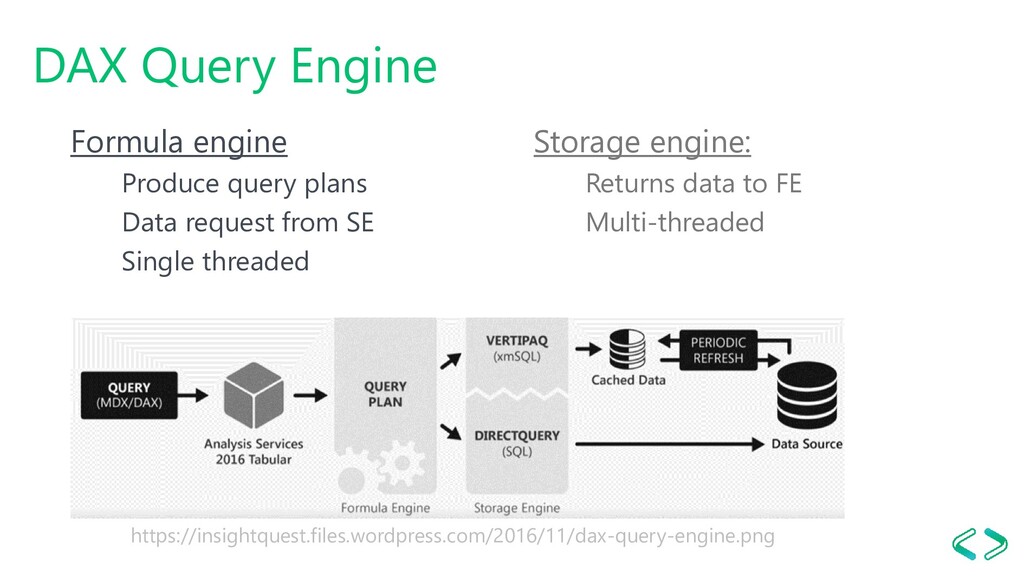
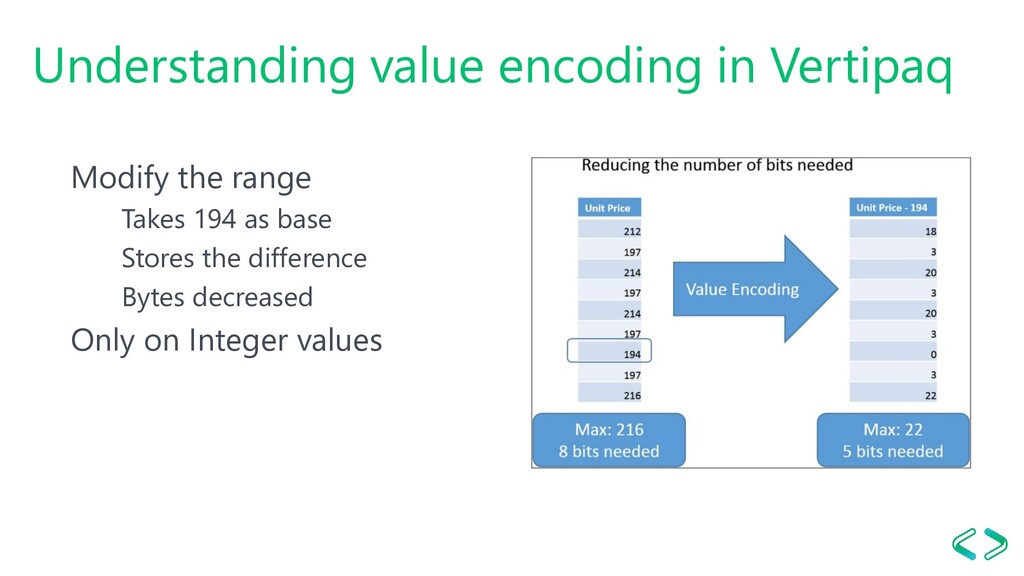
on disk Encoded and uncompressed in memory The process when importing data: 1. Read the data and detect data types 2. Encode 3. Compress when saving on disk
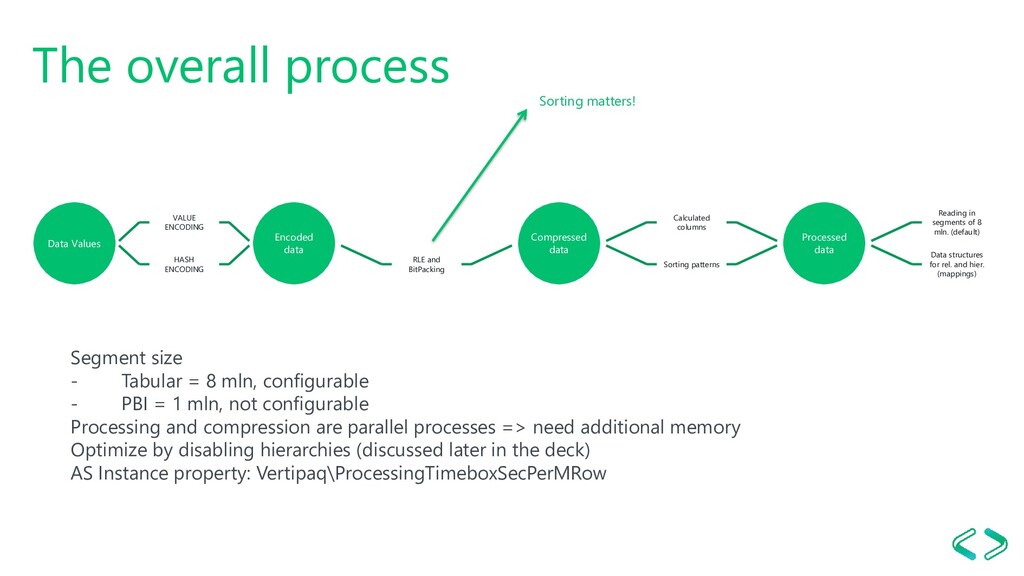
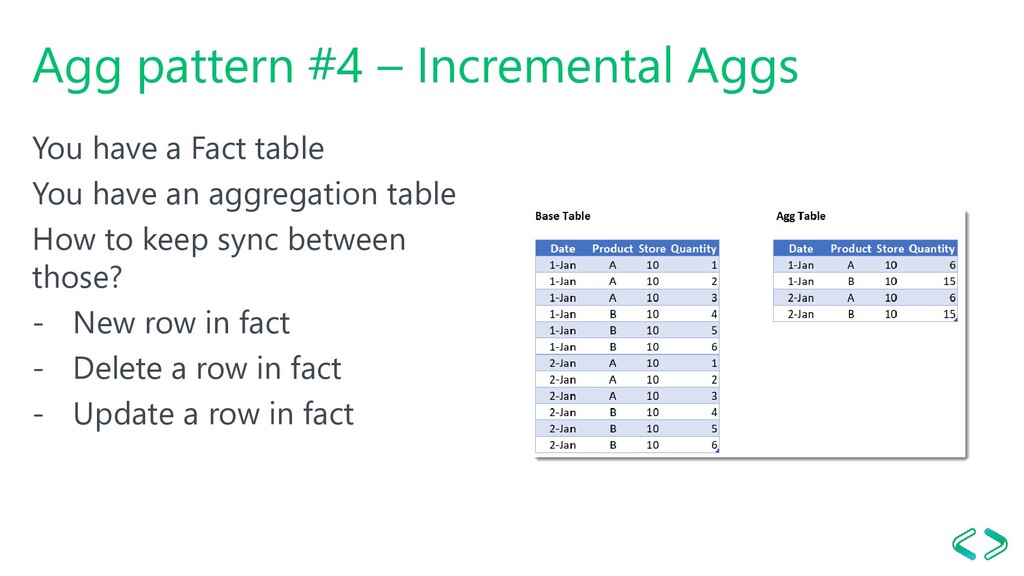
data RLE and BitPacking Compressed data Calculated columns Sorting patterns Processed data Reading in segments of 8 mln. (default) Data structures for rel. and hier. (mappings) Segment size - Tabular = 8 mln, configurable - PBI = 1 mln, not configurable Processing and compression are parallel processes => need additional memory Optimize by disabling hierarchies (discussed later in the deck) AS Instance property: Vertipaq\ProcessingTimeboxSecPerMRow Sorting matters!
