improves the flexibility and speed of queries.
• Flexible Table Formats: Supporting Apache Iceberg and Delta Lake.
• Fast Query Processing: Engineered for high-speed data querying across distributed data sources.
• Federated Queries: Allows querying data from multiple sources, simplifying analytics across disparate data stores (data federation).
• Scalable and Flexible: Easily scales to accommodate large datasets and complex queries.
Apache Spark
Offers powerful data processing capabilities, enabling performant complex analytics and machine learning on big data.
• In-Memory Computing: Accelerates processing speeds by keeping data in RAM, significantly faster than disk-based alternatives.
• Advanced Analytics: Supports complex algorithms for machine learning, graph processing, and more.
• Fault Tolerance: Resilient distributed datasets (RDDs) provide fault tolerance through lineage information.
• Language Support: Offers APIs in Python, Java, Scala, and R, broadening its accessibility and usability.
Apache Hive Metastore
A centralized repository for storing metadata about Hive tables, databases, and other schema-related objects.
• Centralized Metadata Management: Maintains metadata for all Hive tables, e.g. schema information, table locations, partitioning, and more. It enables seamless integration with tools like Apache Spark, Trino, and other query engines that rely on Hive for schema discovery.
• Partition and Schema Handling: Partition awareness significantly improves query performance for large datasets by partition pruning.
• Schema Evolution: It supports schema changes, such as adding or modifying columns, without requiring migration of existing data.
