Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
これからの強化学習_3.1_3.2
Search
ij_spitz
May 31, 2017
Technology
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
これからの強化学習_3.1_3.2
ij_spitz
May 31, 2017
More Decks by ij_spitz
See All by ij_spitz
GunosyにおけるABテストの全容
ij_spitz
3
2.3k
プロダクト改善のためのデータ分析入門
ij_spitz
1
100
海外スタートアップにおけるA/Bテスト基盤の紹介
ij_spitz
9
17k
GunosyにおけるABテスト
ij_spitz
1
490
fitbitではじめるオープンデータ
ij_spitz
0
180
食べログデータから見る東新宿と西早稲田のランチ事情
ij_spitz
0
390
Linuxとファイル
ij_spitz
0
110
紳士なおじさんYeomanに学ぶ異性を落とす3つのテクニック
ij_spitz
0
220
Supporter Opinion
ij_spitz
0
81
Other Decks in Technology
See All in Technology
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
280
デジタル・デザイン構想 by Sayaka Ishizuka
y150saya
0
200
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
290
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
340
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
3.8k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.3k
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
840
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
2.4k
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
200
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
650
最近評価が難しくなった
maroon8021
0
260
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Featured
See All Featured
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
The Curse of the Amulet
leimatthew05
2
13k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Typedesign – Prime Four
hannesfritz
42
3.1k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
How to make the Groovebox
asonas
2
2.3k
Being A Developer After 40
akosma
91
590k
Unsuck your backbone
ammeep
672
58k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
30 Presentation Tips
portentint
PRO
1
340
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Transcript
第3章 強化学習の工学応用 3.1・3.2 株式会社Gunosy データ分析部 石塚 淳
2 ©Gunosy Inc. 3.1 高次元・実環境における強化学習 目次 • 3.1.1 最適制御問題 •
3.1.2 時間逆方向の価値観数の伝搬に基づく運動学習 • 3.1.3 時間方向の内部シミュレーション計算を用いた運動学習 • 3.1.4 おわりに
3 ©Gunosy Inc. 3.1 高次元・実環境における強化学習 • コンピュータゲームや囲碁では熟練者を打ち負かす事例が生み出されている ◦ 学習に必要な膨大なサンプルを容易に収集できる •
ヒューマノイドロボットのような多自由度・高次元のシステムが動的に変化する環境におい て自律的に学習し動作するための技術開発 ◦ 学習に必要な大漁のデータを取得することが極めて難しく、実応用への道筋が明らか ではない ▪ 実応用へのアプローチを紹介することが本節の目標
4 ©Gunosy Inc. 3.1.1 最適制御問題 式 (3.1.1) の力学系の拘束条件下で目的関数を最小化するための制御則を求める問題 • x:
