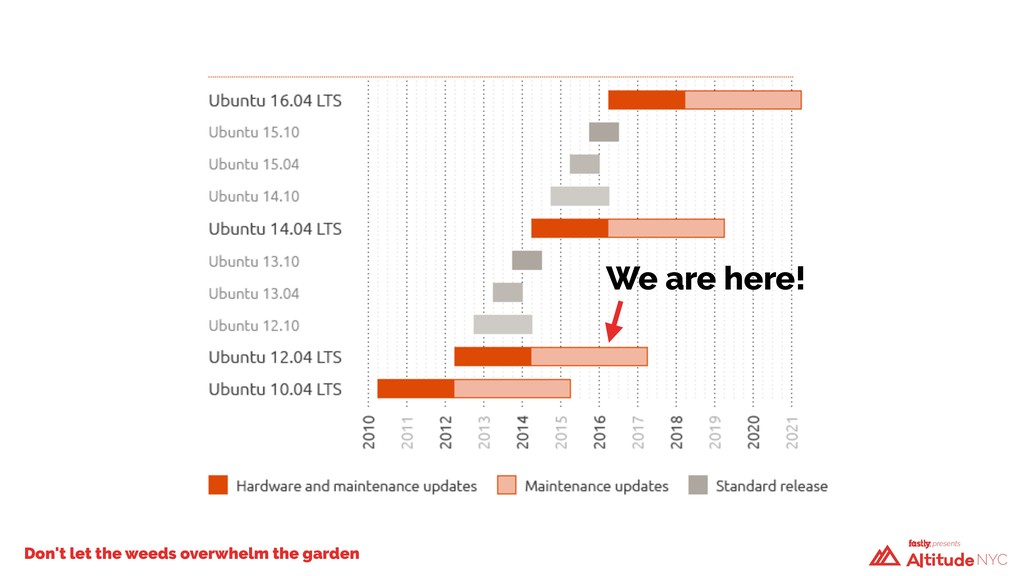
And so, over the past 12 months, we rewrote the majority of our infrastructure code, upgraded the operating system, and rebuilt every single server in our public cache fleet from the ground up—without anyone noticing. Previously, it took Fastly about six people over six weeks to install a new POP. Now, it requires just one person and a single week.
We attribute our ability to rapidly scale, both safely and reliably, to a new approach, which we'll discuss in this talk. We will relive the design and redeployment of our public cache fleet, the challenges faced, lessons learned, and benefits gained from our new architecture.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}