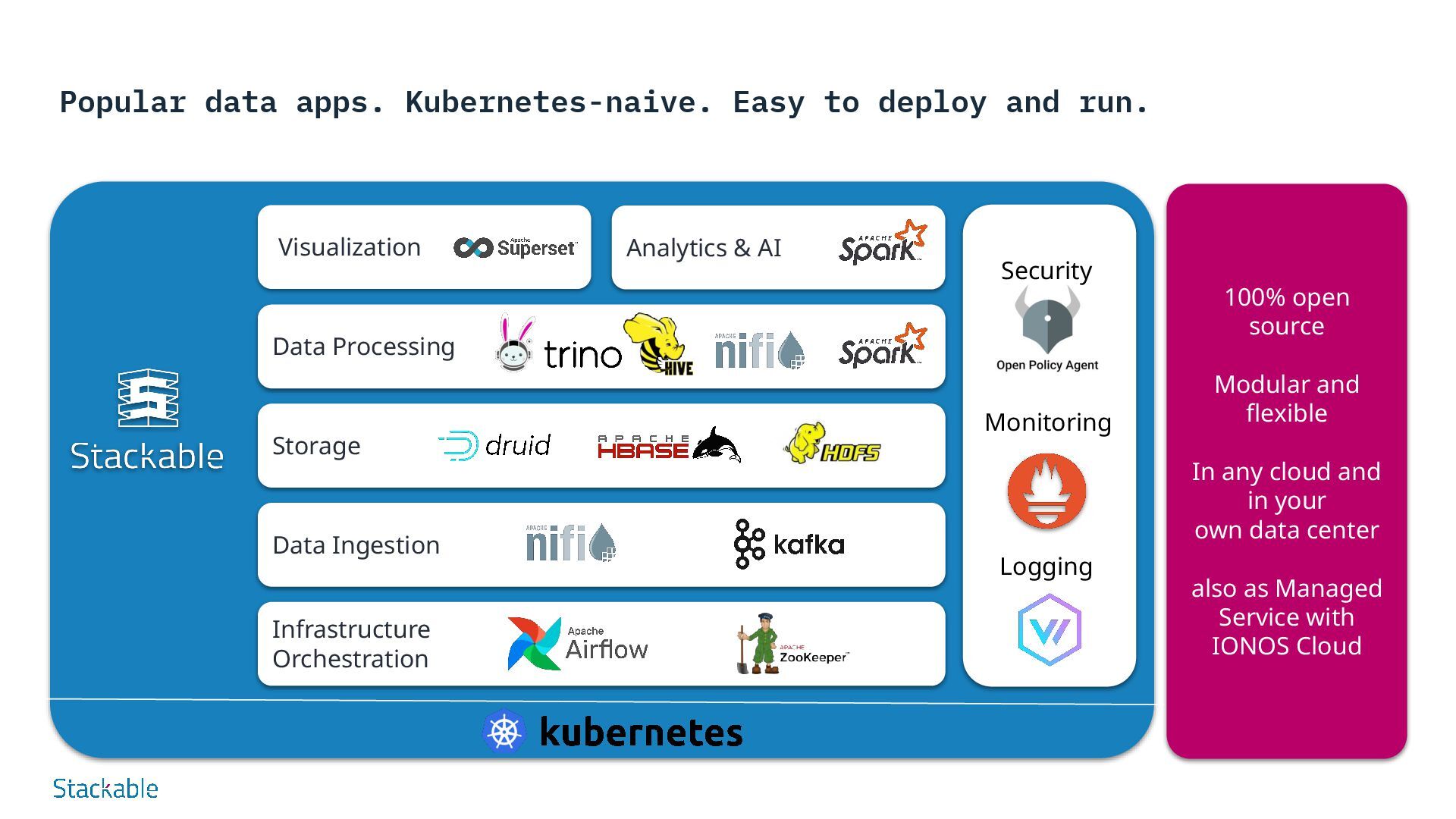
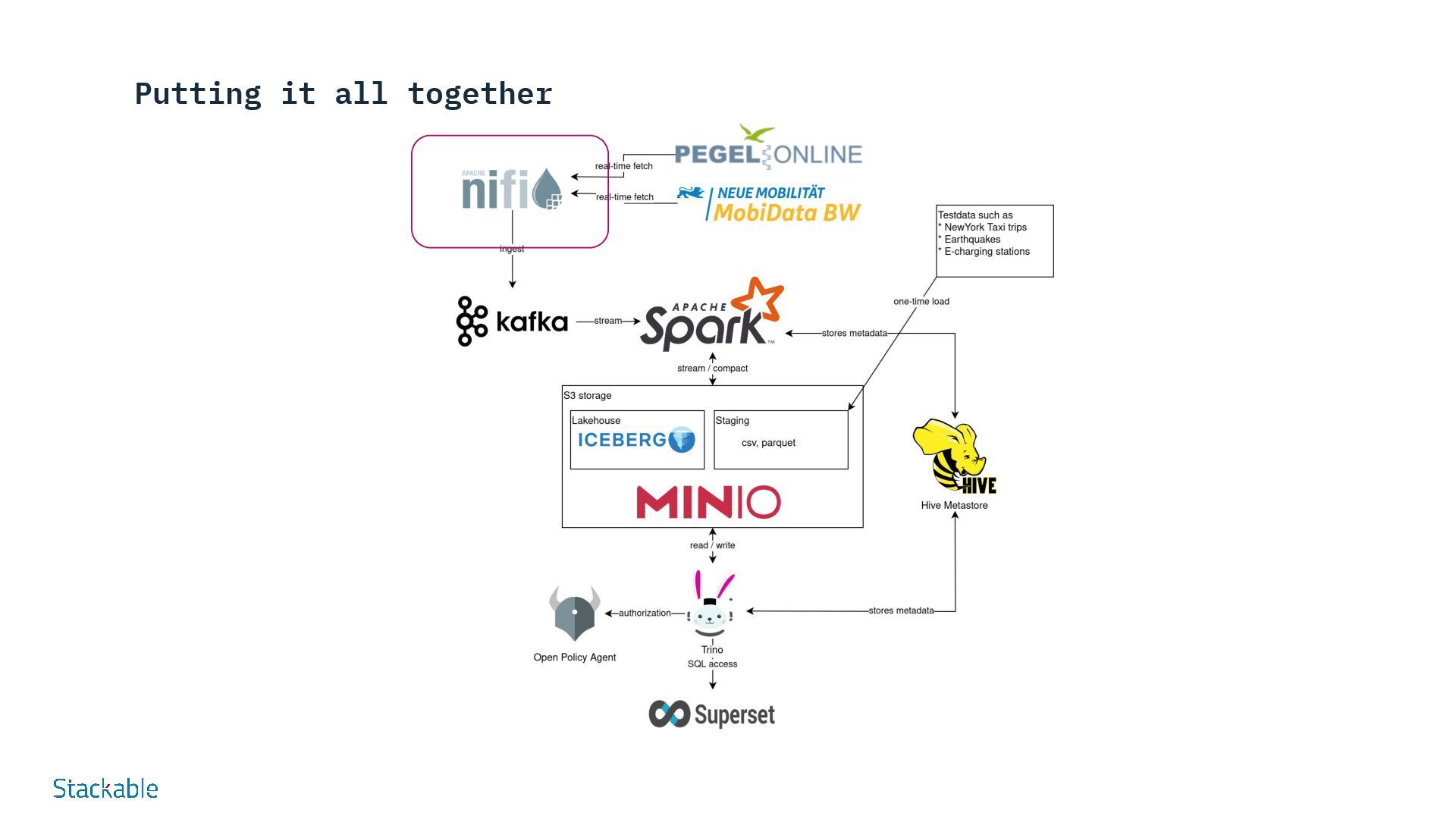
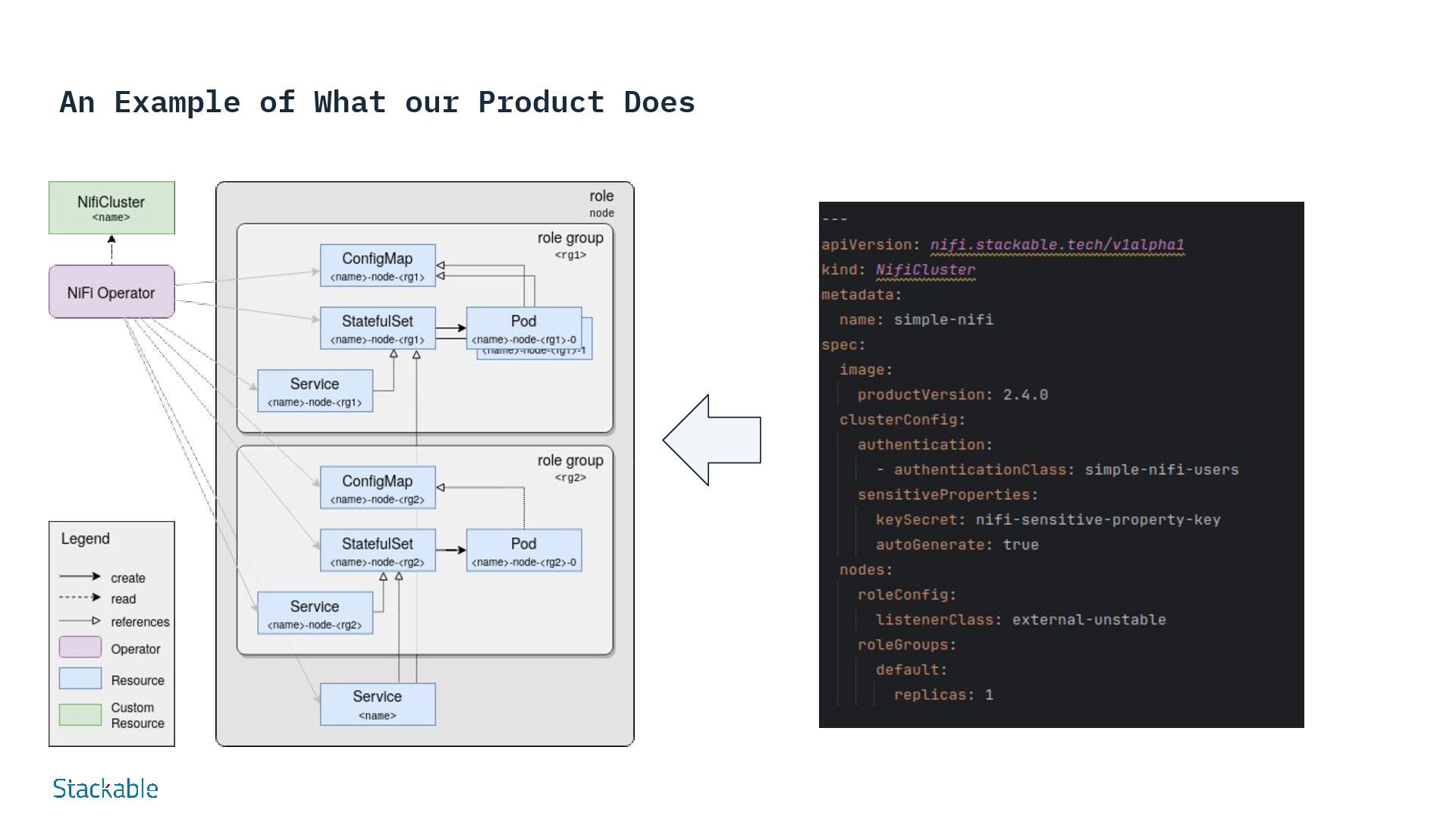
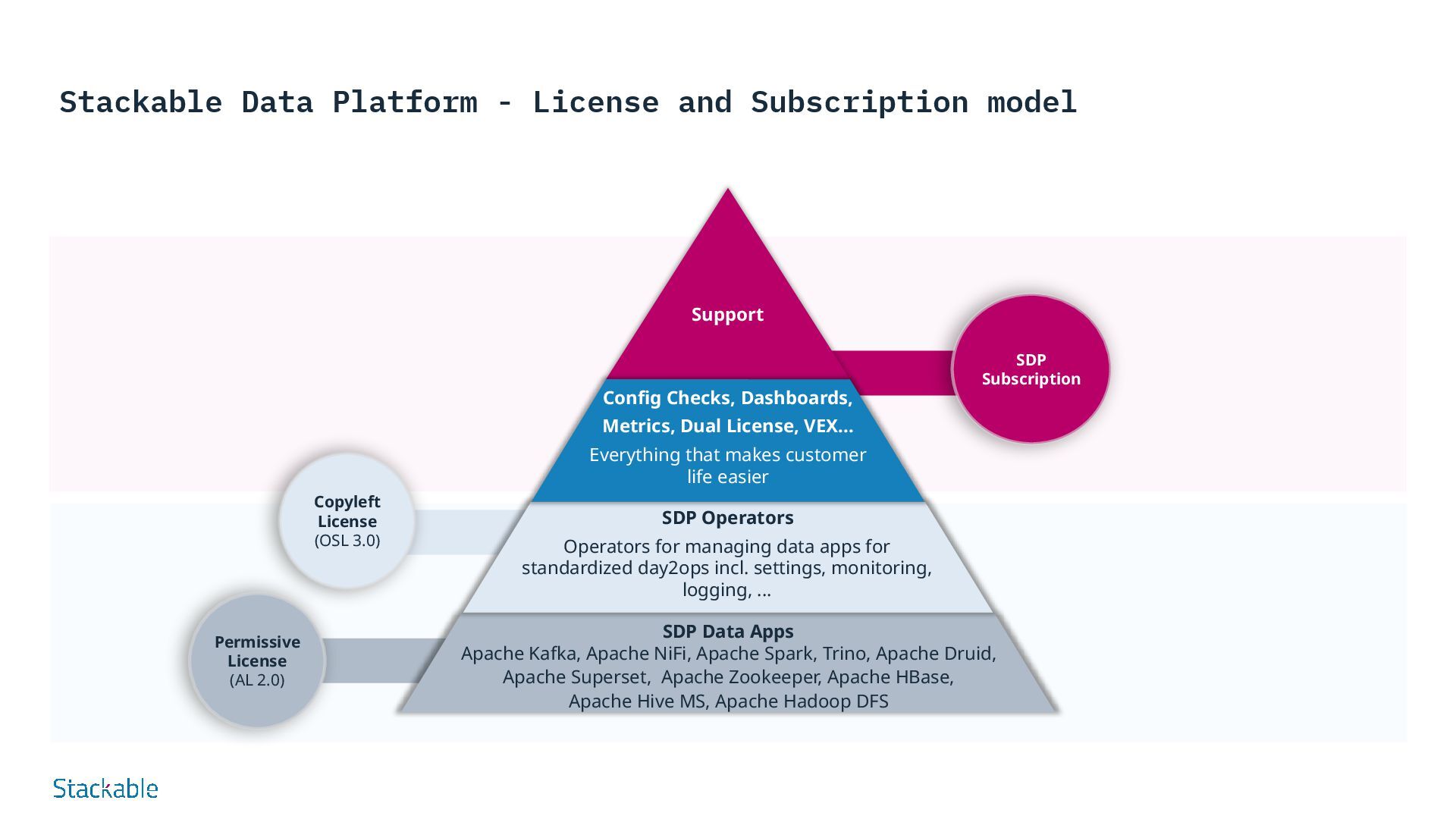
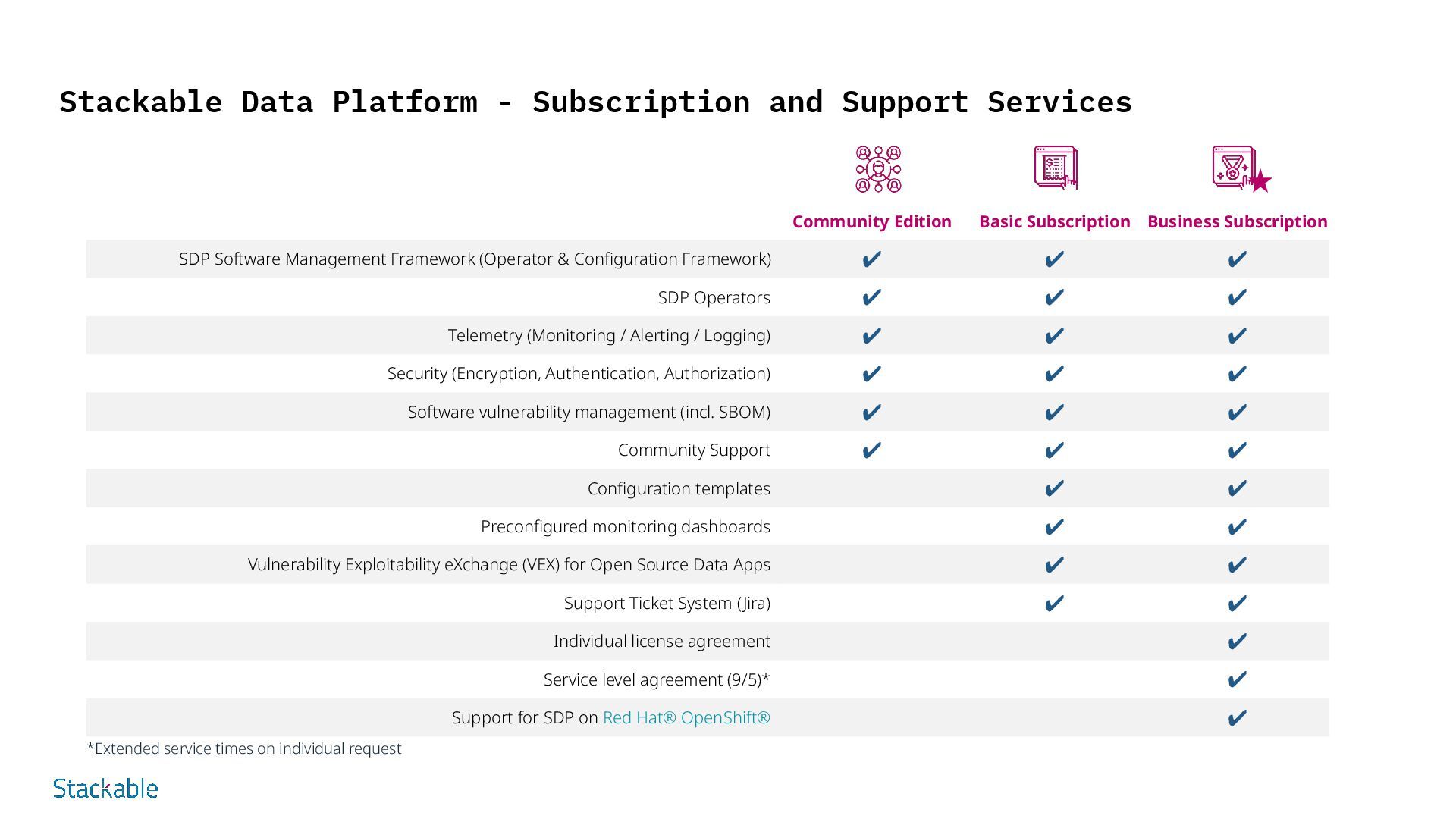
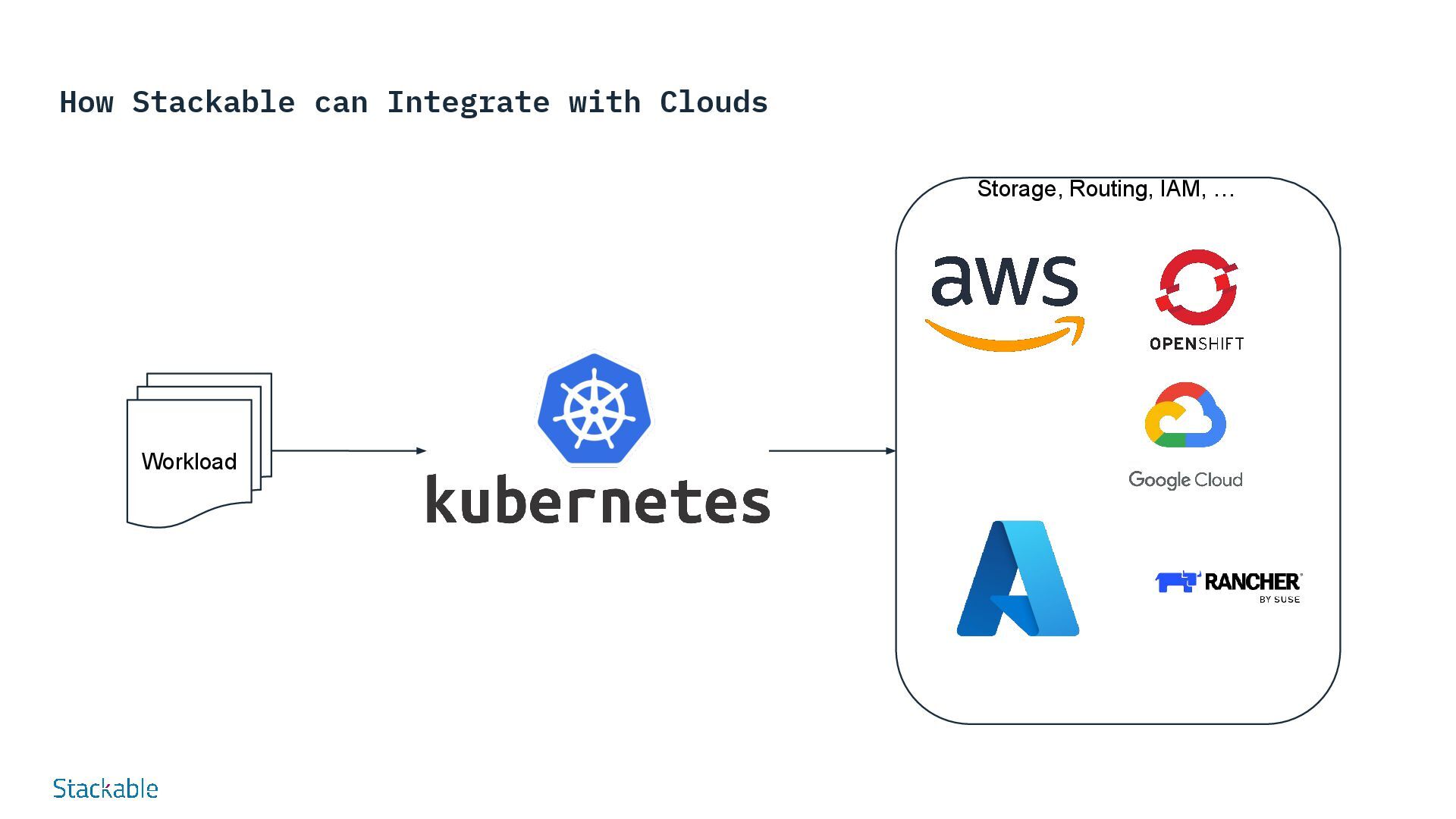
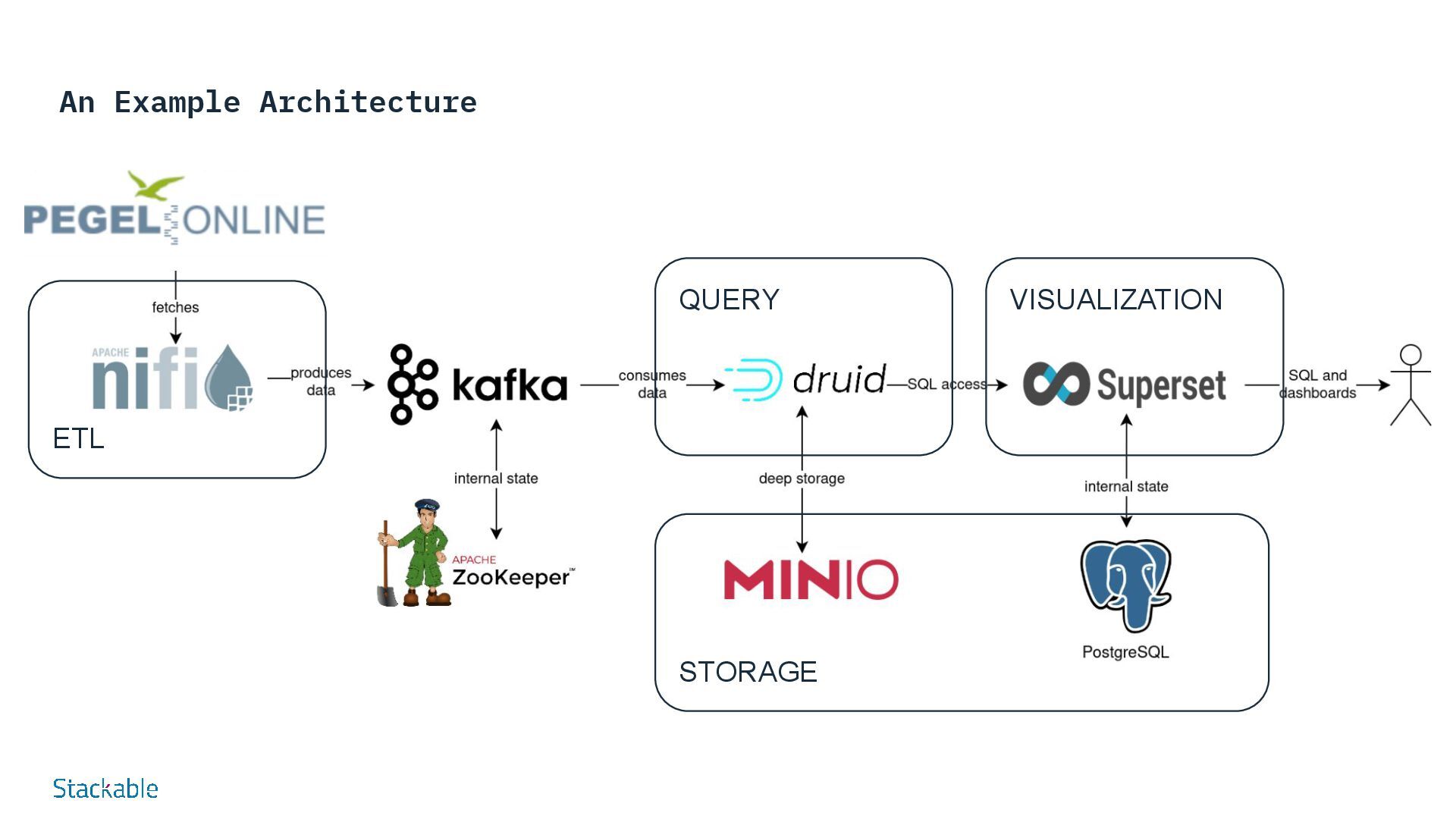