from the source Text and big numbers are with high priority If you need analysis – try to push it to the DB engine (if possible) Filter, filter, filter!!!
by default in PBI - Required for Time Intelligence How to change it? - PowerBI settings - Choose an explicit date table (mind the gaps in dates and ranges)
- Take more storage - High precision is not always required How to change it? - PowerBI: change data types - SSAS Tabular: SSDT or Tabular Editor or TSML/XMLA
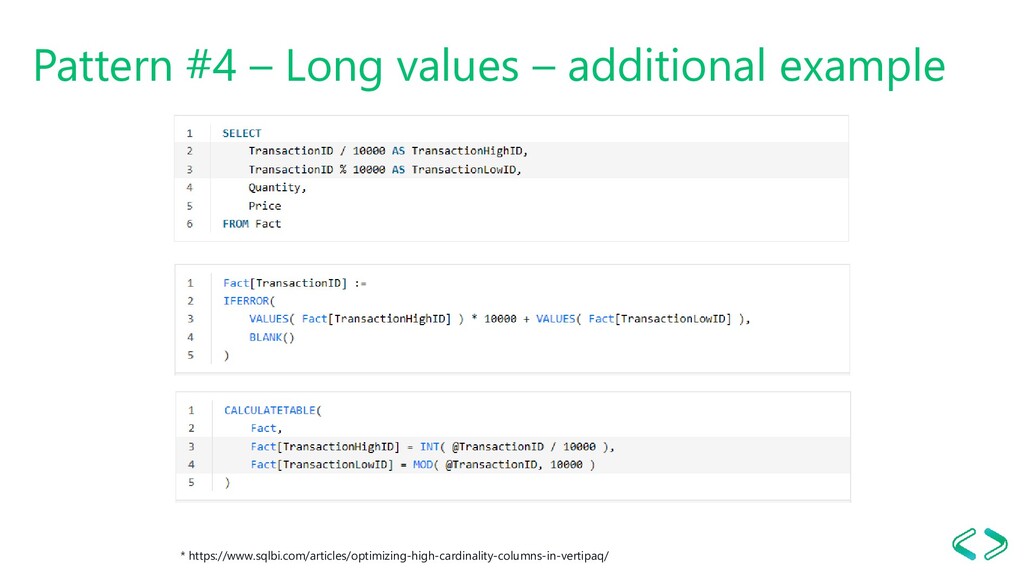
20-digit value - Can use DECIMAL - Not much of an effect How to fix it? - Split the column to parts 100200300 = 100*1000000 + 200*100000 + 300 - Numbers: use modulo and division - Text: use Left/Substring/Right
