Over the past 6 months at Fastly we’ve migrated away from our legacy monitoring systems and have deployed Prometheus as our primary system for infrastructure and application monitoring.
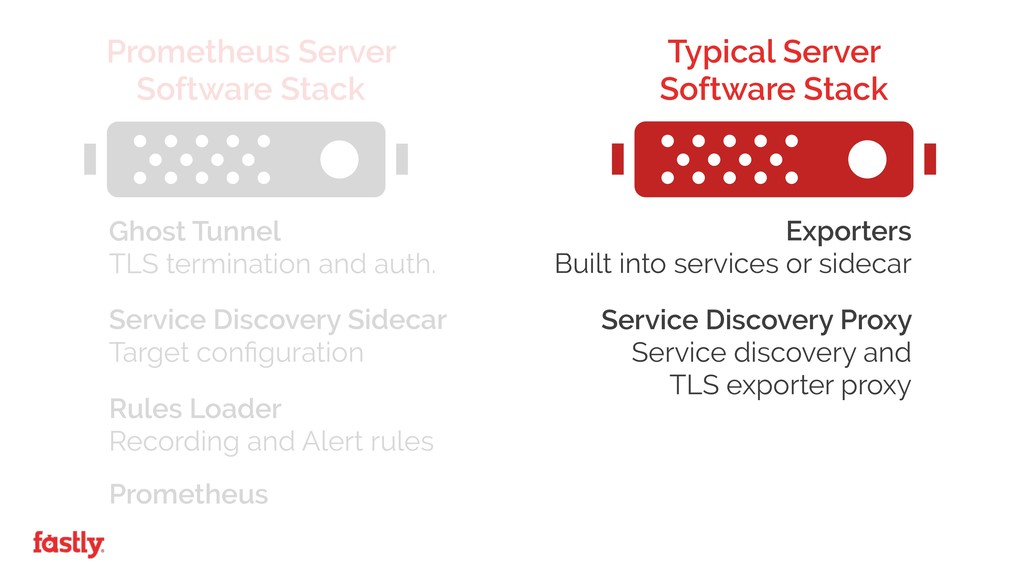
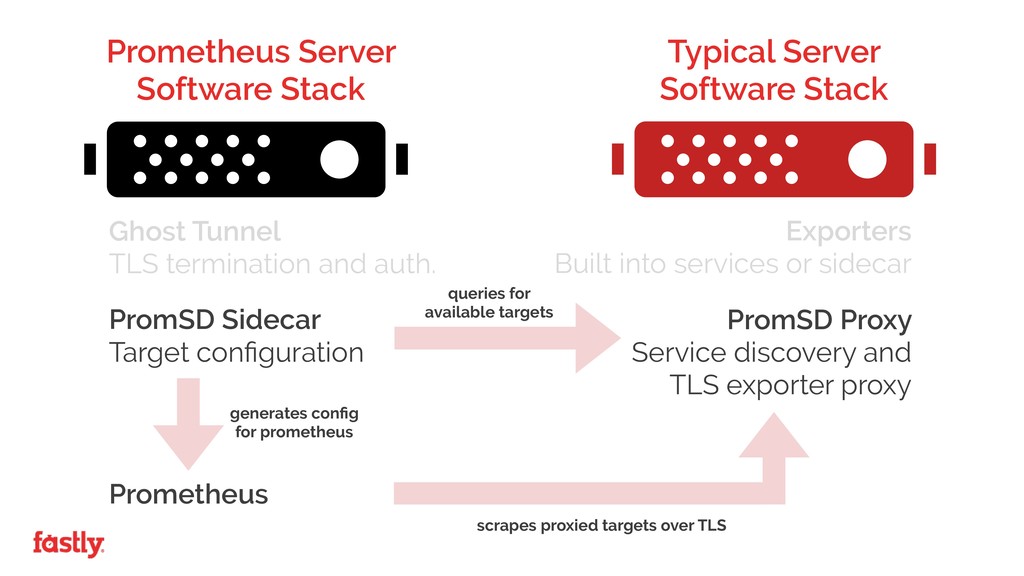
The Prometheus approach posed some unique challenges over traditional monitoring systems, whilst at the same time enabling us to easily scale our monitoring infrastructure alongside our global network growth.
