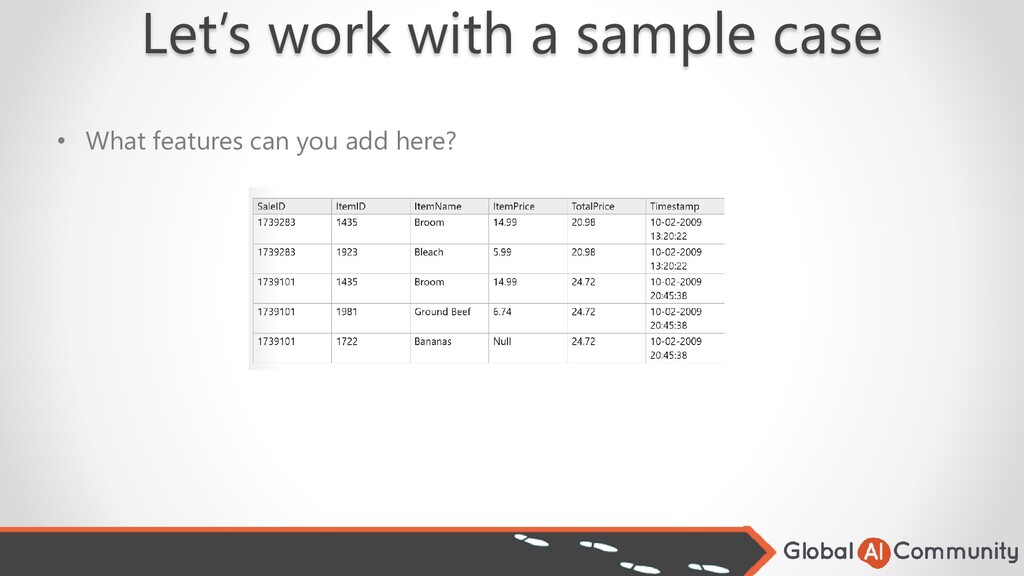
are sold out before the end of each month and management needs to know how to properly stock them • Your input data is like this: • You need to go through the whole data science process. What would be the steps?
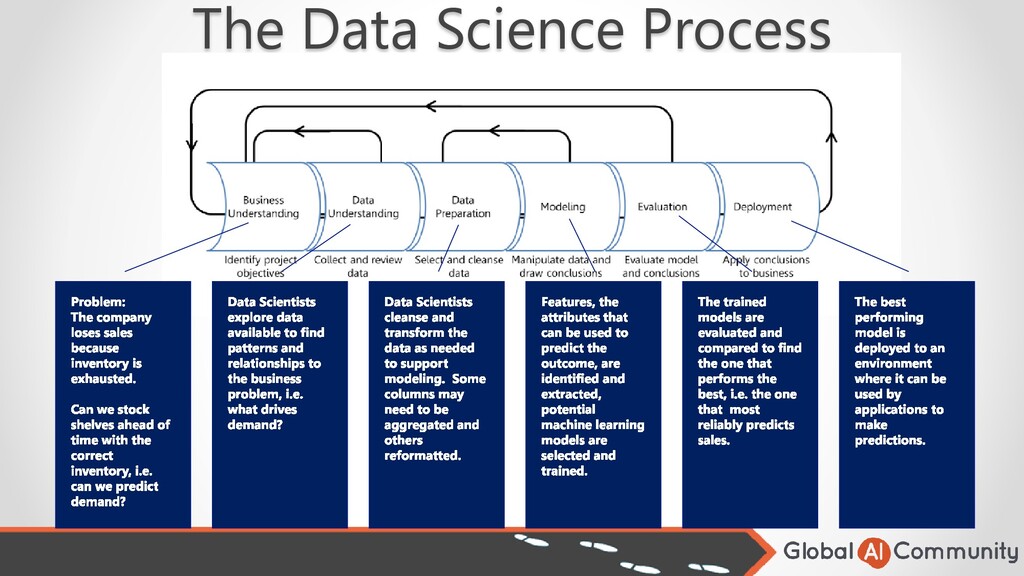
can also be done by the data scientist. • Cleanse data of null and bad values. • Data may be aggregated (counts, sums, averages, etc.) and reformatted or calculated columns may be added. • Data can come from many sources and formats such as SQL Server, Cosmos DB, Flat Files, etc. • Data must be merged from the sources into a consistent and useful dataset.