システムの状態変数, u: 制御入力 • π: 制御則 • J: 目的関数 • r: コスト関数, Φ: 終端コスト関数
5 ©Gunosy Inc. 3.1.1 最適制御問題 価値観数とベルマン方程式は以下のようになる
6 ©Gunosy Inc. 3.1.2 時間逆方向の価値観数の伝搬に基づく運動学習 • 対象のシステムが線形の場合、解析的に解ける ◦ テキストはシステムが線形でコスト関数が 2次の場合
• 対象が非線形の場合、近似的に価値観数を導出する ◦ 状態空間全域にわたって価値観数を近似的に求めることは困難 ▪ 多くの状態変数を持つため、計算量が膨大になる ▪ => 運動軌道周りに注力して制御則を導出する
7 ©Gunosy Inc. 3.1.2 時間逆方向の価値観数の伝搬に基づく運動学習 • ある軌道まわりで価値関数の2次近似を導出し、その近似された価値関数を最小化するよ うな制御則を用いる方法を考える • 時間逆方向に価値観数の2次モデルを伝搬させる
◦ https://ja.wikipedia.org/wiki/%E5%BE%AE%E5%88%86%E5%8B%95%E7%9 A%84%E8%A8%88%E7%94%BB%E6%B3%95 が詳しい
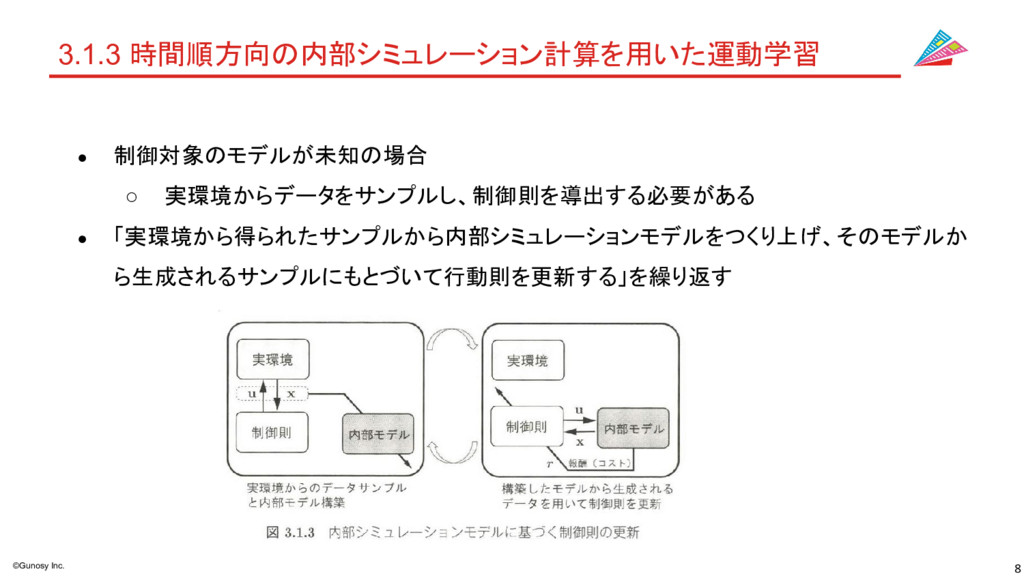
8 ©Gunosy Inc. 3.1.3 時間順方向の内部シミュレーション計算を用いた運動学習 • 制御対象のモデルが未知の場合 ◦ 実環境からデータをサンプルし、制御則を導出する必要がある •
「実環境から得られたサンプルから内部シミュレーションモデルをつくり上げ、そのモデルか ら生成されるサンプルにもとづいて行動則を更新する」を繰り返す
9 ©Gunosy Inc. 3.2 連続的な状態・行動空間への拡張:マルチロボットシステムへの適用 目次 • 3.2.1 マルチロボット強化学習 •
3.2.2 頑健なMRSのための強化学習法 • 3.2.3 適用例:均質なMRSの協調行動獲得 • 3.2.4 おわりに
10 ©Gunosy Inc. 3.2 連続的な状態・行動空間への拡張:マルチロボットシステムへの適用 • 3.2節ではマルチロボットシステム(複数のロボットからなる系)に対する強化学習のアプ ローチを紹介 ◦ 利点
▪ 並列作業による効率化 ▪ 協調作業による高度化 ▪ 故障に対する頑健性 ◦ 課題 ▪ 次元の呪い ▪ 他エージェントの動きが一定でないため環境が動的 ▪ 不完全知覚問題
