Global Azure - designing and implementing a DWH in the cloud
A slidedeck from my talk on Global Azure Virtual Event 2020, where I shared what was the process and design of a DWH scenario I had to work on for a customer.
datawarehouse layers • Core concepts that differ from traditional DWH • Key issues to be aware of • Demos • Unzipping with ADF • Setting Datalake permissions (Gen 2)
to CSV/Excel based on multi table joins and filters • Singleton read operations • 100+ columns to export • Source – 1 trillion rows • Challenges for an on-prem solution • Capacity, licensing, hardware • Flexibility • Pressure on the source system during extraction
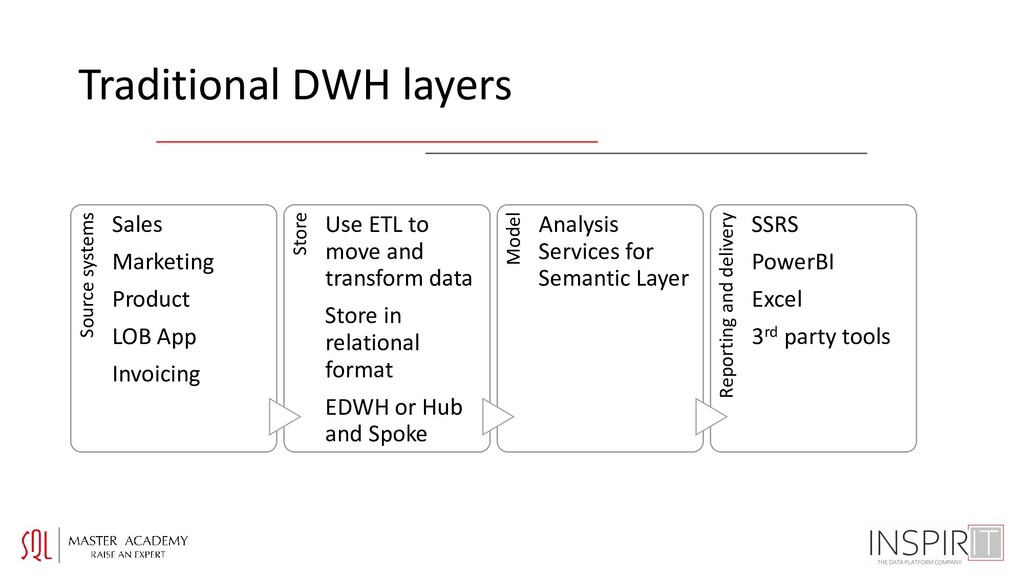
Invoicing Store Use ETL to move and transform data Store in relational format EDWH or Hub and Spoke Model Analysis Services for Semantic Layer Reporting and delivery SSRS PowerBI Excel 3rd party tools
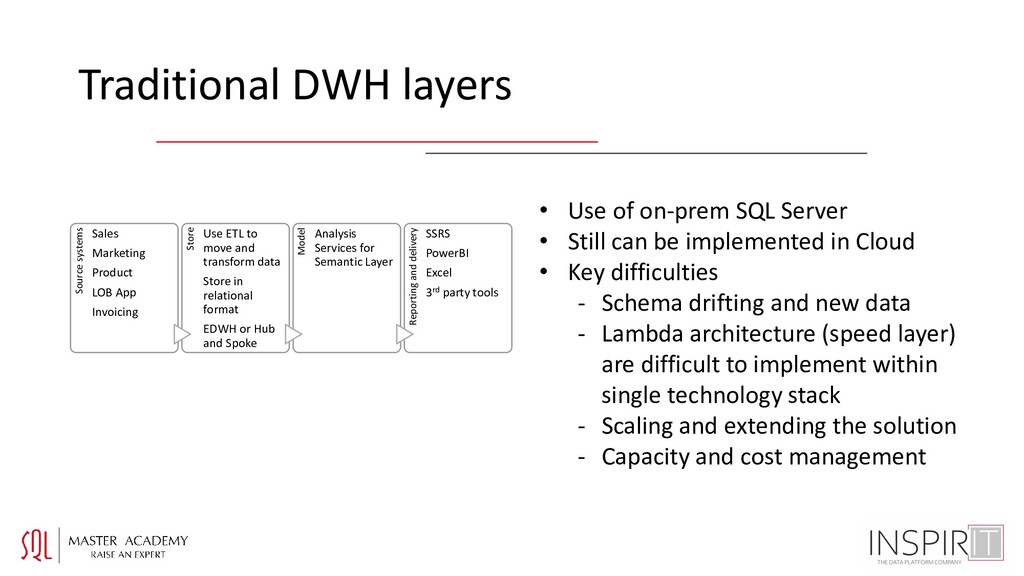
Invoicing Store Use ETL to move and transform data Store in relational format EDWH or Hub and Spoke Model Analysis Services for Semantic Layer Reporting and delivery SSRS PowerBI Excel 3rd party tools • Use of on-prem SQL Server • Still can be implemented in Cloud • Key difficulties - Schema drifting and new data - Lambda architecture (speed layer) are difficult to implement within single technology stack - Scaling and extending the solution - Capacity and cost management