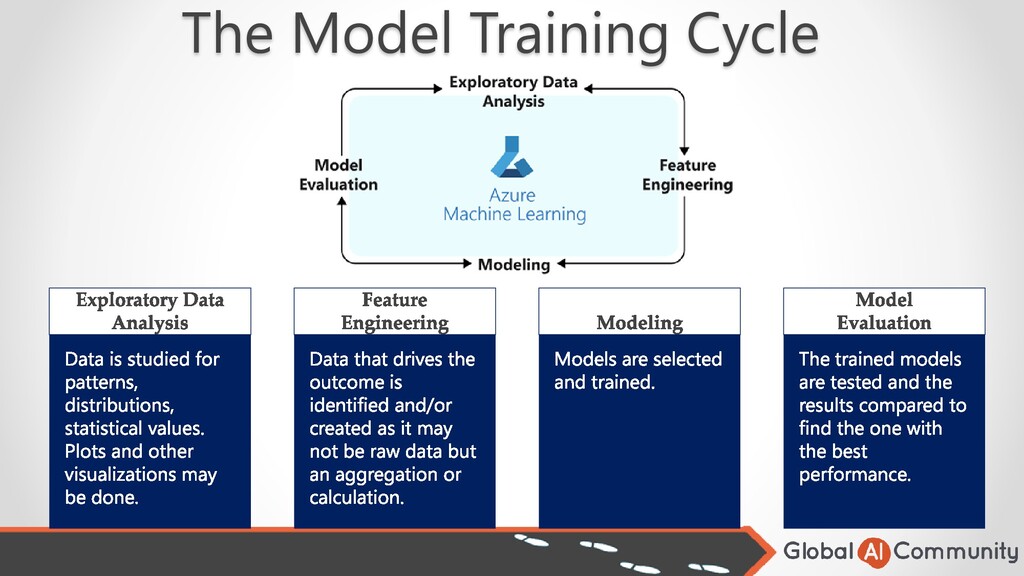
to support you machine learning model. • In some cases, raw data can be used with little or no transformation. • In other cases, you need to create the data you need through transformations or aggregations. • Example of possibly little transformation might be the customer country code. • Example of a transformation might be to calculate the patient age using birth date and create age bands like ‘< 18’, ’18 – 25’, ‘26 – 35’, ‘36 – 45’, etc. • Example of aggregation would be to count the number of past readmissions for patient.
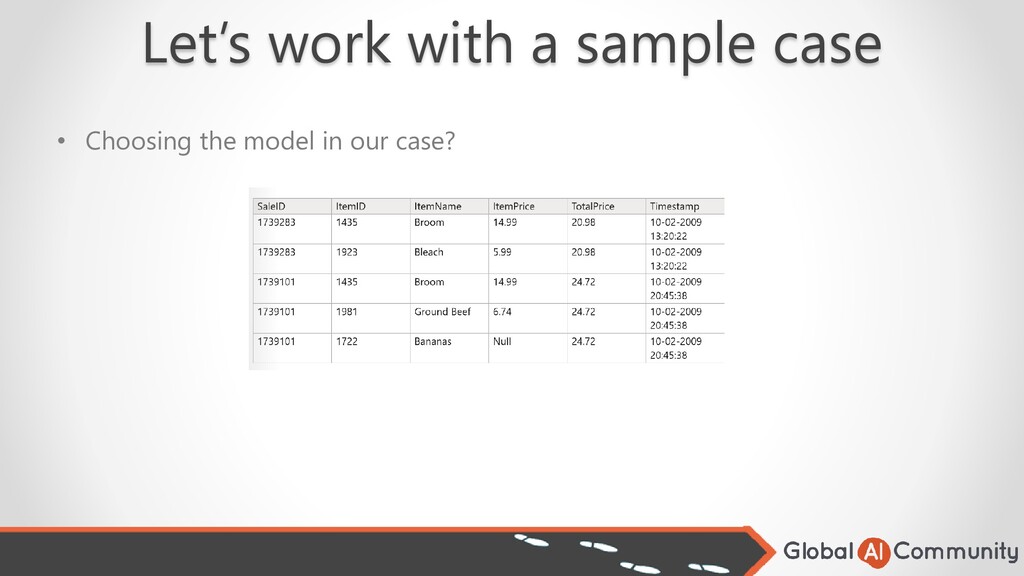
you think will have the best accuracy. • Different types of models work best for certain types of problems. • Some models can predict continuous values like sales. • Others classify data such as good email or SPAM. • Models vary in the complexity of algorithms they support. • More complex models require more resources to use.