11 ©Gunosy Inc. 3.2.2 頑健なMRSのための強化学習法 • 多くの研究では、ロボットはシステム特性をある程度理解した上で、有効であろう役割分担 や必要な機能が各ロボットにあらかじめ与えられている ◦ 非均質なロボットで構成される
• 想定外の状況下でも有効な役割分担を自律的に発現するとともにその役割を可塑的に変 化しうる ◦ 均質なロボットで構成される ◦ 自律的機能分化: 各ロボットが状況に応じた機能の適応的形成と動的割り当てを同時 に行う
12 ©Gunosy Inc. 3.2.2 頑健なMRSのための強化学習法 • ベイズ判定法に基づく強化学習法 ◦ ルール構成 ▪
各クラスをガウス分布によって表現し、各クラスの確率分布を表すパラメータとそ のときの出力をif-then形式で記述したルールとして学習器に記憶する(クラス ≒ ルール) ◦ 動作選択 ▪ 入力に対する各ルールの事後確率をベイズの公式から求め、事後確率最大の ルールに記述されている出力を実行する
13 ©Gunosy Inc. 3.2.3 適用例:均質なMRSの協調行動獲得 • アーム型ロボットの協調荷上げタスク ◦ 3関節を持つアームロボット3台が荷物を規定の高さまで傾けずに持ち上げる ◦
ゴール時に報酬を、傾きがしきい値を超えた時に罰を全ロボットに与える ▪ 全ロボットが一切知識を持たない状態から行った実験 ▪ 安定的な行動を獲得後に1台のロボットを初期化する実験(割愛
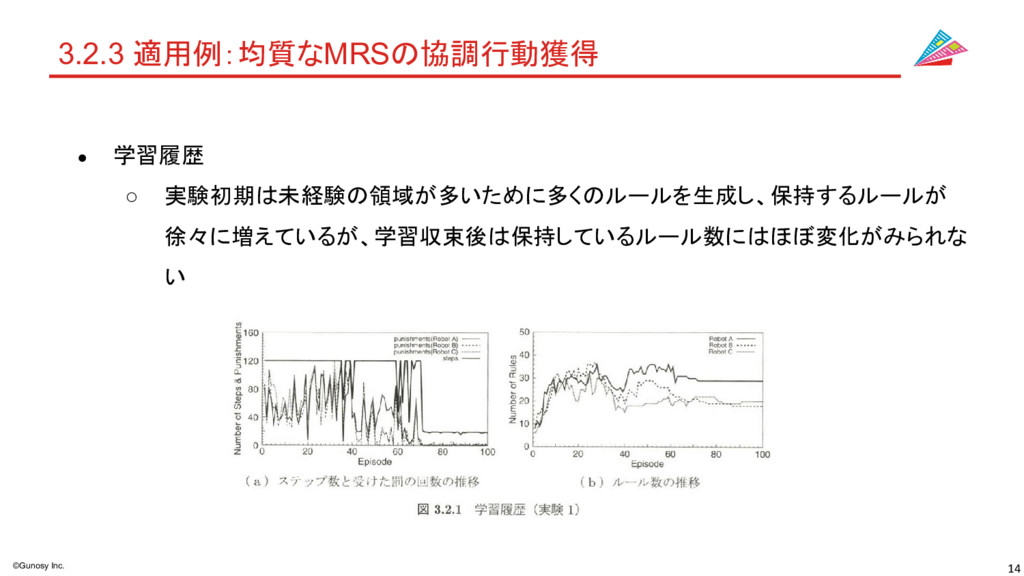
14 ©Gunosy Inc. 3.2.3 適用例:均質なMRSの協調行動獲得 • 学習履歴 ◦ 実験初期は未経験の領域が多いために多くのルールを生成し、保持するルールが 徐々に増えているが、学習収束後は保持しているルール数にはほぼ変化がみられな
い
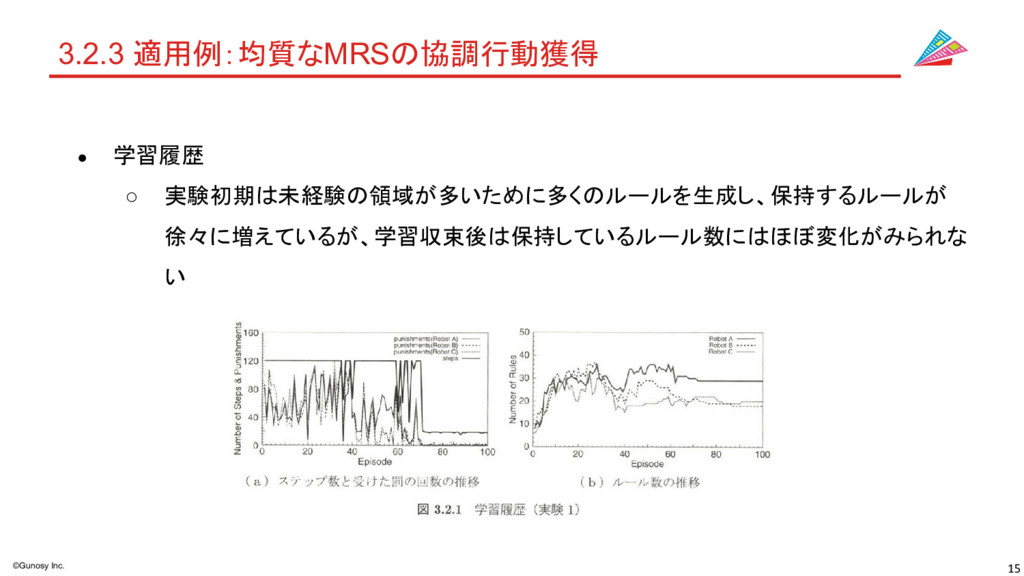
15 ©Gunosy Inc. 3.2.3 適用例:均質なMRSの協調行動獲得 • 学習履歴 ◦ 実験初期は未経験の領域が多いために多くのルールを生成し、保持するルールが 徐々に増えているが、学習収束後は保持しているルール数にはほぼ変化がみられな
い
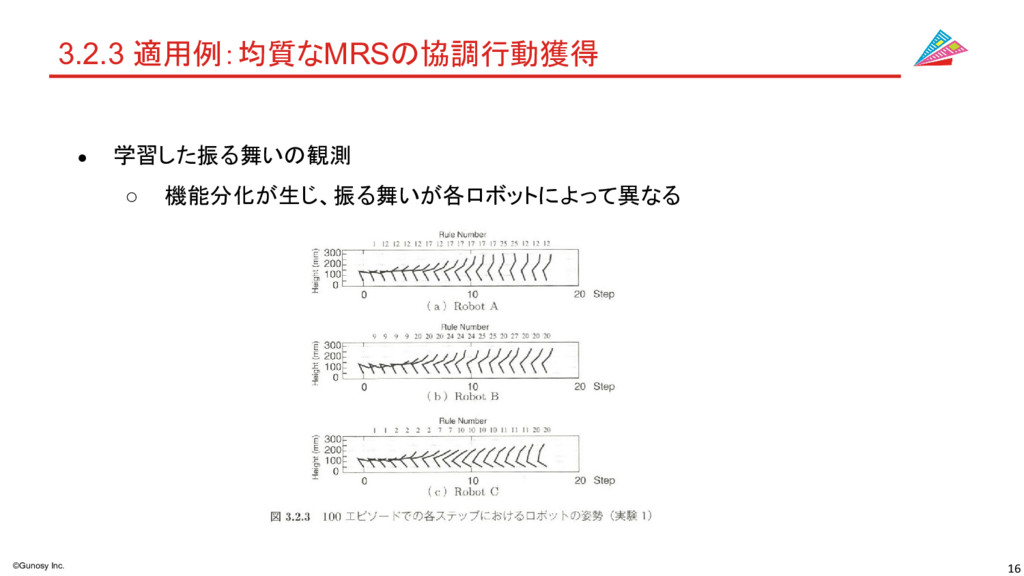
16 ©Gunosy Inc. 3.2.3 適用例:均質なMRSの協調行動獲得 • 学習した振る舞いの観測 ◦ 機能分化が生じ、振る舞いが各ロボットによって異なる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}