- Hits FE - Not always required How to fix it? - Split whole part from decimal part into columns 12.4 = 12 + 4/10 - Write explicit measures that first aggregate then devide SUM(WholePart) + SUM(DecimalPart)/10
in the same column in the source - Usually date or time is needed for analysis How to fix it - Split date and time into separate columns - Define granularity for time (do you need HH, MM and SS or just HH); separate them in different columns with high cardinality - Store the date in int format (i.e. YYYYMMDD)
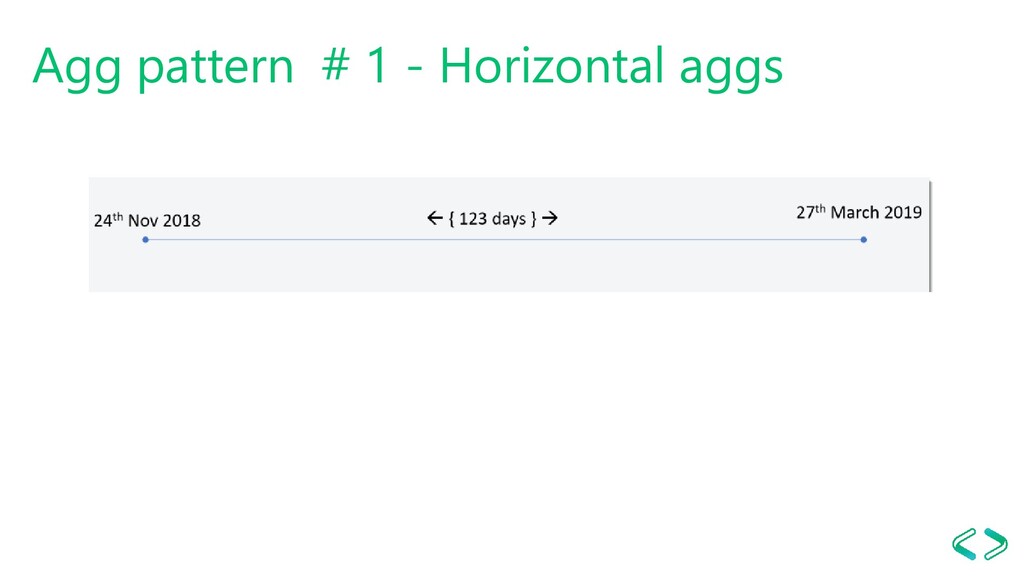
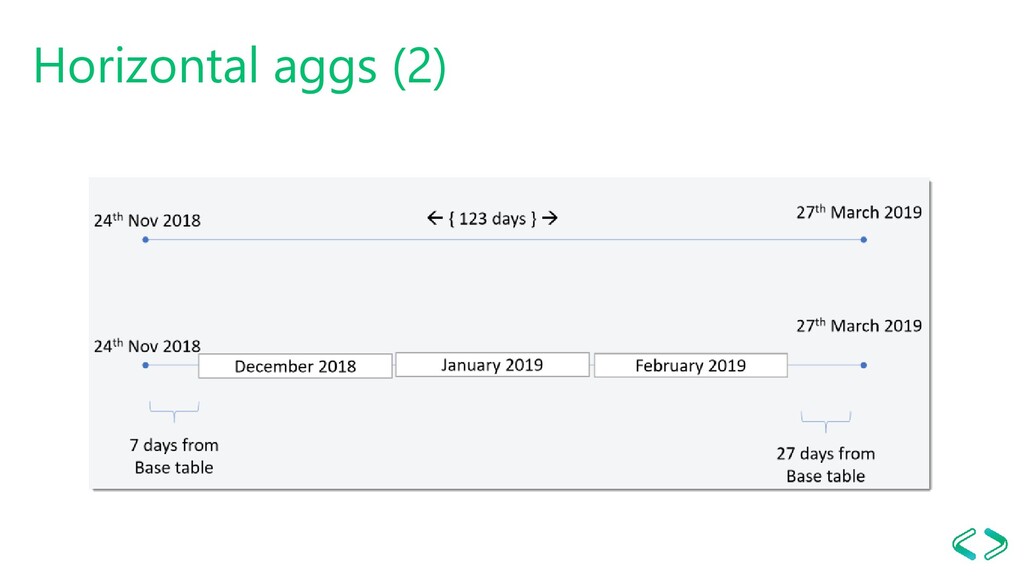
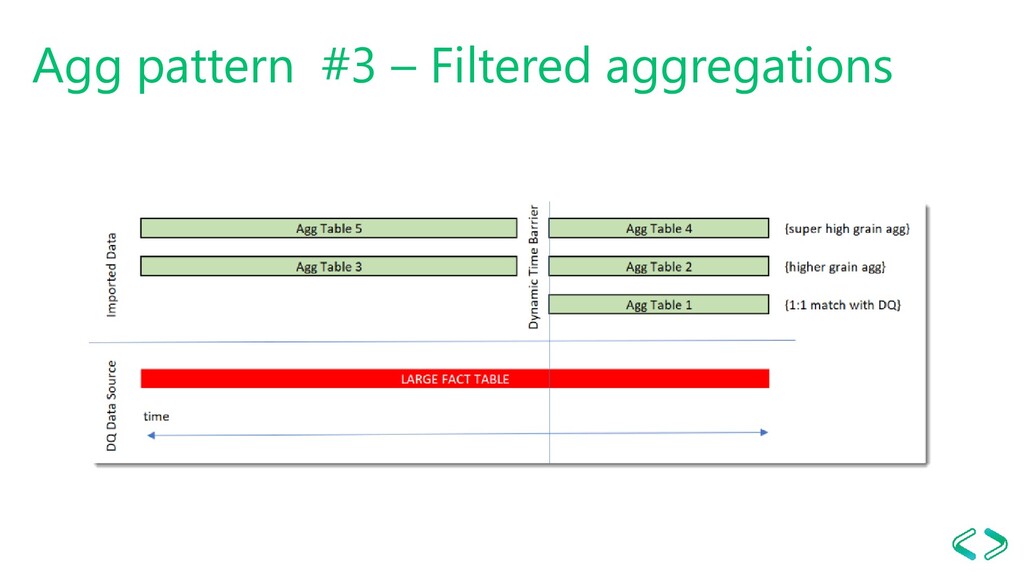