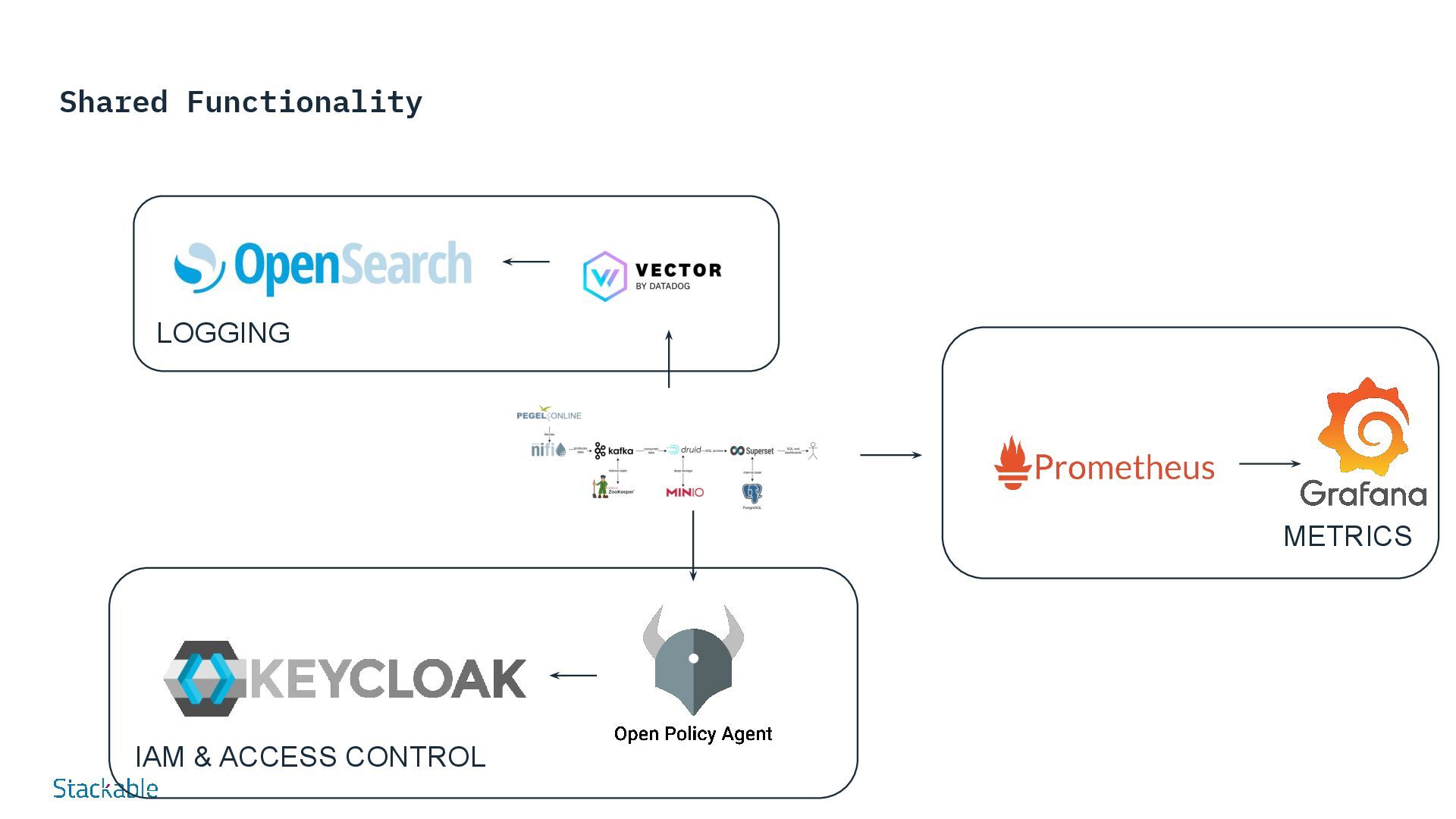
SDP: Data Processing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Contact: Sönke Liebau [email protected] +49 4103 926 3100](https://files.speakerdeck.com/presentations/fb8b7ce3b4e74a8eb3d8d458dd70d1e6/slide_81.jpg){kind=link}