Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
バンディット問題の理論とアルゴリズム第10章
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
issei
January 10, 2017
Technology
960
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
バンディット問題の理論とアルゴリズム第10章
2017/1/10 輪読資料(10.1と10.2)
2017/1/25 輪読資料(10.3)
issei
January 10, 2017
More Decks by issei
See All by issei
#ssmjp20170324LT
isseita
0
620
社外勉強会に行ってみよう
isseita
0
180
高層天気図の読み方
isseita
0
1.7k
Other Decks in Technology
See All in Technology
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
410
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
280
デジタル・デザイン構想 by Sayaka Ishizuka
y150saya
0
200
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
700
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
430
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
2.9k
Baseline対応のDOMの型定義を作った
uhyo
3
720
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
270
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
1
220
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.3k
Featured
See All Featured
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.3k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
The Language of Interfaces
destraynor
162
27k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
The SEO identity crisis: Don't let AI make you average
varn
0
510
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Building AI with AI
inesmontani
PRO
1
1.1k
Fireside Chat
paigeccino
42
4k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Rails Girls Zürich Keynote
gr2m
96
14k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Transcript
バンディット問題の理論とアルゴリズム 第 10章 バンディット手法の応用 輪読担当: issei
About me Issei Takano 仕事:フロントエンド(BackboneJS、Seasar2) 専門:物理学(統計力学、気象力学) Twitter: it__ssei slack: ssmjp,
ng-japan, … game: PSO2, FF14 (c) ギルティクラウン製作委員会 (c) Project-118/凪のあすから製作委 員会
10章のあらすじ バンディット手法をどのように適用できるのかを示す。 1. ゲーム木探索(囲碁・将棋) 2. インターネット広告配信 3. 推薦システム
10.1 ゲーム木探索
三目並べ (図10.1参照) 木構造:現在の局面と、そこから遷移可能な局面とで作る 探索手法:ミニマックス探索
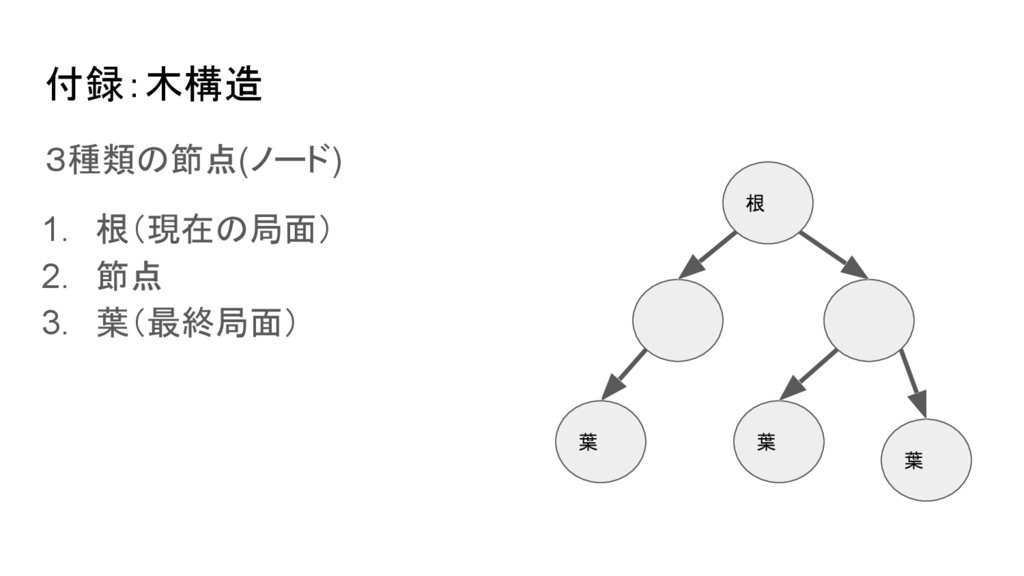
付録:木構造 3種類の節点(ノード) 1. 根(現在の局面) 2. 節点 3. 葉(最終局面) 根 葉
葉 葉
ミニマックス探索(p172) 対象:三目並べ 設定:木構造は予め全て展開しておく 評価値:次のようにして最終局面から辿ってくる 自分の手:最大値(マックス) 相手の手:最小値(ミニ) 最善手:評価値が最大の節点への遷移
