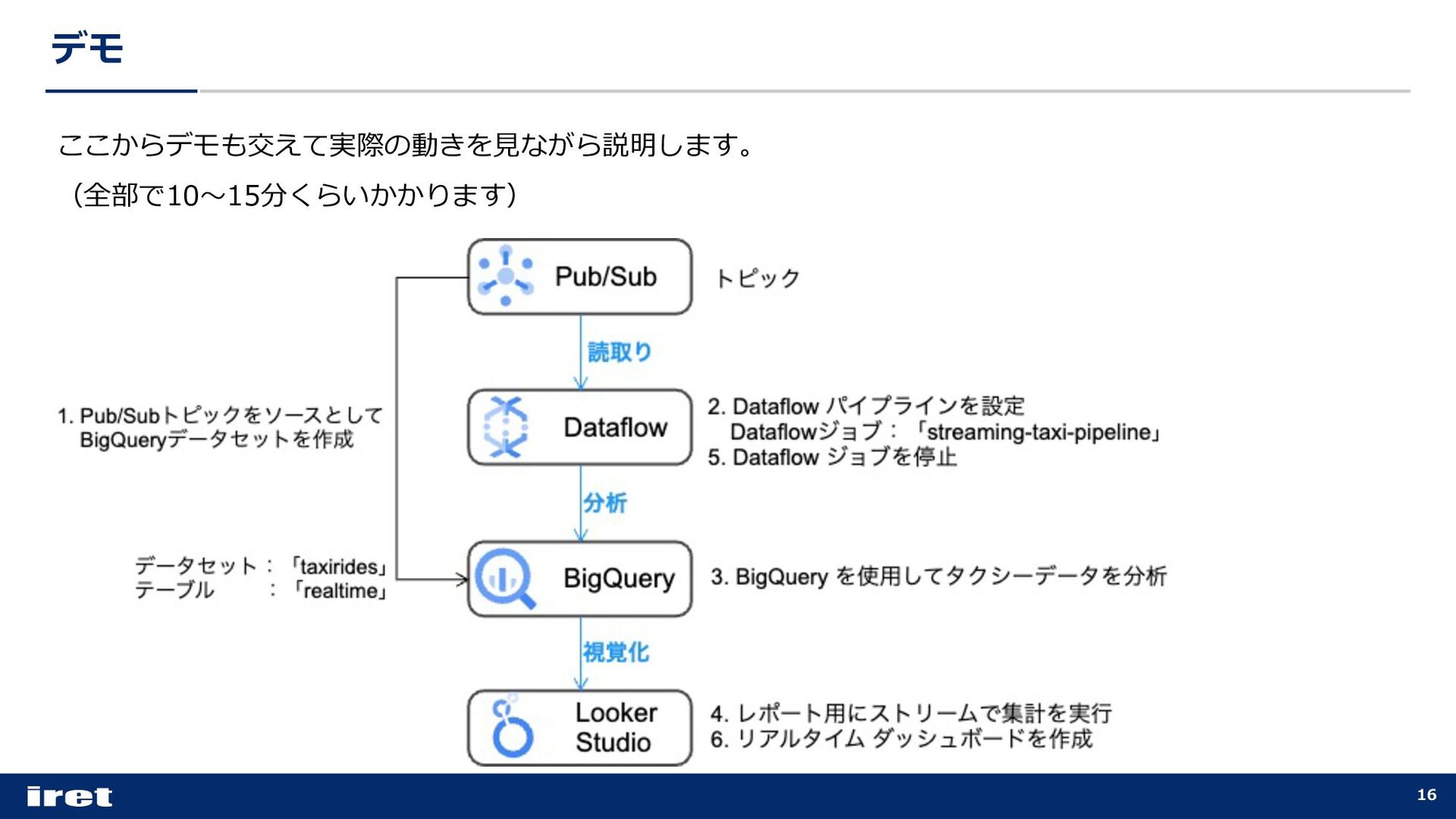
ストリーミング データ パイプラインを構築します。 • Google Cloudのデータ分析系サービスであるPub/Sub、BigQuery、Dataflow、Looker Studioについて 学びます。 • 内容的には、Google Cloud Professional Cloud Data Engineer 試験の内容に近いです。 (参考)A Streaming Data Pipeline for a Real-Time Dashboard with Google Cloud Dataflow
SELECT timestamp, TIMESTAMP_TRUNC(timestamp, HOUR) AS `時`, TIMESTAMP_TRUNC(timestamp, MINUTE) AS `分`, TIMESTAMP_TRUNC(timestamp, SECOND) AS `秒`, ride_id, latitude, longitude, meter_reading, ride_status, passenger_count FROM taxirides.realtime ORDER BY timestamp DESC LIMIT 1000 ) # calculate aggregations on stream for reporting: SELECT ROW_NUMBER() OVER() AS `ダッシュボード_ ソート`, `分`, COUNT(DISTINCT ride_id) AS `乗⾞合計`, SUM(meter_reading) AS `収益合計`, SUM(passenger_count) AS `乗客合計` FROM streaming_data GROUP BY `分`, timestamp
ストリームパイプラインの設定を⼿動ですることで、ストリームパイプラインのイメージができるように なった • 処理したストリーミングデータをBigQueryに格納し、可視化する⽅法を学べた • このようなダッシュボードを作成することで、ストリーミングデータの状況をリアルタイムで確認し、問 題やチャンスを素早く把握、ビジネス上の意思決定に活⽤できそう • Google Cloud Professional Cloud Data Engineer 試験対策にもなる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1. Pub/SubトピックをソースとしてBigQueryデータセットを作成 18 1. BigQueryのプロジェクトIDの右横に表⽰される から、[データセットを作成] をクリック 2. [データセットID] に「taxirides」と⼊⼒](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_17.jpg){kind=link}
{kind=link}