awareness) Scenario - Transactional Fact table(s) - Queries aggregate data in ranges i.e. last X days, last month, last week, etc. The solutions - Aggregate table per week - Aggregate table per month - Lots of DAX (~120 lines per measure) - https://dax.tips/2019/10/21/creative-aggs-part-ii-horizontal-aggs/
Time intelligence calculations, multiple periods - Custom periods like last 28 days, last 9 weeks Solution - Additional time intelligence table calculated at ETL or DAX
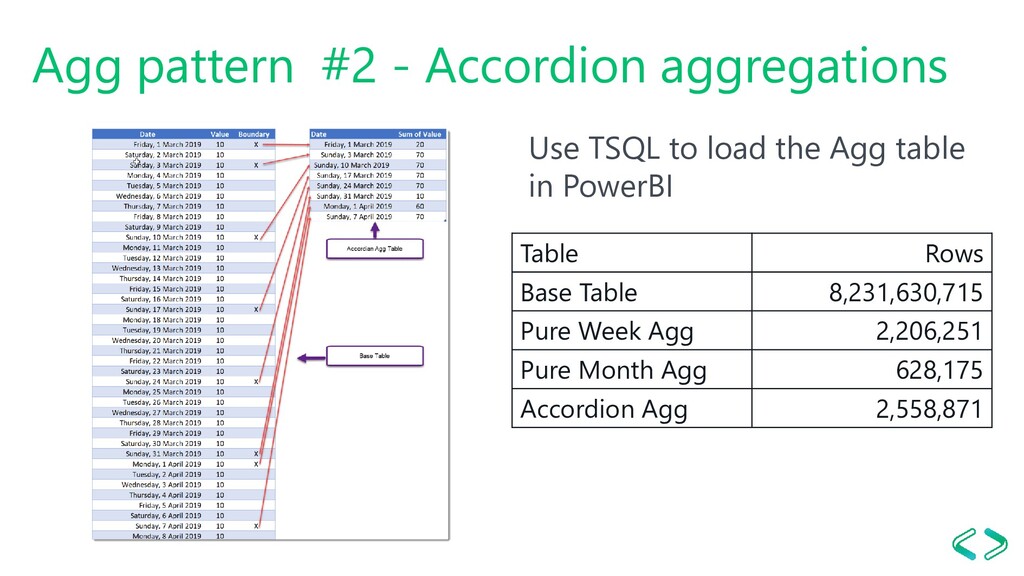
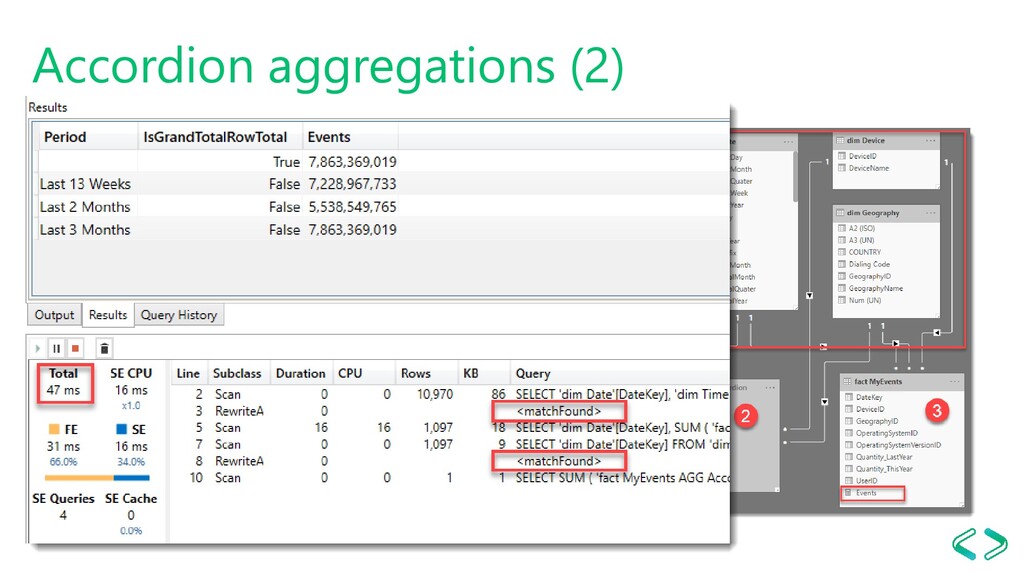
Aggregation Awareness Scenario - Transactional fact table - Monthly, weekly or mixed reporting The solution - Accordion agg table - Can be combined with Row-Based TI