囲碁や将棋 木構造:現在の局面と、そこから遷移可能な局面とで作る 問題点:ゲーム木を全探索するのは不可能 対処法:ゲーム木を最終局面まで展開せずに評価する
モンテカルロ木探索 対象:囲碁・将棋 木構造:現在の局面と、そこから遷移可能な局面とで作る。 ただし、最初は全て展開せずに途中で止めておく (止めた箇所を「葉節点」と呼んでいる) 評価方法:評価したい局面から先をモンテカルロ法でランダムに プレイ(プレイアウト)
モンテカルロ木探索の一般形 s 0 :現在の局面、v 0 :根節点の木Tについて 1. 木Tの葉節点 v t
の選択 2. 木Tの拡張 (葉節点 v t に子節点v’ を追加し、それを新たなv t とする) 3. プレイアウトによる、葉節点v t から到達可能な最終局面の評価値のランダム抽出 4. ランダム抽出された評価値の葉節点v t から根節点v 0 への逆伝搬 繰り返し後に、v 0 の子節点vjを選択する
モンテカルロ木探索にバンディット手法を使う s 0 :現在の局面、v 0 :根節点の木Tについて 1. 木Tの葉節点 v t
の選択 ←ここにUCB方策を用いるのがUCTアルゴリズム 2. 木Tの拡張 (葉節点 v t に子節点v’ を追加し、それを新たなv t とする) ←ここにもバ ンディットを使うのが有効 3. プレイアウトによる、葉節点v t から到達可能な最終局面の評価値のランダム抽出 4. ランダム抽出された評価値の葉節点v t から根節点v 0 への逆伝搬 繰り返し後に、v 0 の子節点vjを選択する →UCBスコア 第一項:知識利用、第二項:探索
10.2 インターネット広告
このセクションで扱う広告配信 1. クリック毎に課金・報酬(PPC)を行う 2. 広告オークション 広告主からの広告代を最大化する方法を考える
クリック毎に課金・報酬(PPC)を行う配信方式 こんな広告:ブログのスペースに貼るタイプ 問題点:どの広告が最もクリック率が高いかは、配信しないと推定できない バンディット問題に当てはめると 知識利用:現時点までのクリック率が最大の広告を配信する 探索:配信数が少なく、クリック率の推定精度が低い広告を配信する
PPC広告配信の定式化 制約: 広告は予算内の回数まで配信する 配信先ページと広告の相性がある 線形計画問題:全体のクリック数を最大化する 推定する対象:クリック率 ←配信回数が少ないうちは、ギッティンズ指標などを用いて 大きめに見積もる
広告オークション オークションに競り勝った広告を掲載する方式 落札額による分類 1. 第一価格オークション ←腹の探り合いになるため使わない 2. 第二価格オークション ←通常使うのはこちら 正直なオークション: 1. 他の広告の提示金額に依存しない
2. 全ての広告がそうなる 広告収入最大化する設計:アルゴリズム10.2参照
10.3 推薦システム
推薦システム 情報フィルタリングをつかって、各人に合った商品を推薦したい 1. 人口統計学的属性に基づくフィルタリング 2. 内容に基づくフィルタリング 3. 協調フィルタリング
フィルタリングで使うモデル(属性や内容に基づくもの) X i :評価値または購買確率 θ:モデルパラメータ a:ユーザ属性とアイテム属性の交互作用を考慮した属性のベクトル u:ユーザ ε:誤差項
フィルタリングの性能指標 ・訓練データで学習した予測器の、テストデータに対する推薦精度 ・新規ユーザに対する初期段階の予測精度 ・探索と知識利用のバランスを取るためにバンディット手法を用いる
オフライン評価(性能指標の一例として) ニュース推薦システム(Li et. al 2010)にてPolicy Evaluatorの利用が提案された。 まず、各時刻にランダムに(一様分布で)選んだ方策でニュースを推薦する →これによって取れたログから事象列を作る ※ここには評価したい方策を入れない 次に、Policy
Evaluatorによる方策の評価をオフラインで行う ・評価したい方策で推薦したニュースと一致する事象を順に探す ・定理10.2の通り、オンライン評価の結果と分布が一致する
協調フィルタリング ユーザのアイテムに対する評価値行列の欠損値を推定する問題として定式化する →行列分解 MをUとVに分解する ・Vを線形モデルとして推定して固定し Uを線形バンディットの手法で決める→トンプソン抽出 ・Vに事前分布を与え UとVの最大事後確率(MAP)を推定する→確率的行列分解
推薦アイテムのリストを評価するには 推薦アイテムのリスト表示時の報酬関数を用いる ・1つでもクリックされれば1、クリックなければ(放棄)0 ユーザの好みを知らない状態で推薦の報酬を最大化するアイテムの集合を求める →NP困難な問題になる (最大被覆問題) →評価するにはp186中程のリグレットを用いるのが妥当 →順位付きリストなら敵対的多腕バンディットで解けて、 リグレットの上限が決まっている
以上です。お付き合いいただきありがとうございます!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}