![2. Dataflow パイプラインを設定 20 Pub/Subからセンサーデータを読み取り、BigQueryに書き込むDataflowストリーミングデータパイプライ ンを設定します。 1. Dataflowのメニューバーの [テンプレートからジョブを作成] をクリック](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![3. BigQuery を使⽤してタクシーデータを分析 24 ストリーミング中のデータを分析します。 realtime テーブルに書き込まれたデータを表⽰する⽅法は次のとおりです。 1. BigQueryのメニューで[クエリを新規作成]をクリック 2.](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
![4. レポート⽤にストリームで集計を実⾏ 27 レポート⽤にストリームで集計を計算します。 1. 引き続きクエリエディターで次のように⼊⼒し、[実⾏]をクリック WITH streaming_data AS (](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_26.jpg){kind=link}
{kind=link}
![4. レポート⽤にストリームで集計を実⾏ 29 2. [保存] > [クエリを保存]をクリック 3. [クエリの保存]ダイアログの[名前]フィールドに「My Saved](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_28.jpg){kind=link}
![5. Dataflow ジョブを停⽌ 30 Dataflow ジョブを停⽌して、プロジェクトのリソースを解放します。 1. Dataflowの[ジョブ]メニューから「streaming-taxi-pipeline」をクリック 2. [停⽌]をクリックし、[キャンセル]](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_29.jpg){kind=link}
![6. リアルタイム ダッシュボードを作成 31 リアルタイム ダッシュボードを作成してデータを視覚化します。 1. BigQueryのエクスプローラーペインで、プロジェクトIDを展開 2. [保存したクエリ]を展開し、「My](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_30.jpg){kind=link}
{kind=link}
![7. 時系列ダッシュボードを作成 33 1. Looker Studioで、[ + ] 空⽩のレポートテンプレートをクリック 2.](https://files.speakerdeck.com/presentations/2c3ac8f9c2fb42d49484e499819c44b3/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}