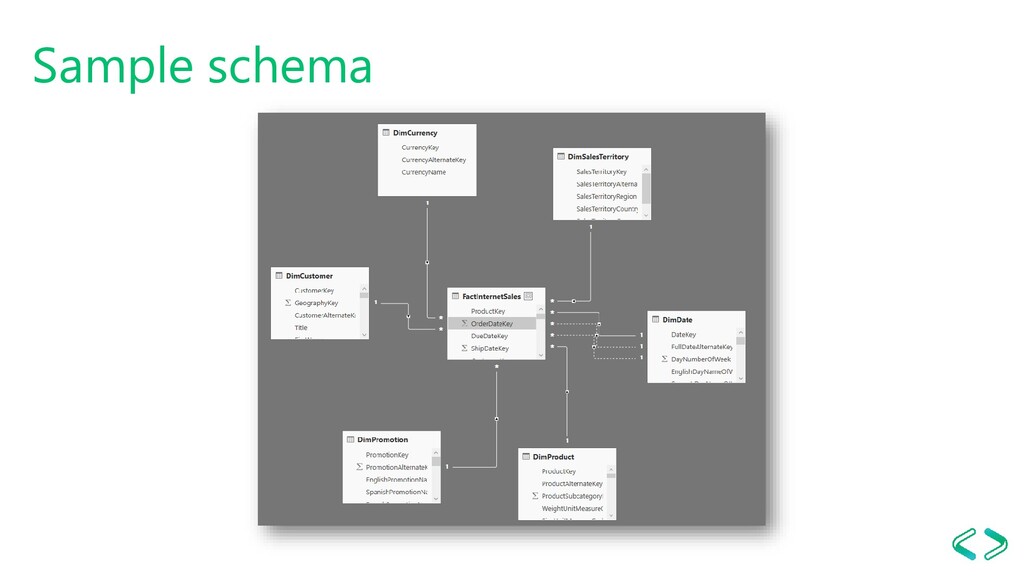
type conversions). Filter out unused dimension values (unless a business scenario requires them). Integer Surrogate Keys (SK). Hint for VALUE encoding on numeric columns (AS ONLY). Hint for disabling hierarchies on SKs (AS ONLY). - speeds up processing - decreases model size (eventually)
cardinality (data type conversions). Consider moving calculations to the source (to use in compression evaluations). Ordered by less diverse SKs first (to maximize compression). Increased Tabular sample size for deciding Encoding, by considering segments and partitions(AS ONLY). Hint for VALUE encoding on numeric columns (AS ONLY). Hint for disabling hierarchies (AAS and AS2017 CU7 ONLY).