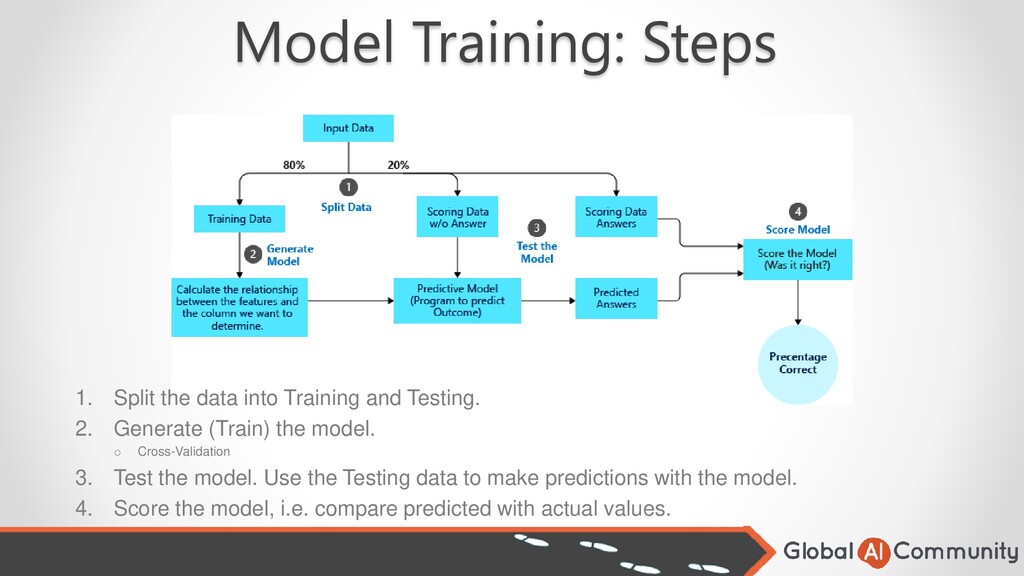
Testing. 2. Generate (Train) the model. o Cross-Validation 3. Test the model. Use the Testing data to make predictions with the model. 4. Score the model, i.e. compare predicted with actual values.
metrics that are useful when evaluating a classification model are accuracy and precision. To understand these terms, it is essential to understand what a confusion matrix is. A confusion matrix includes the following data. •True positive: the number of times a model predicts true (or yes) when it is actually yes •True negative: the number of times a model predicts false (or no) when it is actually false •False negative: the number of times a model predicts false when it is actually true •False positive: the number of times a model predicts true when it is actually false Mean squared error Mean squared error (MSE) is one of the most popular model evaluation metrics in statistical modeling. It allows you to look at how far your predictions are on average from the correct y values. These are just a couple of metric available for model evaluation. The type of model will drive the direction of the model evaluation, but the technique you choose will depend on whether the model is a classification or numerical prediction.
resource intensive using a lot of CPU cycles and memory. • The end result of model training is a small, lightweight, program called a model. • Using a model usually takes significantly less resources than training it. • The bottom line is that we don’t need to use the same platform for consuming the model that we used to train it.
be used such as by a web/mobile app. • Usually this is done by a developer. • Deployment requirements are very different from model training requirements. o Security o Dependencies o Availability • Ideal for cloud based containers.