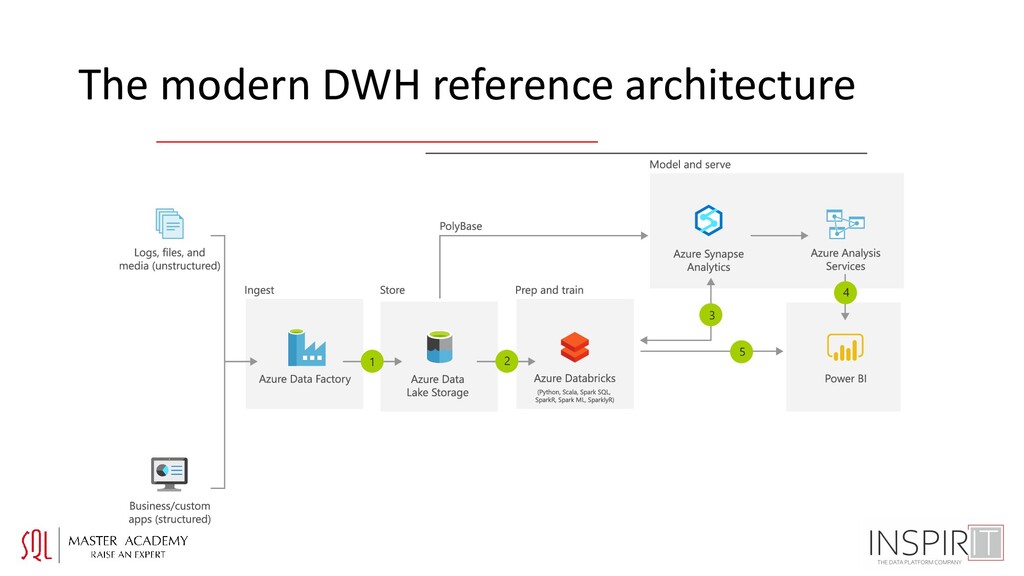
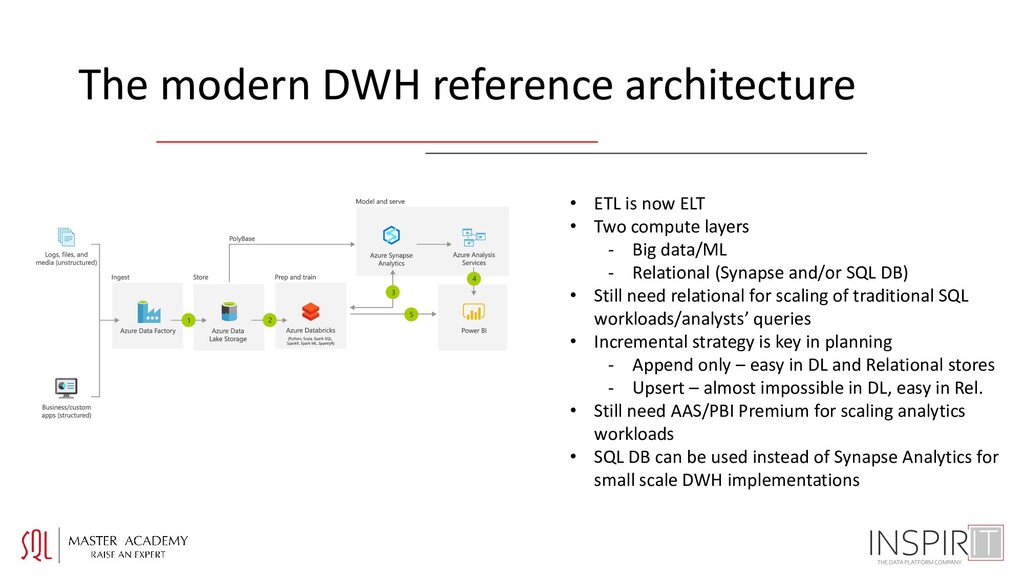
• Two compute layers - Big data/ML - Relational (Synapse and/or SQL DB) • Still need relational for scaling of traditional SQL workloads/analysts’ queries • Incremental strategy is key in planning - Append only – easy in DL and Relational stores - Upsert – almost impossible in DL, easy in Rel. • Still need AAS/PBI Premium for scaling analytics workloads • SQL DB can be used instead of Synapse Analytics for small scale DWH implementations
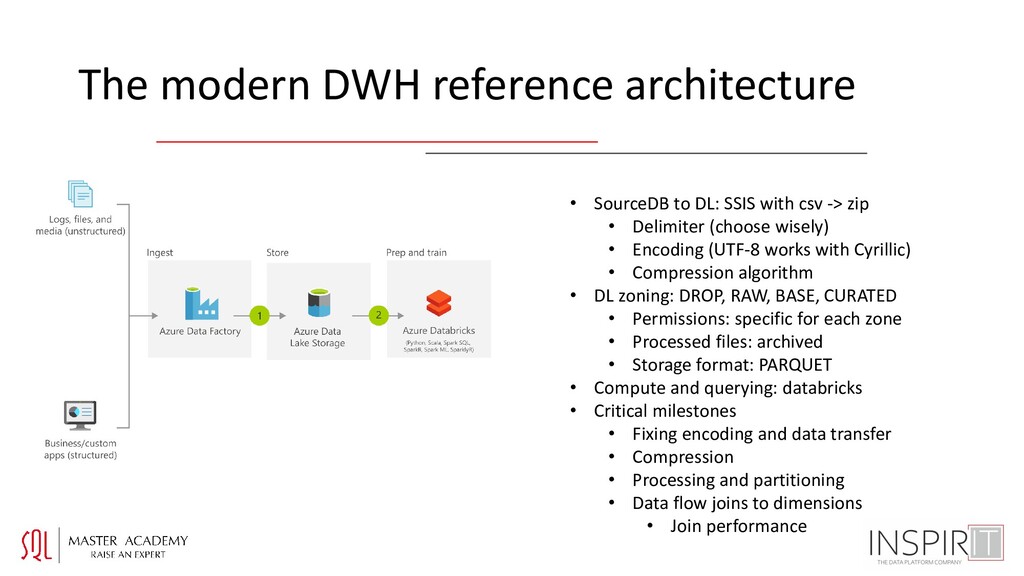
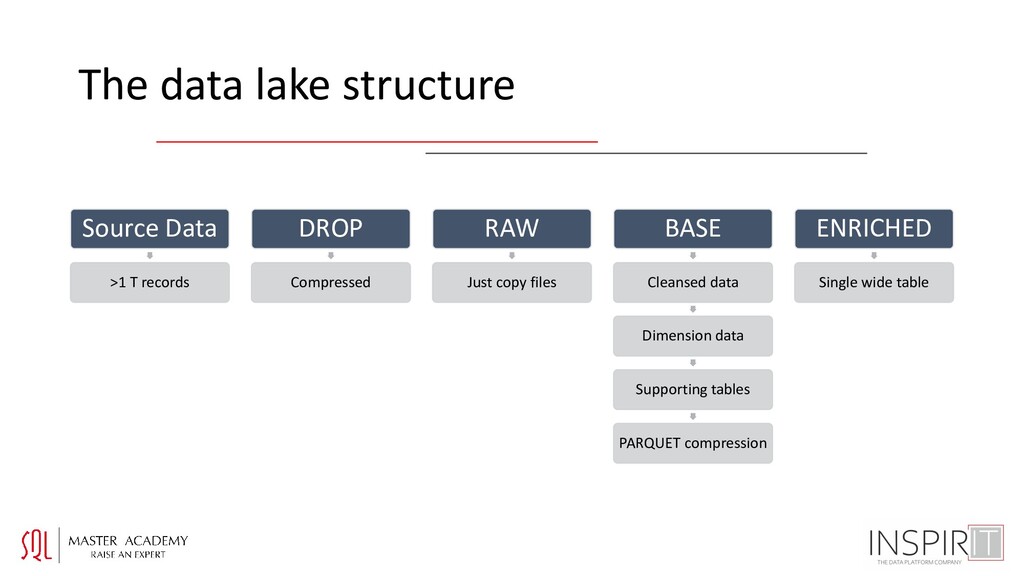
with csv -> zip • Delimiter (choose wisely) • Encoding (UTF-8 works with Cyrillic) • Compression algorithm • DL zoning: DROP, RAW, BASE, CURATED • Permissions: specific for each zone • Processed files: archived • Storage format: PARQUET • Compute and querying: databricks • Critical milestones • Fixing encoding and data transfer • Compression • Processing and partitioning • Data flow joins to dimensions • Join performance
• Header-detail of 2 sets of tables • Multiple nomenclatures • Including one with >10 mln records • Output: • Header • Join 3 times details • Join 9 times the 10 mln record nomenclature • Join ~10 times the other small tables
Requires insert only source • Updates/deletes are lost • DL writes by default are append • UPSERT • Not native for DL and/or spark • Can be implemented with: • Databricks delta • Union of full and delta and extracting the latest rows (if you have a timestamp_ • Separating insert/deletes/updates (you can use ADF Template “Parquet CRUD”
additional costs for metadata • Databricks is split into two – VMs and workspaces • ADF is paid in two different aspects • DIU/hour pipeline activities with compute • Core/hour for data flows
the entire flow with SMALL data and small compute • Test and verify which compression works for you • Plan your incremental strategy in advance • ADF • DEBUG does not write data unless you debug a pipeline • Use separate integration environment for debug with small TTL (you are paying for the time the IR is turned on) • Set partitioning for large dataset operations explicitly. Know your data distribution! • Plan for compute acquiring • Use dataset referencing • Schema drifting – choose between late binding or strict schema
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}