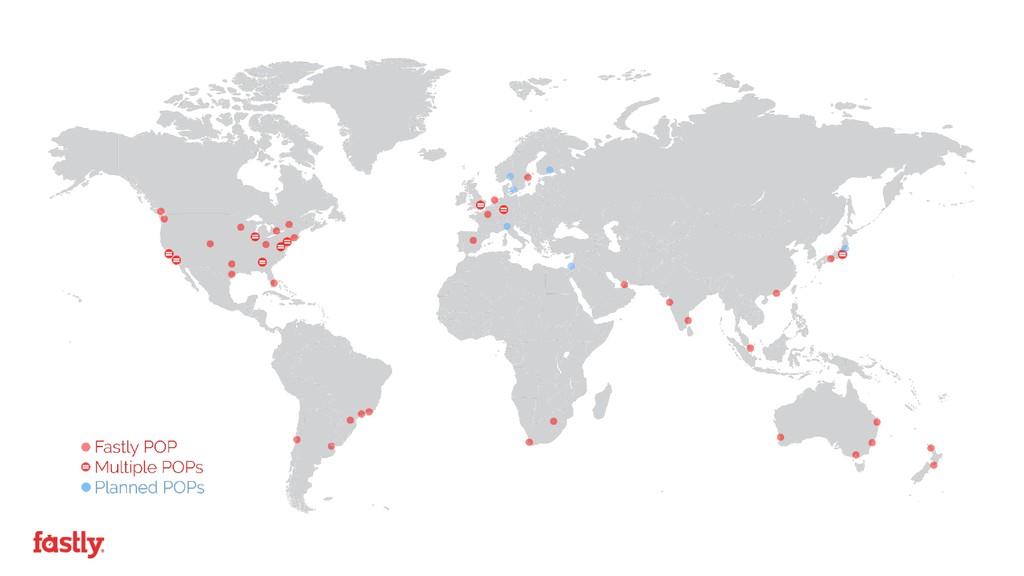
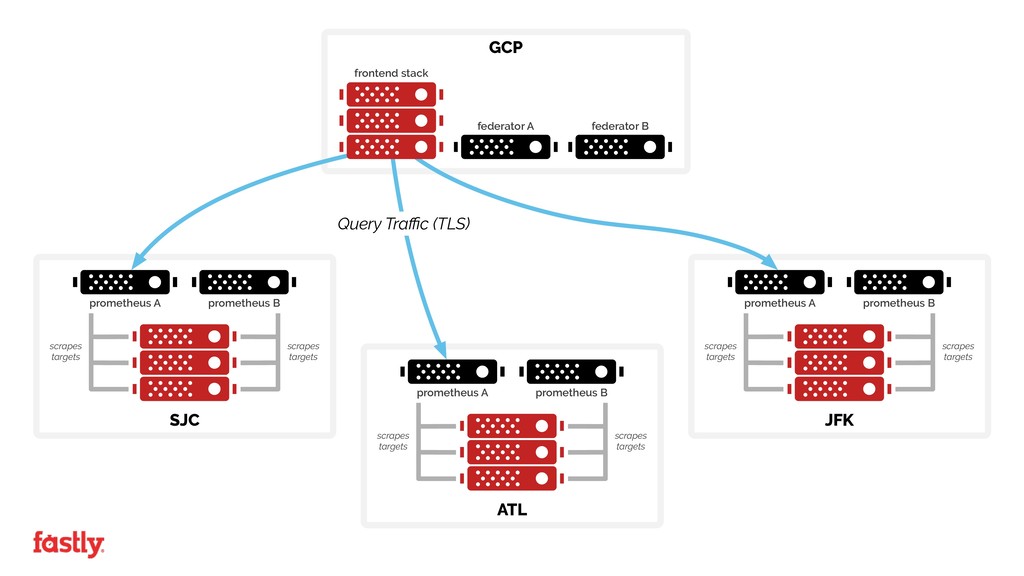
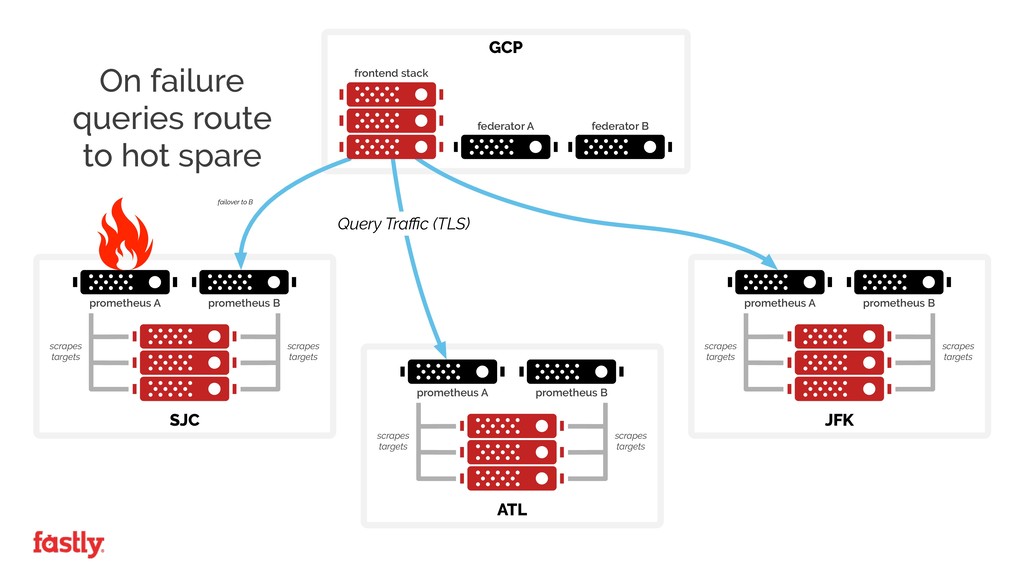
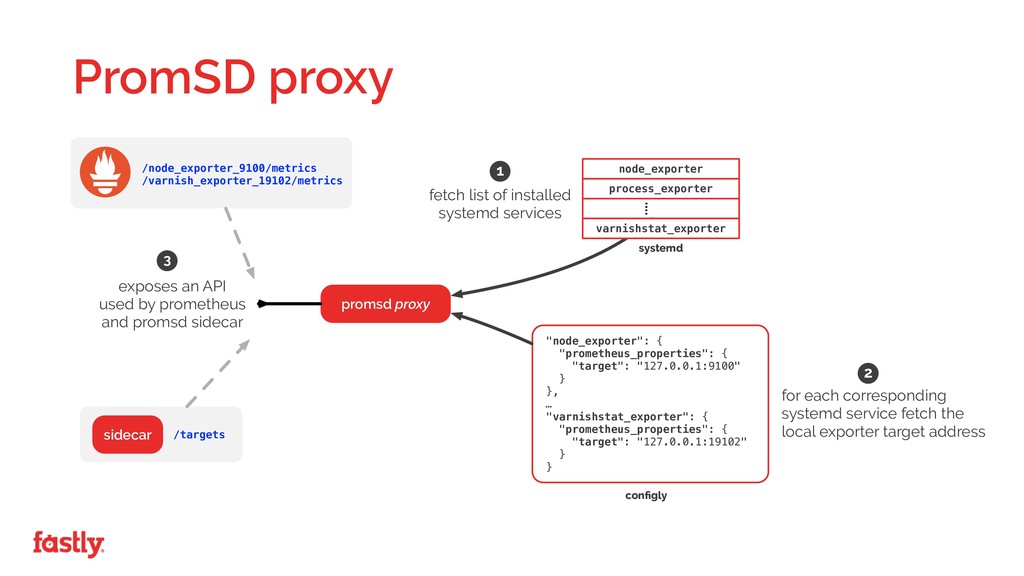
It hasn't been completely smooth sailing and deploying Prometheus across a globe spanning network serving over 10% of the world’s internet traffic has raised its fair share of technical and challenges in moving from centralized push based monitoring systems to a heavily distributed pull based architecture.
In this presentation you will learn how we addressed these challenges in ways that deviate slightly from conventional wisdom, the mistakes we made along the way, and how the new system has been received by our teams.
We hope that our experiences can help you better understand, from a practical perspective, how to be adapt your knowledge of monitoring past and apply it so be successfully introduce Prometheus to your organization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![promsd sidecar "exporter_hosts": [ "10.0.0.1", "10.0.0.2", "10.0.0.3", "10.0.0.4" ] configly](https://files.speakerdeck.com/presentations/2c582dfd954342208974e919a2fe358e/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}