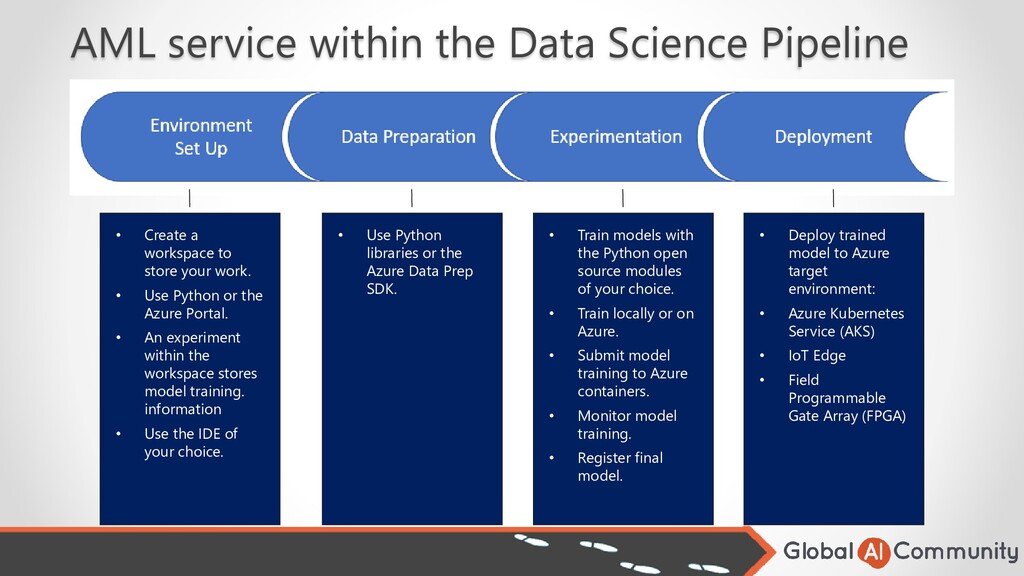
workspace to store your work. • Use Python or the Azure Portal. • An experiment within the workspace stores model training. information • Use the IDE of your choice. • Use Python libraries or the Azure Data Prep SDK. • Train models with the Python open source modules of your choice. • Train locally or on Azure. • Submit model training to Azure containers. • Monitor model training. • Register final model. • Deploy trained model to Azure target environment: • Azure Kubernetes Service (AKS) • IoT Edge • Field Programmable Gate Array (FPGA)
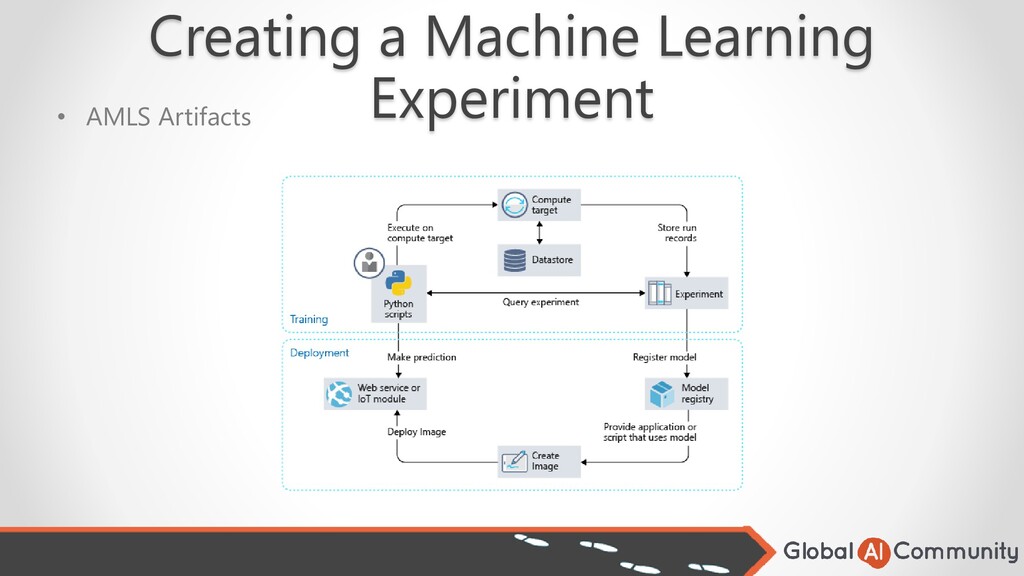
deploy it. • Target Deployment Environments Supported are: o Docker image o Azure Container Instances o Azure Kubernetes Service (AKS) o Azure IoT Edge o Field Programmable Gate Array (FPGA). • For the deployment, you need the following files: o A score script file tells AMLS to call the model. o An environment file specifies package dependencies o A configuration file requests the required resources for the container