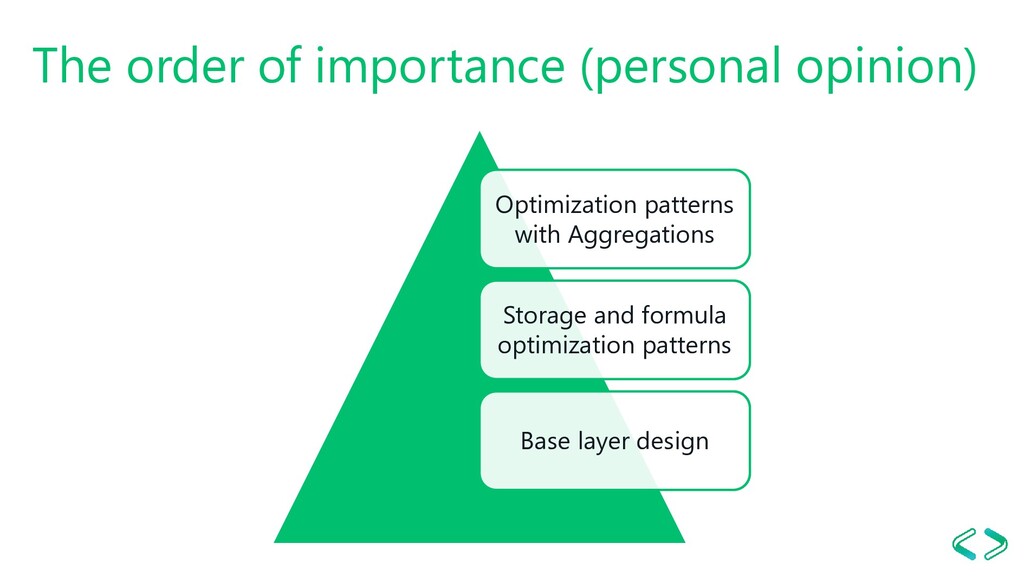
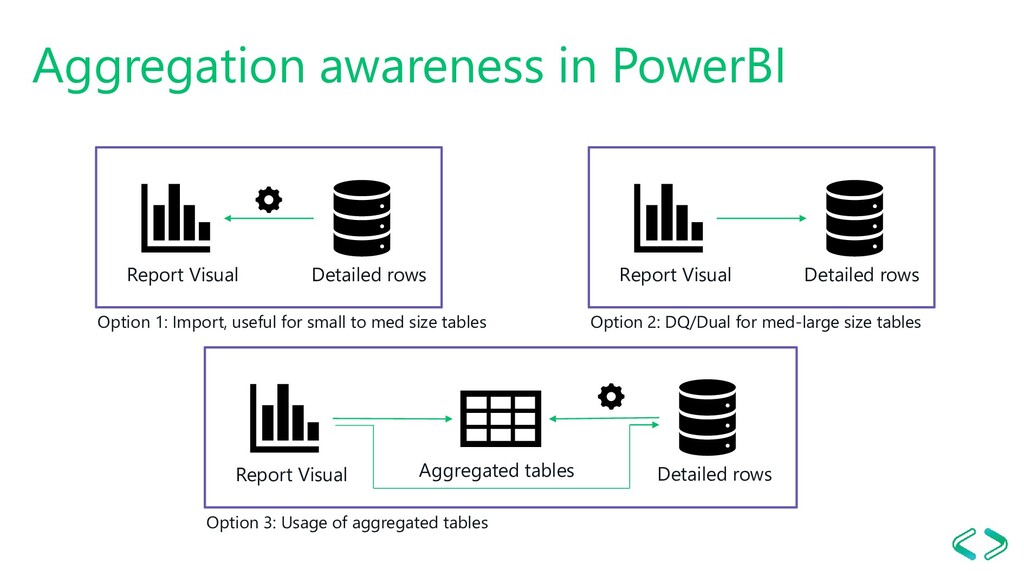
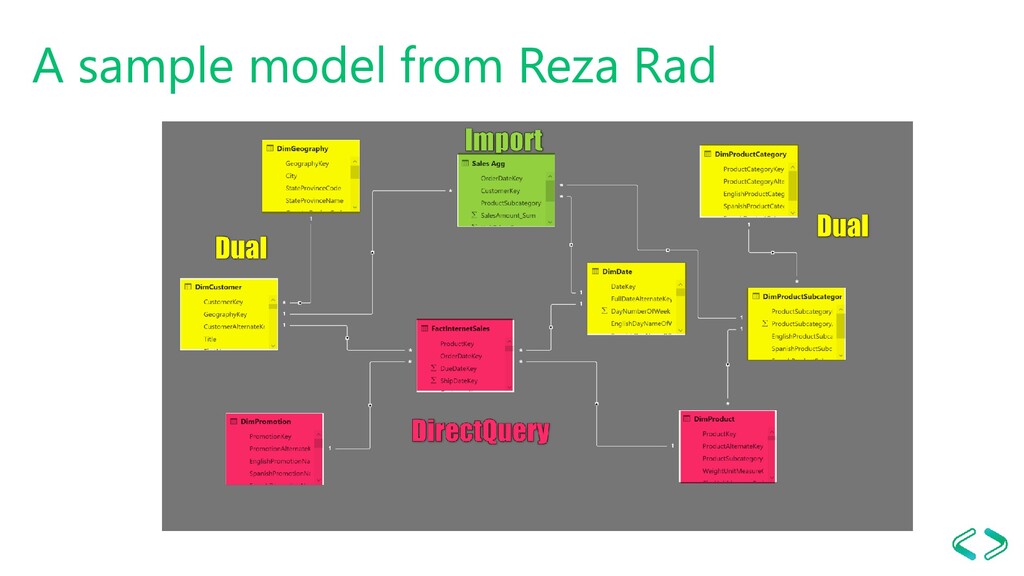
friend, and Bidirectional filtering is the enemy As small memory footprint as possible Decrease calculated tables and columns Tweak server and model settings Use custom aggregations tables DAX Studio, Vertipaq Analyzer and Tabular Editor FTW
Server 2012 Analysis Services https://blogs.msdn.microsoft.com/karang/2013/08/02/sql-2012-tabular- performance-tuning-of-tabular-models-in-sql-server-2012-analysis-services/ Modeling AS for Scalability https://blogs.msdn.microsoft.com/analysisservices/2018/08/08/whitepaper- on-modeling-for-as-tabular-scalability/ Phil Seamarks’s series on smart aggregations https://dax.tips/2019/10/18/creative-aggs-part-i-introduction/
Profiler - NOT deprecated for Analysis Services DAX Studio - FREE and extremely powerful (http://daxstudio.org/) Community excel templates - VertiPaq Analyzer (https://www.sqlbi.com/tools/vertipaq-analyzer/) Tabular Editor (https://tabulareditor.github.io/) - Design and management
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}