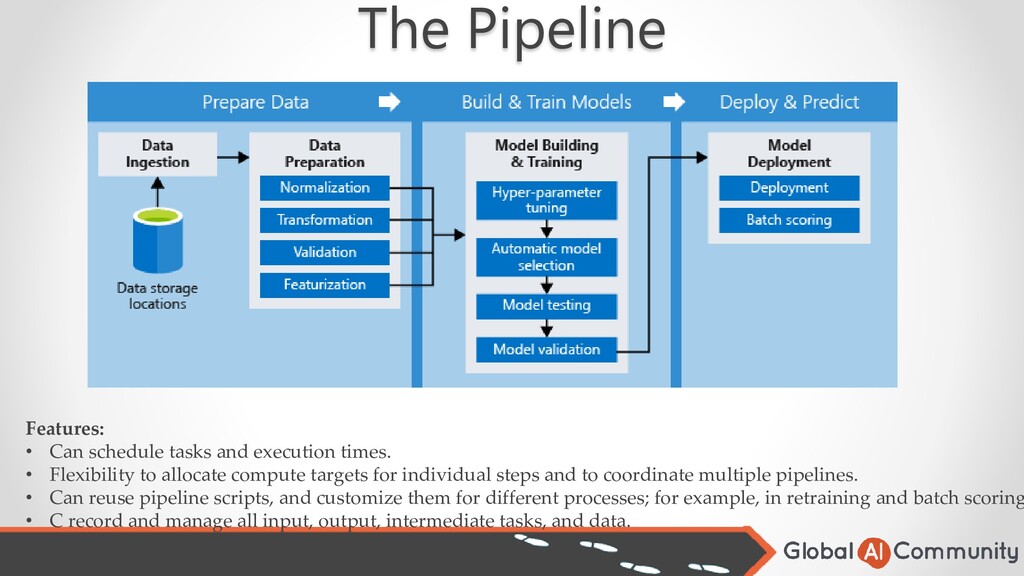
• Flexibility to allocate compute targets for individual steps and to coordinate multiple pipelines. • Can reuse pipeline scripts, and customize them for different processes; for example, in retraining and batch scoring • C record and manage all input, output, intermediate tasks, and data.
Limited resources (memory and CPU) • Azure Kubernetes Service (AKS) o Real-time interface o Production and web services o Highly scalable (auto-scale) o Supports GPU! • AML Compute o Batch interface o Normal and low-prio VMs managed by the AMLS o Supports GPU • Azure IoT edge • FPGA
o ACI (docker) (small loads) o AKS o WebService + GPU = AKS ONLY!!! • Batch scoring o Using pipelines! o Azure ML Compute (preview) o GPU + batch scoring = ML Compute WITH Pipelines
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}